書籍「機械学習エンジニアのためのTransformers」を読む
概念などを理解することが目的なので、気が向くままに脱線したり chapGPT に聞いて補完したりする。
前書き
transformer は 2017 年に Google が "Attention Is All You Need
" 発表したニューラルネットワークのアーキテクチャ。従来(RNN ベースが主流)の手法を粉砕した
長いデータ列の特徴を捉え、大規模なデータセットを扱うことに優れている。自然言語処理だけでなく画像処理にも応用されている
大きなデータセットを使ってゼロから学習することは、ほとんどのプロジェクトで難しい。そのような場合、事前学習 (pre-trained) したもデールが利用できる。このテクニックは画像処理の世界では 2010 年初頭から主流だったらしい。自然言語処理では、文脈を考慮しない単語埋め込み表現に限定されていた。この状況が 2018 年に変わり、ファインチューニングができるようになった
Hugging Face が公開する「モデルハブ」が、ファインチューニングをより使いやすいものにした。trasformer ライブラリは TensorFlow と PyTorch をサポートし、両方に対応した事前学習済みのモデルを入手でき、そこから自分のタスクに合わせてファインチューニングができるようになる。
trasnformers はモデルの使用を学習のためにいくつかの抽象化レイヤーを提供する
Tokenizer, Model, Trainer API を使えるようになり、モデルを学習できるようになる
Trainer を Acelerate ライブラリ(?) に置き換える方法を紹介する(現時点で意味はよくわからない)
まずは 1, 2章を読んで、あとは興味ある部分をやるとよい、とのこと
RNN の重要な功績は、ある言語の単語列を別の言語に対応付けることを目的とした機械翻訳システムの開発。
参考: Andrej Karpathy blog - The Unreasonable Effectiveness of Recurrent Neural Networks
通常、このようなタスクでは Encoder/Decoder または Seq2seq アーキテクチャで取り込まれる。入力と出力はどちらも任意長の系列である。
Encoder の役目は入力系列を最後の隠れ状態 (last hidden state) にエンコードすること。Decoder は、Encoder が出力した表現を受け取って出力系列の生成を行う。
※たぶん「隠れ状態」は単語埋め込みの話をしていると思われる
Encoder/Decoder の構成要素は、系列をモデル化できるならどんな NN でも大丈夫。

このアーキテクチャは、Encoder の最後の隠れ状態が「情報ボトルネック」になる弱点がある。特に、長い系列を扱う場合に「意味」を扱うことが難しくなってしまう(長い系列を1個の情報に圧縮することが難しい)。最初の状態が失われてしまうことがある。
ここで Attention という技術が利用でき、このボトルネックを解消できる。Attention では、Decoder が Encoder の すべての状態にアクセスできるようにする というもの。

RNN における Attention の開発経緯を理解することで、transformer のアーキテクチャを理解することに役立つ。
transformer では、RNN の再帰性は排除され、かわりに self attention が導入された。
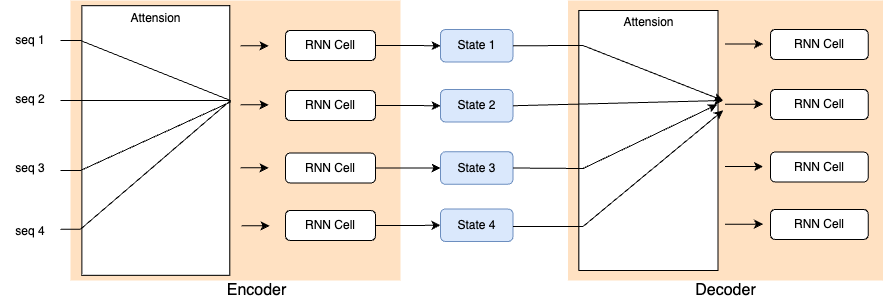
詳しくは、3章で言及。
NLP における転移学習
ULMFiT ではこんな感じになる。
- 出現済みの単語を基に次の単語を予測するタスクを学習(「言語モデル」のタスク)
- ドメイン適応。ターゲットドメインのコーパスに適応させる。ここでは、ターゲットコーパスの次の単語を予測させる
- ファインチューニング。タスクに応じた分類器を用いる
GPT, BERT は TLMFiT の発展形(?)として登場した。Attention と転移学習を組み合わせた transformer
GPT:
transformer アーキテクチャの Decoder 部分のみ使用し、ULMFiT と同じアーキテクチャを採用している
GPT は "BookCorpus" で事前学習されている。
BRET:
transformer アーキテクチャの Encoder 部分と「マスク言語モデル」を使用する。
マスク言語モデルは、テキスト中でランダムにマスクされた単語として最も可能性が高いものを予測する。
BERT は "BookCorpus" と英語版 Wikipedia で事前学習されている。
Fransformer を始める
- PyTorch や TensorFlow をベースとしたモデルアーキテクチャを構築
- 事前学習済みの重みを読み込む(可能である場合)
- 入力を前処理し、モデルから出力を得て、タスクに応じた後処理を施す
- DataLoader を実装し、モデルを学習するための損失関数と Optimizer を定義
各ステップで、モデルやタスクごとにカスタムロジックが必要。ここの規格を統一するのが Hugging Face Transformers. タスクに特化したヘッドを提供している(テキスト分類、固有表現認識、質問応答など)ので、簡単にファインチューニングできる。
以下はテキスト分類のトピックであるセンチメント分析を扱ってみる。テキストの生データからセンチメントを抽出する。
