[日本語訳]間違ったコードを間違って見せる(Making Wrong Code Look Wrong - Joel Spolsky)
概要
以前から原文(元記事)をご存じの方やハンガリアン記法について再三、議論した方などは何をいまさらという話題だと思いますが、
私は原文やハンガリアン記法にシステムハンガリアンやアプリケーションハンガリアンというものがあったという事を最近、知りました。
原文をしっかりと学習する為、良い日本語訳の記事を探しましたが、頭にすんなり入ってくるような記事を見つける事ができなかったので、
英語の勉強もかねて自分なりに日本語に翻訳してみました。
なお、本記事で登場するAmazonに関連する書籍のリンクは、すべてAmazonアソシエイト[1]のリンクとなります。
この記事のターゲット
- Joel Spolsky氏の記事「Making Wrong Code Look Wrong(間違ったコードを間違って見せる)」の日本語訳を見たい方
- アバウトな翻訳内容でも問題ない方
- ハンガリアン記法について、詳しく知りたい方
- “アプリケーションハンガリアン”と“システムハンガリアン”の違いをしっかり理解したい方
間違ったコードを間違って見せる - ジョエル・スポルスキ氏
以下より翻訳内容の始まり。
概念を学ぶということ
1983年9月、私ははじめて本格的な仕事に就いた。オラニムというイスラエルにある大きなパン工場で働き、航空母艦ほどもある巨大な6つのオーブンで毎晩10万個ものパンを作っていた。
はじめてパン工場に入ったときは、その惨状が信じられなかった。オーブンの側面は黄ばみ、機械は錆びつき、油だらけだった。
「いつもこんなに散らかっているのですか?」と私は尋ねた。
「え?何のことだ?」「ちょうど掃除が終わったところだ。ここ数週間で一番きれいだよ。」とマネージャーは言った。
なんてこった。
その意味がわかるまで、毎朝パン工場を掃除すること数ヶ月かかった。パン工場では、清潔とは機械に生地がついていないということ、ゴミ箱に発酵中の生地がないこと、床に生地が落ちていないことを意味していた。
清潔とは、オーブンが白くきれいであるという意味ではなかった。オーブンにペンキを塗るのは10年ごとにすることで、毎日することではない。清潔だからといって油汚れがまったくないという事ではない。実際、定期的に油を差す必要のある機械はたくさんあり、薄いきれいな油の層があれば、たいていは洗浄されたばかりの機械であることを示していた。
パン工場における清潔という概念は、学ばなければならないものだった。部外者から見れば、その店に入って清潔かどうかを判断することは不可能だった。ドウラウンダー(四角いブロックをボール状に丸める機械、下記の写真)の内面がきれいに削られているかどうか、部外者が見ようとは思わないだろう。部外者なら、古いオーブンのパネルが変色していることにこだわるだろう。しかし、パン職人にとっては、オーブンの外側の塗装が少し黄色く変色し始めていようが、気にすることはない。パンの味は変わらないのだから。

引用した画像:This is what a dough rounder looks like.
パン屋で2カ月も働けば、きれいに "見る"方法を学ぶことができた。
コードも同じだ。
原文 < クリックで折りたたみが開く >
💡 原文 - 概念を学ぶということ
Way back in September 1983, I started my first real job, working at Oranim, a big bread factory in Israel that made something like 100,000 loaves of bread every night in six giant ovens the size of aircraft carriers.
The first time I walked into the bakery I couldn't believe what a mess it was. The sides of the ovens were yellowing, machines were rusting, there was grease everywhere.
“Is it always this messy?” I asked.
“What? What are you talking about?” the manager said. “We just finished cleaning. This is the cleanest it's been in weeks.”
Oh boy.
It took me a couple of months of cleaning the bakery every morning before I realized what they meant. In the bakery, clean meant no dough on the machines. Clean meant no fermenting dough in the trash. Clean meant no dough on the floors.
Clean did not mean the paint on the ovens was nice and white. Painting the ovens was something you did every decade, not every day. Clean did not mean no grease. In fact there were a lot of machines that needed to be greased or oiled regularly and a thin layer of clean oil was usually a sign of a machine that had just been cleaned.
This is what a dough rounder looks like.The whole concept of clean in the bakery was something you had to learn. To an outsider, it was impossible to walk in and judge whether the place was clean or not. An outsider would never think of looking at the inside surfaces of the dough rounder (a machine that rolls square blocks of dough into balls, shown in the picture at right) to see if they had been scraped clean. An outsider would obsess over the fact that the old oven had discolored panels, because those panels were huge. But a baker couldn't care less whether the paint on the outside of their oven was starting to turn a little yellow. The bread still tasted just as good.
After two months in the bakery, you learned how to “see” clean.
コーディング規約のその先へ
プログラマーになりたての頃、あるいは新しい言語のコードを読もうとしたとき、すべてが同じように不可解に見える。プログラミング言語そのものを理解するまでは、明らかな構文エラーでさえ気づくことができない。
学習の最初の段階では、私たちが通常“コーディング・スタイル”と呼ぶものを認識し始める。つまり、インデントの標準に準拠していないコードや、大文字で表記された変な変数に気づくようになる。
このときあなたは、「このフジツボ野郎[2]。これからは一貫したコーディング規約が必要だ!」と言い翌日はチームのためにコーディング規約を書き上げ、次の6日間は“真の中括弧スタイル[3]”について議論、次の3週間は古いコードを“真の中括弧スタイル”となるよう書き直すと、マネージャーに見つかってしまい「金を稼げないことに時間を費やすな」と怒鳴られる。 そしてコードを見直すときだけ再フォーマットするのは悪いことではないと判断し“真の中括弧スタイル”が約半分ほど進行したあたりで、きれいさっぱり目的を忘れてしまい、ある文字列クラスを別の文字列クラスに置き換えるような、金儲けとはまったく関係のないことに夢中になり始める。
特定の環境でコードを書くことに熟練してくると、他のことが見えるようになってくる。コーディング規約では、まったく問題ないようなことでも、それはあなたを不安にさせる。
原文 < クリックで折りたたみが開く >
💡 原文 - コーディング規約のその先へ
When you start out as a beginning programmer or you try to read code in a new language it all looks equally inscrutable. Until you understand the programming language itself you can't even see obvious syntactic errors.
During the first phase of learning, you start to recognize the things that we usually refer to as “coding style.” So you start to notice code that doesn't conform to indentation standards and Oddly-Capitalized variables.
It's at this point you typically say, “Blistering Barnacles, we've got to get some consistent coding conventions around here!” and you spend the next day writing up coding conventions for your team and the next six days arguing about the One True Brace Style and the next three weeks rewriting old code to conform to the One True Brace Style until a manager catches you and screams at you for wasting time on something that can never make money, and you decide that it's not really a bad thing to only reformat code when you revisit it, so you have about half of a True Brace Style and pretty soon you forget all about that and then you can start obsessing about something else irrelevant to making money like replacing one kind of string class with another kind of string class.
