OSS版OpenMetadataでBigQueryのメタデータ管理してみた
こんにちは。Acompany新卒のハルカです。
CEOに同姓の高橋さんがいるので、私はハルカさんと呼ばれています。
OSS系のデータカタログの1つであるOpenMetadataを触ってみました。公式サイトからサンドボックス版を試すことができますが、今回はDockerを使ってローカル環墐で立ち上げて、BigQueryとの連携を試してみました。
OpenMetadataとは?
OpenMetadataは、OSSのデータカタログの1つです。データ検出、ガバナンス、データ品質、オブザーバビリティ、コラボレーションなど、幅広い機能を提供しています。
以下の特徴があると言われています。
- 直感的なユーザーインターフェースにより、データを素早く見つけられる
- メタデータの追加・編集、ロールベースのアクセス制御が可能
- データのリネージュ(系統)を可視化し、データパイプラインやETL処理でのデータの変化・加工を追跡できる
- データ品質テストやプロファイリング機能により、データの完全性や正確性を監視できる
- 柔軟性とカスタマイズ性が高く、コミュニティによる活発な開発で継続的に機能改善される
OpenMetadataかDataHubか?
OSS系のデータカタログでは他にもLinkedInが作ったDataHubなどがあります。
この2つはよく比較されることが多いですが、以下のような違いがあります。
| 項目 | OpenMetadata | DataHub |
|---|---|---|
| 開発開始年 | 2021年 | 2019年 |
| アーキテクチャ | シンプルな構成を志向。MySQLとElasticsearch、AirFlowで構成可能 | スケーラビリティを重視した分散アーキテクチャ。Kafka、Elasticsearch、Neo4jなど多数のコンポーネントで構成 |
| メタデータ管理 | 必要最小限のデータ構造で機能を実現。The Open Metadata Type Systemによるメタデータの分類と整理 | 柔軟にエンティティを追加できるデータモデル設計 |
| データリネージ | データアセット間のリネージを自動で生成。PIIデータのフラグ付けとリネージ伝搬が可能 | 影響分析のためのデータリネージ生成機能あり |
| データ品質 | データ品質管理機能あり。独自仕様のテスト追加が可能 | - |
| PII(個人情報)管理 | PIIデータの自動タグ付け機能あり。リネージを通じてPII情報を伝搬 | - |
| 費用 | OSSだが、SaaS版の提供も予定 | 完全なOSS |
| コミュニティ | 2021年から本格的に活動開始。Collate社が中心に開発 | 2019年からのOSSプロジェクトとして確立されたコミュニティ |
| サポート | OSSコミュニティによるサポート | LinkedInによる継続的な開発とOSSコミュニティのサポート |
UIや検索の使い勝手、データリネージの可視化、データ品質管理など、OpenMetadataはデータカタログとしての機能を強化している印象です。
OpenMetadataの準備
以下の環境で検証しました。
- マシン: MacBook Pro(M2 Pro)
- OS: macOS Sonnoma 14.4.1
Dockerの準備
公式DocにDockerとDocker composeのバージョンが指定されているのでそれに従います。
Docker Desktop on Macからインストールします。
上記のデスクトップ版パッケージであれば、Docker ComposeはDockerと同時にインストールされます。但し、homebrewでDockerをインストールした場合は、別途Docker composeのインストールが必要でした。
- Docker: version 20.10.0 以上
- Docker Compose: version v2.1.1以上
$ docker --version
Docker version 25.0.3, build 4debf41
$ docker compose version
Docker Compose version v2.24.6-desktop.1
OpenMetadataの立ち上げ
作業用のディレクトリを作成して移動します。
$ mkdir openmetadata-docker && cd openmetadata-docker
公式docに従い、Dockerコンテナを立ち上げます。
PostgreSQLを使った起動
curlかwgetでdocker-compose-postgres.ymlをダウンロードします。
curl -sL -o docker-compose-postgres.yml https://github.com/open-metadata/OpenMetadata/releases/download/1.3.1-release/docker-compose-postgres.yml
or
wget https://github.com/open-metadata/OpenMetadata/releases/download/1.3.1-release/docker-compose-postgres.yml
立ち上げ
docker compose -f docker-compose-postgres.yml up --detach
MySQLを使う場合
curlかwgetでdocker-compose-mysql.ymlをダウンロードします。
curl -sL -o docker-compose.yml https://github.com/open-metadata/OpenMetadata/releases/download/1.3.1-release/docker-compose.yml
or
wget https://github.com/open-metadata/OpenMetadata/releases/download/1.3.1-release/docker-compose.yml
docker compose -f docker-compose.yml up --detach
以下のURLにアクセスするとOpenMetadataのホーム画面が表示されます。
http://localhost:8585
初期のユーザーはadmin、パスワードはadminです。

