TypeScriptパーサーのベンチマーク:Rustツールの性能の謎を解く
TL;DR: JavaScriptで使われるネイティブパーサーは、言語間の余分な作業のために常に速いとは限りません。これらのオーバーヘッドを回避し、マルチコアを使うことが性能にとって重要です。
Rustは、そのパフォーマンスと安全性の特徴から、JavaScriptエコシステムの中で急速に選択肢の一つになっています。しかし、RustをJavaScriptツールに統合することは、特に効率的で移植性の高いプラグインシステムを設計する際に、固有の課題をもたらします。
「JavaScriptツールをRustで書き直すことは、広範な外部貢献を必要としない速度重視のプロジェクトにとって有利です。」
ESLintの作者であるNicholas C. Zakas
Rustは、その急な学習曲線のために難しいものになりがちで、さらにコンパイルされたバイナリを異なるプラットフォームに配布することも簡単ではありません。
Rustベースのプラグインは、すべてのプラグインを静的にコンパイルするか、動的にロードするための注意深く設計されたABI(アプリケーションバイナリインターフェース)のいずれかを必要とします。
しかし、これらの考慮事項は、この記事の範囲を超えています。そこで、ここでは、JavaScriptでプラグインを書くための堅牢なツールを提供する方法に焦点を当てます。
JavaScriptツールの重要な構成要素は、ソースコードを抽象構文木(AST)に解析することです。プラグインは、ASTを調べたり操作したりして、ソースコードを変換します。したがって、Rustだけで解析するだけでは十分ではありません。ASTをJavaScriptにもアクセス可能にする必要があります。
この記事では、JavaScript、Rust、Cで実装されたいくつかの人気のあるTypeScriptパーサーのベンチマークを行います。
パーサーの選択
利用可能なJavaScriptパーサーは数多くありますが、このベンチマークではTypeScriptパーサーに焦点を当てます。現代のバンドラーは、TypeScriptをそのままサポートする必要がありますし、TypeScriptはJavaScriptの上位集合です。TypeScriptをベンチマークすることは、実際のバンドラーのワークロードを模倣するための賢明な選択です。
評価対象のパーサーは以下の通りです。
- Babel: Babelパーサー(以前はBabylon)は、Babelコンパイラで使用されるJavaScriptパーサーです。
- TypeScript: TypeScriptチームからの公式なパーサーの実装です。
- Tree-sitter: ソースファイルのために具象構文木を構築・更新できるインクリメンタルなパーシングライブラリで、テキストエディタの使用に十分に速い任意のプログラミング言語を解析することを目指しています。
- ast-grep: 抽象構文木に基づいたコードの構造的検索、リント、書き換えのためのCLIツールです。ここでは、そのnapi bindingを使用しています。ast-grepについて知らない方には、Makotoさんの「日本語紹介」がおすすめです。
- swc: Rustで書かれた超高速なTypeScript/JavaScriptコンパイラで、パフォーマンスとRustとJavaScriptの両方のユーザーのためのライブラリであることに重点を置いています。
- oxc: Oxidation Compilerは、JS/TSのための高性能なツールの組み合わせで、Rustで書かれた最速で最も準拠したパーサーを持つと主張しています。
ネイティブアドオンの性能特性
ベンチマークに入る前に、まずNode-APIベースのソリューションの性能特性を見てみましょう。
Node-APIの利点:
- より良いコンパイラ最適化: ネイティブ言語のコードは、データのレイアウトがコンパクトで、CPU命令の数が少なくなります。
