Isaac Simで画像の領域分割を行う





Isaac Simで画像の領域分割を行うノードがNvidiaで提供されていたので使ってみます。このノードは、深層学習のU-Netモデルを使用したセグメンテーションを行い、注目したい物体を抽出するマスク画像を作成できます。ここでは、画像内から人の領域のみを抽出するということをやっています。具体的には以下のようなマスク画像を作成します。

入力画像

作成されたマスク画像では人のいる領域とそれ以外が分離されている
Image Segmentation
今回使用するパッケージは以下のものです。
ビルド&認識モデル設定&起動
パッケージをビルドします。ビルドは例によってdocker内で行いますので、GPUの設定などを行っておきます(このあたりの手順はここやここを参照)。
dockerを起動します。
$ ~/workspaces/isaac_ros-dev/ros_ws/src/isaac_ros_common/scripts/run_dev.sh
パッケージをGithubからダウンロードします(ディレクトリ等は適宜作成してください)。
$ cd ~/workspace/isaac_ros-dev/catkin_ws_ros2/src
$ git clone https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_image_segmentation
$ git clone https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_dnn_inference
ダウンロードしたパッケージをビルドします。
$ colcon build
次に学習済みデータをダウンロードします。ここでは以下のものを使用します。
$ mkdir -p /tmp/models/peoplesemsegnet/1
$ cd /tmp/models/peoplesemsegnet
$ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/peoplesemsegnet/versions/deployable_v1.0/files/peoplesemsegnet.etlt
ダウンロードしたデータを今回のノードで使用できるように変換します。変換ツールはdocker内にすでにありますので、以下のコマンドを実行します。
$ /opt/nvidia/tao/tao-converter -k tlt_encode -d 3,544,960 -p input_1,1x3x544x960,1x3x544x960,1x3x544x960 -e /tmp/models/peoplesemsegnet/1/model.plan -o softmax_1 peoplesemsegnet.etlt
/tmp/models/peoplesemsegnet/config.pbtxtを作成して、以下の内容を記載します。
name: "peoplesemsegnet"
platform: "tensorrt_plan"
max_batch_size: 0
input [
{
name: "input_1"
data_type: TYPE_FP32
dims: [ 1, 3, 544, 960 ]
}
]
output [
{
name: "softmax_1"
data_type: TYPE_FP32
dims: [ 1, 544, 960, 2 ]
}
]
version_policy: {
specific {
versions: [ 1 ]
}
}
/workspaces/isaac_ros-dev/catkin_ws_ros2/src/isaac_ros_image_segmentation/isaac_ros_unet/launch/isaac_ros_unet_triton.launch.py(起動スクリプト)を修正して、起動時に先ほど作成した学習済みデータを読み込むようにします。
(35~36行目を以下のように修正)
'model_name': 'peoplesemsegnet',
'model_repository_paths': ['/tmp/models'],
ビルドします。
$ cd /workspaces/isaac_ros-dev/catkin_ws_ros2
$ colcon build --packages-up-to isaac_ros_unet
セグメンテーションノードを起動します。
$ source install/setup.bash
$ ros2 launch isaac_ros_unet isaac_ros_unet_triton.launch.py
このノードは/imageトピックを通じて画像を入力すると、その画像のセグメンテーションを行いマスク画像を出力するというものになっています。
画像を入力する
別端末を起動して、すでに起動しているdockerに接続し、画像を出力するノード(image_publisher)をビルドします(コンテナIDなどの指定はここを参照)。
$ docker exec -it <container id> /bin/bash
$ cd /workspaces/isaac_ros-dev/catkin_ws_ros2/src
$ git clone --single-branch -b ros2 https://github.com/ros-perception/image_pipeline.git
$ cd /workspaces/isaac_ros-dev/catkin_ws_ros2
$ colcon build --packages-up-to image_publisher
画像ファイルをimageトピックとして出力するには以下のコマンドを実行します。image_publisher起動時に画像ファイルのパスを指定します。ここではisaac_ros_unet下に用意されているテスト用の画像を指定しています。
$ source install/setup.bash
$ ros2 run image_publisher image_publisher_node /workspaces/isaac_ros-dev/src/isaac_ros_image_segmentation/isaac_ros_unet/test/test_cases/unet_sample/image.jpg --ros-args -r image_raw:=image
起動するとimage_publisherは指定した画像を/imageトピックとして定期的に出力し続けます。
認識結果の確認
image_publisherを起動すると、最初に起動したdockerコンテナでログが出力され始めるはずです。この状態でさらに別端末を立ち上げ、以下のコマンドでビューワを起動すると結果を確認できます(このコマンドは別にdocker内でなくても良いです)。
$ ros2 run rqt_image_view rqt_image_view
冒頭に掲載した画像はこのビューワをキャプチャしたものです。ビューワの上部のプルダウンから表示するものを切り替えることができます。
/image
/unet/colored_segmentation_mask
ちなみにプルダウンには上記の2つ以外に/unet/raw_segmentation_maskというトピックがあるのですが、選択しても真っ黒な画像しか表示されません。どうやらモノクロ画像を認識するときに使用するトピックのようです。
Isaac Simで認識
前述の通り、このセグメンテーションノードは/imageトピックを入力すれば画像のセグメンテーションを行ってくれるので、Isaac Simで使用する場合はimage_publisherの代わりにロボットのカメラ画像を/imageトピックとして入力すれば良いということになります。
公式の手順ではノード起動のlaunchスクリプトにトピック名のリマップを追加して接続していますが、ここではロボットの出力するカメラ画像のトピック名を変更することで接続します。以下手順を記載します。
- docker内でセグメンテーションノードを起動
- Isaac Simを起動
- ROS2 Bridgeを有効化
-
Isaac/Samples/ROS/Scenario/carter_warehouse_apriltags_worker.usdを開く - Carterロボットの
ROS_Camera_Stereo_LeftのRaw USD PropertiesのrgbPubTopicが/rgb_leftになっているのを/imageに変更 - シミュレーション実行(Playボタンを押す)