As you get more proficient at writing code in a particular environment, you start to learn to see other things. Things that may be perfectly legal and perfectly OK according to the coding convention, but which make you worry.
C言語を使った例
char* dest, src;
これは適切なコードであり、あなたのコーディング規約にしたがっているかもしれないし、意図されたものかもしれない。しかし、C言語のコードを書くのに十分な経験を積めば、destをcharポインターとして宣言している一方で、srcを単なるcharとして宣言していることに気づくだろう。このコードはちょっと汚い感じがする。
原文 < クリックで折りたたみが開く >
💡 原文 - C言語を使った例
For example, in C:
char* dest, src;
This is legal code; it may conform to your coding convention, and it may even be what was intended, but when you've had enough experience writing C code, you'll notice that this declares dest as a char pointer while declaring src as merely a char, and even if this might be what you wanted, it probably isn't. That code smells a little bit dirty.
さらに微妙な例
if (i != 0)
foo(i);
上記のような場合、コードは100%正しい。ほとんどのコーディング規約にしたがっているし、何の問題もない。しかし、if文の単一ステートメント本体が中括弧で囲まれていないという事実が、あなたを悩ませるかもしれない。
if (i != 0)
bar(i);
foo(i);
このように中括弧を付け忘れると、意図せずfoo(i)を無条件となる!そのため、あなたは中括弧で囲まれていないコードやブロックを見ると、ほんのごく僅かな気持ち悪さを感じ不安になるかもしれない。
原文 < クリックで折りたたみが開く >
💡 原文 - さらに微妙な例
Even more subtle:
if (i != 0) foo(i);In this case the code is 100% correct; it conforms to most coding conventions and there's nothing wrong with it, but the fact that the single-statement body of the ifstatement is not enclosed in braces may be bugging you, because you might be thinking in the back of your head, gosh, somebody might insert another line of code there
if (i != 0) bar(i); foo(i);… and forget to add the braces, and thus accidentally make foo(i)unconditional! So when you see blocks of code that aren't in braces, you might sense just a tiny, wee, soupçon of uncleanliness which makes you uneasy.
問題を見つけやすくする為のコードを意図的に作り込む
さて、ここまでプログラマーとしての達成度を3段階に分けて述べてきた。
-
キレイなコードと汚いコードの区別がつかない
-
表面的なコードのキレイさを考えるようになる、コーディング規約に準拠するレベル
-
奥底の問題をわずかに感じるようになり、試行錯誤してコードを直そうと試す
私が本当に伝えたいと思っているのは、これらよりさらに上のレベルで、
- 問題を見つけやすくする為のコードを意図的に作り込む事で、キレイなコードとなる可能性を高める。
これこそが本当のプロ。問題を見つけやすくするような規約を生み出すことで、強固なコードを作るということだ。
それでは、ちょっとした例を紹介しよう。例では強固なコードを生み出す際に使用する一般的なルールとなる。
おそらく嫌悪感を与える類の内容ではないと思うが、最終的にはハンガリアン記法の擁護につながるだろう。
それと、特定の条件下における例外に対し批判があるが、おそらく、あなたの置かれている状況とは異なるだろう。
しかし、もしあなたがハンガリアン記法は悪いものと誤信し、他の意見など聞きたくもないと考えているのなら、
ローリーのところにある素晴らしいコミックを読めばいい。
そこで失う事は少ないはず。
あなたが怒る前に眠くなりそうなサンプルコードをお見せする。
その通り。あなたがほぼ眠っている状態で、あまり抵抗できない時に“ハンガリアン記法=良い、例外=悪い”ということをこっそりと教えるよ。
原文 < クリックで折りたたみが開く >
💡 原文 - 問題を見つけやすくする為のコードを意図的に作り込む
OK, so far I've mentioned three levels of achievement as a programmer:
You don't know clean from unclean.
You have a superficial idea of cleanliness, mostly at the level of conformance to coding conventions.
You start to smell subtle hints of uncleanliness beneath the surface and they bug you enough to reach out and fix the code.
There's an even higher level, though, which is what I really want to talk about:
- You deliberately architect your code in such a way that your nose for uncleanliness makes your code more likely to be correct.
This is the real art: making robust code by literally inventing conventions that make errors stand out on the screen.
So now I'll walk you through a little example, and then I'll show you a general rule you can use for inventing these code-robustness conventions, and in the end it will lead to a defense of a certain type of Hungarian Notation, probably not the type that makes people carsick, though, and a criticism of exceptions in certain circumstances, though probably not the kind of circumstances you find yourself in most of the time.
But if you're so convinced that Hungarian Notation is a Bad Thing and that exceptions are the best invention since the chocolate milkshake and you don't even want to hear any other opinions, well, head on over to Rory's and read the excellent comix instead; you probably won't be missing much here anyway; in fact in a minute I'm going to have actual code samples which are likely to put you to sleep even before they get a chance to make you angry. Yep. I think the plan will be to lull you almost completely to sleep and then to sneak the Hungarian=good, Exceptions=bad thing on you when you're sleepy and not really putting up much of a fight.
例題(問題を見つけやすくする為のコードを意図的に作り込む)

引用した画像:Somewhere in Umbria
よし。それでは例題に入ろう。最近、若者に流行っているようだから、とあるウェブベースのアプリケーションを構築していると仮定しよう。
クロスサイトスクリプティング脆弱性、通称XSSと呼ばれるセキュリティ脆弱性がある。ここでは詳細について触れないが、ウェブ・アプリケーションを構築する際に知っておかなければならないのは、ユーザーがフォームに入力した文字列をそのまま同じ値で返さないよう注意しなければならないという点だ。
たとえば、“What is your name?”というテキストボックスを持つウェブページがあり、そのページを送信すると別ページで“Hello, Elmer!”と表示される。(ユーザー名を“Elmer”と仮定した場合)
これはセキュリティの脆弱性となる、なぜならユーザーは“Elmer”の代わりにあらゆる悪意のあるHTMLやJavaScriptを入力することで、そのJavaScriptが悪さをする可能性があるからだ。それで彼ら(彼女ら)は、Cookie情報を盗み取り“Dr. Evil's”[4]の闇サイトに送信することができる。
補足説明:XSSについて
原文 < クリックで折りたたみが開く >
💡 原文 - 例題(問題を見つけやすくする為のコードを意図的に作り込む)
An Example
Right. On with the example. Let's pretend that you're building some kind of a web-based application, since those seem to be all the rage with the kids these days.
Now, there's a security vulnerability called the Cross Site Scripting Vulnerability, a.k.a. XSS. I won't go into the details here: all you have to know is that when you build a web application you have to be careful never to repeat back any strings that the user types into forms.
