前置き
- 情報は2025年3月のものとなります。今後、情報が変わることは大いにあります。
概要
- OpenAIは2025年3月20日(米国時間)に3つの新しい音声AIモデル"gpt-4o-transcribe"、"gpt-4o-mini-transcribe"、"gpt-4o-mini-tts"をリリースしました。(下記、英語ですがURLです。翻訳しながら読んでください)
https://openai.com/index/introducing-our-next-generation-audio-models/ - OpenAIのX
https://x.com/OpenAIDevs/status/1902817202358685880?ref_src=twsrc^tfw|twcamp^tweetembed|twterm^1902817202358685880|twgr^5910c2acc3a92faa758085d2afc0e006329a634f|twcon^s1_&ref_url=https%3A%2F%2Fweel.co.jp%2Fmedia%2Ftech%2Fopenai-gpt4o-transcribe%2F
特徴
- これまでのWhisperモデルに比べ、誤認識を大幅に削減
- 日本語をはじめとして、100以上の言語に対応
- 2025年3月現在はAzureOpenAI上ではモデルデプロイできない
gpt-4o-transcribeの特徴
- 音声の文字起こしが可能なAIモデルです。gpt-4o-transcribeおよびgpt-4o-mini-transcribeは、精度・耐環境性を重視した音声文字起こしモデルとして、特にリアルタイム処理に強みを持っています。
- 高精度な文字起こし
- Whisperシリーズに比べ、単語誤り率(WER)が大幅に低下し、ノイズや多様なアクセント、話速の変化がある環境でも正確な転写が可能です。
- 高度な技術的工夫
- 強化学習や高品質なオーディオデータセットを用いた中間トレーニングにより、音声の微妙なニュアンスも正確に捉えます。(嚙んだりしたところや間が空いたところも正確に文章化できておりました!!)また、ノイズ除去や意味的な音声活動検出技術が搭載され、話の一区切りを見極めながら転写するため、自然な文章が生成されます。
- リアルタイムストリーミング対応
- ストリーミング機能を利用すれば、連続したオーディオ入力をリアルタイムでテキストに変換できるため、会議の議事録作成やライブイベントなどの用途にも適しています。
- 話者分離は未対応
- 現時点では、複数の話者を個別に識別する機能(diarization)は搭載されていません。(実際に検証したが、不可能でした)
gpt-4o-mini-transcribeの特徴
- 高速かつ低コスト
- gpt-4o-transcribeと同様の高精度な文字起こしを実現しながら、モデルサイズを小型化することで処理速度が向上し、コスト面でも優れています。
- 実用性重視の設計
- リアルタイムの音声入力に対して高速に反応するため、さまざまなアプリケーションへの組み込みが容易です。開発者向けAPIとして提供され、迅速な実装が可能です。
gpt-4o-mini-ttsの特徴
- 自然でカスタマイズ可能な音声生成
- テキストから自然な音声を生成するだけでなく、ユーザーや開発者が「どのように話すか(例えば、感情豊かに、ドラマチックに、中世の騎士風に、など)」と指示できる点が大きな特徴です。
- 多彩な声質と雰囲気
- 複数のプリセットやカスタム指示により、用途に応じた音声を生成でき、カスタマーサポート、ストーリーテリング、教育用途など幅広いシーンで活用できます。
- デモ環境の提供
- 無料でOpenAI.fmなどのデモサイトで、実際に音声生成の挙動を試すことができるため、導入前にその性能を確認できます。(後程、検証します。)
OpenAIでの料金
※OpenAIのサイトでも公開されておりますが、まとめておきました。また円ドル為替は2025年3月の情報です。
- Text tokens (Price per 1M tokens)
| Model | Input | Output |
|---|---|---|
| gpt-4o-mini-tts | $0.60(約¥90) | - |
| gpt-4o-transcribe | $2.50(約¥373) | $10.00(約¥1,493) |
| gpt-4o-mini-transcribe | $1.25(約¥187) | $5.00(約¥747) |
- Audio tokens
| Model | Input | Output |
|---|---|---|
| gpt-4o-mini-tts | - | $12.00(約¥1,792) |
| gpt-4o-transcribe | $6.00(約¥896) | - |
| gpt-4o-mini-transcribe | $3.00(約¥448) | - |
試してみた_Part1 (gpt-4o-mini-transcribe)
gpt-4o-mini-transcribeでの検証
APIキーの準備
- OpenAIのウェブサイト(https://openai.com/) にアクセスする。
- メニューバーの[APIプラットフォーム]>[APIログイン]をクリックする。

- [Ctrl]キーと[K]キーを同時に押下するか[Search]をクリックする。

- 入力欄に"API keys"を入力し、[API keys]をクリックする。

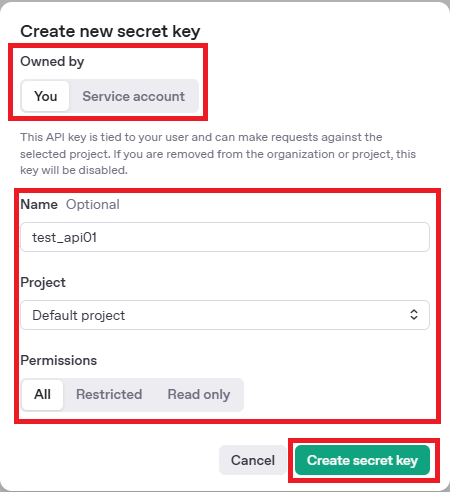
- [Create new secret key]をクリックする。(右上、中央箇所どちらでも可)

