Node.jsでバイナリ量子化してMongoDB Atlas Vector Searchのメモリ消費を24倍削減する
MongoDB Atlas Vector Searchでベクトル検索を実装するとき、embeddingをそのまま保存していくとメモリを大きく消費してしまう
1536次元のembeddingをdouble(倍精度浮動小数点数)配列のまま保存すると、3000件のembeddingで18MB消費する

embeddingは検索用途のためキャッシュに載せたいけど、1件あたり6kBかかるのは大きすぎる
MongoDB Atlas Vector Searchがベクトル量子化をサポートした
2024年10月から12月にかけて、MongoDB Atlas Vector Searchでもベクトル量子化がサポートされるようになった
特にバイナリ量子化を適用すれば、検索精度を95%保ちながらメモリ消費量を24分の1に削減できる
既存のembeddingを全件データマイグレーションして、バイナリ量子化を適用することにした
事前準備 MongoDB Node.js Driver v6.12.0以降にアップグレード
2024年12月10日にリリースされたばかりです
Node.jsでバイナリ量子化してMongoDBに保存する
ベクトルの各要素を、doubleから1ビットに変換する
-1 ~ 1の範囲に正規化されたベクトルであれば、しきい値0で量子化する
ちなみにMongoDBのドキュメントによると、0ちょうどの場合は0に変換するらしい
量子化したベクトルを、MongoDB Node.js Driverが提供しているBinary.fromBitsでBinDataのVector subtypeに変換する
ちなみにfromBitsは、2024年11月18日に追加されたばかりの機能のようです
import { Binary } from "mongodb";
export const binaryQuantize = (vector: number[]) =>
Binary.fromBits(vector.map((scalar) => (scalar > 0 ? 1 : 0)));
バイナリ量子化されたBinDataをMongoDBに保存していけば、データマイグレーションできる
データマイグレーションするバッチを実行
私が開発しているアプリでは、インフラとしてGoogle Cloud Run Jobsを使っています