So for example if you have a web page that says “What is your name?” with an edit box and then submitting that page takes you to another page that says, Hello, Elmer! (assuming the user's name is Elmer), well, that's a security vulnerability, because the user could type in all kinds of weird HTML and JavaScript instead of “Elmer” and their weird JavaScript could do narsty things, and now those narsty things appear to come from you, so for example they can read cookies that you put there and forward them on to Dr. Evil's evil site.
疑似コードによる説明
擬似コードで説明しよう。想像して。
s = Request("name")
上記はHTMLフォームから入力情報(POST引数)を読み取る。もしこんなコードを書いたのなら、
Write "Hello, " & Request("name")
上記の場合、あなたのサイトはすでにXSS攻撃に対して脆弱となる。これだけで合致してしまう。
コピーした文字列をHTMLに返す前に、エンコードする必要がある。エンコードとは"(ダブルクォーテーション)を " や
>(大なり)を > に置き換えたりする事などを指す。
つまり、
Write "Hello, " & Encode(Request("name"))
上記は、まったく問題ない。
ユーザーから送信される、あらゆる文字列は安全ではない。安全ではない文字列をエンコード無しで出力してはいけない。
このような間違いをがあった場合、コードが間違ってように見えるコーディング規約を考え出してみよう。
間違っているコードが、間違って見えるのなら、そのコードに取り組んでいる人やレビューする人が見つける可能性がある。
原文 < クリックで折りたたみが開く >
💡 原文 - 疑似コードによる説明
Let's put it in pseudocode. Imagine that
s = Request("name")
reads input (a POST argument) from the HTML form. If you ever write this code:
Write "Hello, " & Request("name")
your site is already vulnerable to XSS attacks. That's all it takes.
Instead you have to encode it before you copy it back into the HTML. Encoding it means replacing " with ", replacing > with >, and so forth. So
Write "Hello, " & Encode(Request("name"))
is perfectly safe.
All strings that originate from the user are unsafe. Any unsafe string must not be output without encoding it.
Let's try to come up with a coding convention that will ensure that if you ever make this mistake, the code will just look wrong. If wrong code, at least, looks wrong, then it has a fighting chance of getting caught by someone working on that code or reviewing that code.
考えられる解決策 - その1
1つ目の解決策はユーザーから送信されてきた時点で、すべての文字列をすぐにエンコードすること。
s = Encode(Request("name"))
Encodeで囲まれていないRequestを見かけたら、そのコードは間違っているに違いない。
規約に反している囲われていないRequestを目で追い始めるようになる。
この規約に従うことで、XSSのバグを回避するという点ではうまく機能するが、
この方法は必ずしも最適な手法ではない。
たとえば、ユーザーからの文字列を、どこかのデータベースに格納したいとする、
その際、HTMLエンコードされた文字列をデータベースに格納する意味はない。
なぜかというと、格納されたデータがHTMLページ以外で処理される可能性があるからだ。
クレジットカードの決済アプリケーションの場合、HTMLエンコードされていると混乱してしまう。
多くののウェブ・アプリケーションでは、HTMLページに送る直前まで内部的に文字列のエンコードは行わないという原則に基づき開発されている。
私たちは、しばらくの間、安全ではないフォーマットので使い続けなければならない。
オーケー。もう一度トライしよう。
考えられる解決策 - その2
文字列を書き出す際にエンコードが必要というコーディング規約を作るとどうだろう?
s = Request("name")
// much later:
Write Encode(s)
Encodeで囲っていないWriteを見るたびに、何か間違っていることがわかる。
しかしまぁ、これでは、うまくいかないケースがある…コード内に少しでもHTMLの断片があり、エンコードができないケースだ。
If mode = "linebreak" Then prefix = "<br>"
// かなり後に
Write prefix
上記では、文字列を出口でエンコードする必要がある我々の規約に則ると、間違っているように見える。
Write Encode(prefix)
上記のようにしてしまうと、<br>となり、改行を挿入することになっている。
しかし現在、改行を開始するはずの<br>は<br>にエンコードされ、ユーザーには文字通り<br>として表示される。これも正しくない。
つまり、文字列を読み込むときにエンコードできないパターンもあれば、書き込むときにできないパターンもある為、どちらの案もうまくいかない。
また、規約がないと、以下のようなリスクがある。
s = Request("name")
...数ページ後...
name = s
...数ページ後...
recordset("name") = name // name を データーベースの項目、name に格納
...数日後...
theName = recordset("name")
...数ページ あるいは 数か月後...
Write theName
文字列をエンコードしたか覚えているだろうか?バグを見つける事ができる場所は1つもない。探る場所がどこにもない。
このようなコードがたくさんあると、全文字列の出所を辿り、尚且つエンコードされている事を確認するには、膨大な難問の解決が必要となる。
原文 < クリックで折りたたみが開く >
💡 原文 - 考えられる解決策
Possible Solution #1
One solution is to encode all strings right away, the minute they come in from the user:
s = Encode(Request("name"))
So our convention says this: if you ever see Request that is not surrounded by Encode, the code must be wrong.
You start to train your eyes to look for naked Requests, because they violate the convention.
That works, in the sense that if you follow this convention you'll never have a XSS bug, but that's not necessarily the best architecture. For example maybe you want to store these user strings in a database somewhere, and it doesn't make sense to have them stored HTML-encoded in the database, because they might have to go somewhere that is not an HTML page, like to a credit card processing application that will get confused if they are HTML-encoded. Most web applications are developed under the principle that all strings internally are not encoded until the very last moment before they are sent to an HTML page, and that's probably the right architecture.
We really need to be able to keep things around in unsafe format for a while.
OK. I'll try again.
Possible Solution #2
What if we made a coding convention that said that when you write out any string you have to encode it?
s = Request("name")
// much later:
Write Encode(s)Now whenever you see a naked Write without the Encode you know something is amiss.
Well, that doesn't quite work… sometimes you have little bits of HTML around in your code and you can't encode them:
If mode = "linebreak" Then prefix = "
"// much later:
Write prefixThis looks wrong according to our convention, which requires us to encode strings on the way out:
Write Encode(prefix)
But now the "
", which is supposed to start a new line, gets encoded to <br> and appears to the user as a literal < b r >. That's not right either.So, sometimes you can't encode a string when you read it in, and sometimes you can't encode it when you write it out, so neither of these proposals works. And without a convention, we're still running the risk that you do this:
s = Request("name")
...pages later...
name = s...pages later...
recordset("name") = name // store name in db in a column "name"...days later...
theName = recordset("name")...pages or even months later...
Write theNameDid we remember to encode the string? There's no single place where you can look to see the bug. There's no place to sniff. If you have a lot of code like this, it takes a ton of detective work to trace the origin of every string that is ever written out to make sure it has been encoded.