OpenMetadata Home画面
新規ユーザー登録
ユーザー登録画面から新規ユーザーを登録します。
以降の作業には管理者権限が必要なため、「Settings」→「Team & User Management」→「Admins」と進み、管理者アカウントを作成します。

設定

Team & User Management
一般ユーザーから管理者へ変更
新規ユーザー登録時には一般ユーザーとして作成した場合、以降の作業で必要な管理者権限を付与するために「Roles」に「Admin」を追加します。

初期のadminからログアウトして、作成したアカウントで再度ログインします。
データソースの登録: BigQuery
本記事ではBigQueryとの連携を試してみます。
以下のドキュメントに従い、BigQueryの設定を行います。
BigQuery側の準備
「IAMと管理」→「サービスアカウント」→「サービスアカウントを作成」からサービスアカウントを作成します。
作成したサービスアカウントにBigQueryの閲覧権限を付与します。
必要な権限
OpenMetadataがBigQueryのメタデータを取得するために、以下の権限が最低限必要です。[1]
| 権限 | 必要な理由 |
|---|---|
bigquery.datasets.get |
メタデータ取り込みに必要 |
bigquery.tables.get |
メタデータ取り込みに必要 |
bigquery.tables.getData |
メタデータ取り込みに必要 |
bigquery.tables.list |
メタデータ取り込みに必要 |
resourcemanager.projects.get |
メタデータ取り込みに必要 |
bigquery.jobs.create |
プロファイリングに必要 |
これらの権限を持つカスタムロールを作成し、OpenMetadataとの連携に使用するサービスアカウントに割り当てます。
