Nvidia(ROS)のオブジェクトの姿勢推定をやってみる
はじめに
ここではNvidiaのオブジェクト認識を使用してみます。具体的には以下のものです。
ROS2で実装されているためロボットで画像認識を使用したい場合に有用です。以下に特徴を記載します。
- 入力画像はsensor_msgs/Imageトピックとして入力
- 入力した画像から認識対象のオブジェクトを認識し、その姿勢を推定
- 認識するオブジェクトは事前の学習が必要
- 推定結果はgeometry_msgs/PoseArrayトピックで出力
以下、リンク先のサンプルの実行手順となります。
環境
ここでは以下のスペックのデスクトップPCを使用します。
| 項目 | 概要 |
|---|---|
| OS | Ubuntu 20.04 LTS |
| kernel | 5.13.0-35-generic |
| CPU | インテル(R) Core(TM) i7-11700F |
| MEM | 32GB |
| GPU | GeForce RTX 3060 |
| Driver Ver | 510.47.03 |
| CUDA Ver | 11.6 |
Docker
例によって実行環境のDocker環境をセットアップしておきます。手順はこのあたりを参照。
環境構築
今回ワークスペースは以下のパスを指定します。
~/workspaces/isaac_ros-dev/catkin_ws_ros2
必要パッケージの取得
まず、端末(①)を起動し、以下のコマンドで必要なパッケージを取得します。
$ cd ~/workspaces/isaac_ros-dev/catkin_ws_ros2/src
$ git clone https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_common
$ git clone https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_nitros
$ git clone https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_pose_estimation
$ git clone https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_dnn_inference
以下のコマンドでサンプルのrosbagを取得します。このrosbagを再生すると認識に使用する画像のimageトピックが出力されます。
$ cd ~/workspaces/isaac_ros-dev/catkin_ws_ros2/src/isaac_ros_pose_estimation