真の解決策
では、うまくいくコーディング規約を提案しよう。ルールはひとつだけ。
ユーザーから来た文字列はすべて、プレフィックス(接頭辞)が“us”(安全でない文字列)で始まる名前の変数(またはデータベースの項目)に格納しなければならない。
HTMLエンコードされた文字列や、既知の安全な場所から来た文字列はすべて、プレフィックス“s”(安全な文字列)で始まる名前の変数に格納しなければならない。
同じコードを書き直してみよう。変数名以外は何も変えず、新しい規約に合わせてみる。
us = Request("name")
...数ページ後...
usName = us
...数ページ後...
recordset("usName") = usName
...数日後...
sName = Encode(recordset("usName"))
...数ページ あるいは 数か月後...
Write sName
新しい規約で注目してほしいのは、コーディング規約が守られている限り、安全でない文字列でミスを犯しても1行のコードで見つける事ができるということ。
s = Request("name")
上記はルール違反だ。なぜなら、Requestの結果がsで始まる変数に代入されているという内容を見て、これはルール違反だとわかる。Requestの結果は常に安全ではないため、常に名前が "us "で始まる変数に代入されなければならない。
us = Request("name")
上記はOKだ。
usName = us
上記もOK。
sName = us
上記は、もちろん間違えている。
sName = Encode(us)
上記は、正にその通り。
Write usName
上記は、確実に間違っている。
Write sName
上記はOKだ。
Write Encode(usName)
上記も同様にOK。
コードすべての行を単独で調べる事ができ、すべての行が正しければ、コード全体が正しい事となる。
このコーディング規約により、あなたの目はWrite usXXXを見て、それが間違っている事が知る。そして、それをどう修正すればよいか即座にわかるようになる。
最初のうちは、間違ったコードを見るのは、少し難しいが、3週間続けると目がしだいに順応してくる。巨大なパン工場を見たパン屋の従業員のように、即座にこう言う。「ジェイ・ズース、誰も掃除してねぇじゃねか!おい、お前ら、いったい何をやってたんだ?」
このルールを少し拡張し、Request関数とEncode関数の名前をUsRequestとSEncodeに変更(もしくは包括)するなど、安全ではない文字列、または安全な文字列を返す関数はUsとSで始めるようにする。変数に対しても同じように。
原文 < クリックで折りたたみが開く >
💡 原文 - 真の解決策
The Real Solution
So let me suggest a coding convention that works. We'll have just one rule:
All strings that come from the user must be stored in variables (or database columns) with a name starting with the prefix “us” (for Unsafe String). All strings that have been HTML encoded or which came from a known-safe location must be stored in variables with a name starting with the prefix “s” (for Safe string).
Let me rewrite that same code, changing nothing but the variable names to match our new convention.
us = Request("name")
...pages later...
usName = us...pages later...
recordset("usName") = usName...days later...
sName = Encode(recordset("usName"))...pages or even months later...
Write sNameThe thing I want you to notice about the new convention is that now, if you make a mistake with an unsafe string, you can always see it on some single line of code, as long as the coding convention is adhered to:
s = Request("name")
is a priori wrong, because you see the result of Request being assigned to a variable whose name begins with s, which is against the rules. The result of Request is always unsafe so it must always be assigned to a variable whose name begins with “us”.
us = Request("name")
is always OK.
usName = us
is always OK.
sName = us
is certainly wrong.
sName = Encode(us)
is certainly correct.
Write usName
is certainly wrong.
Write sName
is OK, as is
Write Encode(usName)
Every line of code can be inspected by itself, and if every line of code is correct, the entire body of code is correct.
Eventually, with this coding convention, your eyes learn to see the Write usXXX and know that it's wrong, and you instantly know how to fix it, too. I know, it's a little bit hard to see the wrong code at first, but do this for three weeks, and your eyes will adapt, just like the bakery workers who learned to look at a giant bread factory and instantly say, “jay-zuss, nobody cleaned insahd rounduh fo-ah! What the hayl kine a opparashun y'awls runnin' heey-uh?”
In fact we can extend the rule a bit, and rename (or wrap) the Request and Encodefunctions to be UsRequest and SEncode… in other words, functions that return an unsafe string or a safe string will start with Us and S, just like variables.
真の解決策 - ルールを少し拡張した例
さて、コードを見てみよう。
us = UsRequest("name")
usName = us
recordset("usName") = usName
sName = SEncode(recordset("usName"))
Write sName
上記は何をしたのかわかる?これにより、イコール(=)の両辺が同じプレフィックスで始まっていることを確認し、間違いがわかるだろう。
us = UsRequest("name") // OK、両辺ともUSとなっている。
^^ ^^
s = UsRequest("name") // バグ
^ ^^
usName = us // OK
^^ ^^
sName = us // もちろん間違い。
^ ^^
sName = SEncode(us) // 正にその通り。
^ ^
Writeの名前をWriteSに、それとSEncodeの名前をSFromUsに変更する事で、さらに一歩進むことができる。(下記で変更)
us = UsRequest("name")
^^ ^^
usName = us
^^ ^^
recordset("usName") = usName
^^ ^^
sName = SFromUs(recordset("usName"))
^ ^ ^^ ^^
WriteS sName
^ ^
上記の通り、間違えがより見えやすくなる。あなたの目は、怪しいコードを「見る」ことを学ぶだろう。そうすることで、コードを書いたりコードを読んだりする通常の工程だけで、わかりにくいセキュリティ・バグを見つける事ができる。
間違ったコードを間違って見せることは良いことだが、必ずしもすべてのセキュリティ問題に対する最適解ではない。起こりうるすべてのバグやミスを見つけることはできない。しかし、何もないよりあった方が良いのは確かで、間違ったコードが間違って見えるようなコーディング規約の方が良い。プログラマーがコードに目を通す度に、特定のバグがチェックされ未然に防ぐといったような増分的な利点が得られる。
原文 < クリックで折りたたみが開く >
💡 原文 - 真の解決策 - ルールを少し拡張した例
Now look at the code:
us = UsRequest("name")
usName = us
recordset("usName") = usName
sName = SEncode(recordset("usName"))
Write sNameSee what I did? Now you can look to see that both sides of the equal sign start with the same prefix to see mistakes.
us = UsRequest("name") // ok, both sides start with US
s = UsRequest("name") // bug
usName = us // ok
sName = us // certainly wrong.
sName = SEncode(us) // certainly correct.Heck, I can take it one step further, by naming Write to WriteS and renaming SEncode to SFromUs:
us = UsRequest("name")
usName = us
recordset("usName") = usName
sName = SFromUs(recordset("usName"))
WriteS sNameThis makes mistakes even more visible. Your eyes will learn to “see” smelly code, and this will help you find obscure security bugs just through the normal process of writing code and reading code.
Making wrong code look wrong is nice, but it's not necessarily the best possible solution to every security problem. It doesn't catch every possible bug or mistake, because you might not look at every line of code. But it's sure a heck of a lot better than nothing, and I'd much rather have a coding convention where wrong code, at least, looked wrong. You instantly gain the incremental benefit that every time a programmer's eyes pass over a line of code, that particular bug is checked for and prevented.
