論文解説 IntentRec: Netflixにおける訪問意図を考慮したパーソナライズ推薦
この記事は、Netflixが発表した推薦システムに関する手法 IntentRecについて解説します。
ユーザーが「今、何をしたいか」という意図を予測し、それを次の推薦アイテムの予測に活用する「階層的マルチタスク学習」のアーキテクチャを提案し、Netflixの実データでSOTA(最高性能)を達成した内容です。
この論文のすごいところ
ユーザーの「次に何をしたいか」という意図 (例:新しい作品の発見、いつもの続きを視聴)を予測し、それを推薦に活かす新しい手法 IntentRecを提案しました。
「意図予測」→「アイテム予測」という階層的マルチタスク学習(Hierarchical-Multi-Task-Learning, 以下H-MTL)を採用しました。これにより、意図を予測するだけでなく、その予測結果を「特徴量」として次のアイテム推薦に利用することで、推薦精度を大幅に向上させた。Netflixの実データによるオフライン実験において、次アイテム予測および意図予測でSOTAを達成しました。
なぜこの論文を選んだか
SpotifyやNetflixのようなストリーミングサービスやAmazonのようなECサイトで推薦をする際にユーザーの訪問意図は重要です。本論文では意図を推定して、適切な推薦アイテムを決めており、非常に興味があったためです。
また、Netflixのような大規模プラットフォームが、ユーザーの「意図」という曖昧な概念をどのように定義し、モデル化しているかに純粋な興味がありました。
論文解説
概要 (Abstract)
背景/課題
- 推薦システムにおいて、ユーザーがそのセッションで「何をしたいか」という意図(例:前見た動画の続きを見たい、新しい動画を探したい)が分かれば、より質の高い推薦が可能である。
- しかし、従来の推薦モデルは、この「意図」を直接扱えていないか、扱えても次アイテム予測との連携が不十分であった。
提案手法
- 本論文では IntentRec という新しい推薦フレームワークを提案した。
- これは、ユーザーのインタラクション系列(暗黙的フィードバック)を用いて、まずユーザーの潜在的な意図を予測し、次にその意図予測の結果を追加の特徴量として利用して、次にインタラクションするであろうアイテムを予測する階層的マルチタスク学習(H-MTL)アーキテクチャを採用した。
結果
- Netflixの実際のユーザーログデータを用いたオフライン実験により、IntentRec が次アイテム予測および次意図予測の両方で、既存のSOTAモデルを著しく上回る性能を示すことを実証した。
既存研究とこの論文の位置づけ (Introduction / Related Work)
意図を推定することの重要性
従来のシーケンシャル推薦モデルは、主にユーザーの過去の行動履歴に基づいて「次に何を見るか」を予測することに焦点を当ててきた(例: SASRec, BERT4Rec)。
しかし、同じ行動履歴を持っていても、ユーザーのその時々の「意図」によって、次に求めるアイテムは大きく異なる。
例えば、「新作映画をじっくり探したい」: 発見意図 の場合と、「昨日見ていたドラマの続きが見たい」: 継続視聴意図 の場合では、推薦すべきアイテムは全く異なる。
