PythonでRDBMSのNested-Loop Joinを実装して2つのCSVを外部結合して射影してみた
はじめに
ベン図と結合(JOIN)
RDBMSの結合は、よくベン図を用いて説明されますが、逆に混乱を招いておりたいへん難しいのではないかと思います(すくなくともぼくには難しかった)
なぜならわれわれは、テーブル(表)という概念で考えるからです。
ベン図はみたまんまテーブルではないので、テーブルから集合へどのように変化するのかイメージがつきにくいと思います。ベン図を見せられて、OUTERとかINNERとかLEFTとかRIGHTとか言われても、なんだかよくわかりません。とくにOUTERはいちばんわかりにくいと思います。
そういうわけで、テーブルの結合を考えるにあたっては、それを実装してみるのがいちばんいいのではないかと思います。
そもそもRDBMSは魔法が起きているわけじゃなくてデータ置き場なんやで
えぇ感じにSQLを書くとえぇ感じに素早くデータが得られて魔法が起きてるっぽく見えるRDBMSですが、その実態はCSVのような「単なる表」や「配列(リスト)」をイメージするといいんだろうなと思います。
「単なる表」というと語弊があっていろいろと言われるような気もしますが、「魔法的な表」というふうに考えるのではなくて、下のように普通の配列(リスト)にできちゃうと考えるといいかもしれません。
次のようなテーブル(リレーション)は、
name | twitter
---- | -------
かえる | https://twitter.com/harukaeru1981
かえる(en) | https://twitter.com/harukaeru_en
株式会社マツリカ | https://twitter.com/mazrica_jp
実際には、
[
['name', 'twitter'],
['かえる', 'https://twitter.com/harukaeru1981'],
['かえる(en)', 'https://twitter.com/harukaeru_en']
['株式会社マツリカ', 'https://twitter.com/mazrica_jp']
]
と考えてみたいです。
この配列から、「WHERE name = 'かえる' だったら、その行の twitter カラムを取る」みたいなことを実装するというノリです。(ちなみにこういう WHERE句を使って行を選択するのを「選択」というみたいです)
こういうふうに考えると、「なんてこった!今すぐ実装してみよう!!!実装したい!!」という気持ちになりますよね。
重要概念を頭の中にキープ!
Nested-Loop Join アルゴリズムとは
2つのテーブルを結合させるためには、1つのテーブルをぐるぐるループさせて、もう1つのテーブルもぐるぐるループさせるということが必要になります。はあ? よくわかりませんね。
やっぱり、Nested-Loop Join アルゴリズムと聞くととても怖い感じがします。Nested-LoopのあとにJOINという言葉が来るし、略すとNLJアルゴリズムとかいうおどろおどろしい言葉に見えます。
だから難しく聞こえると思います。
しかし実際にはその中心概念は「二重ループ」だと思います。ネストしたループでJOINするからNested-Loop Joinと考えると怖くなくなります。
↓ちょうど次のコードがわかりやすいと思います。たぶんベン図よりわかりやすいです。
result_set = []
for outer_row in outer_table:
for inner_row in inner_table:
result_set.append(outer_row + inner_row)
ネストしたループの中でガチャーン!(outer_row + inner_rowができるジョイン!)してますね。
outer_table / inner_tableは、表(テーブル)のことです。難しく考えないほうがいいです。
ちなみに↑のコードでは、条件など無関係にすべてを結合しています。
↓データが全然違いますが、こちらの例では persons テーブルを2回ループしています。2つの行を2回ループしているので、4行出力されています。(きみはJOINするときON句が必要だと思っているかもしれないが、実はなくても動く。ナ、ナンダッテーーーー!!)