一般的なルールについて
この間違ったコードを間違って見せるという用件は、画面の1か所に正しい情報を一緒にまとめることが大切。
文字を見る時に、その文字列が安全か安全ではないか知る必要がある。私は、その情報を別ファイルやスクロールが必要な所、別ページのような場所に配置したくない。それには、変数の命名規則が必要だ。
他にも一緒の場所に配置する事でコードを改善できる例がたくさんある。大抵のコーディング規約には次のようなルールがある。
- 関数(Function)は短くする
- 変数を使い時、できるだけ近くで宣言する
- マクロを使って自分だけのプログラミング言語を作らない
-
gotoを使わない - 閉じ中括弧(
})は、対応する開き中括弧({)から1画面以上離さない
これらのルールに共通しているのは、コードが実際に行うことを可能な限り一か所に集め、関連する情報を得ようとしている点だ。こうする事で、あなたの目の玉が起きている事を把握できる可能性が高まる。
一般論として、物事を隠してしまうような言語機能には少し恐怖を感じている。コードを見ると
i = j * 5;
...Cでは、少なくともjが5倍され、その結果がiに格納されていることはわかる。
しかし、C++で同じコードの部分だけ見た場合、何もわからない。まったくない。C++で実際に何が起こっているのかを知る唯一の方法は、iとjがどんな型なのかを知ることだ。というのも、jはoperator*がオーバーロードされた型かもしれない、乗算しようとするとものすごい気の利いたことをするからだ。そしてiはoperator=がオーバーロードされた型かもしれない、型に互換性がないので暗黙的な自動の型変換関数(型強制)が呼び出されてしまうかもしれない。それを見つける唯一の方法は、変数の型をチェックするだけでなく、その型を実装しているコードを見つけることだ。もしどこかに継承があれば、神があなたを助けてくれるだろう、そのコードが実際にどこにあるか見つける為に、クラス階層を一人で探る必要はある。もしどこかにポリモーフィズムがあれば、本当に困ったことになる。なぜなら、iとjがどんな型として宣言されているかを知るだけでは不十分で、それらが今どんな型なのかを知らなければならないからだ。(ふぅ!)
参考記事 < クリックで折りたたみが開く >
C++でi=j*5を見たとき、あなたは自力でどうにかするしかない。このコードは、見ただけで起こりうる問題を発見する能力を下げると考えている。
もちろん、こんなことはどうでもいいことだ。operator*をオーバーライドするような賢いスクールボーイ的なことをする場合、素敵で漏れのない抽象化を提供を目的としたものだ。jはUnicode String型で、Unicode Stringに整数を乗算することは、繁体字中国語を標準中国語に変換するための良い抽象化であることは明らか。そうだよね?
問題は、お察しの通り漏れのない抽象化は存在しないということだ。この件については、漏れる抽象化の法則(The Law of Leaky Abstractions)で広い範囲ですでに語っているので、ここでは繰り返さない。
スコット・マイヤーズ(Scott Meyers)は、少なくともC++においては、C++の失敗や困難な事例など、あらゆることを紹介することでキャリアを積んできた。(ちなみに、スコットの著書 Effective C++[5]の第3版が出たばかりで、完全に書き直されている。今すぐ手に入れよう!)
要約すると
オーケー。
かなり脱線してしまった。今までの経緯を要約しよう。
要約:
間違ったコードを間違って見せるコーディング規約を探す。関連する情報を画面上の同じ場所にまとめて配置することで、特定の種類の問題を発見し、すぐに修正することができる。
原文 < クリックで折りたたみが開く >
💡 原文 - 一般的なルールについて
A General Rule
This business of making wrong code look wrong depends on getting the right things close together in one place on the screen. When I'm looking at a string, in order to get the code right, I need to know, everywhere I see that string, whether it's safe or unsafe. I don't want that information to be in another file or on another page that I would have to scroll to. I have to be able to see it right there and that means a variable naming convention.
There are a lot of other examples where you can improve code by moving things next to each other. Most coding conventions include rules like:
Keep functions short.
Declare your variables as close as possible to the place where you will use them.
Don't use macros to create your own personal programming language.
Don't use goto.
Don't put closing braces more than one screen away from the matching opening brace.
What all these rules have in common is that they are trying to get the relevant information about what a line of code really does physically as close together as possible. This improves the chances that your eyeballs will be able to figure out everything that's going on.In general, I have to admit that I'm a little bit scared of language features that hide things. When you see the code
i = j * 5;
… in C you know, at least, that j is being multiplied by five and the results stored in i.
But if you see that same snippet of code in C++, you don't know anything. Nothing. The only way to know what's really happening in C++ is to find out what types i and j are, something which might be declared somewhere altogether else. That's because j might be of a type that has operator* overloaded and it does something terribly witty when you try to multiply it. And i might be of a type that has operator= overloaded, and the types might not be compatible so an automatic type coercion function might end up being called. And the only way to find out is not only to check the type of the variables, but to find the code that implements that type, and God help you if there's inheritance somewhere, because now you have to traipse all the way up the class hierarchy all by yourself trying to find where that code really is, and if there's polymorphism somewhere, you're really in trouble because it's not enough to know what type i and j are declared, you have to know what type they are right now, which might involve inspecting an arbitrary amount of code and you can never really be sure if you've looked everywhere thanks to the halting problem (phew!).
When you see i=j*5 in C++ you are really on your own, bubby, and that, in my mind, reduces the ability to detect possible problems just by looking at code.
None of this was supposed to matter, of course. When you do clever-schoolboy things like override operator*, this is meant to be to help you provide a nice waterproof abstraction. Golly, j is a Unicode String type, and multiplying a Unicode String by an integer is obviously a good abstraction for converting Traditional Chinese to Standard Chinese, right?
The trouble is, of course, that waterproof abstractions aren't. I've already talked about this extensively in The Law of Leaky Abstractions so I won't repeat myself here.
Scott Meyers has made a whole career out of showing you all the ways they fail and bite you, in C++ at least. (By the way, the third edition of Scott's book Effective C++ just came out; it's completely rewritten; get your copy today!)
Okay.
I'm losing track. I better summarize The Story Until Now:
Look for coding conventions that make wrong code look wrong. Getting the right information collocated all together in the same place on screen in your code lets you see certain types of problems and fix them right away.
