AI何も知らないSREがGenerative AIで何ができるか考えた in 2023
はじめに
本記事は3-shake Advent Calendar 2023シリーズ1、3日目の記事です。
3-shakeの橋本と言います。2023年は諸事情により半年ほど休職しており、5月からのスタートでした。
復職後のリハビリタスクとして「ChatGPT流行ってるからSRE的に何ができるか色々触ってみて」とだいぶアバウトなテーマで色々遊ばせていただきました。
そんな活動が功を奏したのか、今年は以下2つの登壇、LT参加を行うことができました。
2023/09/29(金) SRE NEXT 2023「SREとして向き合うGenerative AI」
2023/10/27(金) Generative AI Meetup & Google Cloud Next '23 Recap 「AI ど素人 SRE の Gen AI 活用事始め」
本記事では上記の登壇資料をベースに、SREとしてのGenerative AIの使い道の提案をまとめます。
何故今Generative AIなのか
AIがバズワードになったのはDeepLearningが流行り始めた頃(2010年代前半)かなと思います。機械学習はクラス分類や数値予測のための特定のタスクに対して望ましい結果を出力するためにモデルを作成することを意味し、実際にAIの力を得るためには①学習用の整形されたデータの集まり、②モデル作成のための数学知識(代数、微積)が必要でした。様々なライブラリやマネージドのAIプラットホームが作成されることで例えば複雑な数理モデルの知識をすべて持たずとも学習を実行することができるようになってきていますが、依然学習データの作成等はハードルの高い作業なのではないかと思います。
その中で入出力がテキストであるということ以外は汎用的なLLMを始めとする生成AIの登場により、タスクに特化したものではないものの、幅広い状況でAIの力を誰でもすぐに利用できるようになった点が大きな違いであり、急速に利用が広まったという個人的な理解です。
Generative AI(ほぼLLM)の基礎知識
promptとは?
LLMへの質問(input)をPromptと呼びます。
ChatGPT登場当初様々なテクニックが登場しましたが、徐々にモデル側が人間に近く進化していくんじゃなかろうかと思っているのでプロンプトエンジニアって職業ができるのかどうかは懐疑的です。(個人の意見です←重要)
様々なpromptガイドが登場していましたが、現在は各社のドキュメントにガイドが乗っていることが多いためそちらを参考にpromptを組み上げていくとよいです。
参考
- OpenAI: Prompt engineering
- Google: Introduction to prompt design
LLMの弱点 - トークン長制限
LLMはモデルの構築方法にもよりますが入力、出力それぞれに、もしくは両方の合計に長さの制限が存在します。これをトークン長制限と言います。
トークンとは文字列を取り扱う単位であり、一般的におよそ4文字が1トークンになります。
大規模な質問や出力を得たい場合には①トークン長制限が大きいモデルを利用する②質問を要約する
の2つの手段が考えられます。
トークン長制限が大きいモデルを利用する
シンプルに巨大なモデルを利用することで大きな入出力を取り扱うことができます。基本的に大きいモデルのほうが利用料が高い傾向にありますが、gpt4-turboの登場によってだいぶ使いやすくなったかなと言う印象です。
質問を要約する
上記の通り大規模なトークンのモデルが多く登場してきているため最近は必須ではないかもしれませんが以前は質問文を分割して一度「以下の文章を要約してください」のような指示でLLMにわたすことで文章を圧縮するようなテクニックが取られていました。
特に、順序関係を保つため先頭から徐々に要約する手法を再帰的要約と言います。
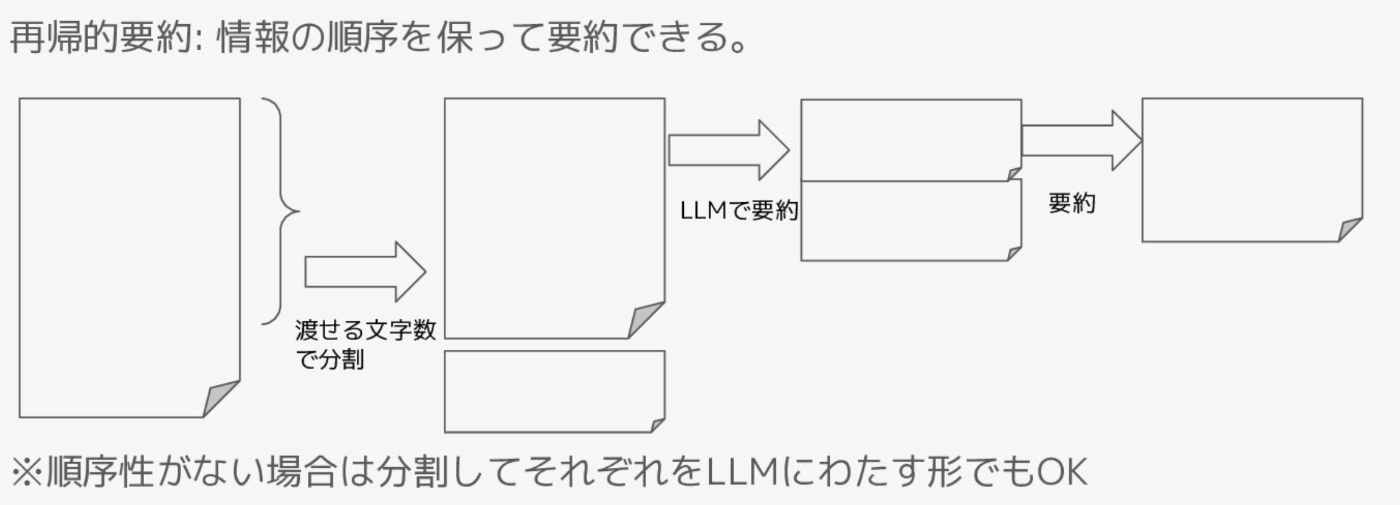