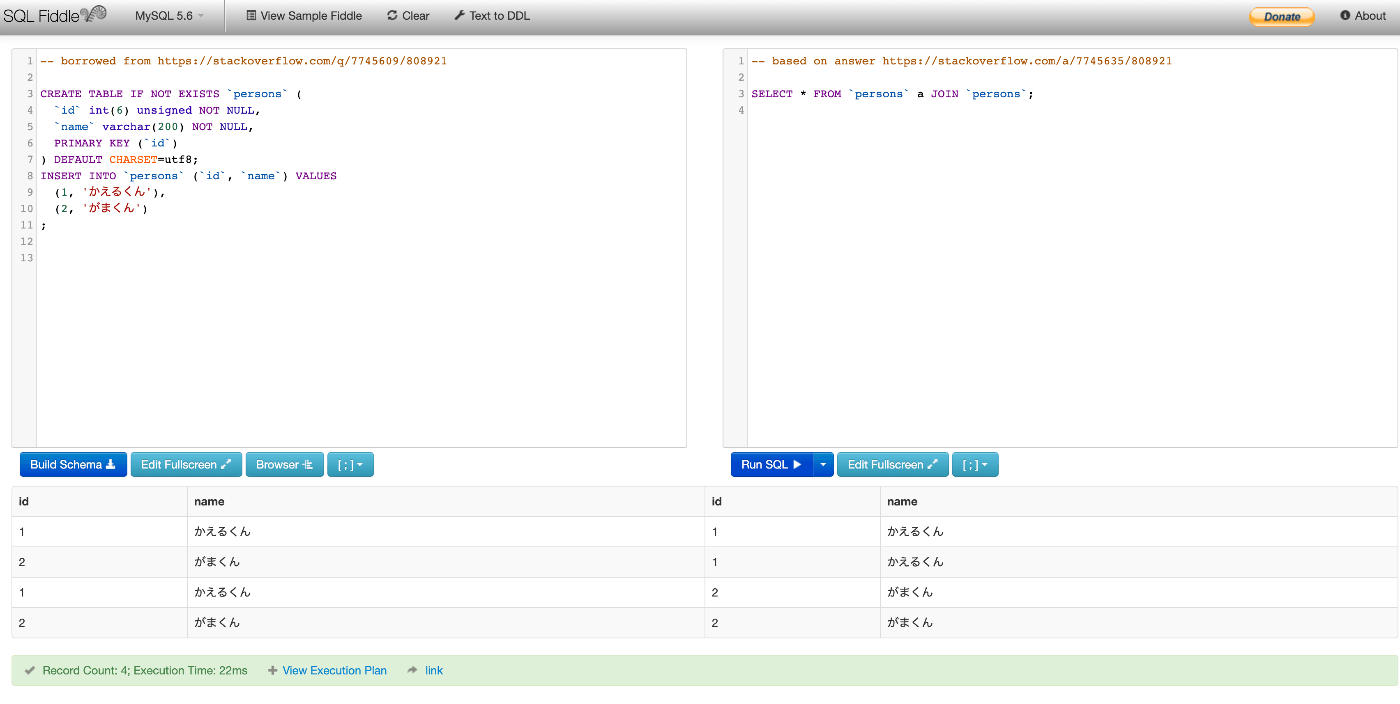
↓デモはこちらから
より詳しく・詳細はこちらをどうぞ↓
ちなみにouter_tableは日本語では外部表(駆動表)、inner_tableは内部表と言うみたいです。
実装方針
じゃあ実装していきます。あらかじめ断りますが、全然使える形として実装していないです。わかりやすいところでいうと、インデックスや内部結合(INNER JOIN)は実装していないです。
この記事では、軽くサマった解説だけを載せているので、実際に動かしたい場合はこの記事の一番下にあるGitHubに飛んでください。
実装の概要
- CSVを読み込んでえぇ感じに使いやすい形に変換する
- この使いやすい形を
Schema(スキーマ。構造のこと)と呼ぶことにします。
- この使いやすい形を
-
SchemaとSchemaをループさせて結合させる - 結合はとりあえず
LEFT OUTER JOINだけつくる - 射影(SELECT)も入れちゃおう
最終的にどういうのができるのか
次の2つのCSVを結合して、
First Name,Last Name,Address,State Name,State Code,ZIP
John,Doe,120 jefferson st.,Riverside,NJ, 08075
Jack,McGinnis,220 hobo Av.,Phila,PA,09119
〜〜〜省略〜〜〜
Code,State,Abbreviation,Alpha code
01,Alabama,Ala.,AL
02,Alaska,,AK
04,Arizona,Ariz.,AZ
〜〜〜省略〜〜〜
このPythonファイルを実行したときに、
import table_schema
import joins
f = open('samples/addresses.csv')
addresses = table_schema.get_schema_from_csv(f)
f = open('samples/postals.csv')
postals = table_schema.get_schema_from_csv(f)
l_addresses = joins.left_outer_join(
addresses, 'addresses.State Code',
postals, 'postals.Alpha code'
)
result = joins.select(l_addresses, ['addresses.*', 'postals.State'])
c = result.to_csv()
print(c)
↓こんな感じでState CodeとAlpha codeをもとに結合してStateを得たいです

実装
CSVを読み込んでえぇ感じに使いやすい形に変換する
CSVを読み込んで、table_name, header, rowsと分けて使いやすい形にしています。色々書いていますが、やっていることはそれだけです。
つまりなんらかのデータをTableSchemaに一度つっこんでしまえば、table_name, header, rowsをあとで自由に使えます。
class TableSchema:
def __init__(self):
self.table_name = None
self.header = []
self.rows = []
def __str__(self):
return f'<header: {self.header}, rows: {self.rows}'
def from_csv(self, csv_file, has_header=True, table_name=None):
self.table_name = table_name if table_name else csv_file.name.split('/')[-1].split('.')[0]
self.header = []
self.rows = []
reader = csv.reader(csv_file)
for i, row in enumerate(reader):
if has_header and i == 0:
self.header = row
elif not has_header and i == 0:
self.header = map(str, range(len(row)))
else:
if len(row) != len(self.header):
raise Exception('Invalid row count')
self.rows.append(row)
self.header = [self.table_name + '.' + h for h in self.header]
これはとてもおもしろいところですが、このTableSchemaの形にするようにデータを加工できれば、別にもともとのデータはCSVじゃなくてもなんでもいいわけです。
たとえば、HTMLの <table></table>をここに加工して突っ込んでもいいのです。これは地味にべんりで、「すべてをテーブルにして加工すれば最強では!?」という発想が生まれると思います。
こうしたプラグインをたくさん作って加工しやすいようにしたのがETLツールの1つと言われて、今流行っているようです。すごい。
SchemaとSchemaをループさせて LEFT OUTER JOINさせる