私はハンガリー(ハンガリアン記法 = 良い)

引用した画像:Lugnano, Umbria, Italy
さて、悪名高いハンガリアン記法の話に戻そう。
ハンガリアン記法はマイクロソフトのプログラマー、チャールズ・シモニー(Charles Simonyi)によって考案された。シモニーがマイクロソフトで手掛けた主要プロジェクトのひとつが、Wordだった。実際、彼はゼロックス・パルク(Xerox PARC)でブラボー(Bravo)という世界初のWYSIWYGワープロを作るプロジェクトを指揮した。
WYSIWYGワープロでは、スクロール可能なウィンドウがあるため、すべての座標をウィンドウからの相対座標か、ページからの相対座標かで、解釈が必要となる。
シモニーがハンガリアン記法と呼ばれるものを使い始めたのは、それが多くの理由の内の1つだと、私は推測している。その記法はハンガリー語のように見え、シモニーはハンガリー出身だったので、この名前が付いた。シモニー版のハンガリアン記法では、すべての変数の頭に、その変数が含む種類(kind)を示す小文字のタグが付けられていた。
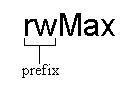
引用した画像:For example, if the variable name is rwCol, rw is the prefix.
私は意図的に種類(kind)という言葉を使っている。というのも、シモニーは論文で種類(type)という間違った言葉を使ってしまい、何世代ものプログラーマー達が意図を誤解してしまったからだ。
シモニーの論文をよく読むと、彼が言いたかったのは、私が前述している例の通りの命名規則、usは“安全でない文字列”、sは“安全な文字列”という意味だった。どちらも種類(type)は文字列型だ。一方をもう片方に代入してもコンパイラーは助けてくれないし、判断や意思決定に必要な知見も教えてくれない。これらは、異なるように扱われて、解釈される必要がある。また、もう一方に代入する時には何らかの種類(kind)の変換関数を呼び出さないとランタイムバグが発生してしまう。あなたの運が良ければ。
原文 < クリックで折りたたみが開く >
💡 原文 - 私はハンガリー(ハンガリアン記法 = 良い)
I'm Hungary
So now we get back to the infamous Hungarian notation.
Hungarian notation was invented by Microsoft programmer Charles Simonyi. One of the major projects Simonyi worked on at Microsoft was Word; in fact he led the project to create the world's first WYSIWYG word processor, something called Bravo at Xerox Parc.
In WYSIWYG word processing, you have scrollable windows, so every coordinate has to be interpreted as either relative to the window or relative to the page, and that makes a big difference, and keeping them straight is pretty important.
Which, I surmise, is one of the many good reasons Simonyi started using something that came to be called Hungarian notation. It looked like Hungarian, and Simonyi was from Hungary, thus the name. In Simonyi's version of Hungarian notation, every variable was prefixed with a lower case tag that indicated the kind of thing that the variable contained.
For example, if the variable name is rwCol, rw is the prefix.
I'm using the word kind on purpose, there, because Simonyi mistakenly used the word type in his paper, and generations of programmers misunderstood what he meant.
If you read Simonyi's paper closely, what he was getting at was the same kind of naming convention as I used in my example above where we decided that us meant “unsafe string” and s meant “safe string.” They're both of type string. The compiler won't help you if you assign one to the other and Intellisense won't tell you bupkis. But they are semantically different; they need to be interpreted differently and treated differently and some kind of conversion function will need to be called if you assign one to the other or you will have a runtime bug. If you're lucky.
シモニー版ハンガリアン記法のコンセプトとは
オリジナルのシモニー版ハンガリアン記法のコンセプトは、マイクロソフト社内では“アプリケーションハンガリアン(Apps Hungarian)”と呼ばれていた。Excelのソースコードには、数多くのrwとcolが登場する。そう、どちらも整数だが、それらを代入し合っても意味がない。Wordでは、xlとxwをよく見かけると思うが、xlは“レイアウトに対する水平座標”を意味し、xwは“ウィンドウに対する水平座標”を意味する。どちらもint型、互換性はない。どちらのアプリでも、“バイト数”を意味するcbが多く使われている。そう、これもint型だが、変数名を見るだけでよくわかる。これはバイト数、つまりバッファサイズだ。xl = cbを見たら、そうだ、バッドコードのホイッスルを鳴らそう。xlもcbも整数であるにもかかわらず、ピクセル単位の水平オフセットをバイト数に設定するのは完全にイカれているからだ。
アプリケーションハンガリアンのプレフィックスは変数だけでなく関数にも使われる。実を言うと、私はWordのソースコードを見たことがないのだが、ウィンドウの縦座標からレイアウトの縦座標に変換するYlFromYwという関数が存在する事には賭けてもいい。前述の例でEncodeからSFromUSに名前を変えた通り、アプリケーションハンガリアンでは、伝統的なTypeToTypeの代わりにTypeFromTypeという表記が必要であり、すべての関数名を返り値の種類で始まるようにした。事実、アプリケーションハンガリアンではエンコード関数はSFromUsという名前である事は必須だ。関数名は、これ以外、選択肢の余地はない。これは、いいことだ。覚えることがひとつ減るし、Encodeという単語がどんなエンコードを指しているのか疑問に思う必要もない。
とくにコンパイラ優れていなかったC言語のプログラミングの時代において、アプリケーションハンガリアンは非常に貴重だった。
原文 < クリックで折りたたみが開く >
💡 原文 - シモニー版ハンガリアン記法のコンセプトとは
Simonyi's original concept for Hungarian notation was called, inside Microsoft, Apps Hungarian, because it was used in the Applications Division, to wit, Word and Excel. In Excel's source code you see a lot of rw and col and when you see those you know that they refer to rows and columns. Yep, they're both integers, but it never makes sense to assign between them. In Word, I'm told, you see a lot of xl and xw, where xl means “horizontal coordinates relative to the layout” and xw means “horizontal coordinates relative to the window.” Both ints. Not interchangeable. In both apps you see a lot of cb meaning “count of bytes.” Yep, it's an int again, but you know so much more about it just by looking at the variable name. It's a count of bytes: a buffer size. And if you see xl = cb, well, blow the Bad Code Whistle, that is obviously wrong code, because even though xl and cb are both integers, it's completely crazy to set a horizontal offset in pixels to a count of bytes.
In Apps Hungarian prefixes are used for functions, as well as variables. So, to tell you the truth, I've never seen the Word source code, but I'll bet you dollars to donuts there's a function called YlFromYw which converts from vertical window coordinates to vertical layout coordinates. Apps Hungarian requires the notation TypeFromType instead of the more traditional TypeToType so that every function name could begin with the type of thing that it was returning, just like I did earlier in the example when I renamed Encode SFromUs. In fact in proper Apps Hungarian the Encode function would have to be named SFromUs. Apps Hungarian wouldn't really give you a choice in how to name this function. That's a good thing, because it's one less thing you need to remember, and you don't have to wonder what kind of encoding is being referred to by the word Encode: you have something much more precise.
Apps Hungarian was extremely valuable, especially in the days of C programming where the compiler didn't provide a very useful type system.