このように、ユーザーの潜在的な意図を推測することは、より精度の高い、パーソナライズされた推薦を行う上で非常に重要であり、近年活発に研究されている。
既存の意図推定モデルの課題
近年、この「意図」自体を予測しようとする研究も登場している (例: TransAct)。しかし、既存の意図予測モデルには大きく2つの限界があった。
- 階層の欠如: 意図予測とアイテム予測を並列に行う単純なマルチタスク学習(MTL)が主流であり、意図予測の結果がアイテム予測の精度向上に直接的に活用されていなかった。
- 短期興味と長期興味の協調: ユーザーの「短期的な興味」(例:今夜だけホラー映画が見たい)と「長期的な嗜好」(例:普段はコメディが好き)を分離してモデル化することが難しかった。
そこで、IntentRecは、(1) 意図予測を先に行い、その結果をアイテム予測の入力とする「階層的マルチタスク学習(H-MTL)」を採用し、(2) 短期的興味を別エンコーダでモデル化し、入力特徴量に加えるアプローチにより、これらの課題を解決した。
提案手法 (Methodology)
手法のコンセプト
提案手法の最も重要なアイデアは、「意図が分かれば、推薦はもっと簡単になる」という直感をアーキテクチャに落とし込んだ点。
従来のモデルが「行動履歴 → 次のアイテム」を直接予測しようとしていたのに対し、 IntentRec は 以下の2段階(階層的)な予測を行う。
- 行動履歴 → まず、"意図" を予測
- 行動履歴 + "予測した意図"→ 次のアイテム
これにより、例えばモデルが「このユーザーは "発見" モードだ」と予測した場合、アイテム予測器は既知のアイテムよりも新規のアイテムを重視するよう調整でき、よりパーソナライズされた推薦が可能になる。
手法の詳細
IntentRec のアーキテクチャは、「入力特徴の構築」「ユーザー意図予測」「次アイテム予測」の3つの主要コンポーネントで構成される。

意図の定義
ユーザー意図は、直接観測できない潜在的なものである。
その代理変数(プロキシ)として、論文 ではユーザーの行動(動画再生など)に関連するメタデータ(暗黙的シグナル)の組み合わせを「意図」として扱います。
具体的には、以下の4つのメタデータが「意図」として定義されました。
- Action Type: ユーザーの行動カテゴリ (例: 新規発見, 継続視聴など)
- Genre: 視聴したジャンル (例: スリラー、アニメ)
- Movie/Show: アイテムの種別 (映画かTV-Showか)
- Time-since-release: リリース時期 (例: 新作か旧作か)

入力特徴の構築
長期的な興味を表す特徴
まず、ユーザーの長期的な行動履歴全体を特徴量シーケンス
具体的には、過去の各インタラクション
これらのメタデータは「カテゴリカル特徴」と「数値特徴」に分類されます。
- カテゴリカル特徴 (アイテムID, ジャンル等): それぞれEmbeddingレイヤーを適用し、密なベクトルに変換する。
- 数値特徴 : 正規化(例: 0〜1)され、1次元特徴量として扱う
これら全てのベクトルと数値を連結 (concatenate, ⊕) することで、その瞬間の行動
短期的な興味を表す特徴
