匿名化SDK Presidioを試す
概要
データ分析基盤構築で匿名化関数を探していたところMicrosoft Presidioを発見。日本語の記事が2023/06/10時点で以下の記事しか発見できなかったので、自分が利用するPython観点で簡単な記事を書きました。
GlueのPIIも検討しましたが、Glue内部でしか使えなそうで汎用性が低い印象でした。
Microsoft Presidioとは
2023/6/10現在でGithubスターが2100を超えており、そこそこ注目されているもので、
WebページのトップをDeepLで翻訳すると次の通り。
Presidio (語源は Latin praesidium 'protection, garrison') は、機密データが適切に管理され、統治されるように支援します。クレジットカード番号、名前、場所、社会保障番号、ビットコインウォレット、米国の電話番号、金融データなど、テキストや画像における民間事業者の高速識別と匿名化モジュールを提供します。
目標
- 非識別化技術を民主化し、意思決定に透明性を持たせることで、組織がよりシンプルな方法でプライバシーを保護できるようにする。
- 特定のビジネスニーズに合わせて拡張性とカスタマイズ性を確保する。
- 複数のプラットフォームで、完全に自動化されたPII非識別化フローと半自動化されたPII非識別化フローの両方を促進する。
検出フローも公式ページに記載されていて、5段階で検出を行っているのがわかる。
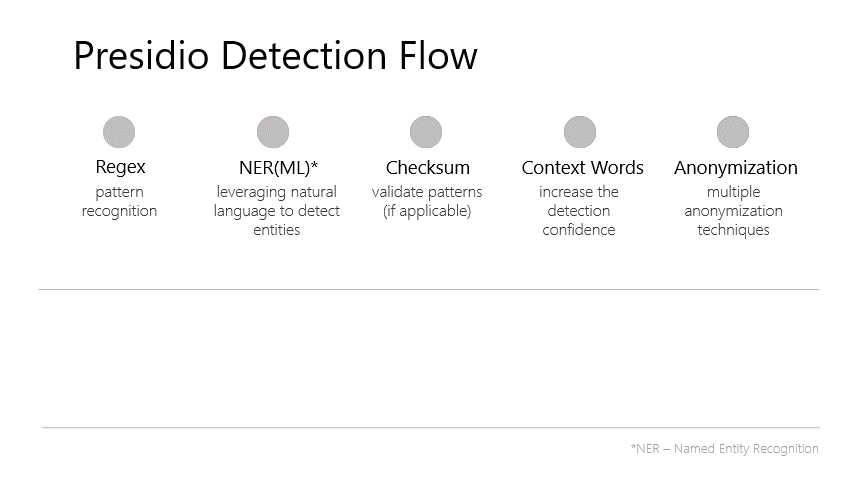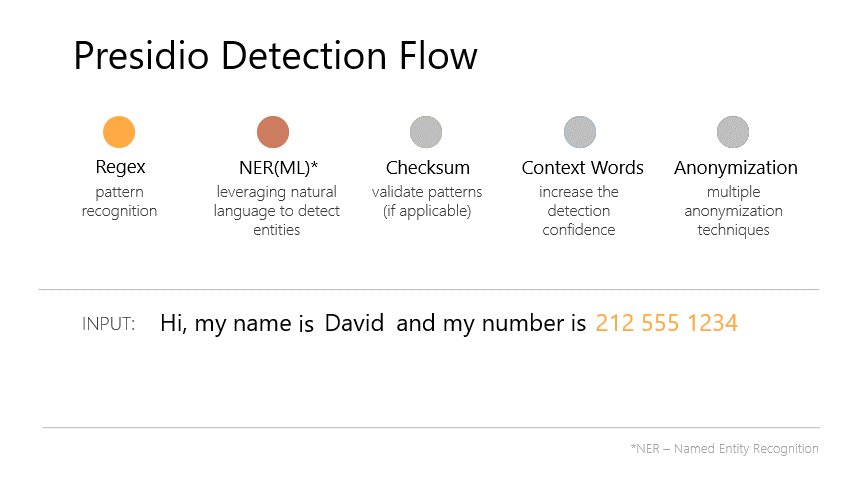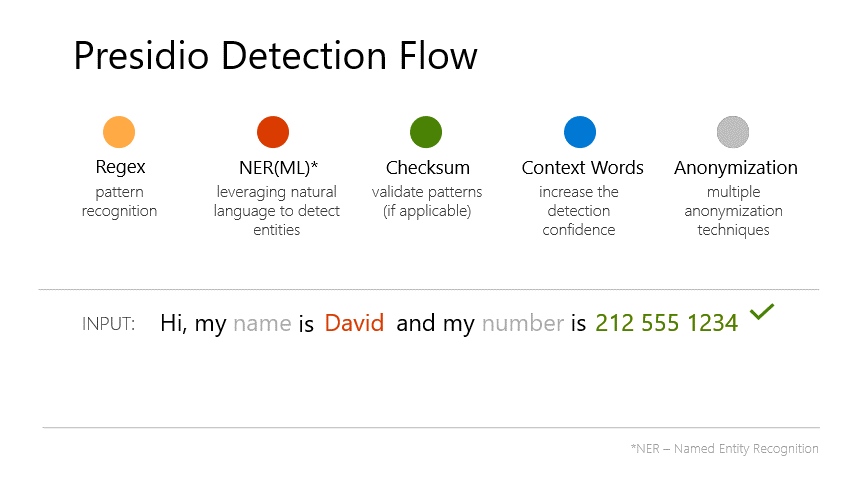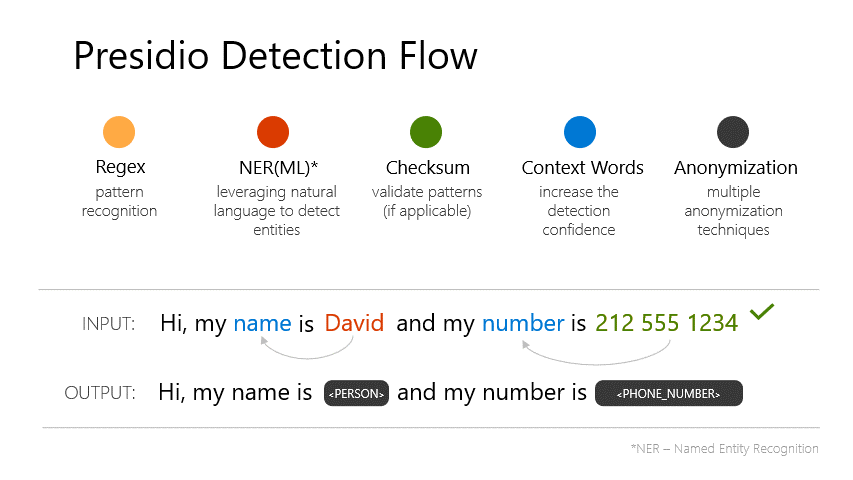
上記のように匿名化SDKとして提供されていて難しそうだが、Pythonであればpipでインストールして簡単に呼び出すことができます。
Presidioは3つのモジュール群からなります。
- Presidio analyzer: PII(個人を特定できる情報)のテキスト認識
- Presidio anonymizer: PIIの匿名化
- Presidio image detector: 画像のPII情報の削除
私が匿名化したかったのはテキストなのでimage detectorは検証していないので本記事では取り扱いません。
テキストを匿名化する場合は
- analyzerでPII情報を検出
- annymizerにanalyzerで検出した情報を渡して匿名化
の流れで行います。
利用方法
インストール
インストールは公式サイトの通り行えば簡単にインストールできました。
pipで2つのモジュールをインストールするだけでした。検出の過程でSpacyというMLライブラリを使っているようで、MLの言語モデルをインストールする必要があります。
以下見ると言語モデルは英語ですが、日本語モデルもあります。そのままだと使えないので、先ほど概要で紹介した記事に使い方が記載してあります。
pip install presidio_analyzer
pip install presidio_anonymizer
# Presidio analyzer requires a spaCy language model.
python -m spacy download en_core_web_lg
今回はPythonで直接呼び出す予定のため、pipでのインストールのみ触れましたが、Dockerイメージも公開されていました。
試してはいませんがDockerイメージの場合Web APIとしてanalyzerとanonymizerが公開されるように見えました。
実行方法
公式サイトのサンプルを動かしました。
analyzer
from presidio_analyzer import AnalyzerEngine, PatternRecognizer
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
import json
from pprint import pprint
