Next.js で Web Speech API を使ってみる
はじめに
この記事では こちらの Youtube 動画で紹介されている音声認識、翻訳、音声合成を組み合わせたアプリを Next.js で作成します。動画でも説明されていますが、今回利用する Web Speech API(音声認識と音声合成)の API はブラウザで利用できるものの動作が不安定です。なので、実験的に試してみる程度に留めておくのが良いです。
ステップ1 作業用のプロジェクトを作成
作業用に Next.js プロジェクトを作成します。長いので、折り畳んでおきます。
作業用の新規に Next.js プロジェクトを作成します。
プロジェクトの作成
create next-app@latestでプロジェクトを作成します。
$ pnpm create next-app@latest next-speech-recognition-api-sample --typescript --eslint --import-alias "@/*" --src-dir --use-pnpm --tailwind --app
$ cd next-speech-recognition-api-sample
不要な設定を削除し、プロジェクトを初期化します。
stylesの初期化
CSSなどを管理するstylesディレクトリを作成します。globals.cssを移動します。
$ mkdir -p src/styles
$ mv src/app/globals.css src/styles/globals.css
globals.cssの内容を以下のように上書きします。
@tailwind base;
@tailwind components;
@tailwind utilities;
初期ページの初期化
app/page.tsxを上書きします。
import { type FC } from "react";
const Home: FC = () => {
return (
<div className="">
<div className="text-lg font-bold">Home</div>
<div>
<span className="text-blue-500">Hello</span>
<span className="text-red-500">World</span>
</div>
</div>
);
};
export default Home;
レイアウトの初期化
app/layout.tsxを上書きします。
import "@/styles/globals.css";
import { type FC } from "react";
type RootLayoutProps = {
children: React.ReactNode;
};
export const metadata = {
title: "Sample",
description: "Generated by create next app",
};
const RootLayout: FC<RootLayoutProps> = (props) => {
return (
<html lang="ja">
<body className="">{props.children}</body>
</html>
);
};
export default RootLayout;
TailwindCSSの設定
TailwindCSSの設定を上書きします。
import type { Config } from 'tailwindcss'
const config: Config = {
content: [
'./src/pages/**/*.{js,ts,jsx,tsx,mdx}',
'./src/components/**/*.{js,ts,jsx,tsx,mdx}',
'./src/app/**/*.{js,ts,jsx,tsx,mdx}',
],
plugins: [],
}
export default config
TypeScriptの設定
TypeScriptの設定を上書きします。
{
"compilerOptions": {
"lib": ["dom", "dom.iterable", "esnext"],
"allowJs": true,
"skipLibCheck": true,
"strict": true,
"noEmit": true,
"esModuleInterop": true,
"module": "esnext",
"moduleResolution": "bundler",
"resolveJsonModule": true,
"isolatedModules": true,
"jsx": "preserve",
"incremental": true,
"baseUrl": ".",
"plugins": [
{
"name": "next"
}
],
"paths": {
"@/*": ["./src/*"]
}
},
"include": ["next-env.d.ts", "**/*.ts", "**/*.tsx", ".next/types/**/*.ts"],
"exclude": ["node_modules"]
}
スクリプトを追加
型チェックのスクリプトを追加します。
{
"scripts": {
+ "typecheck": "tsc"
},
}
動作確認
型チェックします。
$ pnpm run typecheck
ローカルで動作確認します。
$ pnpm run dev
コミットして作業結果を保存しておきます。
$ git add .
$ git commit -m "作業用のプロジェクトを作成"
ステップ2 設定ファイル作成と翻訳コンポーネント作成
翻訳対象の言語を参照するため、設定ファイルを作成し、今後利用するコンポーネントの UI を作成します。
設定ファイルの作成
まずは設定ファイルを作成します。
$ mkdir -p src/data
$ touch src/data/country-codes.json src/data/language-codes.json
設定ファイルを作成します。
{
"AF": "Afghanistan",
"AX": "Åland Islands",
"AL": "Albania",
"DZ": "Algeria",
"AS": "American Samoa",
"AD": "AndorrA",
"AO": "Angola",
"AI": "Anguilla",
"AQ": "Antarctica",
"AG": "Antigua and Barbuda",
"AR": "Argentina",
"AM": "Armenia",
"AW": "Aruba",
"AU": "Australia",
"AT": "Austria",
"AZ": "Azerbaijan",
"BS": "Bahamas",
"BH": "Bahrain",
"BD": "Bangladesh",
"BB": "Barbados",
"BY": "Belarus",
"BE": "Belgium",
"BZ": "Belize",
"BJ": "Benin",
"BM": "Bermuda",
"BT": "Bhutan",
"BO": "Bolivia",
"BA": "Bosnia and Herzegovina",
"BW": "Botswana",
"BV": "Bouvet Island",
"BR": "Brazil",
"IO": "British Indian Ocean Territory",
"BN": "Brunei Darussalam",
"BG": "Bulgaria",
"BF": "Burkina Faso",
"BI": "Burundi",
"KH": "Cambodia",
"CM": "Cameroon",
"CA": "Canada",
"CV": "Cape Verde",
"KY": "Cayman Islands",
"CF": "Central African Republic",
"TD": "Chad",
"CL": "Chile",
"CN": "China",
"CX": "Christmas Island",
"CC": "Cocos (Keeling) Islands",
"CO": "Colombia",
"KM": "Comoros",
"CG": "Congo",
"CD": "Congo, The Democratic Republic of the",
"CK": "Cook Islands",
"CR": "Costa Rica",
"CI": "Cote D'Ivoire",
"HR": "Croatia",
"CU": "Cuba",
"CY": "Cyprus",
"CZ": "Czech Republic",
"DK": "Denmark",
"DJ": "Djibouti",
"DM": "Dominica",
"DO": "Dominican Republic",
"EC": "Ecuador",
"EG": "Egypt",
"SV": "El Salvador",
"GQ": "Equatorial Guinea",
"ER": "Eritrea",
"EE": "Estonia",
"ET": "Ethiopia",
"FK": "Falkland Islands (Malvinas)",
"FO": "Faroe Islands",
"FJ": "Fiji",
"FI": "Finland",
"FR": "France",
"GF": "French Guiana",
"PF": "French Polynesia",
"TF": "French Southern Territories",
"GA": "Gabon",
"GM": "Gambia",
"GE": "Georgia",
"DE": "Germany",
"GH": "Ghana",
"GI": "Gibraltar",
"GR": "Greece",
"GL": "Greenland",
"GD": "Grenada",
"GP": "Guadeloupe",
"GU": "Guam",
"GT": "Guatemala",
"GG": "Guernsey",
"GN": "Guinea",
"GW": "Guinea-Bissau",
"GY": "Guyana",
"HT": "Haiti",
"HM": "Heard Island and Mcdonald Islands",
"VA": "Holy See (Vatican City State)",