長期とは別に、短期興味 (Short-term Interest) をモデル化するため、直近H時間(論文では1週間)の行動履歴だけを別の Short-term Transformer Encoder
ここで、
最終的な入力特徴
最終的な入力シーケンスは、この2つを結合したもの
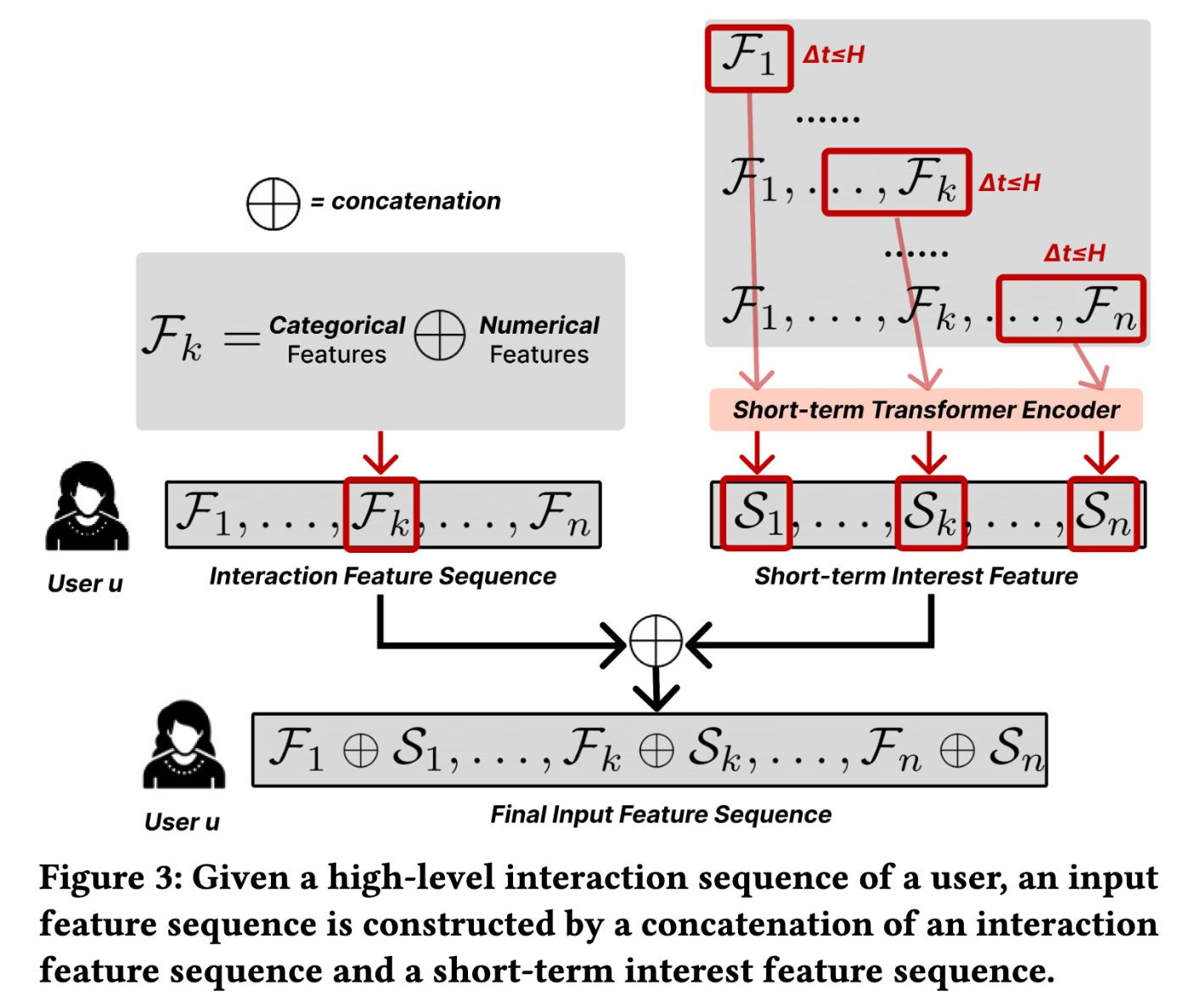
ユーザー意図予測
ステップ1で作成した入力シーケンス (F ⊕ S) を全結合層に入れ、次元削減と正規化をした後、意図予測用のTransformer (Transformer Intent Encoder) に入力する。ここで、TransformerのPositional Encoderには、timestamp embeddingを使用した。
エンコーダの出力シーケンス
1. Action Type: ユーザーの行動カテゴリ (例: Discovering, Continue Watching)
2. Genre: 視聴したジャンル
3. Movie/Show: 映画かTVショウか
4. Time-since-release: 新作か旧作か
以下の式のようにして、各意図のラベルの所属確率を予測します。ここで、
最後にこの4つの意図の予測結果(確率ベクトル)を、Attentionレイヤーで重み付け集約し、そのユーザーの統合意図埋め込み (User Intent Embedding)
ここで、

次アイテム予測
アイテム予測
これまでの全ての特徴量、すなわち F (行動履歴), S (短期興味), そして Z (予測された意図) を全て結合する。
この意図を含めた特徴量シーケンスを、全結合層で次元削減と正規化した後、アイテム予測用のTransformer (Transformer Item Encoder) に入力する。意図用とアイテム用で2つの異なるTransformerエンコーダを使のがポイントであり、重みを共有した場合と比べて性能が良かった。
Transformerで作成した表現
階層的マルチタスク学習 (H-MTL)
アイテム予測の損失関数は、以下のCross-Entropyの通り。ここで、インタラクション期間が長いpositionには大きな価値があるため、重み
もし、ある意図が複数マルチラベルの場合(例: Genre = "romance" + "comedy")は、上記の式をBinary Cross Entropyに変更し、intentラベルごとのsumを一つ増やす。
最終的な学習時の損失関数は、ステップ2の意図予測の損失

実験と結果 (Experiments / Results)
実験方針
著者らは、提案手法 IntentRec の有効性を証明するため、主に以下のResearch Question (RQ) に答えようとした。
-
Q1 (SOTA比較):
IntentRecは、既存のSOTA(最高性能)モデル (例: TransAct) よりも次アイテム予測・意図予測の精度が高いか? - Q2 (Ablation Study): 提案手法の階層的MTLや短期興味モデリングは、本当に性能向上に寄与しているか?
- Q3 (Ablation Study): 予測した4つの意図のうち、どれが次アイテム予測に最も重要だったか?