# 認識対象のテキスト
text_to_anonymize = "His name is Mr. Jones and his phone number is 212-555-5555"
analyzer = AnalyzerEngine()
# 電話番号を認識させる
analyzer_results = analyzer.analyze(text=text_to_anonymize, entities=["PHONE_NUMBER"], language='en')
print(analyzer_results)
実行結果は次の通りになります。
[type: PHONE_NUMBER, start: 46, end: 58, score: 0.75]
何文字目がどの程度のスコアでヒットしたかがわかると思います。analyzerは認識だけで匿名化は行いません。また、entitiesに"PHONE_NUMBER"をしていますが、これを"PERSON"にするとMr. Jonesがヒットします。
[type: PERSON, start: 16, end: 21, score: 0.85]
entities一覧はここに記載してあります。
GlueのPIIでは日本語固有のエンティティも定義されていて、対応方針の差を感じました。
匿名化
こちらもサンプルコードのとおり。実行する場合はanalyzerの結果をインプットにしているので、くっつけてください。
anonymizer = AnonymizerEngine()
anonymized_results = anonymizer.anonymize(
text=text_to_anonymize,
analyzer_results=analyzer_results,
operators={"DEFAULT": OperatorConfig("replace", {"new_value": "<ANONYMIZED>"}),
"PHONE_NUMBER": OperatorConfig("mask", {"type": "mask", "masking_char" : "*", "chars_to_mask" : 12, "from_end" : True}),
"TITLE": OperatorConfig("redact", {})}
)
print(f"text: {anonymized_results.text}")
print("detailed response:")
pprint(json.loads(anonymized_results.to_json()))
実行結果は次の通りになります。
1つ目はentitiesに"PHONE_NUMBER"、2つ目はentities"PERSON"にした場合です。
text: His name is Mr. Jones and his phone number is ************
text: His name is Mr. <ANONYMIZED> and his phone number is 212-555-5555
コードにある通り、operatorで匿名化の方法を細かく指定が可能です。サンプルでは"PHONE_NUMBER"はアスタリスク12文字と設定しているため、アスタリスクで出力され、"PERSON"は特段の設定をしていないので、デフォルトの<ANONYMIZED>で設定されています。
ほかにも様々なサンプルがPresidioのサイトに公開されています。
匿名化の精度について
自分は氏名についてマスキングしたかったので"PERSON"についてのみ調べてみました。結果としてはPresidioで完全にマスキングすることはできず、匿名化の手助け程度という印象でした。一方、氏名でここまでマスキングできるのであれば、電話番号やE-Mailならもっと高い精度で匿名化できるのかなと思いました。
氏名固有の精度は次の通り
- デフォルトの"PERSON"では漢字は検出できない。(Spacyの日本語モデルを使えば検出できそう。冒頭紹介したURLでは検出できている様子)
- 日本人もローマ字ならばある程度検出できる
まとめ
自分のユースケースでは採用できませんでしたが、使用用途によっては十分使えるSDKだと思いました。
Discussion