LLMの弱点 - 知らないことは知らない
当然なことですが、LLMのモデルを作成した以降の情報についてはLLMは知識を持ち合わせていません。また場合によってはそのようなケースでも幻覚(ハルシネーション)を見せる=正解かのように誤った出力をすることが起こり得ます。
そのようなケースに対して以下の2つの手法が多くのサービスで提供されています。
ファインチューニング
ファインチューニングは学習済のモデルに対し、追加のデータセットでモデルを再学習する手法です(すいません正直あまり詳しくないです)。
現状私の観測範囲ですと各モデルが提供しているファインチューニングの機能では出力形式の統一などはできても、新たな知識を学習することは難しいというのが多い意見のようです。
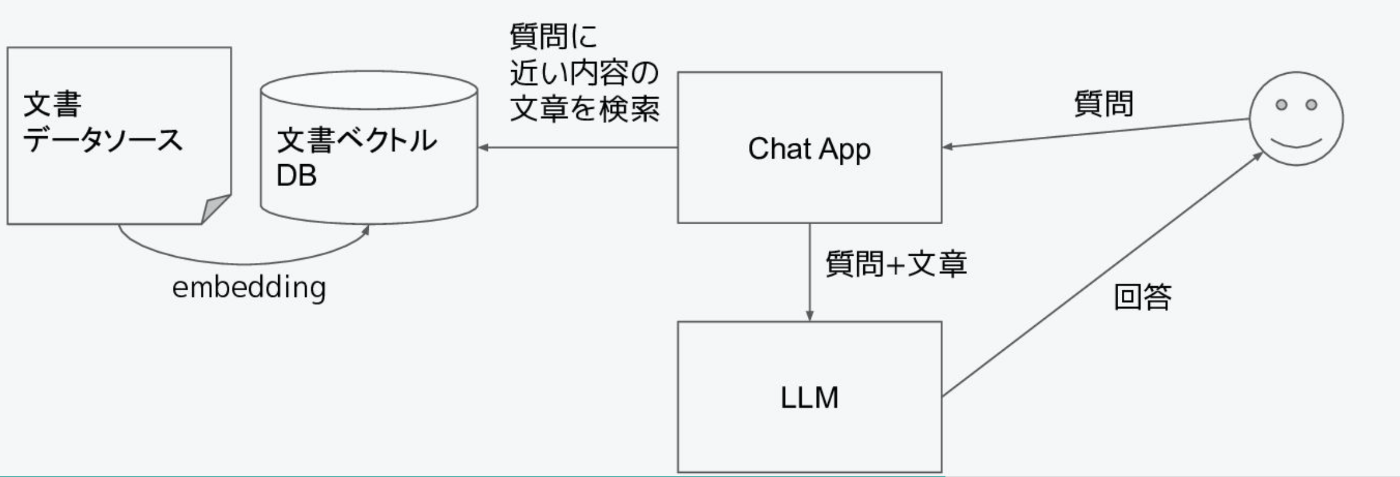
Retrival Argment Generation(RAG)
LLMに必要な情報をpromptとして渡す手法になります。
前述の通りトークン長制限がありますのでデータストアから質問文をベースに必要な情報のみを取得してpromptに付与する必要がありそのような検索 + データストアの仕組みについては各社パブリッククラウドで提供されています。
SREが利用するLLMのユースケース案
SREが信頼性を担保するためにどのようなケースでLLMが活用できるかを考える中で大きく2つの役割があるのではないかと考えました。
情報接種効率の向上
SREingの範囲は膨大で、とてもじゃありませんが1人で捌き切ることはできません。一方で求められる知識範囲は技術にとどまらず運営するSiteのドメイン知識も必要になってきます。すなわち信頼性を高める(=SREingを十分に行う)ためにはある程度の育成が必要になります。そのようなケースで必要な情報にアクセスしやすくするためにRAGを活用し情報接種効率を上げることができると考えます。
例として以下のようなケースが考えられます。
- 社内ドキュメントをデータストアとするRAGをLLMと組み合わせることで社内のチャットツールから様々な知識を検索できるツールを作成し、オンボーディングの期間、コストを下げる。
- 障害対応手順書やポストモーテムをデータストアとするRAGをLLMと組み合わせることで、障害アラートのメッセージから近しいと思われるknowledgeをオンコール担当者へ通知することで対応リードタイムを短縮する。
toilの自動化実装をpromptで代替する
toilを緩めに定義すると、「自動化可能」で「繰り返される」作業です。様々な自動化施策を皆さん行っていることかと思いますが、自動化が難しかったり、実装コストと削減効果が見合わなかったりし、toil化を見送られている運用がある方が多いと思います。
それらについてLLMのデメリット(100%正確ではない、必ず同じ出力ではない)ことをある程度許容できるようなタスクについてはpromptを書くだけで自動化できるのであれば比較的低コストで実現可能になります。
いくつか試してみたブログがあるので紹介します。
- レポーティング作業を一部代替する
- コストレポート
- パフォーマンスレポート
- etc...
- ドキュメンテーションを代替する
- 構成図の自動作成
- エンジニア向けの記述から非エンジニア向けへの翻訳(Code2text)
最後に
おおまかではありますがSREとしてGenerative AIとどう付き合っていくべきかを考える中で大きく2つの役割を提案させていただきました。
会社としても我々はAIのスペシャリストではありませんが、SRE集団として得た知見をもとにGenerative AIを活用したSREの自動化をゴールに様々な取り組みを行っていきます。
Generative AIの利活用、SRE活動でお悩み等ありましたらぜひお問い合わせください。
スリーシェイク、生成AIを活用したSRE業務自動化への取り組みを発表
Discussion