[ElasticSearch] 事例メモ / 膨大な楽曲数を扱う検索機能を支えるElasticSearchの構成と速度改善手法 (LINE)
Session: https://linedevday.linecorp.com/2021/ja/sessions/118
Title: 膨大な楽曲数を扱う検索機能を支えるElasticsearchの構成と速度改善手法 - 2021 日本語版-
Speaker: 多田 拓 氏 (Development Team T / Server Side Engineer)
Slide: https://speakerdeck.com/line_devday2021/knowledge-derived-from-search-for-huge-track-metadata-with-elasticsearch
Youtube: https://youtu.be/S1IqcVUtouY
サマリ
LINE Music のバックエンドで使っている ES のお話。レーベルさん向けに提供している CMS と API サービスがあり、それぞれパフォーマンス問題があったので改善してみた。
自分なりに重要そうなトピックを抜粋すると以下
- 検索に用いるフィールドが非常に多岐にわたり、データ件数も 85M を数える規模感のユースケースが前提になっている
- wildcard/ match query をこう使った、というケーススタディ
- ノード数とシャード数+レプリカ数の関係にはゆるい不等式があり、それを目安にある程度それぞれの数を見積もれる
- 結局はワークロードを実際に負荷試験してみようぜという話(内部構造に踏み込んで分析して机上でキャパシティを計画する/できるような話ではなかった)
memo
前提事項
- Web アプリやネイティブ (iOS) で提供しているサブスク型サービス "LINE Music"
- レーベル向けに検索サービス “Meta search API” を提供している。これの裏側を紹介する
- 85M 規模の曲数を扱っている
事例(1) - CMS
問題意識
- これまでは楽曲名のみ検索できた。部分一致で評価する
- アルバムやアーティストでの検索ができない
- 同名の曲が他に存在する場合のさらなる絞り込みができない
- 同一の検索フォームでもっと多様な属性で検索したい
- 機能追加によって↑をサポートするようになった、しかし...