ダークサイド(暗黒面)がハンガリアン記法を支配した
しかしその後、ある異変が起きた。
ダークサイドがハンガリアン記法を支配した。
誰もその理由や経緯を知らないようだが、システムハンガリアンと呼ばれるようになったものをWindowsチームのドキュメントライター達が、うかつにも考案してしまったようだ。
誰かがどこでシモニーの論文を読み、論文で“型(type)”という言葉を使っていたのでクラスまたは型システム、コンパイラがする型チェックのような型(type)を指しているものと思った。シモニーの意図はそうではなかった。彼は“タイプ(type)”という言葉が何を意味するのか、非常に注意深く正確に説明したが、意味を成さなかった。大きな痛手となった。
アプリケーションハンガリアンは非常に利便性の高く、配列のインデックスを意味する“ix”のようなプレフィックスがあったり、カウントを意味する“c”、2つの数値の差を意味する “d”[例として“dx”は幅(width)の差]などがある。
システムハンガリアンは、かなり利便性が低いプレフィックスで、longを意味する“l”やunsigned longを意味する“ul”、double wordを意味する“dw”、double wordこれは実際、えっとunsigned longと一緒だ[6]。システムハンガリアンのプレフィックスが示すのは変数における実際のデータ型のみだ。
これは僅かな違いだが、シモニーの意図と実践に対して完全に履き違えてしまっている。複雑な学術的文章を書いても誰も理解されず、誤って解釈される。そして、その誤解された解釈のアイデアがシモニーの考えでなくてもあざ笑われてしまう。システムハンガリアンでは“double word foo,”を意味するdwFooが数多く使われた、マジかよって感じだ、変数がdouble wordという情報は、ほとんど役に立たない。だから、システムハンガリアンに対して反感があっても無理はない。
システムハンガリアンは、Windowsプログラミング・ドキュメントの標準となり、Windowsプログラミング学習のバイブルとなったチャールズ・ペゾルドのプログラミングWindowsのような書籍(書籍のリンク)で広まりハンガリアン記法の主流となった、マイクロソフト社内でさえもWordとExcelを除いたチームで自分たちの間違いを理解しているプログラマーは極めて少なかった。
原文 < クリックで折りたたみが開く >
💡 原文 - ダークサイド(暗黒面)がハンガリアン記法を支配した
But then something kind of wrong happened.
The dark side took over Hungarian Notation.
Nobody seems to know why or how, but it appears that the documentation writers on the Windows team inadvertently invented what came to be known as Systems Hungarian.
Somebody, somewhere, read Simonyi's paper, where he used the word “type,” and thought he meant type, like class, like in a type system, like the type checking that the compiler does. He did not. He explained very carefully exactly what he meant by the word “type,” but it didn't help. The damage was done.
Apps Hungarian had very useful, meaningful prefixes like “ix” to mean an index into an array, “c” to mean a count, “d” to mean the difference between two numbers (for example “dx” meant “width”), and so forth.
Systems Hungarian had far less useful prefixes like “l” for long and “ul” for “unsigned long” and “dw” for double word, which is, actually, uh, an unsigned long. In Systems Hungarian, the only thing that the prefix told you was the actual data type of the variable.
This was a subtle but complete misunderstanding of Simonyi's intention and practice, and it just goes to show you that if you write convoluted, dense academic prose nobody will understand it and your ideas will be misinterpreted and then the misinterpreted ideas will be ridiculed even when they weren't your ideas. So in Systems Hungarian you got a lot of dwFoo meaning “double word foo,” and doggone it, the fact that a variable is a double word tells you darn near nothing useful at all. So it's no wonder people rebelled against Systems Hungarian.
Systems Hungarian was promulgated far and wide; it is the standard throughout the Windows programming documentation; it was spread extensively by books like Charles Petzold's Programming Windows, the bible for learning Windows programming, and it rapidly became the dominant form of Hungarian, even inside Microsoft, where very few programmers outside the Word and Excel teams understood just what a mistake they had made.
間違えに気付いたMicrosoft
そして大反乱が起こった。ついにハンガリアン記法を理解していなかったプログラマー達は、自分たちが使っている誤解されたサブセットがかなりわずらわしく、ほとんど役に立たないことに気づき反旗をひるがえした。ともあれ、システムハンガリアンには、バグを発見するのに、いいところもある。システムハンガリアンを使っていると、変数の型がわかるという点だ。だが、アプリケーションハンガリアンほどの価値はない。
大反乱は“.NET”でのファーストリリースの時にピークをむかえた。Microsoftはついに「ハンガリアン記法は推奨されない」と言い始めた。大喜びだった。わざわざ理由を言わなかったと思う。彼ら(彼女ら)は文書の命名ガイドラインのセクションを調べ、すべての項目に「ハンガリアン記法を使用しないでください」と書いただけだった。[7]この時点でハンガリアン記法はとても不人気で、誰も文句を言わなかったし、ExcelとWord以外の世界の誰もが、強力な型チェックとインテリセンスの時代には不必要となった扱いにくい命名規則を使う必要がないと安堵していた。
だが、アプリケーションハンガリアンには非常に大きな価値があり、コードのコロケーションが増えることでコードの読み書きが容易となる事やデバッグやメンテナンスがしやすくなる事、そして最重要なのが間違ったコードが間違ってみえるようになるということだ。
終わりに、もうひとつ約束したことがある。それは、もう一度、例外に対し批判するということだ。前回、批判したときは大変な目に遭った。Joel on Softwareのホームページで例外は事実上、目に見えないgotoで目に見えるgotoよりも、さらに悪い事と主張し例外は嫌いだ。と書いた。無論、何百万人もの人々が私の喉元に飛びかかってきた。私の擁護に回ったのは、言わずもがなレイモンド・チェンだけだった、ちなみに彼は世界最高のプログラマーである、だからこそ何かを言わなければならない。でしょ?
原文 < クリックで折りたたみが開く >
💡 原文 - 間違えに気付いたMicrosoft
And then came The Great Rebellion. Eventually, programmers who never understood Hungarian in the first place noticed that the misunderstood subset they were using was Pretty Dang Annoying and Well-Nigh Useless, and they revolted against it. Now, there are still some nice qualities in Systems Hungarian, which help you see bugs. At the very least, if you use Systems Hungarian, you'll know the type of a variable at the spot where you're using it. But it's not nearly as valuable as Apps Hungarian.
The Great Rebellion hit its peak with the first release of .NET. Microsoft finally started telling people, “Hungarian Notation Is Not Recommended.” There was much rejoicing. I don't even think they bothered saying why. They just went through the naming guidelines section of the document and wrote, “Do Not Use Hungarian Notation” in every entry. Hungarian Notation was so doggone unpopular by this point that nobody really complained, and everybody in the world outside of Excel and Word were relieved at no longer having to use an awkward naming convention that, they thought, was unnecessary in the days of strong type checking and Intellisense.
But there's still a tremendous amount of value to Apps Hungarian, in that it increases collocation in code, which makes the code easier to read, write, debug, and maintain, and, most importantly, it makes wrong code look wrong.