$ git lfs pull -X "" -I "resources/rosbags/"
以下のコマンドでDocker環境を起動します。
$ cd ~/workspaces/isaac_ros-dev/src/isaac_ros_common
$ ./scripts/run_dev.sh
学習済みモデルを配置する場所をDocker環境内に作成します。
$ mkdir -p /tmp/models/
学習済みモデルのダウンロード
ブラウザを開いてここから学習済みモデルをダウンロードします。対象ファイルはKetchup.pthです。これはボトルケチャップを学習したものです。
ダウンロード後(ここでは~/Downloadsに置いたものとする)、Docker環境内にデータをコピーします。新たに端末(②)を起動して以下のコマンドを実行します。
$ cd ~/Downloads
$ docker cp Ketchup.pth isaac_ros_dev-x86_64-container:/tmp/models
コピーしたファイルを認識に使用できるようにデータの変換を行います。最初の端末(①)で以下のコマンドを実行します。
$ python3 /workspaces/isaac_ros-dev/catkin_ws_ros2/src/isaac_ros_pose_estimation/isaac_ros_dope/scripts/dope_converter.py --format onnx --input /tmp/models/Ketchup.pth
各パッケージのビルドを行うために以下のコマンドを実行します。
$ cd /workspaces/isaac_ros-dev/catkin_ws_ros2
$ colcon build --symlink-install
$ source install/setup.bash
実行
以下のコマンドを実行すると、認識ノードが起動します。
$ ros2 launch isaac_ros_dope isaac_ros_dope_tensor_rt.launch.py model_file_path:=/tmp/models/Ketchup.onnx engine_file_path:=/tmp/models/Ketchup.plan
別端末(③)を起動し、以下のコマンドでDocker環境にアクセスします。この端末では認識する画像を出力します。
$ cd ~/workspaces/isaac_ros-dev/catkin_ws_ros2/src/isaac_ros_common
$ ./scripts/run_dev.sh