- 下記の情報を入力&設定し、[Create secret key]をクリックする。
- Owned by : You
- Name
- Project
- Permissions
- 生成されたAPIキーをメモ帳等でコピペする。コピペ後は[Done]をクリックする。(AzureOpenAIと違って、表示は一度きりなので注意すること)

使用言語&環境
- Python
- Jupyter Notebook
ライブラリインストール
# pipの更新 (実施してもしなくても可)
!python -m pip install --upgrade pip
# openaiライブラリのインストール
!pip install openai
環境変数の準備
# 環境変数の準備
import os
os.environ['OPENAI_API_KEY'] = "<発行したOpenAIキー>"
文字起こし実装
- 今回は何か使えそうなサンプル音声を探し、群馬県高崎市の委員会の開催情報及び音声データを引用しました。環境施設建設特別委員会の「高浜クリーンセンター建設事業の完了について」の音声データを使用してみました。音声データは約13分半です。(Zennの記事にはmp3の添付ができませんでした。)
https://www.city.takasaki.gunma.jp/site/gikai/4494.html
from openai import OpenAI
import os
# APIキーを設定
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# 音声ファイルのパス
audio_file_path = "<音声ファイルのパス>"
# 音声ファイルを開く
audio_file = open(audio_file_path, "rb")
# GPT-4o Transcribeを使用して文字起こし
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file
)
# 結果を表示
print(transcription.text)
結果
- 出力は約38秒
- 綺麗に聞き取れているが、全部で13分半あるものの途中10分で出力されたものが途切れていた。(この辺はトークンの調整が必要そうです。今後、この辺は検証したい。)
- 普通に出力したら、改行されたものは出力されませんでした。

- 下記、出力結果。(改行は私の方でしております。)
ただいまから環境施設建設特別委員会を開会いたします。この際、諸般の報告を申し上げます。
傍聴はあらかじめ許可してあります。以上で諸般の報告を終わります。それでは本日の会議に入ります。
本日の会議は会議規則第118条第1項の規定により、委員1人当たりの発言時間を30分程度としたいと思いますので、よろしくお願いいたします。それでは報告事項に入ります。
高浜クリーンセンター建設事業の完了について説明をお願いいたします。
----------------------
(長くなるので途中省略)
----------------------
説明は終わりました。
本件に対してご質疑等ありましたらお願いをいたします。
唐沢委員。
高浜クリーンセンターの完成に至りまして、本当に良かったなと思っております。
完成式典が無事終わりましたし、既に一般の搬入ヤードなんかが稼働していると思いますけれども、
渋滞解消だとか一般ごみの搬入だとか、今までと若干様子が違うというところが出ていると思いますけれども、まだ稼働していてあまり日が経っておりませんけれども、
何か搬入した一般の方々からご意見とあって伺っているようでしたら伺いたいと思いますけど。
環境施設整備室長。
はい、お答えいたします。新施設が協業開始となり、約1ヶ月が経過したところですが、
旧施設ではごみの種類ごとにそれぞれの受け入れ場所にごみを持ち込んでいましたが、
新施設においては自己搬入ヤードで可燃ごみ、不燃ごみ等ごみの種類にかかわらず一箇所で受け入れてもらえるので、
とても便利になったという声を一番多く聞いております。
また、ごみ搬入時においては計量場所が2箇所となり、ごみ収集車両と一般持ち込み車両を分けて計量してくれるので、
待ち時間と渋滞が緩和され、スムーズにごみ搬入ができるようになったとのご意見をいただいております。以上でございます。
唐沢委員。
はい、わかりました。私の妹なんかも自分でちょこちょこと100キロ以下でなくも、今度はオーバーしただけでいいん
↑
ここで途切れておりました...(経過時間10分のところです)
その他
- 文字起こしのカスタマイズができます。
- ストリーミング(リアルタイム)処理も可能です。
※詳細は下記URL参照。
https://weel.co.jp/media/tech/openai-gpt4o-transcribe/
試してみた_Part2 (gpt-4o-mini-tts)
gpt-4o-mini-ttsを使用したデモ環境を触る
- 繰り返しになりますが、OpenAIは「OpenAI.fm」というデモ環境を用意しており、「gpt-4o-mini-tts」を無料で簡単に試せるので、少し触ってみました。(音声がないと伝わらない面がありますが)
https://www.openai.fm/
-
デモ環境をブラウザで開き、早速[Play]をクリックする。アクセス時の初期設定は声(Voice)が"Coral"、雰囲気が"Dramatic"でそのまま聞くと、アルトボイスの女性の遅い音声が流れました(笑)

-
少し声を変えてみました。"Echo"に変えると男性の声が流れてきました(笑)(自由に選べます)

-
雰囲気を"Cowboy"に変えると、明るい口調になりました(笑)

-
天気情報をコピペした日本語も対応が出来ていました。

その他
-
デモ環境から結果をダウンロードできたり、URLの共有ができたりします。

-
右上のスライダーを切り替えると、Python、JavaScript、cURLでOpenAIのAPIを利用するためのコードが表示されます。API経由でgpt-4o-mini-ttsを使用したい場合、このコードをコピペしてスクリプトや雰囲気を編集することができます。

所管
楽しかったです(笑)
またアップデートがあれば、検証します。

Discussion
まとめありがとうございます!