"HN": "Honduras",
"HK": "Hong Kong",
"HU": "Hungary",
"IS": "Iceland",
"IN": "India",
"ID": "Indonesia",
"IR": "Iran, Islamic Republic Of",
"IQ": "Iraq",
"IE": "Ireland",
"IM": "Isle of Man",
"IL": "Israel",
"IT": "Italy",
"JM": "Jamaica",
"JP": "Japan",
"JE": "Jersey",
"JO": "Jordan",
"KZ": "Kazakhstan",
"KE": "Kenya",
"KI": "Kiribati",
"KP": "Korea, Democratic People's Republic of",
"KR": "Korea, Republic of",
"KW": "Kuwait",
"KG": "Kyrgyzstan",
"LA": "Lao People's Democratic Republic",
"LV": "Latvia",
"LB": "Lebanon",
"LS": "Lesotho",
"LR": "Liberia",
"LY": "Libyan Arab Jamahiriya",
"LI": "Liechtenstein",
"LT": "Lithuania",
"LU": "Luxembourg",
"MO": "Macao",
"MK": "Macedonia, The Former Yugoslav Republic of",
"MG": "Madagascar",
"MW": "Malawi",
"MY": "Malaysia",
"MV": "Maldives",
"ML": "Mali",
"MT": "Malta",
"MH": "Marshall Islands",
"MQ": "Martinique",
"MR": "Mauritania",
"MU": "Mauritius",
"YT": "Mayotte",
"MX": "Mexico",
"FM": "Micronesia, Federated States of",
"MD": "Moldova, Republic of",
"MC": "Monaco",
"MN": "Mongolia",
"MS": "Montserrat",
"MA": "Morocco",
"MZ": "Mozambique",
"MM": "Myanmar",
"NA": "Namibia",
"NR": "Nauru",
"NP": "Nepal",
"NL": "Netherlands",
"AN": "Netherlands Antilles",
"NC": "New Caledonia",
"NZ": "New Zealand",
"NI": "Nicaragua",
"NE": "Niger",
"NG": "Nigeria",
"NU": "Niue",
"NF": "Norfolk Island",
"MP": "Northern Mariana Islands",
"NO": "Norway",
"OM": "Oman",
"PK": "Pakistan",
"PW": "Palau",
"PS": "Palestinian Territory, Occupied",
"PA": "Panama",
"PG": "Papua New Guinea",
"PY": "Paraguay",
"PE": "Peru",
"PH": "Philippines",
"PN": "Pitcairn",
"PL": "Poland",
"PT": "Portugal",
"PR": "Puerto Rico",
"QA": "Qatar",
"RE": "Reunion",
"RO": "Romania",
"RU": "Russian Federation",
"RW": "RWANDA",
"SH": "Saint Helena",
"KN": "Saint Kitts and Nevis",
"LC": "Saint Lucia",
"PM": "Saint Pierre and Miquelon",
"VC": "Saint Vincent and the Grenadines",
"WS": "Samoa",
"SM": "San Marino",
"ST": "Sao Tome and Principe",
"SA": "Saudi Arabia",
"SN": "Senegal",
"CS": "Serbia and Montenegro",
"SC": "Seychelles",
"SL": "Sierra Leone",
"SG": "Singapore",
"SK": "Slovakia",
"SI": "Slovenia",
"SB": "Solomon Islands",
"SO": "Somalia",
"ZA": "South Africa",
"GS": "South Georgia and the South Sandwich Islands",
"ES": "Spain",
"LK": "Sri Lanka",
"SD": "Sudan",
"SR": "Suriname",
"SJ": "Svalbard and Jan Mayen",
"SZ": "Swaziland",
"SE": "Sweden",
"CH": "Switzerland",
"SY": "Syrian Arab Republic",
"TW": "Taiwan, Province of China",
"TJ": "Tajikistan",
"TZ": "Tanzania, United Republic of",
"TH": "Thailand",
"TL": "Timor-Leste",
"TG": "Togo",
"TK": "Tokelau",
"TO": "Tonga",
"TT": "Trinidad and Tobago",
"TN": "Tunisia",
"TR": "Turkey",
"TM": "Turkmenistan",
"TC": "Turks and Caicos Islands",
"TV": "Tuvalu",
"UG": "Uganda",
"UA": "Ukraine",
"AE": "United Arab Emirates",
"GB": "United Kingdom",
"US": "United States",
"UM": "United States Minor Outlying Islands",
"UY": "Uruguay",
"UZ": "Uzbekistan",
"VU": "Vanuatu",
"VE": "Venezuela",
"VN": "Viet Nam",
"VG": "Virgin Islands, British",
"VI": "Virgin Islands, U.S.",
"WF": "Wallis and Futuna",
"EH": "Western Sahara",
"YE": "Yemen",
"ZM": "Zambia",
"ZW": "Zimbabwe"
}
{
"ab": "Abkhazian",
"aa": "Afar",
"af": "Afrikaans",
"ak": "Akan",
"sq": "Albanian",
"am": "Amharic",
"ar": "Arabic",
"an": "Aragonese",
"hy": "Armenian",
"as": "Assamese",
"av": "Avaric",
"ae": "Avestan",
"ay": "Aymara",
"az": "Azerbaijani",
"bm": "Bambara",
"ba": "Bashkir",
"eu": "Basque",
"be": "Belarusian",
"bn": "Bengali (Bangla)",
"bh": "Bihari",
"bi": "Bislama",
"bs": "Bosnian",
"br": "Breton",
"bg": "Bulgarian",
"my": "Burmese",
"ca": "Catalan",
"ch": "Chamorro",
"ce": "Chechen",
"ny": "Chichewa, Chewa, Nyanja",
"zh": "Chinese",
"zh-Hans": "Chinese (Simplified)",
"zh-Hant": "Chinese (Traditional)",
"cv": "Chuvash",
"kw": "Cornish",
"co": "Corsican",
"cr": "Cree",
"hr": "Croatian",
"cs": "Czech",
"da": "Danish",
"dv": "Divehi, Dhivehi, Maldivian",
"nl": "Dutch",
"dz": "Dzongkha",
"en": "English",
"eo": "Esperanto",
"et": "Estonian",
"ee": "Ewe",
"fo": "Faroese",
"fj": "Fijian",
"fi": "Finnish",
"fr": "French",
"ff": "Fula, Fulah, Pulaar, Pular",
"gl": "Galician",
"gd": "Gaelic (Scottish)",
"ka": "Georgian",
"de": "German",
"el": "Greek",
"kl": "Greenlandic",
"gn": "Guarani",
"gu": "Gujarati",
"ht": "Haitian Creole",
"ha": "Hausa",
"he": "Hebrew",
"hz": "Herero",
"hi": "Hindi",
"ho": "Hiri Motu",
"hu": "Hungarian",
"is": "Icelandic",
"io": "Ido",
"ig": "Igbo",
"id, in": "Indonesian",
"ia": "Interlingua",
"ie": "Interlingue",
"iu": "Inuktitut",
"ik": "Inupiak",
"ga": "Irish",
"it": "Italian",
"ja": "Japanese",
"jv": "Javanese",