Before we go, there's one more thing I promised to do, which is to bash exceptions one more time. The last time I did that I got in a lot of trouble. In an off-the-cuff remark on the Joel on Software homepage, I wrote that I don't like exceptions because they are, effectively, an invisible goto, which, I reasoned, is even worse than a goto you can see. Of course millions of people jumped down my throat. The only person in the world who leapt to my defense was, of course, Raymond Chen, who is, by the way, the best programmer in the world, so that has to say something, right?
特定の条件下における例外に対し批判(例外 = 悪い)
この記事の文脈で、例外について説明しよう。あなたの目は、見えるものがある限り、間違ったものを見て学び、未然にバグを防ぐ。コードを本当にしっかりと強固なものにするためには、コードレビューする際にコロケーションを可能とするコーディング規約が必要だ。言い換えると、コードが何をしているかという情報が目の前にあればあるほど、間違いが見つけやすくなり、より良い仕事ができるようになる。次のようなコードがあったら
dosomething();
cleanup();
…あなたの目が教えてくれる「これのどこが悪いんだ?」と。常にクリーンアップしている!しかし、dosomethingが例外を投げる可能性があるということは、cleanupが呼ばれない場合があるということ。finallyなどを使えばそれは簡単に修正ができるが、私の言いたいことはcleanupが確実に呼び出されることを知る為の唯一の方法がdosomethingのコールツリー全体を調査して、例外を投げる可能性のあるものがどこかにないか確認することだ。どこかに例外を投げれば解決でき、苦労は少ないが、本当に重要なのは、例外はコロケーションが無くなってしまうという点だ。コードが正しいことをしているかという疑問に答えるには、どこか別の場所を探す必要がある、つまりそこに見るものがない為、間違ったコードを見て学習する目の能力を活用できないということだ。
1日に1度、大量のデータを集めて印刷するような、ちっぽけなスクリプトを書いている時は、そりゃ例外はすばらしい。起こりうる間違いを、ただプログラム全体にtry/catchで囲むことですべてを無視し、何か問題が起きた場合にメール通知する時ほど好きな事はない。例外は、極めて重要な業務でもなく生命を維持する為でもない、やっつけ仕事のコードやスクリプトには適している。しかし、オペレーティング・システムや原子力発電所、あるいは開腹手術に使われる高速な丸のこを制御するソフトウェアを書くのであれば、例外は非常に危険だ。
例外を正しく制御する方法を理解しておらず、また例外を理解していなくとも心の中に閉まえば私生活が良くなることすら理解できていない、私をヘボいプログラマーだと決めつけるだろうが、それは残念なことだ。本当に信頼できるコードを書く方法は、誤りのない完璧なプログラマーを想定し、隠れた副作用や漏れがある抽象的で複雑な道具を使う事ではなく、よくある人的な脆弱性を考慮したシンプルな道具を使うようにすることだ。
原文 < クリックで折りたたみが開く >
💡 原文 - 特定の条件下における例外に対し批判(例外 = 悪い)
Here's the thing with exceptions, in the context of this article. Your eyes learn to see wrong things, as long as there is something to see, and this prevents bugs. In order to make code really, really robust, when you code-review it, you need to have coding conventions that allow collocation. In other words, the more information about what code is doing is located right in front of your eyes, the better a job you'll do at finding the mistakes. When you have code that says
dosomething();
cleanup();… your eyes tell you, what's wrong with that? We always clean up! But the possibility that dosomething might throw an exception means that cleanupmight not get called. And that's easily fixable, using finally or whatnot, but that's not my point: my point is that the only way to know that cleanup is definitely called is to investigate the entire call tree of dosomething to see if there's anything in there, anywhere, which can throw an exception, and that's ok, and there are things like checked exceptions to make it less painful, but the real point is that exceptions eliminate collocation. You have to look somewhere else to answer a question of whether code is doing the right thing, so you're not able to take advantage of your eye's built-in ability to learn to see wrong code, because there's nothing to see.
Now, when I'm writing a dinky script to gather up a bunch of data and print it once a day, heck yeah, exceptions are great. I like nothing more than to ignore all possible wrong things that can happen and just wrap up the whole damn program in a big ol'try/catch that emails me if anything ever goes wrong. Exceptions are fine for quick-and-dirty code, for scripts, and for code that is neither mission critical nor life-sustaining. But if you're writing an operating system, or a nuclear power plant, or the software to control a high speed circular saw used in open heart surgery, exceptions are extremely dangerous.
I know people will assume that I'm a lame programmer for failing to understand exceptions properly and failing to understand all the ways they can improve my life if only I was willing to let exceptions into my heart, but, too bad. The way to write really reliable code is to try to use simple tools that take into account typical human frailty, not complex tools with hidden side effects and leaky abstractions that assume an infallible programmer.
以上で翻訳内容の終わり。
参考記事
-
原文を見つけたキッカケとなった記事
https://qiita.com/yuu_j/items/d6e6fc4476ab1dc35cdc -
原文(元記事)
https://www.joelonsoftware.com/2005/05/11/making-wrong-code-look-wrong/ -
原文を日本語訳している他の記事
https://web.archive.org/web/20190418033007/http://local.joelonsoftware.com/mediawiki/index.php/間違ったコードは間違って見えるようにする -
CodeZine記事 - Joelに聞く「優れた開発者」の要件・心構え・努力すべきこと
https://codezine.jp/article/detail/2292
※2ページ目以降、続きを読む為にはCodeZineの会員登録が必要。- [日本語訳版]ソフトウェア開発者採用ガイド
https://amzn.to/3YVbIPL - [英語版]Smart and Gets Things Done: Joel Spolsky's Concise Guide to Finding the Best Technical Talent
https://amzn.to/3P3XEQB
- [日本語訳版]ソフトウェア開発者採用ガイド
関連書籍
原文で登場した書籍の🔗リンクです。
-
Amazonアソシエイトとは、成功報酬型広告です。Amazonのアソシエイトとして、当アカウント(https://zenn.dev/haretokidoki)は 適格販売により収入を得ています。 ↩︎
-
原文は
Blistering Barnaclesとありジョークの類だと思うが意味がわからなかった。タンタンの冒険 - めざすは月が元ネタか?(参考記事) ↩︎ -
真の中括弧スタイルとは、字下げスタイルの一種。英語だとThe One True Brace Style(略、1TBS)。 ↩︎
-
おそらくオースティンパワーズに登場するDr.イーブルのこと。 ↩︎
-
ページがリンク切れでインターネットアーカイブでも参照不可だった為、書籍を調べAmazonのリンクを貼り付けています。 ↩︎
-
ここの意図があまり理解できていないが、C言語の
unsigned long(符号なしlong型)とdouble wordのビット数が32bitで同じという事を思い出し説明している描写か? ↩︎
Discussion