😀
# 🧠 PySparkで始めるビッグデータ入門
はじめに
太しかきっかけに「ビックデータってどういうふうにいれるのか」という疑問から
Apache Spark(PySpark)を使ってみようとおもいました
Hadoopなし・Pythonだけでビッグデータ処理をします。
最終的に、CSVをリアルタイム監視してカテゴリ別売上を集計するストリーミング処理まで実装します。
①Sparkとは?
Apache Sparkは、大量のデータを並列処理する分散処理エンジンです。
単一PCのメモリ上で動くため、Hadoopより圧倒的に速い。
| 特徴 | 説明 |
|---|---|
| 高速処理 | メモリ上で実行(MapReduceの数十倍速) |
| 柔軟性 | Python / Java / Scala / R に対応 |
| 多用途 | バッチ処理・ストリーム処理・機械学習に対応 |
| オープンソース | 無料で誰でも使える |
②環境構築(Mac版)
🧩 構成
- macOS(Apple Silicon可)
- Python 3.10
- Java 17 (LTS)
- PySpark 4.0.1
②-1. PySparkのインストール
pip install pyspark
②-2. Java 17 のインストール
brew install openjdk@17
.zshrc に以下を追記します:
export JAVA_HOME="$(
/usr/libexec/java_home -v 17 2>/dev/null || echo "/opt/homebrew/opt/openjdk@17"
)"
export PATH="$JAVA_HOME/bin:/opt/homebrew/opt/openjdk@17/bin:$PATH"
確認:
java -version
# openjdk version "17.0.17"
③PySparkでバッチ集計を試す
📁 ディレクトリ構成:
pyspark_demo/
├─ data/
│ ├─ sales.csv
│ └─ customers.csv
└─ app.py
sales.csv と customers.csv はサンプルを用意済み(50行前後)。
app.py