"kn": "Kannada",
"kr": "Kanuri",
"ks": "Kashmiri",
"kk": "Kazakh",
"km": "Khmer",
"ki": "Kikuyu",
"rw": "Kinyarwanda (Rwanda)",
"rn": "Kirundi",
"ky": "Kyrgyz",
"kv": "Komi",
"kg": "Kongo",
"ko": "Korean",
"ku": "Kurdish",
"kj": "Kwanyama",
"lo": "Lao",
"la": "Latin",
"lv": "Latvian (Lettish)",
"li": "Limburgish ( Limburger)",
"ln": "Lingala",
"lt": "Lithuanian",
"lu": "Luga-Katanga",
"lg": "Luganda, Ganda",
"lb": "Luxembourgish",
"gv": "Manx",
"mk": "Macedonian",
"mg": "Malagasy",
"ms": "Malay",
"ml": "Malayalam",
"mt": "Maltese",
"mi": "Maori",
"mr": "Marathi",
"mh": "Marshallese",
"mo": "Moldavian",
"mn": "Mongolian",
"na": "Nauru",
"nv": "Navajo",
"ng": "Ndonga",
"nd": "Northern Ndebele",
"ne": "Nepali",
"no": "Norwegian",
"nb": "Norwegian bokmål",
"nn": "Norwegian nynorsk",
"oc": "Occitan",
"oj": "Ojibwe",
"cu": "Old Church Slavonic, Old Bulgarian",
"or": "Oriya",
"om": "Oromo (Afaan Oromo)",
"os": "Ossetian",
"pi": "Pāli",
"ps": "Pashto, Pushto",
"fa": "Persian (Farsi)",
"pl": "Polish",
"pt": "Portuguese",
"pa": "Punjabi (Eastern)",
"qu": "Quechua",
"rm": "Romansh",
"ro": "Romanian",
"ru": "Russian",
"se": "Sami",
"sm": "Samoan",
"sg": "Sango",
"sa": "Sanskrit",
"sr": "Serbian",
"sh": "Serbo-Croatian",
"st": "Sesotho",
"tn": "Setswana",
"sn": "Shona",
"ii": "Sichuan Yi",
"sd": "Sindhi",
"si": "Sinhalese",
"sk": "Slovak",
"sl": "Slovenian",
"so": "Somali",
"nr": "Southern Ndebele",
"es": "Spanish",
"su": "Sundanese",
"sw": "Swahili (Kiswahili)",
"ss": "Swati",
"sv": "Swedish",
"tl": "Tagalog",
"ty": "Tahitian",
"tg": "Tajik",
"ta": "Tamil",
"tt": "Tatar",
"te": "Telugu",
"th": "Thai",
"bo": "Tibetan",
"ti": "Tigrinya",
"to": "Tonga",
"ts": "Tsonga",
"tr": "Turkish",
"tk": "Turkmen",
"tw": "Twi",
"ug": "Uyghur",
"uk": "Ukrainian",
"ur": "Urdu",
"uz": "Uzbek",
"ve": "Venda",
"vi": "Vietnamese",
"vo": "Volapük",
"wa": "Wallon",
"cy": "Welsh",
"wo": "Wolof",
"fy": "Western Frisian",
"xh": "Xhosa",
"yi": "Yiddish",
"ji": "Yiddish",
"yo": "Yoruba",
"za": "Zhuang, Chuang",
"zu": "Zulu"
}
翻訳コンポーネントの作成
続いて、翻訳コンポーネントを作成します。
$ mkdir -p src/components/
$ touch src/components/Translation.tsx
"use client";
const Translator = () => {
const isActive = false;
const isSpeechDetected = false;
const language = 'ja-JP';
return (
<div className="mt-12 px-4">
<div className="max-w-lg rounded-xl overflow-hidden mx-auto">
<div className="bg-zinc-200 p-4 border-b-4 border-zinc-300">
<div className="bg-blue-200 rounded-lg p-2 border-2 border-blue-300">
<ul className="font-mono font-bold text-blue-900 uppercase px-4 py-2 border border-blue-800 rounded">
<li>
> Translation Mode:
</li>
<li>
> Dialect:
</li>
</ul>
</div>
</div>
<div className="bg-zinc-800 p-4 border-b-4 border-zinc-950">
<p className="flex items-center gap-3">
<span className={`block rounded-full w-5 h-5 flex-shrink-0 flex-grow-0 ${isActive ? 'bg-red-500' : 'bg-red-900'} `}>
<span className="sr-only">{ isActive ? 'Actively recording' : 'Not actively recording' }</span>
</span>
<span className={`block rounded w-full h-5 flex-grow-1 ${isSpeechDetected ? 'bg-green-500' : 'bg-green-900'}`}>
<span className="sr-only">{ isSpeechDetected ? 'Speech is being recorded' : 'Speech is not being recorded' }</span>
</span>
</p>
</div>
<div className="bg-zinc-800 p-4">
<div className="grid sm:grid-cols-2 gap-4 max-w-lg bg-zinc-200 rounded-lg p-5 mx-auto">
<form>
<div>
<label className="block text-zinc-500 text-[.6rem] uppercase font-bold mb-1">Language</label>
<select className="w-full text-[.7rem] rounded-sm border-zinc-300 px-2 py-1 pr-7" name="language">
<option value="en-US">
English (en-US)
</option>
</select>
</div>
</form>
<p>
<button
className={`w-full h-full uppercase font-semibold text-sm ${isActive ? 'text-white bg-red-500' : 'text-zinc-400 bg-zinc-900'} color-white py-3 rounded-sm`}
>
{ isActive ? 'Stop' : 'Record' }
</button>
</p>
</div>
</div>
</div>
<div className="max-w-lg mx-auto mt-12">
<p className="mb-4">
Spoken Text:
</p>
<p>
Translation:
</p>
</div>
</div>
)
}
export default Translator;
page.tsx と layout.tsx を更新します。
import Translator from "@/components/Translation";
import { type FC } from "react";
const Home: FC = () => {
return (
<main>
<Translator />
</main>
);
};
export default Home;
import "@/styles/globals.css";
import { type FC } from "react";
type RootLayoutProps = {
children: React.ReactNode;
};
export const metadata = {
title: "翻訳",
description: "翻訳アプリです",
};
const RootLayout: FC<RootLayoutProps> = (props) => {
return (
<html lang="ja">
<body className="">{props.children}</body>
</html>
);
};
export default RootLayout;
動作確認
ローカルで動作確認します。現時点ではボタンを押しても特に何も起きません。
$ pnpm run dev
コミットします。
$ git add .