結合は、ちょっと長いですが、真ん中のforが2回ループしているところに注目してください。
NLJしています。そして、「on_left(左側のテーブルのあるカラムの値)とon_right(右側のテーブルのあるカラムの値)が同じだったら結合!(ジョイン!)」というようなことをしています。
使い方
joins.left_outer_join(
addresses, 'addresses.State Code',
postals, 'postals.Alpha code'
)
実装
def left_outer_join(left_table_schema, left_column_name, right_table_schema, right_column_name, table_name=None):
left_header = left_table_schema.header
right_header = right_table_schema.header
left_idx = left_header.index(left_column_name)
right_idx = right_header.index(right_column_name)
result_table_schema = TableSchema()
result_table_schema.table_name = table_name if table_name else left_table_schema.table_name + '__' + right_table_schema.table_name
result_table_schema.header = left_header + right_header
result_table_schema.rows = []
for outer_row in left_table_schema.rows:
on_left = outer_row[left_idx]
found = False
for inner_row in right_table_schema.rows:
on_right = inner_row[right_idx]
if on_left == on_right:
found = True
result_row = outer_row + inner_row
result_table_schema.rows.append(result_row)
else:
continue
if not found:
result_row = outer_row + [None] * len(right_header)
result_table_schema.rows.append(result_row)
return result_table_schema
ついでにSELECTをつくる
アスタリスクを使うためにいろいろ書いていますが、ヘッダーを探してそれを表示しています。たぶんあまりおもしろくはないです。
SELECTを「射影」というととてもかっこいいです。
def select(original_table_schema, column_names):
result_table_schema = TableSchema()
result_table_schema.table_name = 'selected__' + original_table_schema.table_name
result_table_schema.header = []
header_idxs = []
for column_name in column_names:
if '*' in column_name:
for i, header_column in enumerate(original_table_schema.header):
if header_column.startswith(column_name.split('*')[0]) and i not in header_idxs:
result_table_schema.header.append(header_column)
header_idxs.append(i)
else:
i = original_table_schema.header.index(column_name)
if i not in header_idxs:
result_table_schema.header.append(column_name)
header_idxs.append(i)
result_table_schema.rows = [[row[idx] for idx in header_idxs] for row in original_table_schema.rows]
return result_table_schema
まとめ
そういうわけで、おもしろく実装することができました。
実際のプロダクションではインデックスなどを使って高速化することがとてもとても重要になってくると思います。でも、そんなときでもこの「ネストしてループしているんだなあ」ということを頭にぶちこんでおくと、「ネストしてループしているから遅いんだなあ〜」というように考えることができてお得です。(もちろん、ネストしてループしてなくても遅いということもあります)
何かの役に立てばうれしいです。間違っているところ、ご助言等あればおしえていただきたいです。
ソース
Discussion