トピック名を変更

認識結果
いろいろやってみた
こういうものはもともと用意されているサンプル画像では大抵うまくいくようになっています。というわけで、サンプル画像以外の適当な画像を認識させて性能を見てみます。画像は以下のデータセットを使用してみました。

入力画像

出力マスク画像

入力画像

出力マスク画像

入力画像

出力マスク画像

入力画像
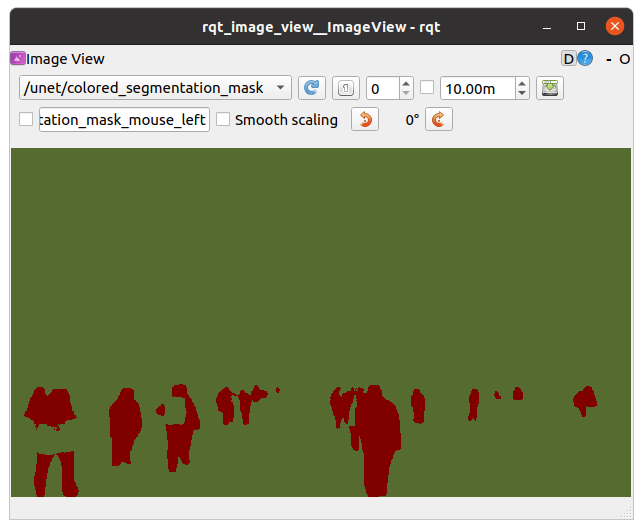
出力マスク画像

入力画像

出力マスク画像

入力画像

出力マスク画像

入力画像

出力マスク画像
まとめ
性能については以下のことが言えると思います。
- 立位が認識しやすい
立位以外は手などのパーツが欠けやすい - 全身が映っていると認識しやすい
上半身だけではうまく認識できないことがある - リュックやバッグなどは抽出されない傾向がある
今回は人領域の抽出を行いましたが、他に使える認識モデル(学習済みデータ)があるかということは気になります。Nvidiaが用意している認識モデルにどのようなものがあるのか、また自分で作るにはどうすればよいのかが現時点ではわかっていません。
Discussion