$ git commit -m "設定ファイル作成と翻訳コンポーネント作成"
ステップ3 音声認識機能を追加
音声認識機能を追加します。
Speech Recogiition API とは
Speech Recognition API は音声認識するための API です。ブラウザ上で音声認識できます。
Speech Recognition API は現状、ブラウザでのサポートは限定的です。全てのブラウザで対応はしていないので利用には注意が必要です。
型を追加
@types/dom-speech-recognitionをインストールします。
$ pnpm add -D @types/dom-speech-recognition
参考までに @types/dom-speech-recognition を入れない場合タイプエラーになります。

Property 'SpeechRecognition' does not exist on type 'Window & typeof globalThis'.ts(2339)
音声認識機能の追加
Translation.tsx を更新します。
+import { useState } from "react";
const Translator = () => {
+ // 認識されたテキストを保存するための state
+ const [text, setText] = useState<string>();
+ // 録音を処理する関数
+ function handleOnRecord() {
+ console.log("hello");
+
+ // クロスブラウザ対応のため、SpeechRecognition オブジェクトを取得
+ const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
+
+ // Speech Recognition API のインスタンスを生成
+ const recognition = new SpeechRecognition();
+
+ recognition.onresult = async function (event) {
+ // ログとして書き出し中身を確認
+ console.log("event", event);
+
+ // 認識されたテキストを取得
+ const transcript = event.results[0][0].transcript;
+
+ // 認識されたテキストを保存
+ setText(transcript);
+ };
+
+ // 録音を開始します。
+ recognition.start();
+ }
return (
<div className="mt-12 px-4">
<div className="max-w-lg rounded-xl overflow-hidden mx-auto">
<div className="bg-zinc-800 p-4">
<div className="grid sm:grid-cols-2 gap-4 max-w-lg bg-zinc-200 rounded-lg p-5 mx-auto">
<p>
<button
className={`w-full h-full uppercase font-semibold text-sm ${
isActive
? "text-white bg-red-500"
: "text-zinc-400 bg-zinc-900"
} color-white py-3 rounded-sm`}
+ onClick={handleOnRecord}
>
{isActive ? "Stop" : "Record"}
</button>
</p>
</div>
</div>
</div>
<div className="max-w-lg mx-auto mt-12">
- <p className="mb-4">Spoken Text:</p>
+ <p className="mb-4">Spoken Text:{text}</p>
</div>
</div>
);
};
コードを解説します。
クロスブラウザの対応するために以下のように記述しています。
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
Speech Recognition API のインスタンスを生成します。
const recognition = new SpeechRecognition();
ボタンを押すと、録音が開始されます。ブラウザ上では、以下のように許可を求められます。
// 録音を開始します。
recognition.start();
コールバック関数を作成してます。コールバック関数が呼び出されるタイミングは、音声認識が終了したときです。コールバック関数では、認識されたテキストを取得して保存します。また、認識されたテキストをログにも書き出しています。
recognition.onresult = async function (event) {
// ログとして書き出し中身を確認
console.log("event", event);
// 認識されたテキストを取得
const transcript = event.results[0][0].transcript;
// 認識されたテキストを保存
setText(transcript);
};
動作確認
ローカルで動作確認します。動作確認には、Chrome を利用してください。
$ pnpm run dev
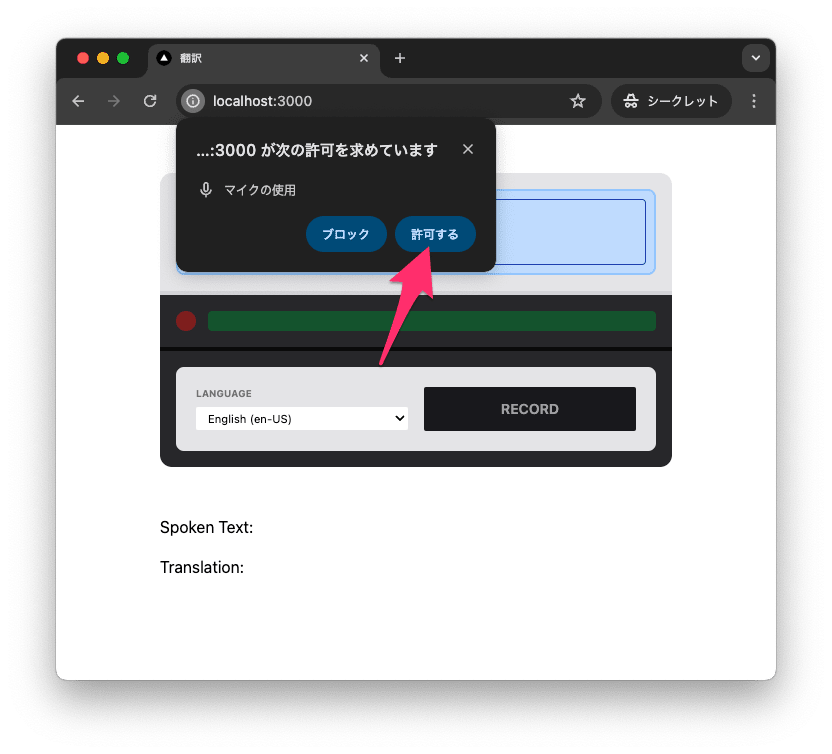
ローカルで実行すると音声認識の許可を求められますが、許可してください。
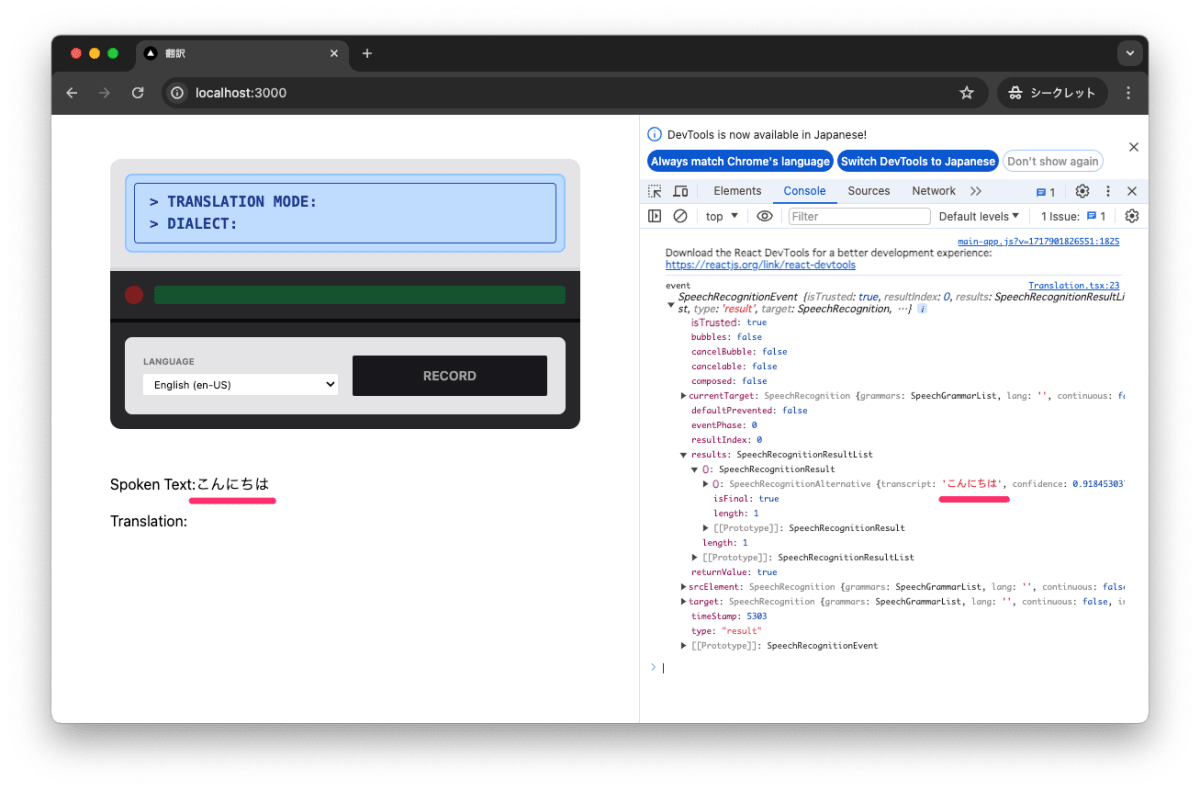
「こんにちは」と話すと、認識されたテキストが表示されます。transcript に認識されたテキスト、confidence に信頼度が表示されます。すごいです。
コミットします。
$ git add .