以下のコードスニペットは Jupyter notebook で実行している。Google colaboratory や Sagemaker notebook など実行環境は適宜。
from transformers import pipeline
classifier = pipeline("text-classification")
# センチメント分析
import pandas as pd
text = """Bromwell High is a cartoon comedy. It ran at the same time as some other programs about school life, such as "Teachers". My 35 years in the teaching profession lead me to believe that Bromwell High's satire is much closer to reality than is "Teachers". The scramble to survive financially, the insightful students who can see right through their pathetic teachers' pomp, the pettiness of the whole situation, all remind me of the schools I knew and their students. When I saw the episode in which a student repeatedly tried to burn down the school, I immediately recalled ......... at .......... High. A classic line: INSPECTOR: I'm here to sack one of your teachers. STUDENT: Welcome to Bromwell High. I expect that many adults of my age think that Bromwell High is far fetched. What a pity that it isn't!"""
outputs = classifier(text)
print(outputs)
pd.DataFrame(outputs)
次は固有表現認識 (named entity recognition)
# 固有表現認識
ner_tagger = pipeline("ner", aggregation_strategy="simple")
outputs = ner_tagger(text)
pd.DataFrame(outputs)
# 質問応答
reader = pipeline("question-answering")
reqstion = "what does the customer want?"
outputs = reader(question=question, context=text)
print(outputs)
# >>> {'score': 0.02156698703765869, 'start': 658, 'end': 666, 'answer': 'teachers'}
pd.DataFrame([outputs])
質問応答はいくつか種類がある。ここの例はテキストから答えを直接抽出する。「抽出型質問応答」と呼ばれている。
「要約」は複雑なタスク。これも pipeline で定義できる
summarizer = pipeline("summarization")
outputs = summarizer(text, min_length=10, clean_up_tokenization_spaces=True)
print(outputs[0]["summary_text"])
翻訳も、要約と同様に生成したテキストを出力とする。
# !pip install sentencepiece
# 翻訳パイプラインの読み込み
# translator = pipeline('translation_en_to_ja', model='Helsinki-NLP/opus-mt-en-jap' )
translator = pipeline('translation', model='Helsinki-NLP/opus-mt-en-jap')
# 翻訳する文章
text = "This is a sample sentence to be translated."
# 翻訳の実行
result = translator(text, max_length=40)
# 結果の出力
print(result[0]['translation_text'])
# >>> これ は 解釈放 の こと で あ る .
※よくわからない翻訳文なのだが、いったん置いとく。2021/08 に株式会社 Yellow Back さんが Yellowback Tech Blog - transformersで英語から日本語への翻訳 という記事でこのあたりに関係しそうな言及をしているので参考まで
最後にテキスト生成。
# テキスト生成
generator = pipeline("text-generation")
response = "Dear bumblebee. I am sorry to hear that your order was mixed up."
