こんにちは、Happy Elements 株式会社でエンジニアをしておりますryoooです。
はじめに
以前にissueを立てたらGitHub Actionsが起動してLLMにPull requestを作らせる試みを試しました。
こちらをやってみて感じたこととして、非エンジニアが使うならこれが良いかもしれませんが、エンジニアが利用するのであれば手元でLLMに働かせたほうが便利だと感じました。
なので本記事ではターミナル上で動いてソースの実装に応じてテストコードを追加・修正してくれるLLMエージェントのgemを開発しましたので紹介します。
ghostestの紹介
ghostestはローカルPC上で動作するRuby製のテストコード自動生成LLMエージェントツールです。
ghostestのリポジトリにあるghostest自体のテストコードは、すべてghostestが自分で書いたもの(※) なので、どれくらいのテストコードが書けるのかは以下から確認ください。
※ うまく出力できない場合もあり、最後あとちょっとのエラー修正で人間の手が必要な場合もありましたが、これくらいのコードなら人間の手助けは軽微な手直し程度で大丈夫でした。
使い方
Gemfileに以下を追記
gem ghostest
インストール
bundle install
config/ghostest.ymlに以下を保存
language: ruby
watch_files:
- app/models/user.rb # テスト対象ファイル
agents:
Mr_test_designer:
role: test_designer
color: light_yellow
system_prompt: |- # システムプロンプトをカスタマイズ可能
<%= I18n.t("ghostest.agents.test_designer.ruby.default_system_prompt").gsub("\n", "\n ") %>
- Ruby version assumes 3 series.
Mr_test_programmer:
role: test_programmer
color: cyan
system_prompt: |-
<%= I18n.t("ghostest.agents.test_programmer.ruby.default_system_prompt").gsub("\n", "\n ") %>
- Ruby version assumes 3 series.
Mr_reviewer:
role: reviewer
color: green
system_prompt: |-
<%= I18n.t("ghostest.agents.reviewer.ruby.default_system_prompt").gsub("\n", "\n ") %>
※ デフォルトのシステムプロンプトは以下のようになっています。
Azureのトークンを設定
export AZURE_OPENAI_API_KEY=xxxxxx
※ デフォルトはOpenAIになっていますが動作確認は取れていません
起動
bundle exec ghostest --use-azure
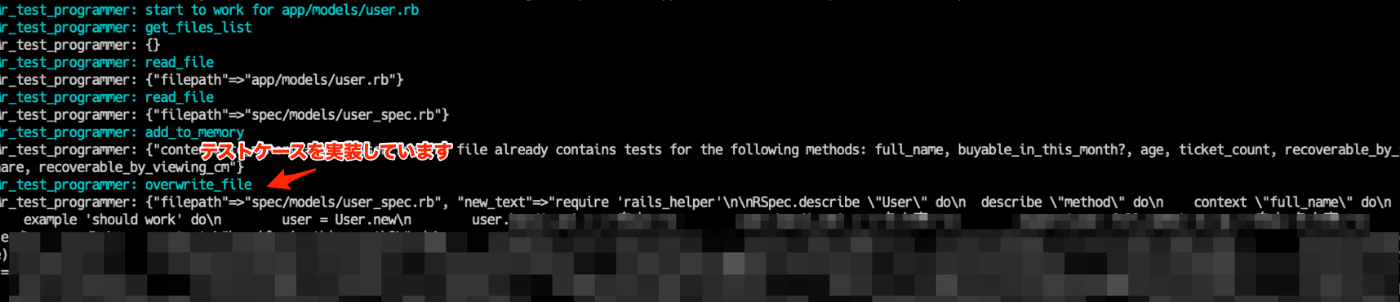
利用イメージ



工夫した点
システムプロンプトの開発を日本語でやりたい
LLMの出力精度はシステムプロンプトの出来に大きく左右されます。
システムプロンプトを試行錯誤したいのですが、精度を考えると英語で書く必要があり、英語が得意でない私にとって英語のシステムプロンプトを試行錯誤するのがツラい感じでした。
ここについては、i18nの機能を使って日本語でシステムプロンプトを書きながらLLMに投げるときには自動で英語に翻訳したものを使うようにしました。
仕組みとしては、以下のように日本語の設定ファイルにプロンプトを記述します。
以下のI18nTranslatorを使って、I18nTranslator.update_dictionary!(:ja, [:en])のようにすることで、日本語のシステムプロンプトを英語に変換するようにしています。