-
Q4 (定性評価): 獲得された意図埋め込み
Zは、人間の直感に合う、解釈可能なものになっているか?
実験設定
- データセット
- Netflixの独自のユーザーエンゲージメントデータ。大規模かつノイズの多い実データ。
- 比較手法
- LSTM, GRU, Transformer : 標準モデル
- SASRec, BERT4Rec : シーケンシャル推薦の代表的手法
- TransAct: Pinterestが発表した、当時のSOTA意図予測モデル
- IntentRec-V0: Netflixの既存の社内モデル。意図予測なし
- 評価指標
- SOTAであるTransActを0%とした場合の相対的なAccuracy改善率 (%)で評価。
実験結果と考察
Q1 (SOTA比較) - Table 1:
-
次アイテム予測:
IntentRecは、SOTAのTransActに対して +7.40%、社内モデルIntentRec-V0に対して +8.22% (0.82+7.40) という、統計的に有意かつ大幅な精度向上を達成した - 意図予測: Action Type予測(+3.31%) やGenre予測(+2.78%) など、全ての意図予測タスクにおいても、既存のSOTAを上回った。

Q2 (Ablation Study) - Table 2:
-
IntentRecのどの部分が性能向上に効いたのかを分析した。(V1をベースライン=0%として比較) -
階層構造の有効性
- 単純なMTL (V1) から、意図予測の結果を入力に使う階層的MTL (V2) に変更するだけで、次アイテム予測性能が +4.53% 向上した。これは、H-MTLアーキテクチャ自体が非常に有効である強力な証拠である。
-
短期興味の有効性
- V2に短期興味モデリング (V3) を追加すると、性能はさらに向上し、ベースライン比で +8.56% (1-week) に達した。短期興味を明示的にモデル化することも重要だったことが分かる。

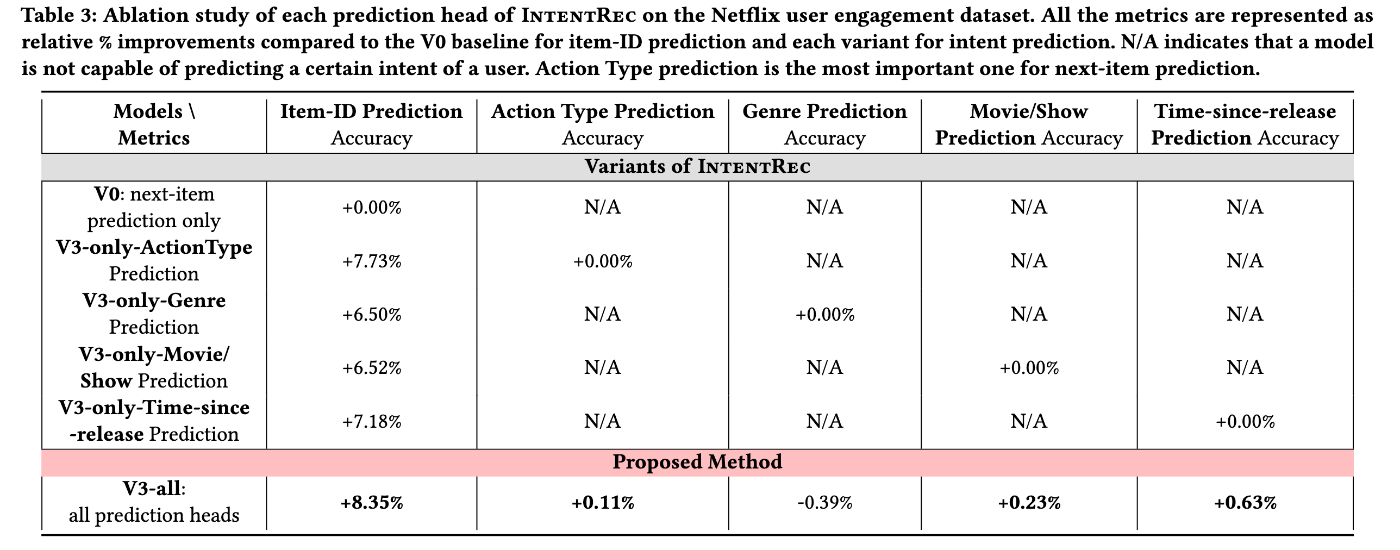
Q3 (Ablation Study) - Table 3:
- 4つの意図タスク(Action Type, Genre, Movie/Show, Time-since-release)のうち、どれか1つだけを使って次アイテム予測を行った場合の性能を比較している。(意図なしのV0モデルをベースライン=0%として比較)
- 結果、Action Type予測 (+7.73%) が、次アイテム予測の精度向上に最も大きく寄与していた。
- これは、「ユーザーが今 "新しいものを発見" したいのか、"いつもの続きを視聴" したいのか」というマクロな行動モードを捉えることが、推薦精度に最も直結することを示唆している。
Q4 (定性評価) - Fig 6, 7:
-
意図埋め込みの可視化 (Fig 6): ユーザーの意図埋め込み
Zをt-SNEで2次元に圧縮して可視化したところ、意味のあるクラスターが形成されていた。例えば、「User Group 1: Explorer (新しいコンテンツを発見する人)」、「User Group 3: Rewatcher (同じものを繰り返し観る人)」、「User Group 2: Anime & Kids Enthusiasts」などが明確に分離されており、モデルがユーザーの主要な意図を捉えられていることがわかる。 -
Attentionの可視化 (Fig 7): 意図埋め込み
Zを作る際のAttentionの重み(どの意図タスクを重視したか)を見ると、ユーザーごとにパーソナライズされていた。- User A: Genre (ジャンル) の重みが0.52と最も高く、実際にファンタジー作品ばかり見ていた。
- User B: Time-since-release (リリース時期) の重みが0.32と高く、実際に古い作品ばかり見ていた。