- ガベージコレクタのランタイムオーバーヘッドがない: これにより、性能がより予測可能になります。
しかし、Node-APIは万能薬ではありません。
Node-APIの欠点:
- FFIオーバーヘッド: 異なるプログラミング言語間のインターフェースのコストです。
- Serdeオーバーヘッド: Rustのデータ構造のシリアライズとデシリアライズはコストがかかります。
- エンコーディングオーバーヘッド: JSのutf-16の文字列をRustのutf-8の文字列に変換すると、大きな遅延が発生する可能性があります。
ネイティブノードアドオンを使用する際の利点と欠点を理解することで、有意義なベンチマークを設計することができます。
ベンチマークの設計
以下の2つ要因を考慮します。
-
ファイルサイズ: 異なるファイルサイズは、異なる性能特性を明らかにします。N-APIベースのパーサーの解析時間は、実際の解析と言語間のオーバーヘッドから構成されます。解析時間はファイルサイズに比例しますが、言語間のオーバーヘッドの増加は、パーサーの実装に依存します。
-
並行性レベル: JavaScriptのシングルメインスレッドでは、並列解析は不可能です。しかし、N-APIベースのパーサーは、別のスレッドで実行できます。それは、libuvのスレッドプールを使用するか、独自のスレッドモデルを使用するかのどちらかです。とはいえ、スレッドの生成もオーバーヘッドをもたらします。
この記事では、以下の要因は考慮していません。
- ウォームアップとJIT: ウォームアップと非ウォームアップの実行の間に有意な差は観察されませんでした。
- GC、メモリ使用量: このベンチマークでは評価していません。
- Node.jsのCLI引数: ベンチマークを代表的にするために、デフォルトのNode.jsの引数を使用しましたが、チューニングによって性能が向上する可能性があります。
ベンチマークのセットアップ
テスト環境
ベンチマークは、以下の仕様を備えたシステムで実行されました。
- オペレーティングシステム: macOS 12.6
- プロセッサ: arm64 Apple M1
- メモリ: 16.00 GB
- ベンチマークツール: Benny
ファイルサイズのカテゴリ
さまざまなコードベースでのパーサーの性能を評価するために、ファイルサイズを以下のように分類しました。
-
シングルライン: ベースラインのオーバーヘッドを測定するための最小限のTypeScriptスニペット、
let a = 123;です。 - 小さいファイル: 一般的なユーティリティファイルを表す24行の簡潔なTypeScriptモジュールです。
- 中くらいのファイル: 平均的な開発ワークロードを反映した400行の典型的なTypeScriptファイルです。
-
大きいファイル: TypeScriptリポジトリから2.79MBの
checker.tsです。これは、パーサーに複雑で大規模なコードベースに挑戦させます。
並行性レベル
このベンチマークでは、5つのファイルを同時に解析することで、現実的なワークロードをシミュレートします。この数値は、実際のJavaScriptツールに対する恣意的ですが合理的な代理値です。
Node.js開発者にとっては、このセットアップが非同期解析の性能に影響を与える可能性があることに注意するかもしれません。しかし、これはRustベースのパーサーに有利になるわけではありません。その根拠は、読者の演習として残しておきます。:)
この記事は、TypeScriptパーサーのベンチマークについて、一般的な概要を提供することを目的としています。N-APIベースのソリューションの性能特性と関係するトレードオフに焦点を当てています。ワークロードに合わせてベンチマークのセットアップを調整してください。
それでは、TypeScriptパーサーのベンチマークの結果について見ていきましょう!
