[ElasticSearch] 事例読み解き / ログ分析プラットフォーム Monolith と LINE Spam対策の現状/Data analysis for security
ここでは2つのストーリーを紹介する。
- インフラセキュリティにおけるログプラットフォーム
- LINE サービスにおけるスパム対策
※キーワードはログ分析ではあるが、中身としては両者は全く別物なので注意
「インフラセキュリティ」の話
サーバー/PC/ネットワーク など。
ここではどのようなログをどう集めて、どう活用するのかを話す。
構築したプラットフォームのことを LINE では "Monolith" と呼んでいる。規模感はこんな感じ;
- 40 のインデックス
- 30,000+ のデータソース
- 600,000,000 件/ 1 day のログ
- 1 TB / 1 day のデータボリューム
以前はログは各自のデバイスにあった。よって、インシデントが発生した場合はデバイスからログを取得する必要があった。また、デバイスからログが Expire していることもあった。これを解決するためにログの一元化に取り組みを行った
2014/11 時点
VIP -> Fluentd -> ES -> Kibana の構成にしていた
ログの種類、量が増えて問題が発生。Kibana が重くなったり、ES がフリーズしたり、Fluentd がログをロストしたり。
2016/08 に ES をアップグレードし、その際に上記の構成を一新した ("Monolith" の形になった)

fluentd を Logstash に変更し、役割ごとにサーバーを分けた。
間に kafka を入れることで、メンテナンスや障害に備えている。
Hadoop に入れたログは消さずに後から分析する用途に利用する。ES に送ったログは即時性が求められる要件に利用する。
(以降、マルウェア感染した場合を想定した仕組みの話)
PC からは定期的に Monolith にデータを送信していて、ダッシュボードで利用状況を可視化している
Linux サーバーの場合は ssh に注目している。LINE では基本的には社内外からを問わず ssh は禁止しているが、例外はあるため状態を把握しておく必要はある。どのサーバーから ssh があったのか、それは成功/失敗したのかを可視化している。
ダッシュボードだけあっても人間が見ることは辛いので、これを機械的にアラートできないかを模索していた。
「正常」「異常」の判定基準は様々な環境要因や見る対象によって異なり、定義が難しかった。検討しているうちに ES が機械学習による異常検知の仕組みを出してきて、これが便利だったので使うことにした。しきい値に定数を使う、という雑なことをしなくて済むようになった。
LINE では、業務でも積極的に LINE を利用している。担当者にいつでも(休日と夜間...)連絡が取れることがポイント。アラートの通知も LINE で担当者に共有している
「アンチスパム」の話
動画 12:48 付近から開始。LINE トークルームでの事例紹介
スパムの現状
2013年に対策を実施してから減少傾向に転じ、2015年からはほぼ横ばいになった。
LINE には「通報」という機能がある。ユーザーが通報することでメッセージ内容を LINE で確認し、判定器がスパム判定を行い、本当にスパムであれば学習データに追加する。