ポリシータグを使用している場合
BigQueryのテーブル列にポリシータグを付与してアクセス制御を行っている場合、追加で以下の権限が必要です。[1:1]
| 権限 | 必要な理由 |
|---|---|
datacatalog.taxonomies.get |
ポリシータグの取得に必要 |
datacatalog.taxonomies.list |
ポリシータグの取得に必要 |
OpenMetadataはこれらの権限により、ポリシータグを取得して該当の列にアタッチします。
権限が設定できたら、Json形式の認証情報をダウンロードして、そのファイルを基にOpenMetadata側の設定を行います。
OpenMetadata側の設定
OpenMetadataのホーム画面から「Settings」→「Services」→「Databases」→「Add New Service」を選択します。
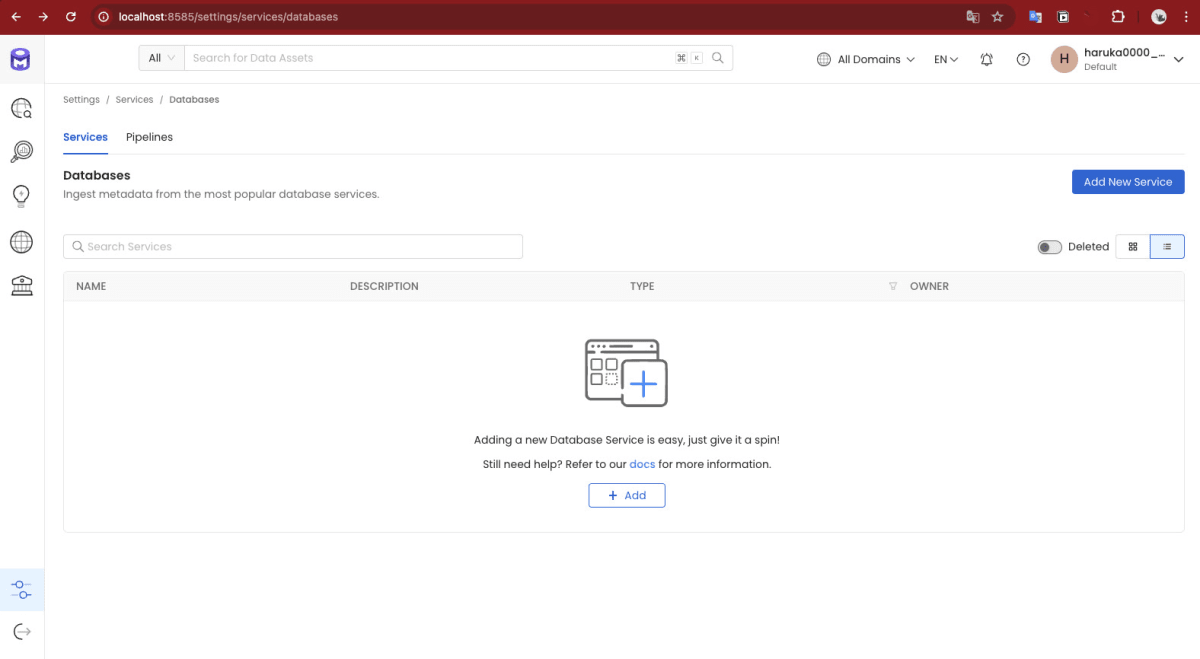
データベースの追加
データベースの追加は次の3つのステップで行います。
-
Serviceの選択
Database ServicesからBigQueryを選択して次へ進みます。
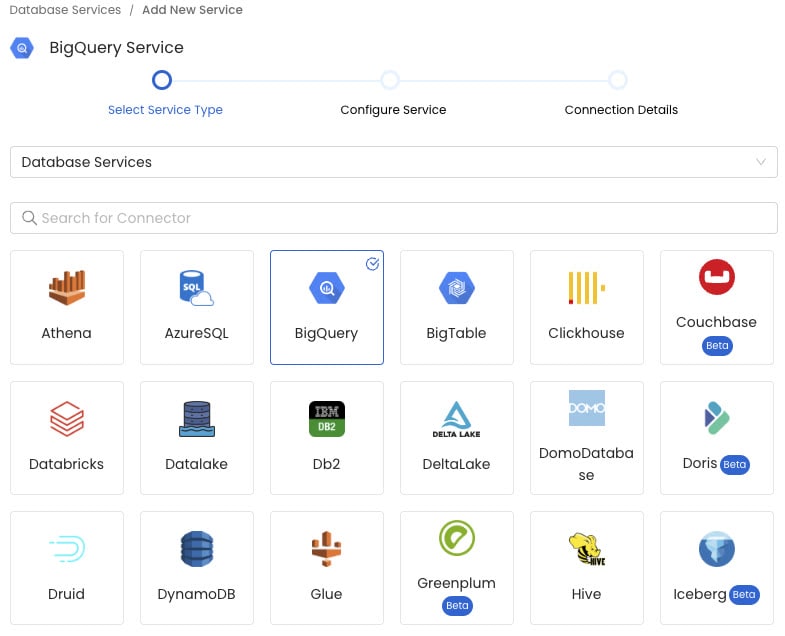
BigQueryを選択 -
サービス情報の設定
Configure Serviceで、「Service Name」と「Description」を入力して次へ進みます。 -
認証情報を入力
ダウンロードしたJsonファイルを開いて、Connection detailsの対応する項目を入力します。

Connection details -
接続テスト
「Connection Test」をクリックして、接続テストを行います。
以下のようにすべての項目がSuccessとなれば接続成功です。権限が足りないと、一部の項目の接続に失敗することがあります。