結果
同期的な解析
各パーサーの性能は、Bennyベンチマークフレームワークが提供するメトリックである秒あたりの操作数で定量化されます。比較しやすくするために、結果を正規化しました。
- 最も速いパーサーはベンチマークとして指定され、効率は100%に設定されます。
- 他のパーサーは、このベンチマークに対して相対的に評価され、その性能はベンチマークの速度の割合として表現されます。


TypeScriptは、すべてのファイルサイズにおいて、他のパーサーを常に上回り、Babelの2倍の速さです。
ネイティブ言語のパーサーは、FFIオーバーヘッドの相対的な影響が減少するため、大きなファイルでは性能が向上します。
しかし、性能の向上は、入力ファイルサイズに比例するシリアライズとデシリアライズ(serde)のオーバーヘッドのために、顕著ではありません。
非同期的な解析
非同期的な解析のシナリオでは、以下のことが観察されます。
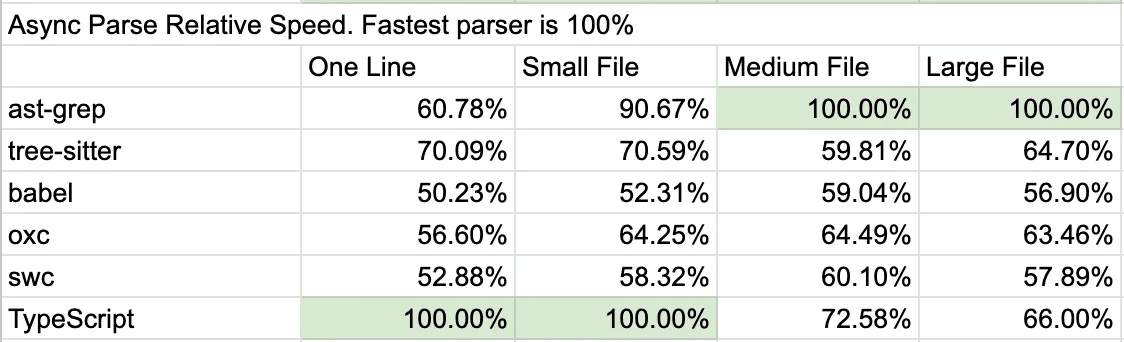

ast-grepは、中から大きなファイルを同時に複数処理する際に優れており、マルチコアの能力を効果的に活用しています。TypeScriptとTree-sitterは、大きなファイルでは性能が低下します。SWCとOxcは、一貫した性能を維持し、マルチコア処理の効率的な利用を示しています。
解析時間の内訳
Node-APIベースのプログラムをベンチマークする際には、Rustのコードを実行するだけでなく、それらを結びつけるNode.jsのグルーコードにかかる時間も理解することが重要です。解析時間は、以下の3つの主要な要素に分解できます。
time = ffi_time + parse_time + serde_time
それぞれの項目について詳しく見ていきましょう。
-
ffi_time(Foreign Function Interface Time): これは、異なるプログラミング言語間で関数を呼び出す際に関連するオーバーヘッドを表します。通常、ffi_timeは固定コストであり、入力ファイルサイズに関係なく一定です。 -
parse_time(Parse Time): パーサーがソースコードを解析し、抽象構文木(AST)を生成するのに必要なコア時間です。parse_timeは入力のサイズに応じてスケールし、解析プロセスの変動コストとなります。 -
serde_time(Serialization/Deserialization Time): Rustのデータ構造をJavaScriptと互換性のある形式にシリアライズするために必要な時間、およびその逆です。parse_timeと同様に、serde_timeは入力ファイルサイズが大きくなるにつれて増加します。
本質的に、パーサーのベンチマークは、実際の解析にかかる時間(parse_time)を測定し、言語間の関数呼び出し(ffi_time)とデータ形式の変換(serde_time)から生じる余分なオーバーヘッドを考慮に入れることを意味します。これらの要素を理解することで、パーサーの効率性とスケーラビリティを評価するのに役立ちます。
結果の解釈
このセクションでは、上記の解析時間の枠組みに基づいて、ベンチマークの結果について詳細かつ技術的な分析を行います。概要を求める読者は、要約にスキップしてもらっても構いません。
FFIオーバーヘッド
同期的な解析と非同期的な解析の両方のシナリオで、解析やシリアライズがほとんどなく、FFIオーバーヘッドが支配的な「一行」のテストケースでは、TypeScriptの優れた性能が示されます。驚くべきことに、この一行のシナリオで優れていると期待されるBabelは、独自の特異なオーバーヘッドを示しています。
ファイルサイズが大きくなるにつれて、FFIオーバーヘッドはあまり重要ではなくなります。これは、FFIオーバーヘッドがほとんどサイズに依存しないからです。例えば、同期的な解析では、ast-grepの相対速度は一行に対して72%であるのに対し、大きなファイルでは78%であり、FFIオーバーヘッドが約6%であることを示唆しています。
FFIオーバーヘッドは、非同期的な解析ではより顕著です。ast-grepの性能は、一行の同期的な解析と非同期的な解析を比較すると、72%から60%に低下します。swc/oxcの性能に顕著な差がないのは、独自の実装によるものかもしれません。
Serdeオーバーヘッド
残念ながら、他のアプリケーションでswc/oxcの驚異的な性能を再現することはできませんでした。