- 1sec 程度だった検索が 5sec になってしまった
- なにが悪かったのか?(本発表の内容)
従来構成では、 keyword タイプを wildcard で検索 していた。これは当時サービスを早くリリースするのを優先したためであり、パフォーマンスに関する検討は優先度が低かった。
なぜ遅かったのか/どうすれば速くなるのか
遅かった理由は、keyword 型と wildcard query が理由。
- keyword は生の文字列を持っていて、とくになんの処理もされていない
- wildcard クエリは後方一致が遅い(これは公式ドキュメントにも記述があるらしい。要追記)
文字列の検索を高速にするなら tokenize 処理が必要。ただし、LINE Music で登場するテキストは固有名詞が多いため、一般的なコーパスに基づく tokenize は不向きだった(これをきちんと検討・対策するための工数がリリース当初はなかった)
どうしたのか
- 楽曲名を text 型に変更
- クエリを Full text query の一種である match query に変更
これによって、転置インデックスが使用できるようになり、検索が高速化した。
また、tokenize には n-gram (3)を使用した(形態素解析ベースのアプローチは前述の理由、データ特性により難しい)。

n-gram の問題は、検索対象文字列の順序が崩れてしまうこと。tokenize したタームの出現順序は反映できない。この問題の対策として、n の数字を大きくすることが検討できる。今回は tri-gram (=3) が丁度良かった。3 文字分で tokenize することで、実用上順序の問題が(無視できる出現頻度となるため)クリアできる。ただ、4文字にすると index が大きくなってしまうので 3文字 (tri-gram) が最適と判断した
ポイントは、
- データ特性上、形態素解析による tokenize が難しかった(1つのドキュメントが短く、固有名詞の登場頻度が多い)
- wildward を大量データに対して投げるとパフォーマンスが悪化する
- このようなケースでは match クエリを利用したい
- N-gram と動的クエリによって、文字列の順序を実用上保証する
事例(2) - API service