データの取得
データベースの追加が完了したら、BigQueryのテーブルを取得してみます。
データの取得にはIngestionsという機能を使います。
Ingestions
Ingestionsとは、様々なデータソースからメタデータを取り込むためのワークフローを指します。
具体的には、
- 様々なデータソース(データベース、BI ツールなど)からメタデータを抽出
- 必要に応じてメタデータを変換・加工
- OpenMetadataのメタデータカタログに取り込む
という一連のプロセスを指します。
Ingestionsのバックエンドには、Apache Airflowが使われていて、AirflowのDAG(Directed Acyclic Graph)として定義されています。
メタデータ取り込み
作成したDatabase Serviceの「Ingestions」タブから、
「Add New Ingestion」→ 「Add Metadata Ingestion」
を選択します。
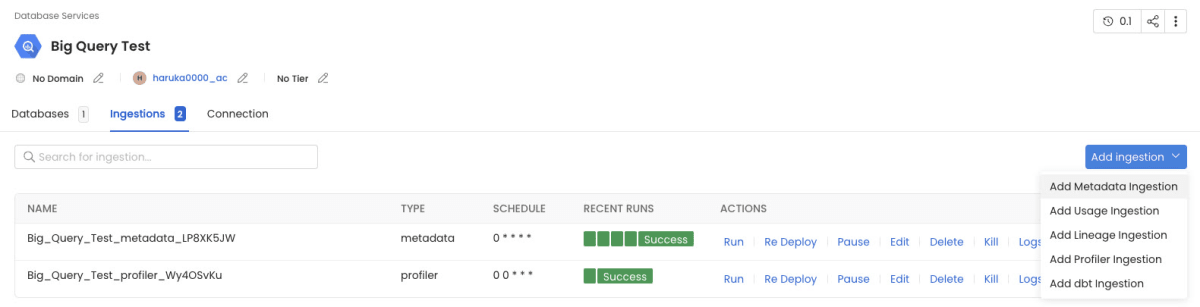
次に、取り込み設定を行います。

フィルタリング
Metadata Ingestionで連携先のデータソースから取得するデータベース/スキーマ/テーブルをフィルタリングすることができます。
-
Include
正規表現を使ってデータベースを明示的に含めることができます。
OpenMetadataは、指定された正規表現の1つ以上に名前が一致するすべてのデータベースを含めます。その他のデータベースは除外されます。 -
Exclude
正規表現を使ってデータベースを明示的に除外することができます。
OpenMetadataは、指定された正規表現の1つ以上に名前が一致するデータベースをすべて除外します。その他のデータベースは含まれます。
| Include | Exclude | 動作 |
|---|---|---|
| 空 | 空 | すべてのデータベース/スキーマ/テーブルが取り込まれる |
| 指定 | 空 | Includeで指定したデータベース/スキーマ/テーブルのみ取り込まれる |
| 空 | 指定 | Excludeで指定したデータベース/スキーマ/テーブルを除いたものが取り込まれる |
| 指定 | 指定 | IncludeとExcludeの積集合:Includeに一致し、かつExcludeに一致しないものが取り込まれる |
その他に設定できる項目
その他に設定できる項目は以下の通りです[1:2]。
| オプション | 説明 |
|---|---|
| Enable Debug Log | デバッグログを有効にする。 |
| Mark Deleted Tables | 削除されたテーブルにマークを付ける。 |
| Mark Deleted Stored Procedures | 削除された保存プロシージャにマークを付ける。 |
| Include Tables | テーブルを含める。 |
| Include Views | ビューを含める。 |
| Include Tags | タグを含める。 |
| Include Owners | 所有者を含める。 |
| Include Stored Procedures | 保存プロシージャを含める。 |
| Query Log Duration | クエリログの期間を設定する。 |
| Query Parsing Timeout Limit | クエリパースのタイムアウト制限を300秒に設定する。 |
| Use Fqn For Filtering | フィルタリングにFQN(完全修飾名)を使用する。 |
| DisplayName | 表示名を設定する。 |
メタデータ取り込みの実行
Nextをクリックして、Ingestions一覧の画面に遷移します。
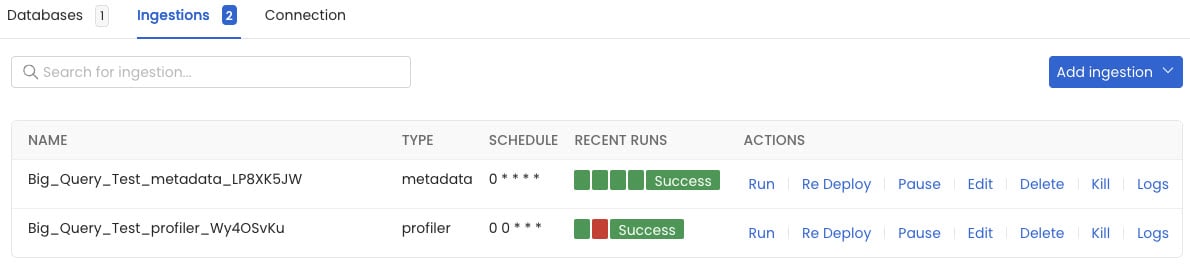
Ingestions一覧
TYPEが「metadata」の先ほど作成したIngestionを選択して、右の「Run」ボタンをクリックします。
RECENT RUNSが「Running」から「Success」に変われば、メタデータの取り込みが完了です。
メタデータの確認
Exploreタブから、取り込んだテーブルのメタデータを確認できます。