$ git commit -m "音声認識機能を追加"
ステップ4 翻訳機能を追加
OpenAI の API を利用し、音声認識結果を翻訳する機能を追加します。
OpenAI のパッケージを追加
OpenAI API を利用するため、openai をインストールします。
$ pnpm add openai
OpenAI API キーを取得
OpenAI API キーの取得方法はこちらを参照してください。
環境変数の設定
環境変数に OpenAI キーを追加します。<your-api-key> に自身の API キーを設定してください。
$ touch .env
# OPENAI_API_KEY は OpenAI の API キーです。
OPENAI_API_KEY='<your-api-key>'
$ touch .env.example
# OPENAI_API_KEY は OpenAI の API キーです。
OPENAI_API_KEY='<your-api-key>'
.gitignore に .env を追加します。
+.env
翻訳APIの実装
OpenAI の LLM を利用し、音声認識結果を翻訳する機能を追加します。まずは、Route Handler を利用し、翻訳機能を実装した API を作成します。
$ mkdir -p src/app/api/translate
$ touch src/app/api/translate/route.ts
import { NextResponse } from 'next/server'
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
})
export async function POST(request: Request) {
const { text, language } = await request.json();
console.log(text, language)
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{
"role": "system",
"content": `
# 役割
あなたは入力された文章を翻訳する翻訳アシスタントです。
# タスク
- 入力された文章を${language}に変換します。
- 翻訳した文章以外は返さないでください。
- 以降は入力された文章を翻訳してください。
`
},
{
"role": "user",
"content": text
}
],
temperature: 0.7,
max_tokens: 64,
top_p: 1,
});
return NextResponse.json({
text: response.choices[0].message.content
});
}
翻訳コンポーネントの修正
Translation.tsx を更新し、先程作成した API を利用して音声認識結果を翻訳する機能を追加します。
const Translator = () => {
+ // 翻訳されたテキストを保存するための state
+ const [translation, setTranslation] = useState<string>();
function handleOnRecord() {
recognition.onresult = async function (event) {
// ログとして書き出し中身を確認
console.log("event", event);
// 認識されたテキストを取得
const transcript = event.results[0][0].transcript;
// 認識されたテキストを保存
setText(transcript);
+
+ // 翻訳をリクエストする
+ const results = await fetch("/api/translate", {
+ method: "POST",
+ body: JSON.stringify({
+ text: transcript,
+ language: "en-US",
+ }),
+ }).then((r) => r.json());
+
+ // 翻訳されたテキストを保存
+ setTranslation(results.text);
};
// 録音を開始します。
recognition.start();
}
return (
<div className="mt-12 px-4">
<div className="max-w-lg mx-auto mt-12">
- <p> Translation: </p>
+ <p> Translation: {translation}</p>
</div>
</div>
);
};
動作確認
ローカルで動作確認します。
$ pnpm run dev
コミットします。
$ git add .
$ git commit -m "翻訳機能を追加"
ステップ5 音声合成機能を追加
翻訳したテキストを読み上げる機能を追加します。
SpeechSynthesisUtteranceとは
テキストを読み上げる音声合成の機能として SpeechSynthesisUtterance を利用します。
SpeechSynthesisUtterance とは、音声合成のためのテキストを表すインターフェースです。
ブラウザのサポート情報はこちらです。
音声合成機能の追加
Translation.tsx を更新します。
recognition.onresult = async function (event) {
// ログとして書き出し中身を確認
console.log("event", event);
// 認識されたテキストを取得
const transcript = event.results[0][0].transcript;
// 認識されたテキストを保存
setText(transcript);
// 翻訳をリクエストする
const results = await fetch("/api/translate", {
method: "POST",
body: JSON.stringify({
text: transcript,
language: "en-US",
}),
}).then((r) => r.json());
console.log(results);
// 翻訳されたテキストを保存
setTranslation(results.text);
+ // 翻訳されたテキストを読み上げる
+ const utterance = new SpeechSynthesisUtterance(results.text);
+ window.speechSynthesis.speak(utterance);
};
動作確認
ローカルで動作確認します。
$ pnpm run dev
日本人が英語を読み上げているような感じの音声が出ました。
コミットします。
$ git add .
$ git commit -m "音声合成機能を追加"
ステップ6 音声合成機能を追加
翻訳対象の言語を選択式に変更
ここでは翻訳対象の言語を選択式に変更します。言語ごとに声優も固定で選択するようにします。
"use client";
-import { useState } from "react";
+import { useState, useEffect } from "react";
const Translator = () => {
// 翻訳されたテキストを保存するための state
const [translation, setTranslation] = useState<string>();
+ // 音声合成のための voice を保存するための state
+ const [voices, setVoices] = useState<Array<SpeechSynthesisVoice>>();
+ // 翻訳する言語を保存するための state
+ const [language, setLanguage] = useState<string>("en-US");
// 認識されたテキストを保存するための state
const [text, setText] = useState<string>();
+ // true の場合は録音中、false の場合は録音していない
const isActive = false;
+ // true の場合は音声が認識されている、false の場合は認識されていない
const isSpeechDetected = false;
- const language = "ja-JP";
+ // 利用可能な言語の一覧
+ // [ "ar-001", "bg-BG", "ca-ES", "cs-CZ", ... ]
+ const availableLanguages = Array.from(
+ new Set(voices?.map(({ lang }) => lang))
+ ).sort();
+ // console.log(availableLanguages);
+ // 音声合成に利用する voice を指定の言語から選択
+ // [{default:false, lang:"en-US", localService:true, name:"Aaron", voiceURI:"Aaron"}, {default:false, lang:"en-US", localService:true, name:"Bad News", voiceURI:"Bad News"}, ...]