CMS だけでなく、レーベル側のシステムに対して API も開放した。バッチリクエストのようなユースケースに耐えられるようにする必要があったが、負荷試験をすると耐えられないことがわかった。
問題意識
データ件数の多さがネックになっており、さらに調査を進めると ES node の CPU が 100% に張り付いておりリクエストが詰まってしまっていることが判明した。
最初はクエリ改善を試みたが、楽曲数が多かったため問題解消には至らず。インフラ強化に踏み切った。
施策
Data node を増強した。社内的には data node の数に制限があったが、想定する負荷要件を満たすために個別で調整してノードを調達した。自由に増やせるわけではないので、ノードを効率よく利用するための最適化をしていった。シャードとレプリカの数を調整した。
- シャード ... データを水平分割した単位
- レプリカ ... シャードの複製単位、可用性向上
Data node の数やシャードの数が対負荷性能の向上に貢献する。
Node を使い切るために
ノード数は決まっていたので、それに基づいて shard, replica を決定した。
Data Nodes <= Shards * (Replicas + 1)
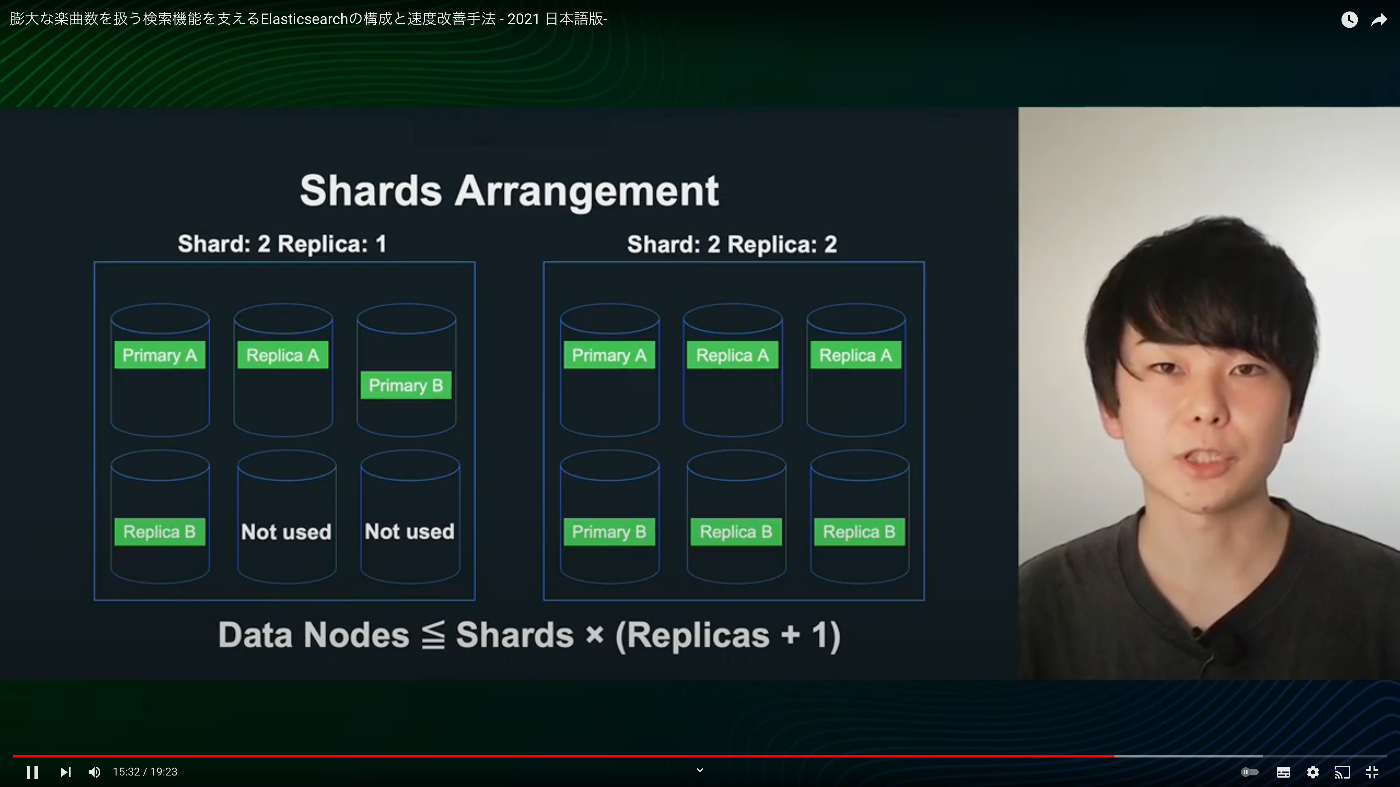
上の図は、 6 nodes に対して 2 shards & 1 replica に設定した場合。使われないノードが2つできてしまう。
分散処理できるノードの数を増やせるように shard, replica 数を設定していく必要があるが、実際のクエリによっても事情は異なってくるので結局のところベンチマークが必要。
実際に LINE で行ったベンチマークでは、以下のような設定で負荷試験を実施した。
- データノード数を 12 に固定し、シャードとレプリカの数を変化させながらテストを実行
- データボリュームは本番相当、400 user を想定して負荷試験を行った
- レスポンス時間に対する min, max, mean, 95% 値をプロットして比較評価
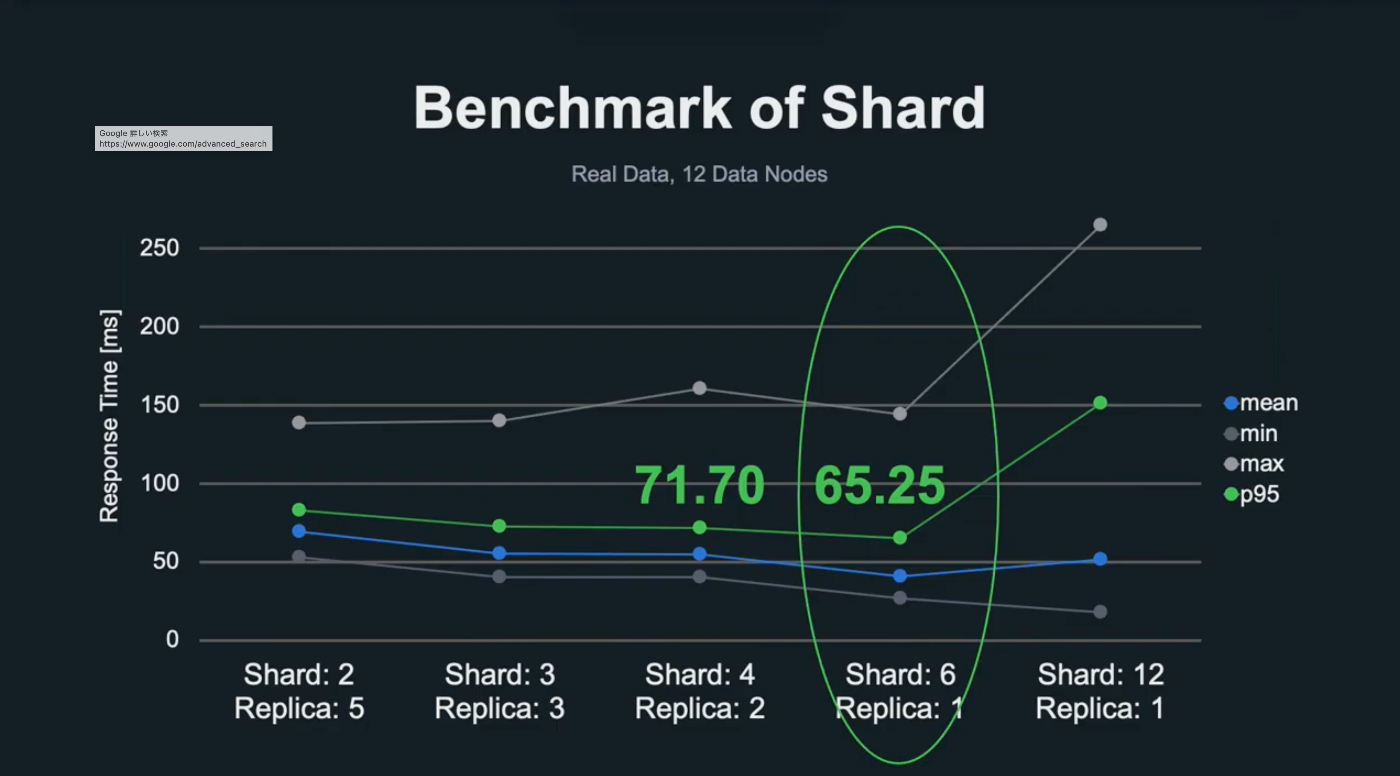
楽曲は全体で 73GB なので、1 shard あたり 12.3 GB になった。
シャード数はデータが増えると最適数も変わってくる。よって、カジュアルに負荷試験ができる環境を整えることも大事。
公式からまとめ(?)記事が出た