from pyspark.sql import SparkSession, functions as F, Window
spark = SparkSession.builder.appName("PySpark-Intro").getOrCreate()
sales = spark.read.csv("data/sales.csv", header=True, inferSchema=True)
customers = spark.read.csv("data/customers.csv", header=True, inferSchema=True)
sales_enriched = sales.withColumn("amount", F.col("price") * F.col("qty"))
# カテゴリ別の集計
by_category = sales_enriched.groupBy("category").agg(
F.count("*").alias("cnt"),
F.sum("amount").alias("sales_sum"),
F.avg("price").alias("avg_price")
).orderBy(F.desc("sales_sum"))
by_category.show(truncate=False)
④リアルタイム処理を試す(Structured Streaming)
④-1. 疑似ストリームデータ生成
writer.py:
import csv, time, random, os
from datetime import datetime
os.makedirs("stream/in", exist_ok=True)
categories = ["Electronics","Home","Grocery","Sports","Books"]
while True:
path = f"stream/in/batch_{int(time.time())}.csv"
with open(path, "w", newline="") as f:
w = csv.writer(f)
w.writerow(["event_time","category","price","qty"])
for _ in range(random.randint(2,5)):
w.writerow([
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
random.choice(categories),
round(random.uniform(5, 1500), 2),
random.randint(1, 5),
])
time.sleep(2)
④-2. ストリーミングアプリ(stream_app.py)
from pyspark.sql import SparkSession, functions as F, types as T
spark = (SparkSession.builder
.appName("PySpark-Streaming-Intro")
.getOrCreate())
schema = T.StructType([
T.StructField("event_time", T.StringType(), True),
T.StructField("category", T.StringType(), True),
T.StructField("price", T.DoubleType(), True),
T.StructField("qty", T.IntegerType(), True),
])
src = (spark.readStream
.option("header", True)
.schema(schema)
.csv("stream/in"))
events = (src
.withColumn("ts", F.to_timestamp("event_time", "yyyy-MM-dd HH:mm:ss"))
.withColumn("amount", F.col("price") * F.col("qty"))
.dropna(subset=["ts","category","amount"]))
agg_base = (events
.withWatermark("ts", "2 minutes")
.groupBy(
F.window(F.col("ts"), "1 minute", "10 seconds"),
F.col("category")
)
.agg(F.round(F.sum("amount"), 2).alias("sales_sum"))
)