Explore
スキーマ
テーブルを選択すると、そのテーブルのスキーマやプロパティを確認できます。
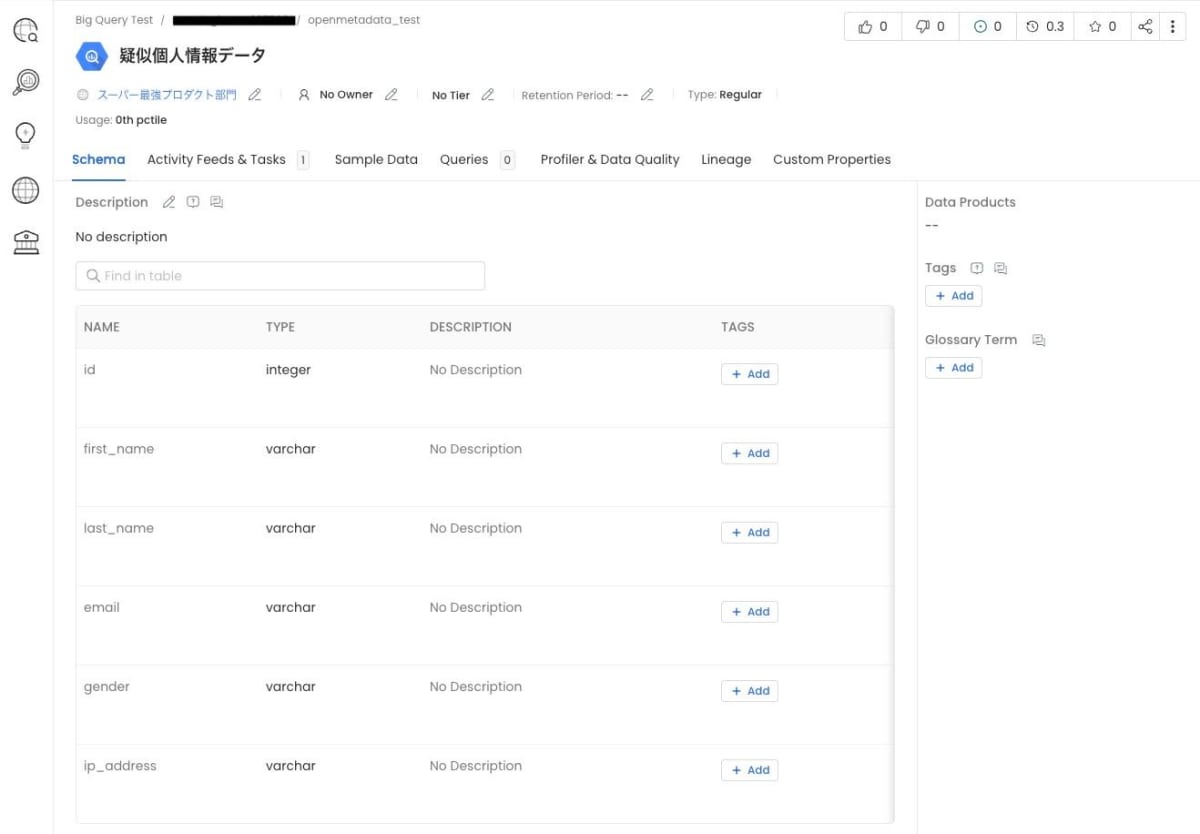
スキーマ
リネージ
リネージを確認することもできます。今回はBigQuery側で特にリネージを設定していないため、現在のテーブルのみが表示されます。