prompt = text + "\nCustomer service response: \n" + response
outputs = generator(prompt, max_length=200)
print(outputs[0]['generated_text'])
1つ上までの例では自分のタスクに合わせたファインチューニングは扱っていない。
Hugging Face Trasnformers のエコシステムを利用することで楽できるかも。公開されているモデルはコード1行でプロジェクトに取り込めるので、試行錯誤が捗る。データセットや、各種指標を計算するためのスニペットも提供される。
Hugging Face
色々ある。
- Hugging Face Hub
- Hugging Face Tokenizers
- Hugging Face Datasets
- Hugging Face Accelerate
GPT 3.5 に説明させてみたのでそのまま転記
Hugging Face Hub
Hugging Face Hubは、機械学習モデルやデータセットを共有し、管理するためのプラットフォームです。このプラットフォームを使用すると、コミュニティメンバーは自分たちの機械学習モデルやデータセットを共有し、他の人がそれを使用して、自分たちの問題を解決するのに役立てることができます。Hugging Face Tokenizers
Hugging Face Tokenizersは、自然言語処理タスクで使用されるテキストデータをトークン化するためのライブラリです。これは、テキストを小さな単位に分割し、機械学習モデルに入力することができる形式に変換することができます。 Hugging Face Tokenizersは、Python、C ++、およびRustで書かれており、さまざまな自然言語処理タスクで広く使用されています。Hugging Face Datasets
Hugging Face Datasetsは、機械学習アルゴリズムをトレーニングするためのデータセットを提供するためのライブラリです。 Hugging Face Datasetsには、様々なデータセットが含まれており、自然言語処理、コンピュータビジョン、音声処理、その他の機械学習タスクに使用することができます。これらのデータセットは、高品質であり、機械学習モデルを開発するために必要なさまざまな種類のデータが含まれています。Hugging Face Accelerate
Hugging Face Accelerateは、分散トレーニングとスケーリングのためのライブラリです。これにより、より大規模なデータセットとより大規模なモデルをトレーニングできるようになります。 Hugging Face Accelerateは、PyTorch、TensorFlow、およびJAXで使用することができます。これにより、より高速でスムーズなトレーニングが可能になります。
transformer に関する課題
(1) 言語
大部分は英語を対象としている。学習データが揃わない言語の事前学習済みモデルを見つけることは簡単ではない
4章で「多言語の固有表現認識」を扱っている。多言語 tarnsformer とそのゼロショットによる言語感転移の可能性について検討する
(2) データの可用性
転移学習が実用的になったが、人間が学習するのに必要な量と比較するとまだデータは不十分
ラベルがない、または少ない状況にどう対応するか、9章で検討する
(3) 長い文章の処理
Self-attention はパラグラフ単位のテキストを扱うには非常にうまく機能する。しかし、文書全体のような長いテキストになると非常に計算量が増える。11章で計算量削減のためのアプローチを検討する
(4) 透明性
解釈性の問題。transformer には解釈性が低い。
モデルの予測に対して「理由」を明らかにするのは、難しいか不可能。モデルが重要な決定をする場合は特に難しい。
(5) バイアス
インターネット上のテキストをベースにしているため、ここに含まれるすべてのバイアスはモデルに刷り込まれる
tokenize の方法として、極端な例として「文字トークン化」「単語トークン化」がある。
単純な単語トークン化を見てみると、色々な問題がある。
- 句読点が混じってしまう
- 活用形を考慮していない
- スペルミス
- レターケース
ゆらぎがすべて別の語彙になってしまう。結果として語彙のサイズが膨れ上がる。
語彙が大きいということは NN のパラメータが増えるということ。
100万語の語彙(一意な単語)があり、これを NN の第1層で 1,000 次元に圧縮したい場合(ほとんどの NLP アーキテクチャで標準的なアーキテクチャ)。
重み行列は 100万 x 1000 = 10億 の重みを持つことになる。
この規模は、GPT-2 に匹敵する。GPT-2 は 15億パラメータ。
サイズが無駄に膨れないようにする工夫が必要。
よくあるアプローチは、コーパスの中で頻出する単語の上位 100,000 語のみ使用し、頻度が低い単語を切り捨てること。
語彙に含まれない単語は「未知語」となり、すべて UNK トークンにマップされる。つまり、UNK トークンになってしまった単語が重要な意味を持つ場合の情報ロスに懸念があることを示している。
ここで紹介する「文字」「単語」の間を取るアプローチが、「サブワードトークン」である
サブワードトークン化
「文字トークン化」「単語トークン化」のいいとこ取りをしようとするアプローチ。
頻出単語は一意なものとして管理する一方、稀な単語はより小さな単位へと分割し、複雑な単語やスペルミスを処理できるようにする。これで入力の長さを管理可能なサイズに保てる。
BERT, DistilBERT の tokenizer として使われる "WordPiece" を見ていく。