+ const availableVoices = voices?.filter(({ lang }) => lang === language);
+ // console.log(availableVoices);
+ // 音声合成を行うための voice を選択
+ // Google または Luciana の voice が利用可能な場合はそれを選択
+ // {default:false, lang:"en-US", localService:false, name:"Google US English", voiceURI:"Google US English"}
+ const activeVoice =
+ availableVoices?.find(({ name }) => name.includes("Google")) ||
+ availableVoices?.find(({ name }) => name.includes("Luciana")) ||
+ availableVoices?.[0];
+ // console.log(activeVoice);
+ useEffect(() => {
+ // 音声合成に必要な voice の一覧を取得
+ // https://developer.mozilla.org/en-US/docs/Web/API/SpeechSynthesis/getVoices
+ const voices = window.speechSynthesis.getVoices();
+ // データが存在するか確認し保存
+ if (Array.isArray(voices) && voices.length > 0) {
+ setVoices(voices);
+ return;
+ }
+ // データが存在しない場合は onvoiceschanged イベントを利用して取得
+ if ("onvoiceschanged" in window.speechSynthesis) {
+ window.speechSynthesis.onvoiceschanged = function () {
+ const voices = window.speechSynthesis.getVoices();
+ setVoices(voices);
+ };
+ }
+ }, []);
// 録音を処理する関数
function handleOnRecord() {
// console.log("hello");
// クロスブラウザ対応のため、SpeechRecognition オブジェクトを取得
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
// Speech Recognition API のインスタンスを生成
const recognition = new SpeechRecognition();
recognition.onresult = async function (event) {
// ログとして書き出し中身を確認
// console.log("event", event);
// 認識されたテキストを取得
const transcript = event.results[0][0].transcript;
// 認識されたテキストを保存
setText(transcript);
// 翻訳をリクエストする
const results = await fetch("/api/translate", {
method: "POST",
body: JSON.stringify({
text: transcript,
- language: "en-US",
+ language,
}),
}).then((r) => r.json());
// console.log(results);
// 翻訳されたテキストを保存
setTranslation(results.text);
// 翻訳されたテキストを読み上げる
const utterance = new SpeechSynthesisUtterance(results.text);
+ if (activeVoice) {
+ utterance.voice = activeVoice;
+ }
window.speechSynthesis.speak(utterance);
};
// 録音を開始します。
recognition.start();
}
return (
<div className="mt-12 px-4">
<div className="max-w-lg rounded-xl overflow-hidden mx-auto">
<div className="bg-zinc-200 p-4 border-b-4 border-zinc-300">
<div className="bg-blue-200 rounded-lg p-2 border-2 border-blue-300">
<ul className="font-mono font-bold text-blue-900 uppercase px-4 py-2 border border-blue-800 rounded">
<li>> Translation Mode:</li>
<li>> Dialect:</li>
</ul>
</div>
</div>
<div className="bg-zinc-800 p-4 border-b-4 border-zinc-950">
<p className="flex items-center gap-3">
<span
className={`block rounded-full w-5 h-5 flex-shrink-0 flex-grow-0 ${
isActive ? "bg-red-500" : "bg-red-900"
} `}
>
<span className="sr-only">
{isActive ? "Actively recording" : "Not actively recording"}
</span>
</span>
<span
className={`block rounded w-full h-5 flex-grow-1 ${
isSpeechDetected ? "bg-green-500" : "bg-green-900"
}`}
>
<span className="sr-only">
{isSpeechDetected
? "Speech is being recorded"
: "Speech is not being recorded"}
</span>
</span>
</p>
</div>
<div className="bg-zinc-800 p-4">
<div className="grid sm:grid-cols-2 gap-4 max-w-lg bg-zinc-200 rounded-lg p-5 mx-auto">
<form>
<div>
<label className="block text-zinc-500 text-[.6rem] uppercase font-bold mb-1">
Language
</label>
<select
className="w-full text-[.7rem] rounded-sm border-zinc-300 px-2 py-1 pr-7"
- name="language"
+ value={language}
+ onChange={(event) => {
+ setLanguage(event.currentTarget.value);
+ }}
>
- <option value="en-US">English (en-US)</option>
+ {availableLanguages.map((language) => {
+ return (
+ <option key={language} value={language}>
+ {language}
+ </option>
+ );
+ })}
</select>
</div>
</form>
<p>
<button
className={`w-full h-full uppercase font-semibold text-sm ${
isActive
? "text-white bg-red-500"
: "text-zinc-400 bg-zinc-900"
} color-white py-3 rounded-sm`}
onClick={handleOnRecord}
>
{isActive ? "Stop" : "Record"}
</button>
</p>
</div>
</div>
</div>
<div className="max-w-lg mx-auto mt-12">
<p className="mb-4">Spoken Text:{text}</p>
<p> Translation: {translation}</p>
</div>
</div>
);
};
export default Translator;
コードを解説します。
SpeechSynthesis: getVoices()を利用し、音声合成に必要な voice の一覧を取得します。取得した voice は setVoices で保存します。
// 音声合成のための voice を保存するための state
const [voices, setVoices] = useState<Array<SpeechSynthesisVoice>>();
useEffect(() => {
// 音声合成に必要な voice の一覧を取得
const voices = window.speechSynthesis.getVoices();
// データが存在するか確認し保存
if (Array.isArray(voices) && voices.length > 0) {
setVoices(voices);
return;
}
// データが存在しない場合は onvoiceschanged イベントを利用して取得
if ("onvoiceschanged" in window.speechSynthesis) {
window.speechSynthesis.onvoiceschanged = function () {
const voices = window.speechSynthesis.getVoices();
setVoices(voices);
};
}
}, []);
音声合成可能な言語一覧を利用可能な音声(voices)から取得し availableLanguages に保存します。
// 利用可能な言語の一覧
// [ "ar-001", "bg-BG", "ca-ES", "cs-CZ", ... ]
const availableLanguages = Array.from(
new Set(voices?.map(({ lang }) => lang))
).sort();
// console.log(availableLanguages);
指定された言語に紐づく音声一覧を取得します。
// 翻訳する言語を保存するための state
const [language, setLanguage] = useState<string>("en-US");
// 音声合成に利用する voice を指定の言語から選択
// [{default:false, lang:"en-US", localService:true, name:"Aaron", voiceURI:"Aaron"}, {default:false, lang:"en-US", localService:true, name:"Bad News", voiceURI:"Bad News"}, ...]
const availableVoices = voices?.filter(({ lang }) => lang === language);
// console.log(availableVoices);
音声一覧を更に特定の音声に絞り込みます。今回は Google か Luciana の音声が利用可能な場合はそれを選択し、それ以外は最初の音声を選択します。
// 音声合成を行うための voice を選択
// Google または Luciana の voice が利用可能な場合はそれを選択
// {default:false, lang:"en-US", localService:false, name:"Google US English", voiceURI:"Google US English"}
const activeVoice =
availableVoices?.find(({ name }) => name.includes("Google")) ||
availableVoices?.find(({ name }) => name.includes("Luciana")) ||
availableVoices?.[0];
// console.log(activeVoice);
更に、利用可能な言語を画面から選択可能とします。
return (
<div className="mt-12 px-4">
<div className="max-w-lg rounded-xl overflow-hidden mx-auto">
<div className="bg-zinc-800 p-4">
<div className="grid sm:grid-cols-2 gap-4 max-w-lg bg-zinc-200 rounded-lg p-5 mx-auto">
<form>
<div>
<select
className="w-full text-[.7rem] rounded-sm border-zinc-300 px-2 py-1 pr-7"
value={language}
onChange={(event) => {
setLanguage(event.currentTarget.value);
}}
>
{availableLanguages.map((language) => {
return (
<option key={language} value={language}>
{language}
</option>
);
})}
</select>
</div>
</form>
</div>
</div>
</div>
</div>
);
最後にこれで選択された言語に紐づく音声を利用して音声合成します。
// 翻訳をリクエストする
const results = await fetch("/api/translate", {
method: "POST",
body: JSON.stringify({
text: transcript,
language,
}),
}).then((r) => r.json());
動作確認
動作確認します。
$ pnpm run dev
日本語で「こんにちは」というと、フランス語が選択されているので「Bonjour」と読み上げられます。
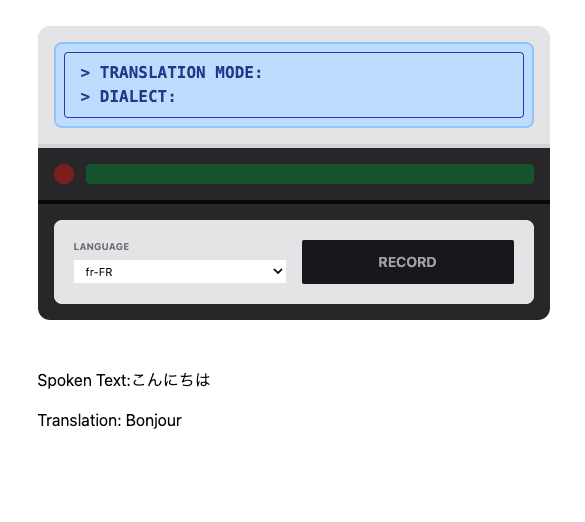
言語は選択式になってます。
コミットします。
$ git add .