続けて以下のコマンドを実行してrosbagを再生します。
$ cd catkin_ws_ros2
$ ros2 bag play -l src/isaac_ros_pose_estimation/resources/rosbags/dope_rosbag/
これで/imageトピックが出力されている状態になります。同時に認識結果が/posesトピックで出力されます。
表示
さらに別端末(④)を起動し、以下のコマンドで同様にDocker環境にアクセスします。この端末では認識結果を表示します。
$ cd ~/workspaces/isaac_ros-dev/catkin_ws_ros2/src/isaac_ros_common
$ ./scripts/run_dev.sh
以下のコマンドを実行してrvizを起動します。
$ rviz2
rviz2で以下の設定を行います。
- fixed frameは
camera - 入力画像である/imageを追加
- 出力姿勢である/posesを追加
設定後は以下のように推定された認識結果が表示されます。
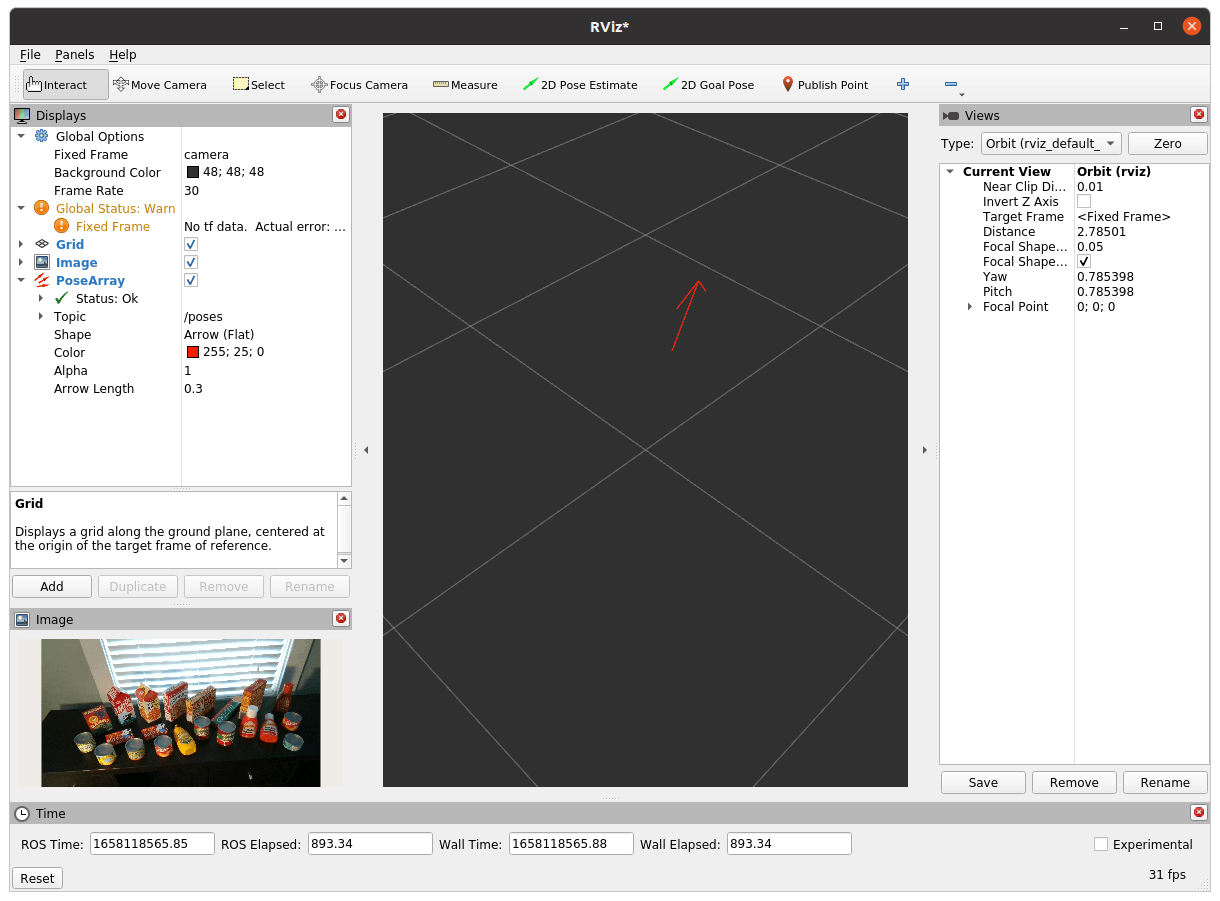
赤矢印が推定結果

入力しているサンプル画像
これだけだとうまく認識できているのかがよくわかりませんね…。
応用
認識したい画像を/imageトピックとして入力すれば認識してくれるので、例えば、以下のようにWebカメラを起動するとカメラ画像に対して認識できます。
$ ros2 run v4l2_camera v4l2_camera_node --ros-args --remap image_raw:=image
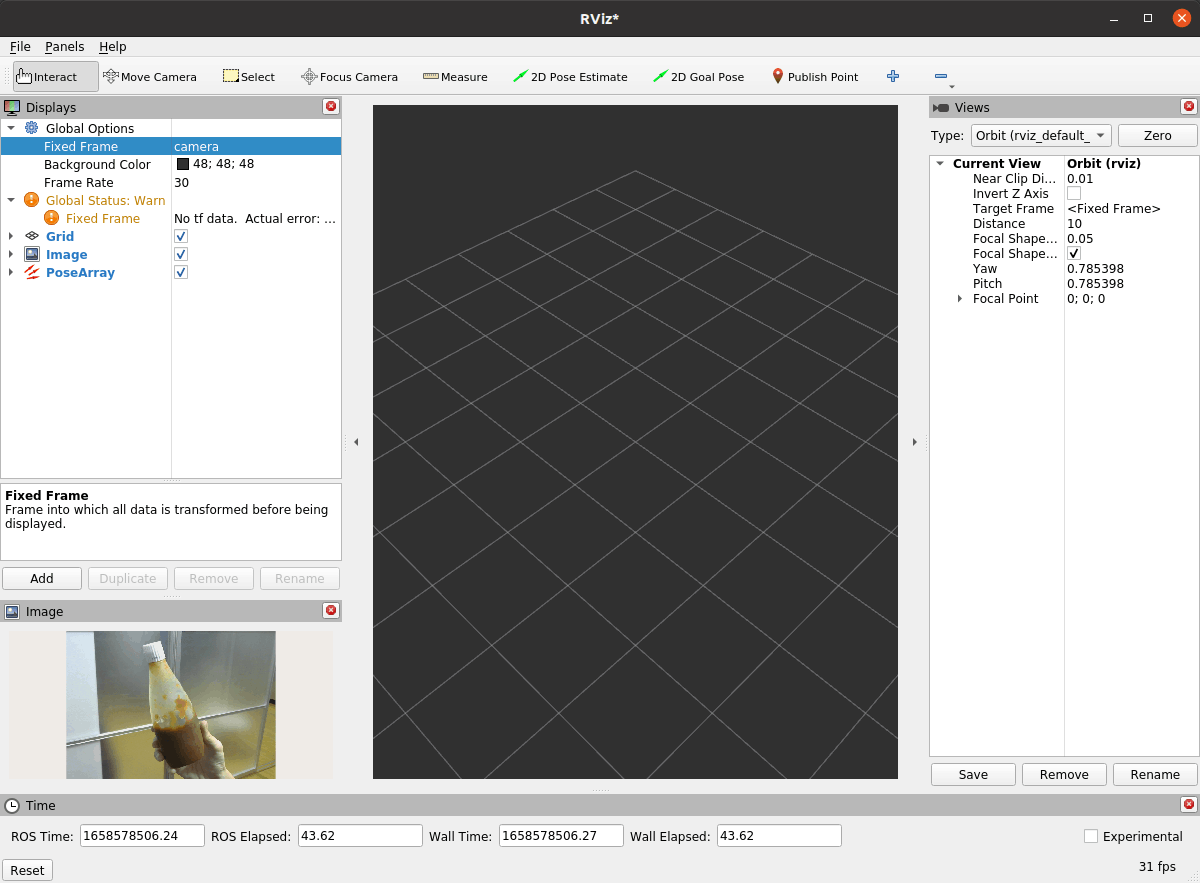
ケチャップを映してみたが…認識しない…
たまに赤矢印が出るときもありますが、基本的には認識できませんでした。これは使用している学習済みのケチャップとここで映しているケチャップの形状等が違うためうまく認識できないのだと思われます。
まとめ
学習済モデルと同じオブジェクトが手元にないので認識できているかどうかがよくわかりませんでした。用意されている学習済モデルはサンプル画像に映っているものだと思われます(Tuna.pthはツナ缶など)。
認識モデルはDOPEとCenterposeという2種類があるようです(今回使用したのはDOPEモデル)。
ここで使用している認識モデルはpytorchで作成されていますので、言い換えれば、学習済みのモデルさえ準備できれば、ROSでの好きなオブジェクトを対象とした画像認識が実現できると言えます。学習済モデルの作成は今後やってみたいです。
Discussion