「大きなファイル」のテストケースでは、FFIの影響が最小限であるにもかかわらず、swcとoxcはTypeScriptコンパイラよりも性能が低いです。これは、Rustから返された文字列にJSON.parseを呼び出すことに依存していることが原因と考えられます。これは直接的なデータ構造の返却よりもまだ効率的です。
Tree-sitterとast-grepは、ツリーオブジェクトを返すことで、serdeオーバーヘッドを回避しています。ツリーノードにアクセスするには、JavaScriptからRustのメソッドを呼び出す必要があり、コストを読み取りプロセスに分散させます。
並列
Tree-sitterを除くすべてのネイティブTSパーサーは、並列サポートを持っています。JSパーサーとは対照的に、ネイティブパーサーの性能は、大きなファイルを同時に解析するときに低下しません。これは、複数のコアの力のおかげです。JSパーサーは、ファイルを一つずつ解析しなければならないため、CPUバウンドに苦しんでいます。
パーサーの性能の要約
各パーサーの性能は、以下の表に要約されています。この表では、異なる操作に対する時間複雑度を概説しています。

表中のconstantは、入力サイズに変化しない定数時間のコストを表し、proportionalは、入力サイズに比例して増加する変動コストを表します。N/Aは、そのコストが適用されないことを意味します。
JSベースのパーサーは、JavaScript環境内で完全に動作するため、FFIやserdeのオーバーヘッドを回避します。その性能は、入力ファイルのサイズに応じてスケールする解析時間にのみ依存します。
Rustベースのパーサーの性能は、固定のFFIオーバーヘッドと入力サイズに応じて増加する解析時間に影響されます。しかし、そのserdeオーバーヘッドは、実装によって異なります。
ast-grepとtree-sitterは、入力サイズに関係なく、一つのツリーオブジェクトの固定のシリアライズコストを持っています。
swcとoxcは、入力サイズに比例して増加するシリアライズとデシリアライズのコストを持ち、全体的な性能に影響を与えます。
議論
変換 vs. 解析
Rustベースのツールは、コードをトランスパイルする速さで有名ですが、このベンチマークでは、JavaScriptで使えるASTにコードを変換するときには別の物語が明らかになります。
この食い違いは、Rustツールの作者にとって重要な考慮事項を浮き彫りにします。Rustのデータ構造をJavaScriptに渡すプロセスは、複雑なタスクであり、性能に大きな影響を与える可能性があります。
Rustツールから期待される高い効率を維持するためには、このデータ交換を最適化することが不可欠です。
パーサーの選択基準
この記事のベンチマークでは、JavaScriptのAPIを提供するパーサーに焦点を当てました。これは選択に影響を与えました。
- Sucrase: パーシングAPIがなく、完全なASTを生成できないという理由で除外されました。これらは、私たちの評価基準にとって重要です。
- Esbuild/Biome: esbuildは主にバンドラーとして機能し、スタンドアロンのパーサーではないため、含まれませんでした。変換やビルドの機能を提供しますが、ASTをJavaScriptに公開しません。同様に、biomeはJavaScriptのAPIを持たないCLIアプリケーションです。
- Esprima: TypeScriptのサポートがないため、このベンチマークでは考慮されませんでした。これは、現代のJavaScript開発エコシステムにとって重要な要件です。
以下は、英語から日本語への技術記事の翻訳の続きです。
JSパーサーについて
Babel:
Babelは、@babel/coreと@babel/parserの2つの主要なパッケージに分かれています。@babel/coreの性能が@babel/parserよりも低いことに注目です。コアパッケージのパーサーを取り巻く追加のエントリーとフックコードのためです。さらに、BabelコアのparseAsync関数は本当に非同期ではありません。非同期関数でラップされた同期的なパーサーメソッドにすぎません。このラッパーは、追加のフックを提供しますが、JavaScriptのシングルスレッドの性質のため、CPU集中的なタスクの性能を向上させることはありません。実際、非同期タスクの管理にかかるオーバーヘッドは、@babel/coreの性能にさらなる負担をかける可能性があります。