$ git commit -m "音声合成機能を追加"
ステップ7 Safari対応
これまで Chrome で動作確認してきましたが、Safari で動作させると動作しません。
具体的には、RECORD ボタンを押すと、マイクは反応しますが動くしません。Safari では収録を終了させないと次のステップへ行けない仕様になっています。つまり、Safari で動作させるためには、収録を終了させる処理を追加する必要があります。
Speed Recognitionを都度インスタンス化
収録ボタンをクリックしたときに、収録を終了させる処理を追加します。具体的には、Speech Recognition を収録ボタン押下時に都度インスタンス化します。
"use client";
-import { useState, useEffect } from "react";
+import { useState, useEffect, useRef } from "react";
const Translator = () => {
+ // Speech Recognition のインスタンス
+ const recognitionRef = useRef<SpeechRecognition>();
// true の場合は録音中、false の場合は録音していない
+ const [isActive, setIsActive] = useState<boolean>(false);
- const isActive = false;
// 録音を処理する関数
function handleOnRecord() {
+ // 録音中の場合は録音を停止
+ if (isActive) {
+ recognitionRef.current?.stop();
+ setIsActive(false);
+ return;
+ }
// console.log("handleOnRecord");
// クロスブラウザ対応のため、SpeechRecognition オブジェクトを取得
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
+ // Speech Recognition API のインスタンスを生成
- const recognition = new SpeechRecognition();
+ recognitionRef.current = new SpeechRecognition();
+ // 収録が開始されると isActive を true に設定
+ recognitionRef.current.onstart = function () {
+ setIsActive(true);
+ };
+ // 収録が終了すると isActive を false に設定
+ recognitionRef.current.onend = function () {
+ setIsActive(false);
+ };
- recognition.onresult = async function (event) {
+ recognitionRef.current.onresult = async function (event) {
// ログとして書き出し中身を確認
// console.log("event", event);
// 認識されたテキストを取得
const transcript = event.results[0][0].transcript;
// 認識されたテキストを保存
setText(transcript);
// 翻訳をリクエストする
const results = await fetch("/api/translate", {
method: "POST",
body: JSON.stringify({
text: transcript,
language,
}),
}).then((r) => r.json());
// console.log(results);
// 翻訳されたテキストを保存
setTranslation(results.text);
// 翻訳されたテキストを読み上げる
const utterance = new SpeechSynthesisUtterance(results.text);
if (activeVoice) {
utterance.voice = activeVoice;
}
window.speechSynthesis.speak(utterance);
};
// 録音を開始します。
- recognition.start();
+ recognitionRef.current.start();
}
};
解説します。
Speech Recognition のインスタンスを useRef を利用して保存します。
// Speech Recognition のインスタンス
const recognitionRef = useRef<SpeechRecognition>();
Speech Recognition のインスタンスには、recognitionRef.current でアクセスできます。
// Speech Recognition API のインスタンスを生成
recognitionRef.current = new SpeechRecognition();
recognitionRef.current.onstart = function () {
setIsActive(true);
};
recognitionRef.current.onend = function () {
setIsActive(false);
};
recognitionRef.current.onresult = async function (event) {
...
};
// 録音を開始します。
recognitionRef.current.start();
収録ボタンをクリックした際に、Speech Recognition のインスタンスを生成し、recognitionRef.current に保存しています。
// Speech Recognition のインスタンス
const recognitionRef = useRef<SpeechRecognition>();
動作確認
動作確認します。
$ pnpm run dev
Safari で動作確認すると、動作が不安定ですが動作はします。まだ Safari では安定した利用は難しそうです。
これを Vercel にデプロイして実行すると、収録ボタンをクリックして発音しも音声認識されません。なぜならば、Speech Recognition API はユーザーからのインタラクションがないと動作しないためです。現状はコールバックとして動作させていますが理想的な動作方法ではありません。
コミットします。
$ git add .
$ git commit -m "Safari対応"
ステップ8 モバイル対応
ここではモバイルで動作するように設定します。(が、実際に動画で記載されていた通り実装しましたが、モバイルでの動作は確認できませんでした。)
コードの修正
"use client";
import { useState, useEffect, useRef } from "react";
const Translator = () => {
// 録音を処理する関数
function handleOnRecord() {
// console.log("handleOnRecord");
// 録音中の場合は録音を停止
if (isActive) {
recognitionRef.current?.stop();
setIsActive(false);
return;
}
+ speak(" ");
// クロスブラウザ対応のため、SpeechRecognition オブジェクトを取得
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
// Speech Recognition API のインスタンスを生成
recognitionRef.current = new SpeechRecognition();
// 収録が開始されると isActive を true に設定
recognitionRef.current.onstart = function () {
setIsActive(true);
};
// 収録が終了すると isActive を false に設定
recognitionRef.current.onend = function () {
setIsActive(false);
};
recognitionRef.current.onresult = async function (event) {
// ログとして書き出し中身を確認
// console.log("event", event);
// 認識されたテキストを取得
const transcript = event.results[0][0].transcript;
// 認識されたテキストを保存
setText(transcript);
// 翻訳をリクエストする
const results = await fetch("/api/translate", {
method: "POST",
body: JSON.stringify({
text: transcript,
language,
}),
}).then((r) => r.json());
// console.log(results);
// 翻訳されたテキストを保存
setTranslation(results.text);
// 翻訳されたテキストを読み上げる
- const utterance = new SpeechSynthesisUtterance(results.text);
- if (activeVoice) {
- utterance.voice = activeVoice;
- }
- window.speechSynthesis.speak(utterance);
+ speak(results.text);
};
// 録音を開始します。
recognitionRef.current.start();
}
+ // 翻訳されたテキストを読み上げる
+ function speak(text: string) {
+ const utterance = new SpeechSynthesisUtterance(text);
+ if (activeVoice) {
+ utterance.voice = activeVoice;
+ }
+ window.speechSynthesis.speak(utterance);
+ }
return (
<div className="mt-12 px-4">
<div className="max-w-lg rounded-xl overflow-hidden mx-auto">
<div className="bg-zinc-200 p-4 border-b-4 border-zinc-300">
<div className="bg-blue-200 rounded-lg p-2 border-2 border-blue-300">
<ul className="font-mono font-bold text-blue-900 uppercase px-4 py-2 border border-blue-800 rounded">
<li>> Translation Mode:</li>
<li>> Dialect:</li>
</ul>
</div>
</div>
<div className="bg-zinc-800 p-4 border-b-4 border-zinc-950">
<p className="flex items-center gap-3">
<span
className={`block rounded-full w-5 h-5 flex-shrink-0 flex-grow-0 ${
isActive ? "bg-red-500" : "bg-red-900"
} `}
>
<span className="sr-only">
{isActive ? "Actively recording" : "Not actively recording"}
</span>
</span>
<span
className={`block rounded w-full h-5 flex-grow-1 ${
isSpeechDetected ? "bg-green-500" : "bg-green-900"
}`}
>
<span className="sr-only">
{isSpeechDetected
? "Speech is being recorded"
: "Speech is not being recorded"}
</span>
</span>
</p>
</div>
<div className="bg-zinc-800 p-4">
<div className="grid sm:grid-cols-2 gap-4 max-w-lg bg-zinc-200 rounded-lg p-5 mx-auto">
<form>
<div>
<label className="block text-zinc-500 text-[.6rem] uppercase font-bold mb-1">
Language
</label>
<select
className="w-full text-[.7rem] rounded-sm border-zinc-300 px-2 py-1 pr-7"
value={language}
onChange={(event) => {
setLanguage(event.currentTarget.value);
}}
>
{availableLanguages.map((language) => {
return (
<option key={language} value={language}>
{language}
</option>
);
})}
</select>
</div>
</form>
<p>
<button
className={`w-full h-full uppercase font-semibold text-sm ${
isActive
? "text-white bg-red-500"
: "text-zinc-400 bg-zinc-900"
} color-white py-3 rounded-sm`}
onClick={handleOnRecord}
>
{isActive ? "Stop" : "Record"}
</button>
</p>
</div>
</div>
</div>
<div className="max-w-lg mx-auto mt-12">
<p className="mb-4">Spoken Text:{text}</p>
<p> Translation: {translation}</p>
</div>
</div>
);
};
export default Translator;
解説します。
音声合成機能を関数化しました。
// 翻訳されたテキストを読み上げる
function speak(text: string) {
const utterance = new SpeechSynthesisUtterance(text);
if (activeVoice) {
utterance.voice = activeVoice;
}
window.speechSynthesis.speak(utterance);
}
クリック時に音声合成機能を呼び出します。
speak(" ");
動作確認
動作確認します。
$ pnpm run dev
モバイルで動作確認します。実際に Safari 上だと動作が安定しません。
コミットします。
$ git add .