- これらにより、
IntentRecがブラックボックスではなく、なぜその推薦をしたのかを「意図」ベースで説明可能であることも示された。


考察、結論、今後の展望
考察
- ドメインの一般性
- この手法はNetflixドメインに特化して調整されているが、EC(例:カテゴリ vs 商品)など、他のドメインでも適用できるようにデザインされている。ただし、意図ラベル等はドメインに応じて適切なものを考える必要がある。
- 意図とアイテム予測の矛盾について
- 意図予測が「映画」でアイテム予測が「TV-Show」といった矛盾が起こる可能性について。著者らの分析では、これらはほとんどの場合で一致していた。仮に一致しなくても、ユーザーの興味が急に変わる(映画を探していたが、新作TVショウに惹かれた)といった正当なケースもあり得ると述べている。
- ダウンストリーム・アプリケーション
- 予測された意図は解釈可能であり、ユーザーのニーズに直結するため、多くの応用に繋がると考察されている。例えば、UIの最適化(意図に基づきUIを変更する)、分析、他のMLモデルへの特徴量としての利用、そして本モデルによる既存の次アイテム予測モデルの置き換えなどが挙げられる。
結論
- 本論文は、ユーザーの潜在的なセッション意図を予測し、それを次アイテム推薦に活用する新しいフレームワーク IntentRec を提案した。
- 「階層的マルチタスク学習 (H-MTL)」と「短期・長期興味のモデリング」を組み合わせることで、Netflixの実データにおいて、次アイテム推薦・意図予測の両方でSOTAを達成した。
限界と今後の展望
- ECなど、他のドメインでも同様の階層的アプローチが有効か、さらなる検証が期待される。
- 今後は、モデルの学習をさらにスケールアップさせることや、LLM(大規模言語モデル)を組み込んで、よりリッチな意図表現(例:「SFだけど感動できる映画」)を扱えるようにすることを展望している。
記事著者の考察と実務への応用
階層構造の活用
- この論文の最大の貢献は、「意図」を単なるマルチタスクの1つ(Shared-Bottom型)として扱うのではなく、意図予測タスク(下流)の出力を、アイテム予測タスク(上流)の入力として明示的に使う「階層構造 (H-MTL)」の有効性を、実データで示した点にあると思います。
Action Typeの重要性
- Table 3で示された「Action Type(発見 vs 継続視聴など)が最も効いた」という知見は、実務上非常に重要です。ユーザーのミクロな好み(どのジャンル、どの俳優)の前に、まずマクロな「行動モード」を捉えることが、推薦の精度分岐点になることを示唆しています。
実務への応用
- Netflixほどの明確な「Action Type」ログがないサービス(例:一般的なEC)でも、この考え方は応用できるはずです。例えば、「カテゴリ内を回遊している(=探索意図)」「特定商品のスペック比較ページを往復している(=検討意図)」「カートに投入した(=購買意図)」といったユーザーの行動フェーズを「意図」として定義し、
IntentRecと同様の階層モデルを構築することが考えられます。
懸念点
- 1. 意図ラベルの定義: この手法の根幹は「良い意図ラベル」の存在にあります (Table 3で "Action Type" が最も効いたことからも明らかです)。意図ラベルの種類や粒度をどう設計するかが、ドメインごとに非常に重要であり、ここの設計を誤るとモデル全体の性能が出ない可能性があります。
-
2. 予測レイヤーのスケーラビリティ: 論文ではアイテム予測にSoftmaxを使用していますが、これはアイテム数が比較的少ないNetflixだからこそ可能です。アイテム数が数百万を超えるECサイトなどでは、出力次元が大きすぎて現実的ではありません。
- アイテム推薦候補が事前に決まっている(リランキング)文脈であれば、DCNやDINのようにpointwiseな推論層に置き換える必要があります。