スパムの地理的な分布としては日本と台湾が突出して多く、優先的に対策する方針とした(ただし、他の国でも増えてきているので範囲を広げようとしている)。
国によってスパム傾向は異なる。日本であればいわゆる「出会い系」が支配的、台湾であれば製品の宣伝や、コピー品や金融関係などのメッセージが多い。他の国を見れば、また違った傾向が出ていることを確認している。
「アカウントは電話番号と紐づくので、アカウントをブロックすればいいのではないか?」と思われるかもしれない。しかし、今は Facebook からでもアカウントは作成可能だし、海外では電話番号は容易に大量入手が可能なので簡単ではない。
スパマーの行動はおよそ↓のようなサイクル
- Create accounts
- Add friends
- Send messages
スパム対策システム
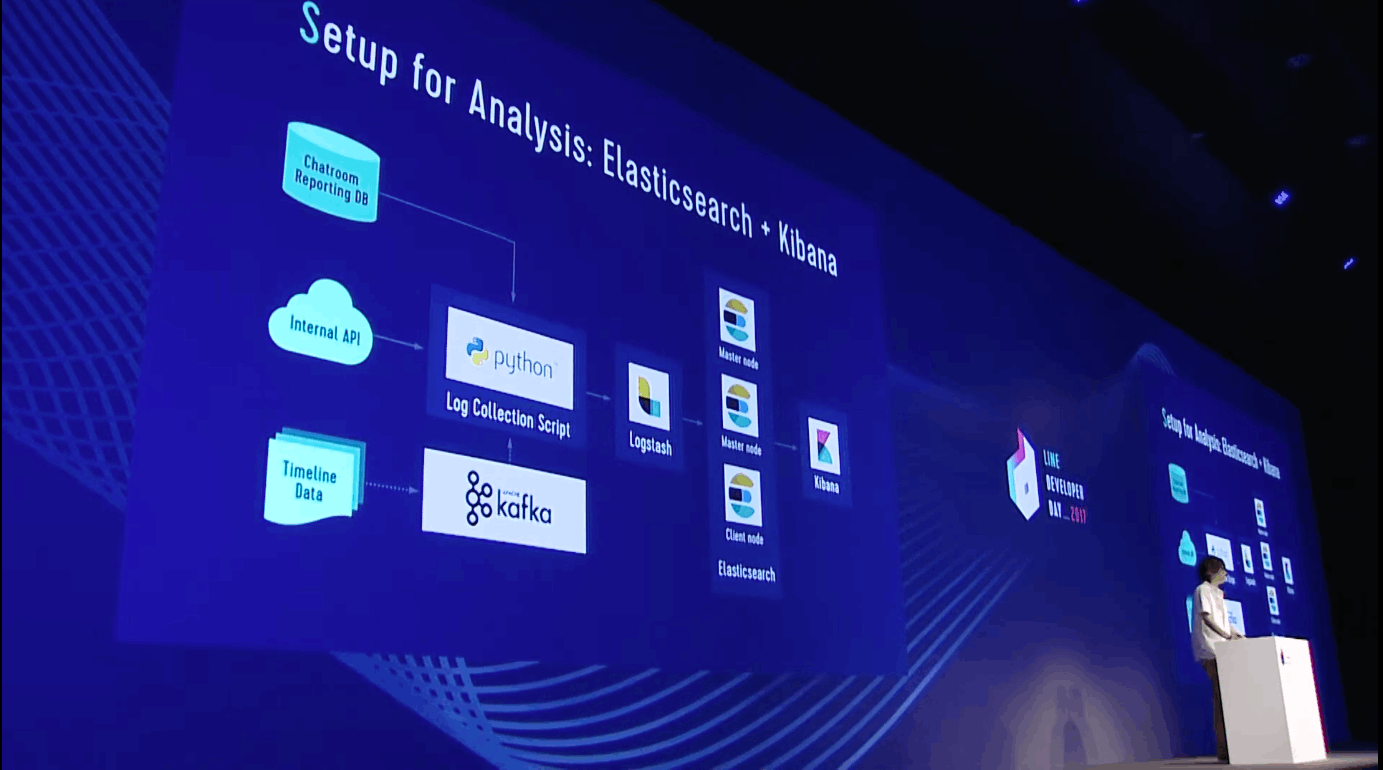
データ収集と可視化には Kibana + ES を使っている。動画 18:45
ブロックのルールには3つのラインがある。
- ルールベース
- 機械学習
- 人手による設定
Create accounts/ Add friends/ Send messages のそれぞれに対して、ルールベースのブロック判定が適用される(例えば、短時間に大量のアカウント登録があればブロックするなど)。ルールベースでは、メッセージの内容ではなく、端末情報などのメタデータを用いている。
ユーザーによる通報ベースのフローでは、ルールベース → 機械学習 → 人による判別 の順序でブロックの判定を行う。ルールベースとは異なり、ML ベースと人間の判定ではメッセージ内容を考慮した判定が行われている。
※個人的な疑問: メッセージの機密性(暗号化)はどうやって担保しているのだろうか・・・?
スパムの世界では、時間軸でスパムの「流行り」が異なる。これは "Concept drift" と呼ばれる(データセットの特性が時間経過で変化する)。よって、ML ベースのシステムでは定期的に学習データを更新していく仕組みになっている。こうすることで「いたちごっこ」にも対応することができるようになる。ルールベースの検知はスパムの内容や時間軸に関わらず「スパマーの行動」をしていればブロック、という仕組みになっているのに対して、時間軸によって変化する傾向を考慮に入れている点が ML ベースの特徴。
正常なメッセージがスパムとして送りつけられる場合もあり、これもスパマーによる一種の攻撃である。検知器の学習が狂ってしまう影響が出る。セキュリティの世界では False positive の発生を防ぐ必要があるため、こうした攻撃は比較的困る類のものになる。現状では、学習時にちょっとしたルールを追加することで対応できているが、スパマーの行動が変われば対策も変わるので、あくまで現状うまくいっている、という程度。
最後に人間による判断。80 - 90% は前段で排除できるが、残りは人間がやるべき。False-positive は本当に防止すべきもので、100万、1000万件の通報あたりで1件の誤検知でもギリギリ、という水準。一般ユーザーが間違ってブロックされてしまうことは避けたい。一方で、スパムの検知漏れ (False-) は False-positive ほどシビアではない。よって、仕組みとして False-positive を防止する方に倒している