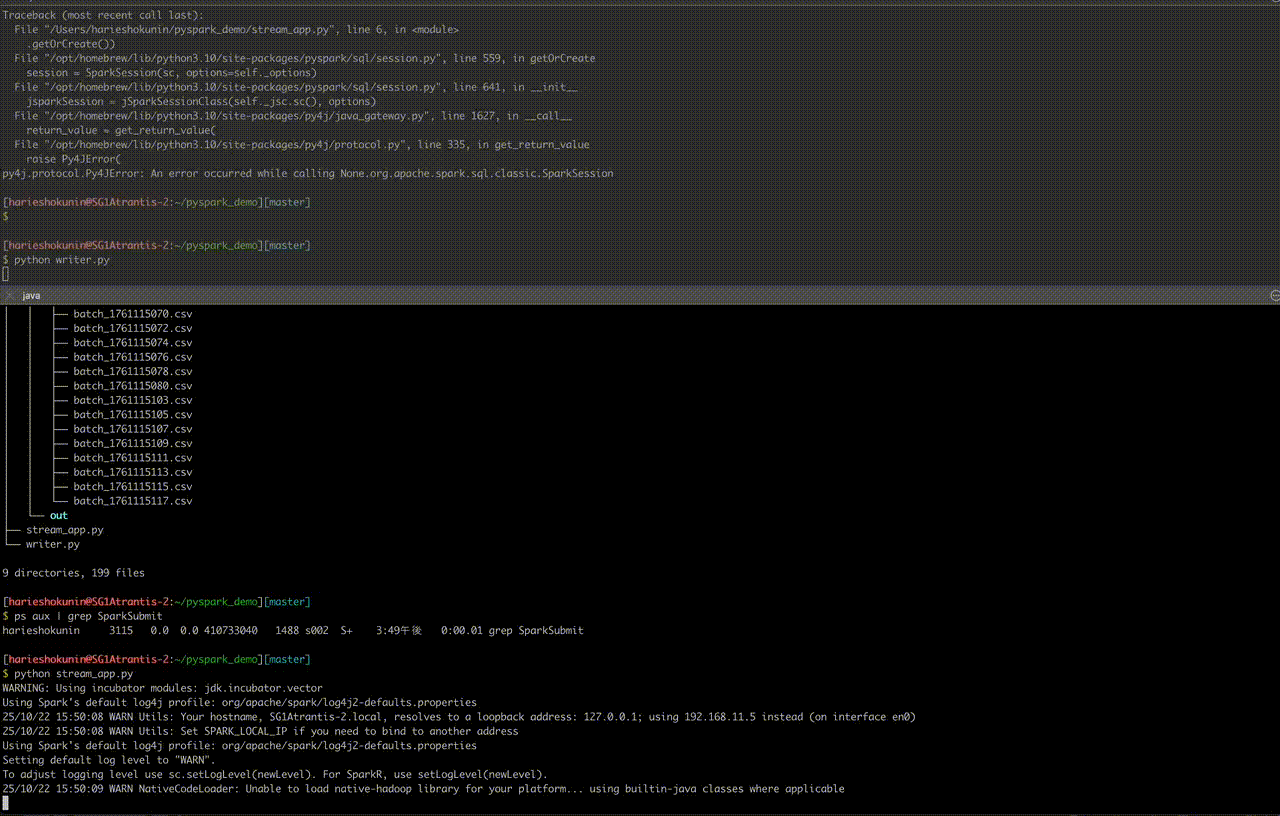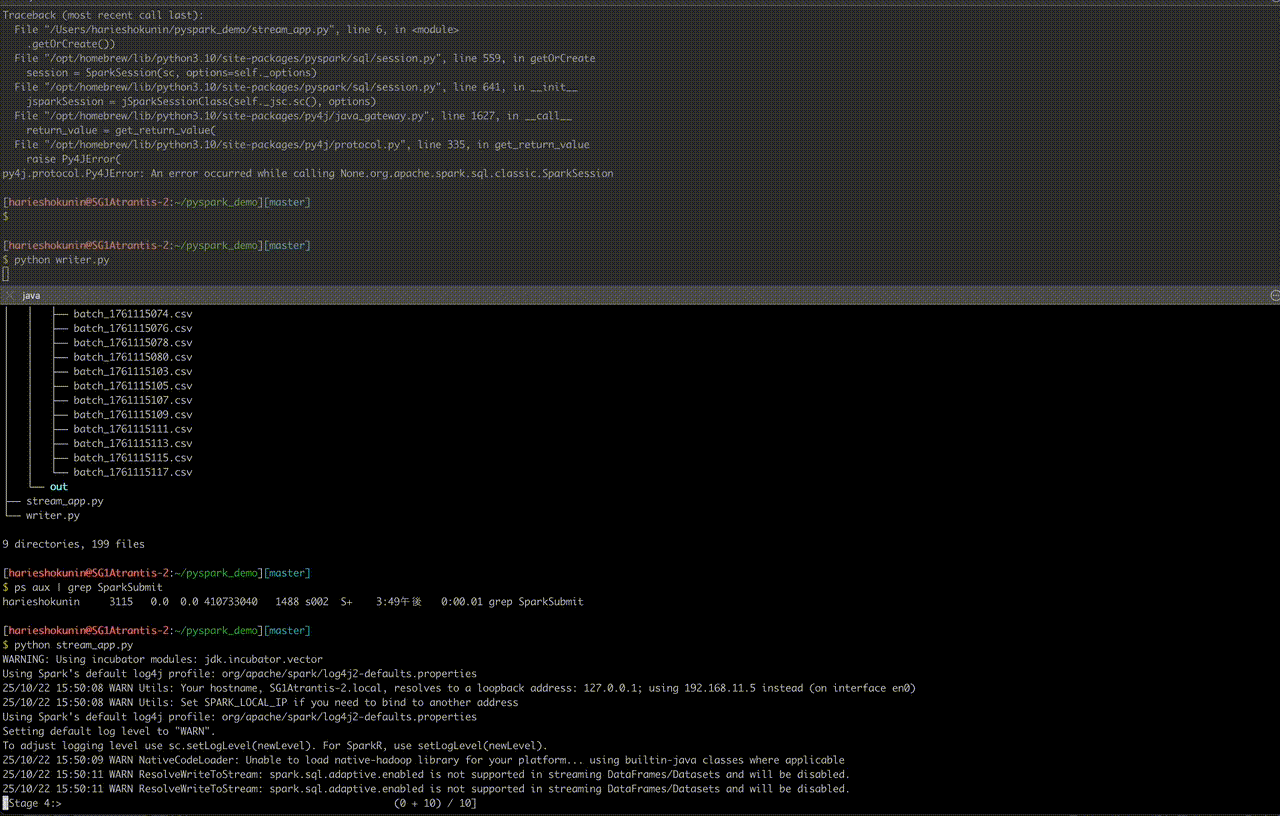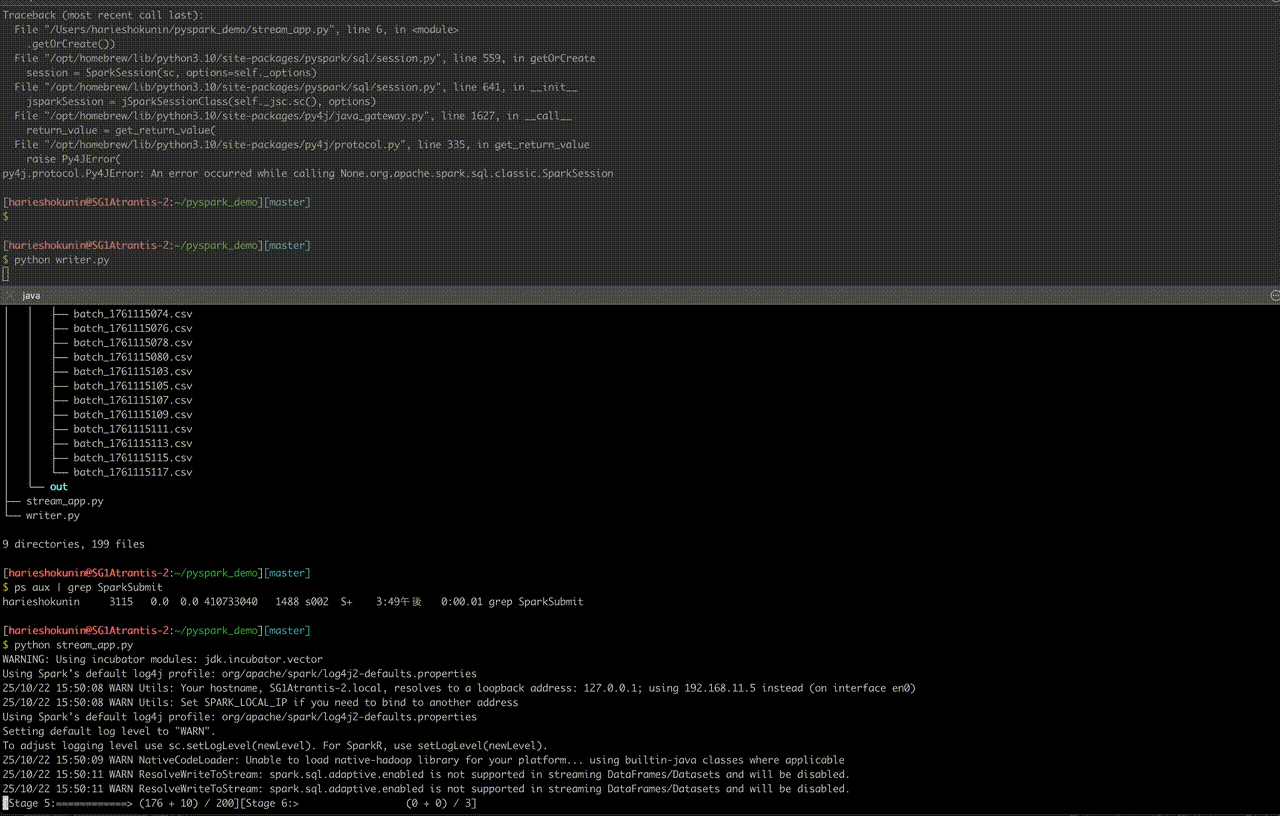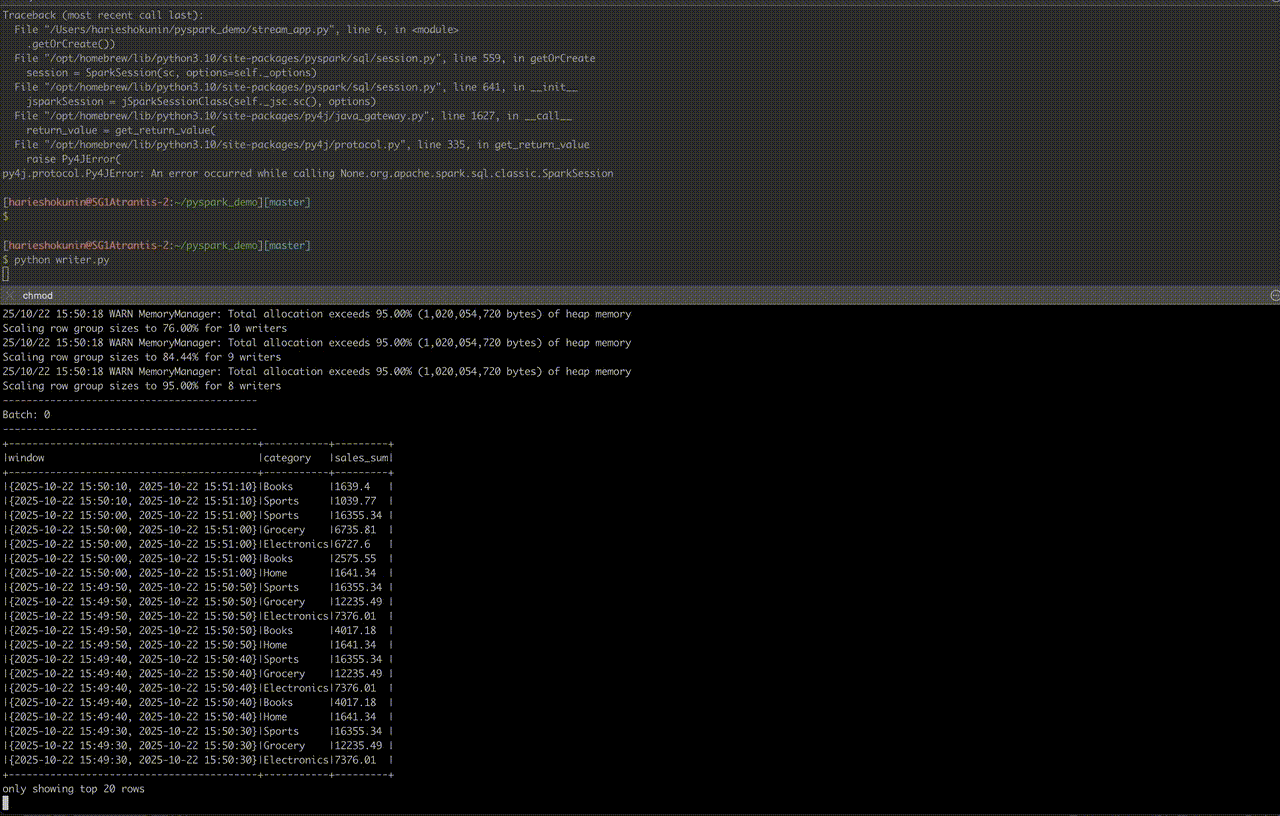
# コンソールにリアルタイム出力(completeモード)
console_df = agg_base.orderBy(F.col("window").desc(), F.col("sales_sum").desc())
q1 = (console_df.writeStream
.outputMode("complete")
.option("truncate", False)
.format("console")
.start())
# Parquetへ保存(appendモード)
q2 = (agg_base.writeStream
.outputMode("append")
.option("checkpointLocation", "stream/checkpoints")
.format("parquet")
.option("path", "stream/out")
.start())
q1.awaitTermination()
q2.awaitTermination()
④-3. 実行手順
ターミナルを2つ開く:
A:ストリーム入力
python writer.py
B:集計処理
python stream_app.py

⑤出力確認(Parquetファイル)
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Check").getOrCreate()
df = spark.read.parquet("stream/out")
df.orderBy(df.window.desc(), df.sales_sum.desc()).show(truncate=False)

参考リンク
📘 補足:次のステップ
- Delta Lake を導入して更新系テーブルを管理する
- MLlib で「次に売れそうなカテゴリ」を予測
- Dashboard可視化(StreamlitやGrafana)と連携
Discussion