Random Forestの学習曲線を描いていく
はじめに
人間たるもの、やっぱりグラフを見ることに喜びを感じますよね?
そんな人間の皆様のために、この記事ではランダムフォレスト(Random Forest, 以下RF)の学習曲線[1]を描く方法を紹介します。
グラフを見ることに喜びを感じない皆様にとっても、皆様のRFモデルがちゃんと弱学習木を増やすごとに性能を改善させられているのか気になると思います。
RFの学習曲線を見る意味
ディープラーニングのモデルなんかでは学習に時間がかかることや、(学習の不安定性を持つモデルなどは)損失が発散してしまったりするので、学習曲線を見るメリットがわかりやすいです。
しかしなぜRFで弱学習木の数ごとに評価指標を描いたグラフを見ることに意味があるのでしょうか?
それに対する私なりの答えは、「RFのオーバーフィット具合を確かめるため」です。
例えば、アウトオブサンプルでの学習曲線が右肩下がりになっていれば訓練データへのオーバーフィットを疑ったり、木ごとの多様性が足りないかもしれないと疑うこともできます。(訓練データへのオーバーフィットを防ぐためにはmax_depthを下げたりすると良いかもしれません。木ごとの多様性が足りない場合、バギングの際に選ぶ特徴量の割合を下げたりすると良いかもしれません。)
実装
アヤメの分類データについて実装した場合です。多クラス分類問題をRFで解いて、クロスエントロピーロスをグラフに表示しています。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
data = load_iris()
X = data.data[:, :]
y = data.target
label_num = np.unique(y).size
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, shuffle=True)
rf_param = {
'n_estimators': 100,
'max_depth': 3,
'max_leaf_nodes': 4,
'random_state': 60,
'max_samples': 0.1
}
rf_model = RandomForestClassifier(**rf_param)
rf_model.fit(X, y)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import log_loss
# plot metrics by n_estimators
# cf: https://www.kaggle.com/code/ahmedabdulhamid/best-n-estimators-for-randomforest
def evalplot_by_n_estimators(x, y, title):
prediction_array = np.ndarray((x.shape[0], label_num))
scores = list()
tree_cnt = 0
for tree in rf_model.estimators_:
pred = tree.predict_proba(x)
prediction_array = float(tree_cnt) / float(tree_cnt + 1) * np.nan_to_num(prediction_array, nan=0.5) + np.nan_to_num(pred, nan=0.5) / float(tree_cnt + 1)
scores.append(log_loss(y, prediction_array))
tree_cnt += 1
assert tree_cnt == len(rf_model.estimators_)
n_estimators = range(1, tree_cnt+1)
plt.figure(figsize=(10, 6))
plt.plot(n_estimators, scores, label=title)
plt.xlabel('Number of Estimators')
plt.ylabel('Score')
plt.title(title)
plt.legend()
plt.grid(True)
plt.show()
import numpy as np
evalplot_by_n_estimators(X_train, y_train, "cross entropy loss score in sample")
evalplot_by_n_estimators(X_test, y_test, "cross entropy loss score out of sample")
結果
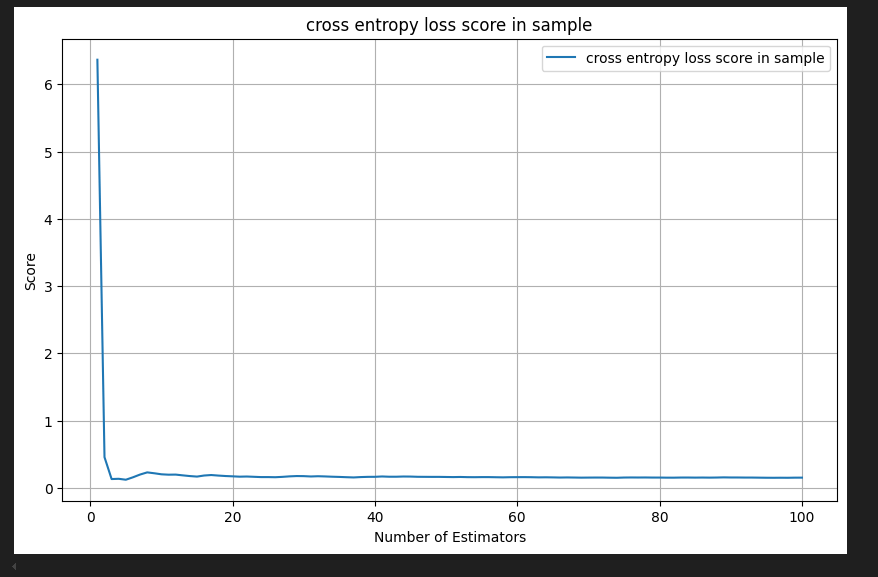
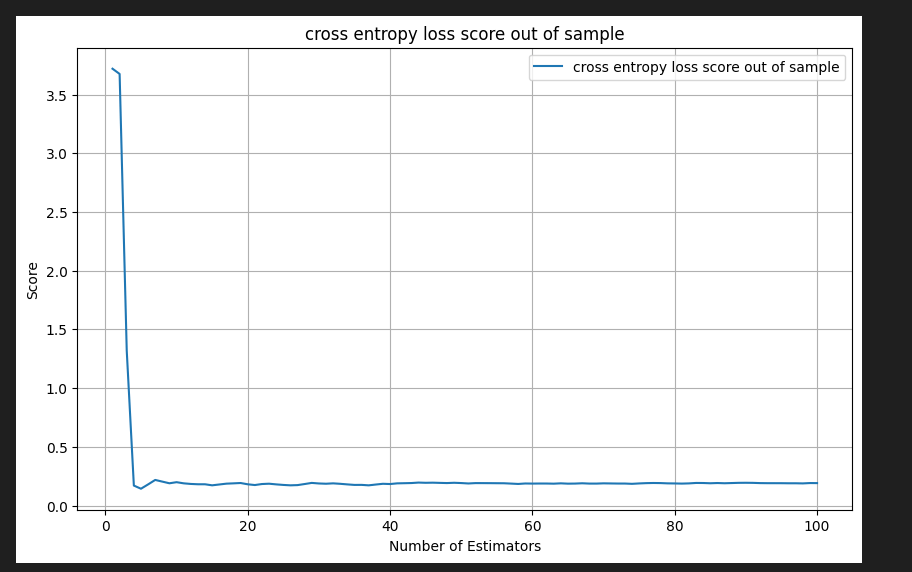
あまり面白味のないグラフができあがりました。Irisデータセットは簡単すぎたようです。
(仮想通貨の価格予測問題を解くモデルでプロットしたときは、それなりに意味のありそうなグラフが出ていました)
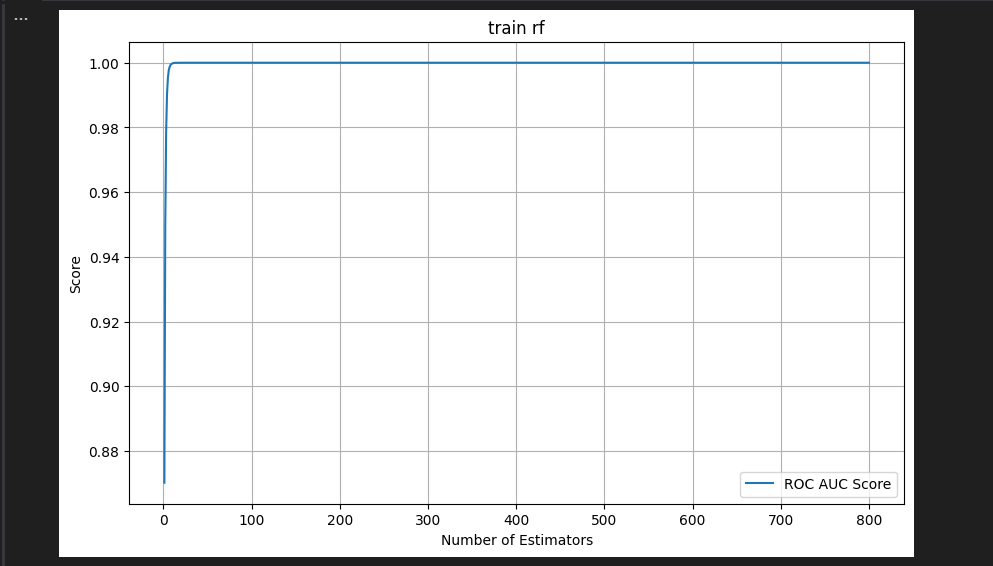
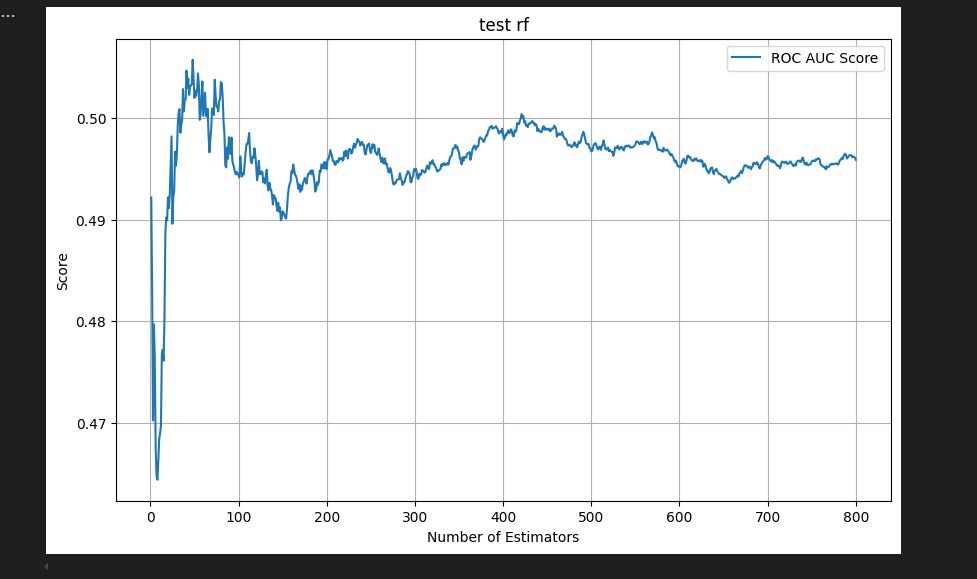
参考文献
https://www.kaggle.com/code/ahmedabdulhamid/best-n-estimators-for-randomforest この記事の実装を参考にしましたが、メモリを毎回確保する実装ではRAMが足りなかったため平均をオンラインで更新するように変更しました。
-
たぶんこの呼び名は適当ではありません。しかしなんと呼ぶべきかわからなかったので、 この記事では、横軸に
n_estimators(RFを構成する弱学習木の数)を取り、縦軸に評価指標(二値分類ならROC-AUCなど)を取ったグラフのことを「学習曲線」と呼んでいます。 RFは評価指標を最小化するように学習するモデルではないので「学習」曲線という名前は微妙だと思いますし、「損失曲線」などの呼び名も同じ理由で不適切だと思っています。 ↩︎
Discussion
これスプリットする前のデータに対してfitしてしまってるのでtestもtrainもfitしきるのは当たりまえですね。