- 候補が決まっていない(検索・リトリーバル)文脈であれば、Two-Towerモデルのように内積計算で対応すべきでしょう。
- いずれにせよ、
IntentRecの最終層 (Item Prediction Layer) はそのまま使えず、ドメインに応じた修正が必須です。ただし、意図を明示的に予測し、後段のモデルでその意図を活用するというコンセプト自体は、ECサイトでも大いに有効だと考えられます。
- 3. 計算コストとリアルタイム性: モデルは「短期興味用」「意図予測用」「アイテム予測用」と、実質3つのTransformerエンコーダを利用しています。これがどの程度の計算量になり、リアルタイムの推論リクエストに応えられるのかは、実務上の大きな懸念点です。
- 4. 急激な興味シフトへの追従性: 論文では「意図とアイテムの予測が矛盾しても、それは正当な興味のシフトであり得る」と考察しています。しかし、短期興味(V3)がどの程度柔軟にこれを捉えられるかは未知数であり、急激なコンテキストの変化(例:さっきまで自分用に調べていたが、子供用のアイテムを探し始めた)にどこまでリアルタイムに対応できるかは、さらなる検証が必要そうです。
- 5. エラーの伝播: このアプローチは、意図予測器の精度に依存します。もし意図予測器が間違った意図(例:本当は"探索" なのに "継続視聴" と予測)を出力した場合、それがノイズとなって次アイテム予測器の精度をかえって下げてしまうリスク(Error Propagation)も考慮する必要があるでしょう。
将来性 (ダウンストリーム・タスク):
- 論文でも「ダウンストリーム・アプリケーション」として言及されていますが、これは非常に期待できる方向性です。
- 最近、以下のSpotifyの論文 のように、検索・推薦など、サービス内の様々なタスクで共通して使える「一般化されたユーザー表現(User Representation)」の研究が注目されています。
-
IntentRecが生成する「統合意図埋め込みZ」は、まさにこの一般化ユーザー表現の一種と捉えることができます。単に次のアイテムを推薦するためだけでなく、このZをユーザーの「現在の状態ベクトル」として、検索結果のパーソナライズやUIの最適化など、様々な下流タスクに活用していく進化が期待できます。
まとめ
- Netflixが提案した
IntentRecは、ユーザーの「意図」を予測し、推薦精度を向上させるための手法です。 - そのメインアイデアは、「意図予測 → アイテム予測」という階層的マルチタスク学習 (H-MTL) にあり、これによりSOTAを大幅に超える性能を達成しました。
- 特に「ユーザーが "発見" したいのか "継続" したいのか」といったマクロな行動モード (Action Type) を捉えることが、推薦精度向上に最も重要であるという知見が得られました。
参考文献・次に読むべき論文
-
TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
- 意図予測のSOTAとして比較されたPinterestの論文
-
TransAct V2: Lifelong User Action Sequence Modeling on Pinterest Recommendation
- TransActの後継。この論文ではここで提案された階層的マルチタスク学習を取り入れている。
-
Generalized User Representations for Transfer Learning
- 後続のタスクで使えるSpotifyのユーザー表現の論文
-
Generalized user representations for large-scale recommendations | Spotify Research
- 上記論文のあとに出た論文。内容はほぼ同じ。
Discussion