TypeScript:
TypeScriptのパーシング能力は、TypeScriptコンパイラ(TSC)が遅いという一般的な認識に反します。ベンチマークの結果は、TSCの主なボトルネックは解析ではなく、その後の型チェックのフェーズにあることを示唆しています。
ネイティブパーサーについて
SWC:
最初にその名を知らしめたRustパーサーであるSWCは、JavaScriptで使えるようにAST全体をシリアライズするという直接的なアプローチを採用しています。広範囲のAPIを提供することで、Rustベースのツールソリューションを求める人々にとって最適な選択肢となっています。いくつかの固有のオーバーヘッドにもかかわらず、SWCの堅牢性と先駆者としての地位は、引き続き好ましいオプションとなっています。
Oxc:
Oxcは、利用可能な最速のパーサーのタイトルを争う存在ですが、その性能はシリアライズとデシリアライズ(serde)のオーバーヘッドによって減速されます。私たちのベンチマークにJSONパーシングを含めたのは、実際の使用法を反映したものですが、このステップを省略すれば、Oxcの速度は大幅に向上する可能性があります。
Tree-sitter
Tree-sitterは、TypeScriptに特化したわけではない、さまざまな言語に適した汎用的なパーサーとして機能します。その結果、性能はJavaScriptで実装されたJavaScriptに焦点を当てたパーサーであるBabelとほぼ同じになります。残念ながら、Rustパーサーは、N-APIのオーバーヘッドがなくても、必ずしも速いとは限りません。
Rustで作られた汎用的なパーサーは、JavaScriptで慎重に手作りされたパーサーに勝てないかもしれませんね。
ast-grep
ast-grepはtree-sitterによって駆動されています。その性能はtree-sitterよりもわずかに速く、napi.rsがC++のnan.hを使った手動のバインディングよりも速いことを示しています。
性能の向上がnapiからなのかnapi.rsからなのかはわかりませんが、
結果は実装の有効性を物語っています。さすがBroooooklyn氏!
ネイティブパーサーの性能のコツ
tree-sitterとast-grepの優位性
これらのパーサーは、解析後にRustオブジェクトのラッパーをNode.jsに返すことで、serdeのコストを回避しています。この戦略は効率的ですが、コストが読み取りフェーズに分散されるため、JavaScriptでのASTへのアクセスが遅くなる可能性があります。
ast-grepの非同期の利点:
ast-grepの性能は、同時に複数のパーシングを行うシナリオでは、libuvのスレッドを複数利用していることが大きな要因です。デフォルトでは、libuvのスレッドプールのサイズは4に設定されていますが、スレッドプールのサイズを拡張することで、さらに性能を向上させる可能性があります。これにより、利用可能なCPUコアを最大限に活用できます。
将来の展望
将来に向けて、TypeScriptパーサーの性能をさらに洗練させる有望な方向性がいくつかあります。
-
Serdeオーバーヘッドの最小化: シリアライズとデシリアライズのプロセスを最適化することで、例えばRustオブジェクトのラッパーを利用することで、これらの操作が引き起こす性能の低下を減らすことができます。
-
マルチコアの能力の活用: マルチコアアーキテクチャの効果的な利用は、パーシング速度の大幅な向上につながり、ツールの効率性を変えることができます。
-
ASTの再利用の促進: JavaScript内での抽象構文木の再利用を容易にすることで、コストのかかるパーシング操作の頻度を減らすことができます。
-
Rustへのワークロードの移行: ASTノードのクエリに特化したドメイン固有言語(DSL)を作成することで、計算処理の大部分をRust側に移行し、全体的な効率を向上させることができます。
これらの潜在的な改善は、Rustツールのパーシング性能の限界を押し広げる、エキサイティングな機会を表しています。開発者コミュニティにさらに強力なツールを提供するために、革新を続けていきます!
この記事がお役に立ちましたら、ast-grepにスターをつけていただけると嬉しいです!
Discussion
Zennこんにちは、初投稿です。最近日本の開発者の方々がRustをフロントエンドのツールとして使うことに興味があることに気づきました。英語記事の翻訳を投稿しました。
よろしくお願いします。