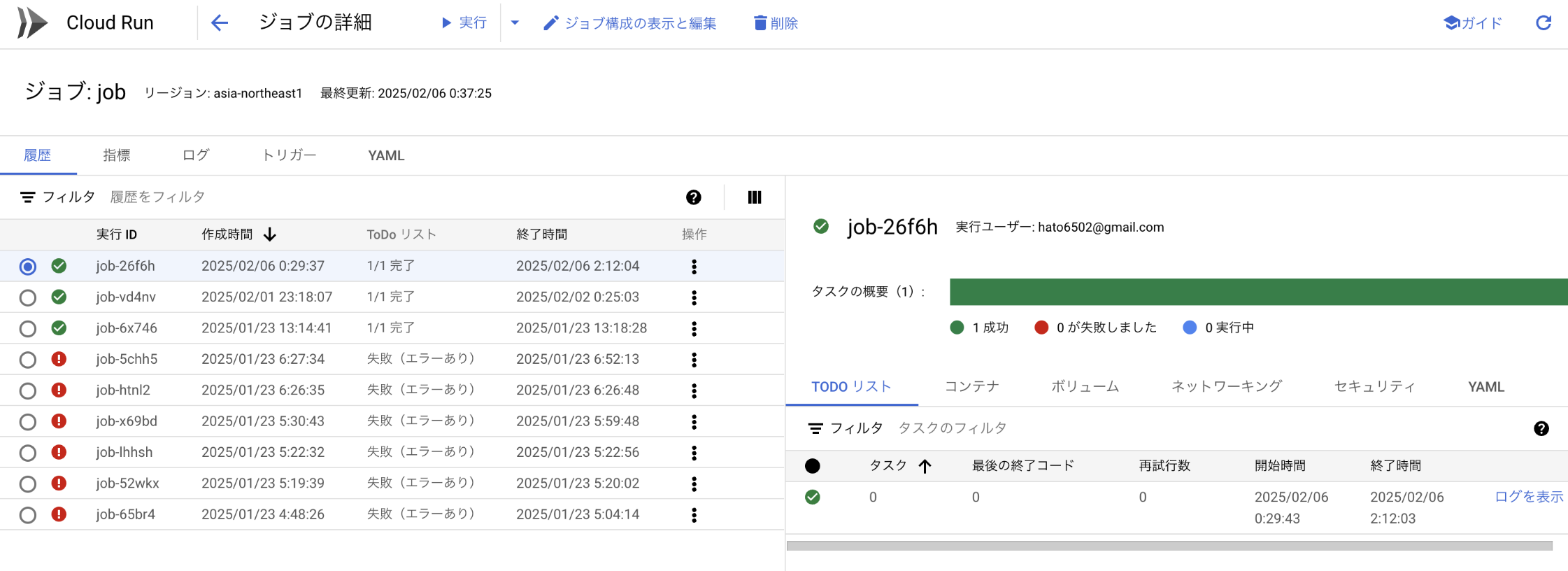
マイグレーション前はdoubleの配列だった

マイグレーション後は無事BinDataになっている
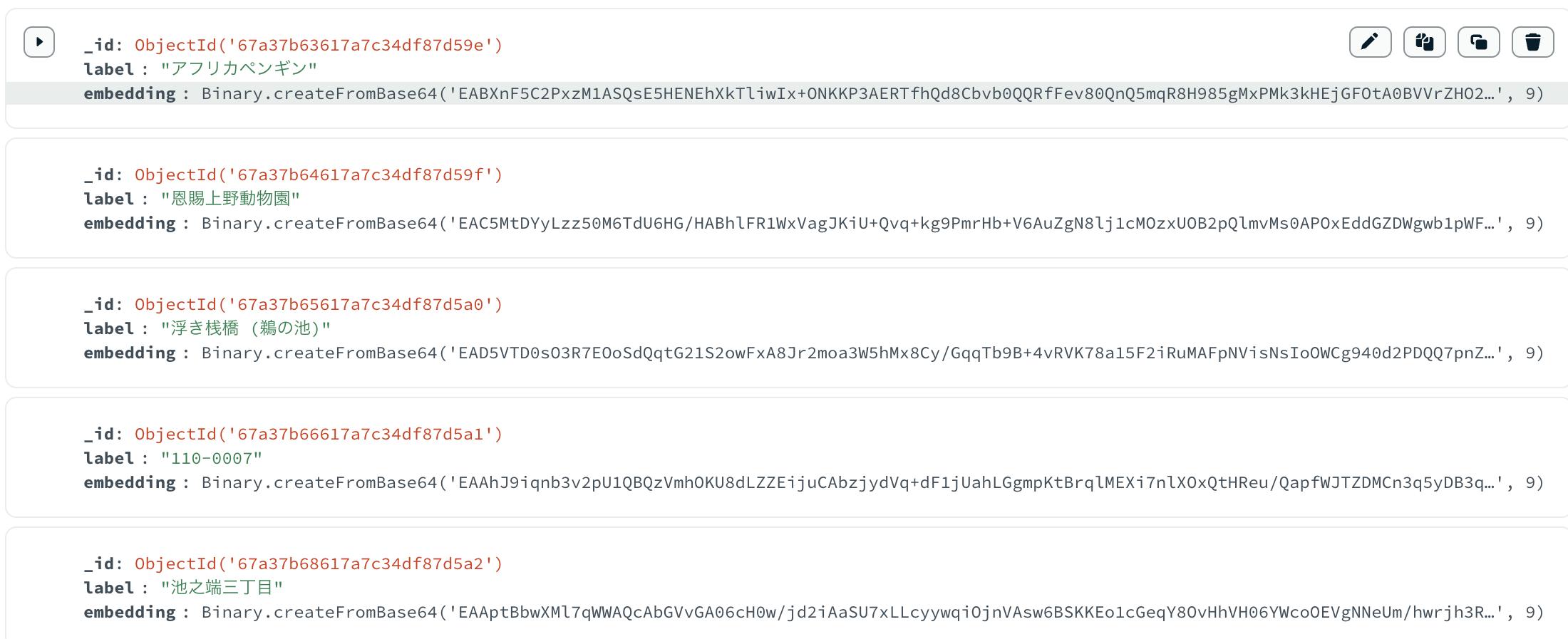
MongoDB Atlasのvector search indexを修正する
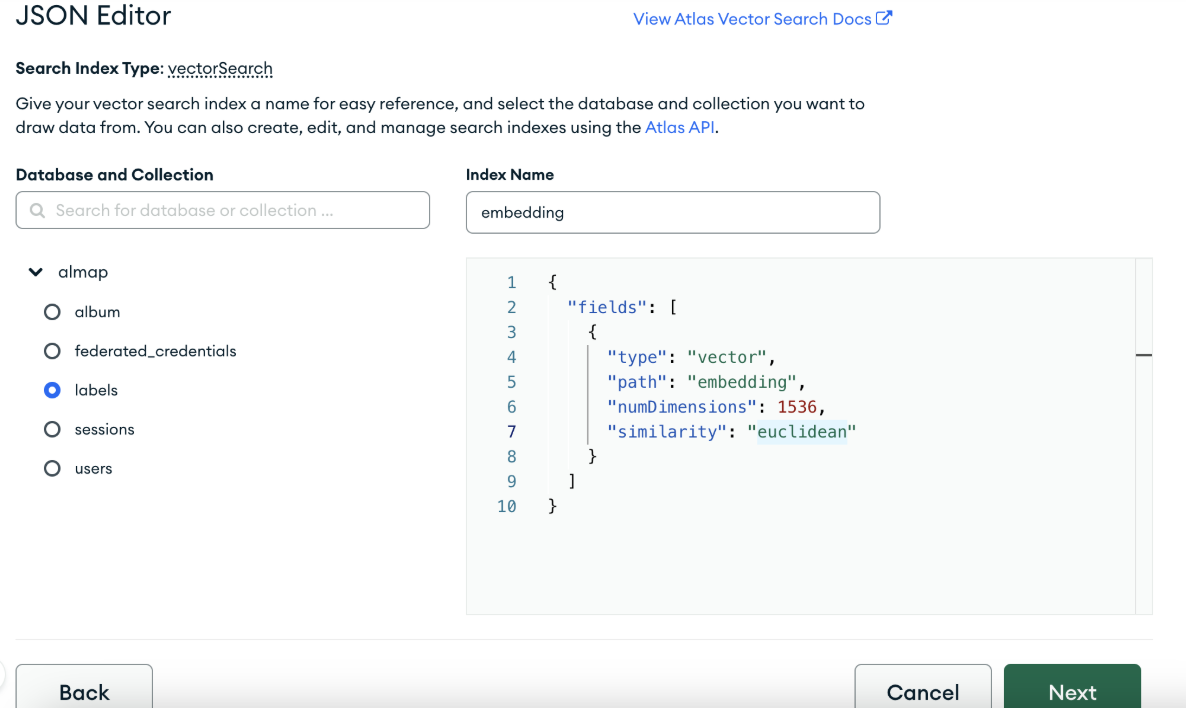
バイナリ量子化を適用した場合、利用できる類似度関数はeuclidean(ユークリッド距離)だけです
いままでsimilarityにcosine(コサイン類似度)を指定していたため、euclideanに修正する
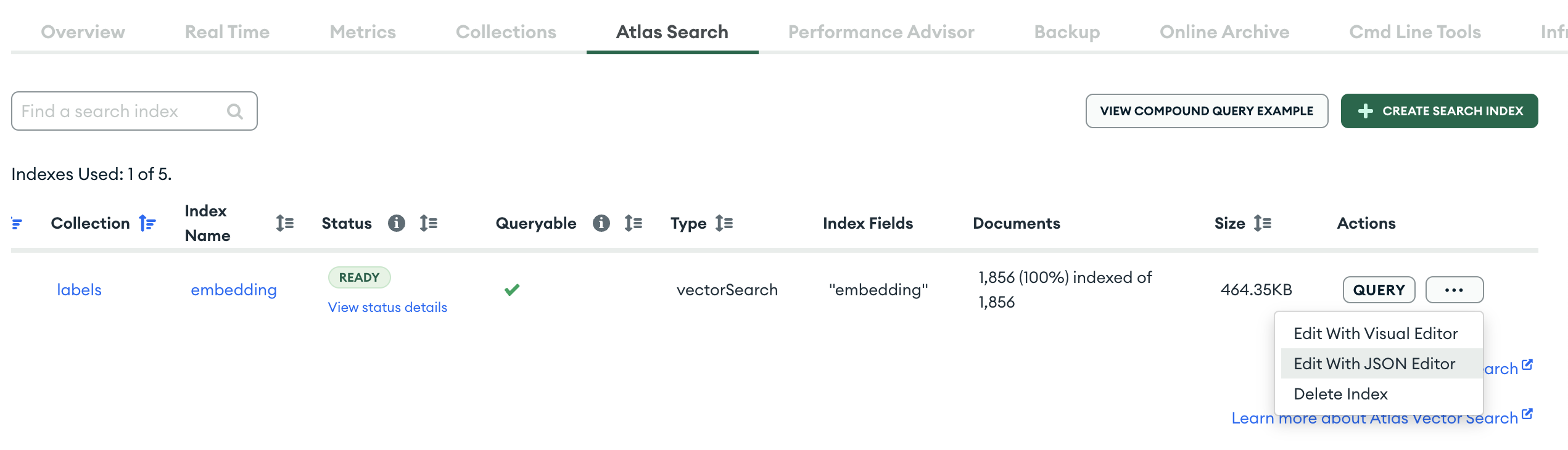
メモリ消費量が24分の1削減された
無事にインデックスが更新され、1850件のembeddingでメモリ消費量は460kBに削減された
embedding1件あたりで計算すると、6kBから0.25kBに削減されている

試しにベクトル検索してみたところ、検索結果への違和感もなさそうだ
Discussion