リネージ
サンプルデータ
IngestionsにProfiler Ingestionを追加することで、BigQueryのテーブルから、任意の数の行をランダムにサンプリングして表示することができます。今回は試しに3件を表示してみました。

サンプルデータ
データの品質テスト
Profiler & Data Qualityタブから、データの品質テストを行うことができます。
「first_nameがNULLでないこと」を確認するテストを追加してみました。

データ品質テストの作成
反映までに若干時間がかかるかもしれませんが、テストが完了すると、テスト結果が表示されます。
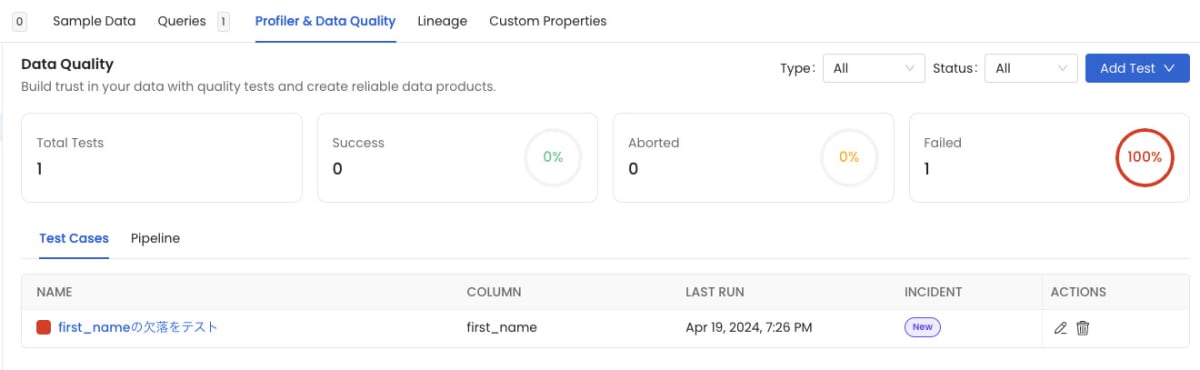
データ品質テストの結果
今回は、意図的に「fist_name」にがNULLのデータを追加していたため、テストが失敗しています。このように、テスト項目を追加してデータの品質を監視することで、データの異常をいち早く検知することができます。また、データの品質を一定に保つことで、アナリストやデータサイエンティストが信頼できるデータを使って分析を行うことができます。
まとめ
今回は、OpenMetadataの概要と、BigQueryとの連携を試してみました。
データカタログとしての機能を強化しているOpenMetadataは、データの可視化やデータ品質管理など、データ活用に必要な機能を提供しています。
また、データソースの追加やメタデータの取り込み、データ品質テストなど、UIも直感的で使いやすい印象でした。
ドキュメントも充実しているため、データエンジニアリング勉強中の私でも、比較的スムーズに試すことができました。
おわりに
Acompanyでは、我々と一緒にプライバシーテックの領域で世界を目指してくれるメンバーを募集しています。まずは、カジュアル面談でAcompanyという会社のことを知ってもらいたいです。
また、弊社の他のブログは以下エンジニアブログハブから見られます!
Discussion