$ git commit -m "モバイル対応"
ステップ8 言語・方言を表示
ここでは言語と方言を表示するようにします。
言語と方言のデータを可視化
言語と方言のデータを可視化します。
"use client";
import { useState, useEffect, useRef } from 'react';
+import { default as languageCodesData } from '@/data/language-codes.json';
+import { default as countryCodesData } from '@/data/country-codes.json';
+const languageCodes: Record<string, string> = languageCodesData;
+const countryCodes: Record<string, string> = countryCodesData;
const Translator = () => {
const recognitionRef = useRef<SpeechRecognition>();
const [isActive, setIsActive] = useState<boolean>(false);
const [text, setText] = useState<string>();
const [translation, setTranslation] = useState<string>();
const [voices, setVoices] = useState<Array<SpeechSynthesisVoice>>();
const [language, setLanguage] = useState<string>('pt-BR');
const isSpeechDetected = false;
- const availableLanguages = Array.from(
- new Set(voices?.map(({ lang }) => lang))
- ).sort();
+ const availableLanguages = Array.from(new Set(voices?.map(({ lang }) => lang)))
+ .map(lang => {
+ const split = lang.split('-');
+ const languageCode: string = split[0];
+ const countryCode: string = split[1];
+ return {
+ lang,
+ label: languageCodes[languageCode] || lang,
+ dialect: countryCodes[countryCode]
+ }
+ })
+ .sort((a, b) => a.label.localeCompare(b.label));
+ const activeLanguage = availableLanguages.find(({ lang }) => language === lang);
const availableVoices = voices?.filter(({ lang }) => lang === language);
const activeVoice =
availableVoices?.find(({ name }) => name.includes('Google'))
|| availableVoices?.find(({ name }) => name.includes('Luciana'))
|| availableVoices?.[0];
useEffect(() => {
const voices = window.speechSynthesis.getVoices();
if ( Array.isArray(voices) && voices.length > 0 ) {
setVoices(voices);
return;
}
if ( 'onvoiceschanged' in window.speechSynthesis ) {
window.speechSynthesis.onvoiceschanged = function() {
const voices = window.speechSynthesis.getVoices();
setVoices(voices);
}
}
}, []);
function handleOnRecord() {
if ( isActive ) {
recognitionRef.current?.stop();
setIsActive(false);
return;
}
speak(' ');
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
recognitionRef.current = new SpeechRecognition();
recognitionRef.current.onstart = function() {
setIsActive(true);
}
recognitionRef.current.onend = function() {
setIsActive(false);
}
recognitionRef.current.onresult = async function(event) {
const transcript = event.results[0][0].transcript;
setText(transcript);
const results = await fetch('/api/translate', {
method: 'POST',
body: JSON.stringify({
text: transcript,
language: 'pt-BR'
})
}).then(r => r.json());
setTranslation(results.text);
speak(results.text);
}
recognitionRef.current.start();
}
function speak(text: string) {
const utterance = new SpeechSynthesisUtterance(text);
if ( activeVoice ) {
utterance.voice = activeVoice;
};
window.speechSynthesis.speak(utterance);
}
return (
<div className="mt-12 px-4">
<div className="max-w-lg rounded-xl overflow-hidden mx-auto">
<div className="bg-zinc-200 p-4 border-b-4 border-zinc-300">
<div className="bg-blue-200 rounded-lg p-2 border-2 border-blue-300">
<ul className="font-mono font-bold text-blue-900 uppercase px-4 py-2 border border-blue-800 rounded">
<li>
- > Translation Mode:
+ > Translation Mode: { activeLanguage?.label }
</li>
<li>
- > Dialect:
+ > Dialect: { activeLanguage?.dialect }
</li>
</ul>
</div>
</div>
<div className="bg-zinc-800 p-4 border-b-4 border-zinc-950">
<p className="flex items-center gap-3">
<span className={`block rounded-full w-5 h-5 flex-shrink-0 flex-grow-0 ${isActive ? 'bg-red-500' : 'bg-red-900'} `}>
<span className="sr-only">{ isActive ? 'Actively recording' : 'Not actively recording' }</span>
</span>
<span className={`block rounded w-full h-5 flex-grow-1 ${isSpeechDetected ? 'bg-green-500' : 'bg-green-900'}`}>
<span className="sr-only">{ isSpeechDetected ? 'Speech is being recorded' : 'Speech is not being recorded' }</span>
</span>
</p>
</div>
<div className="bg-zinc-800 p-4">
<div className="grid sm:grid-cols-2 gap-4 max-w-lg bg-zinc-200 rounded-lg p-5 mx-auto">
<form>
<div>
<label className="block text-zinc-500 text-[.6rem] uppercase font-bold mb-1">Language</label>
<select className="w-full text-[.7rem] rounded-sm border-zinc-300 px-2 py-1 pr-7" name="language" value={language} onChange={(event) => {
setLanguage(event.currentTarget.value);
}}>
- {availableLanguages.map((language) => {
- return (
- <option key={language} value={language}>
- {language}
- </option>
- );
- })}
+ {availableLanguages.map(({ lang, label }) => {
+ return (
+ <option key={lang} value={lang}>
+ { label } ({ lang })
+ </option>
+ )
+ })}
</select>
</div>
</form>
<p>
<button
className={`w-full h-full uppercase font-semibold text-sm ${isActive ? 'text-white bg-red-500' : 'text-zinc-400 bg-zinc-900'} color-white py-3 rounded-sm`}
onClick={handleOnRecord}
>
{ isActive ? 'Stop' : 'Record' }
</button>
</p>
</div>
</div>
</div>
<div className="max-w-lg mx-auto mt-12">
<p className="mb-4">
Spoken Text: { text }
</p>
<p>
Translation: { translation }
</p>
</div>
</div>
)
}
export default Translator;
動作確認
動作確認します。
$ pnpm run dev
言語と方言が表示されます。
コミットします。
$ git add .
$ git commit -m "言語・方言を表示"
まとめ
この記事では こちらの Youtube 動画で紹介されている音声認識、翻訳、音声合成を組み合わせたアプリを Next.js で作成しました。動画でも説明されていますが、今回利用する音声認識と翻訳の API はブラウザで利用できるものの動作が不安定です。なので、実験的に試してみる程度に留めておくのが良いです。
私が作業したリポジトリはこちらです。
Discussion