英語のシステムプロンプトを出力したら日本語の原文のmd5を記録しておき、原文が変更されていれば再度翻訳するようになっています。
このようにi18nの言語ファイルを整備してから以下のように使うことで、LLMに投げるときには英語の文字列で投げられるようになっています。
I18n.t('ghostest.agents.test_programmer.default_system_prompt')
これについてはシステムプロンプトを最適化する際の開発生産性がかなり高まったように思うので今後も似たような仕組みを活用したいと感じています。
エージェントを細かく分ける
エージェントごとにシステムプロンプトを最適化しなければ全体の精度は上がりません。
テストを書かせるなら「テストを書く際に考えること、テストを実装する手順」を(Few-shotなども取り入れて)事細かくシステムプロンプトに書けば精度が上がりますし、レビューをさせるならレビューの観点をすべてプロンプトに含める必要があります。
その中で、このツールでは、「テストプログラマー」と「レビュワー」以外に、「テストケースデザイナー」という一般には聞き慣れないエージェントを作りました。これは「必要なテストケースを考えるだけのエージェント」として「テストケースデザイナー」を設定することで全体の品質の向上を狙った試みになります。
実際これにより、テストプログラマーはテストケースを作成する必要がなくなり、指示されたテストケースを実装することだけに集中できるためシステムプロンプトが書きやすくなり、精度が上がったように感じています。
現実世界ではテストケースを考えるだけのエンジニアは多くの場合で採用しませんが、LLMエージェントを活用する世界においては、業務を細かく分けて細分化して各業務を行うエージェントのシステムプロンプトを個別に最適化することで精度をあげられるという現実世界と違った面白い特性があると感じました。
さらにいうとGPT4を使うのではなく、細分化したエージェントごとに専門のファインチューニングを行ったLLMモデルを使うことが可能なら、さらに精度を上げることができると考えられますし、いずれそうなっていくように思います。
Function callingの切り方で精度アップ
Function callingは単純なタスクに分離したほうが精度が上がるようでした。
たとえば、MakeNewFileとOverwriteFileの2つの関数を分けたのですが、これは最初WriteFileという1つの関数で行っていました。
1つの関数だとLLMが使い方を誤る例があったのですが、2つの関数に分けると安定して動くようになりました。
1つの関数のままでも関数のdescriptionで上手に調整できたかもしれませんが、関数数に余裕があるなら分けるのは単純で効果的だと思いました。
課題
実装側に問題がある可能性がある場合の処置
テストを書いたもののテストが通らない場合、実装側に問題がある可能性もあります。
今回のツールについては、実装側に問題がある可能性がある際にはその旨を出力して、そこで処理を止めるようにしています。
しかし、この機能があることで、LLMがわりと早い段階でギブアップをしてしまうことが見受けられました。
自分としては、他のエージェントと相談しながらエラーの解消に向けて試行錯誤してほしくても、早めの段階で「実装側に問題がないか確認してください」と匙を投げるようになってしまっているので、このあたりはもっと丁寧に作る必要があります。
テストデータの修正がうまくない
共通で使っているテストデータを修正すれば通るような場合でも、他のテストへの影響まで考えられず共通部分の修正までLLMの方で判断して修正するような動きはみられませんでした。
システムプロンプトに「他のテストに影響のある修正を加えた際にはすべてのテストを実行すること」などを足す方法もあるかもしれませんが、LLMに理解させるコンテキストが大きくなると精度が下がるため難しいかもしれません。
テストで大量のエラーが発生した際に処理しきれない
テストを出力して一度に数十個のエラーが出た場合、LLMは上手に修正できません。
おそらくエラーメッセージが複雑に長くなりすぎてLLMの理解に間違いが生じるのと、複数の修正タスクを一度にお願いされて間違えやすくなっているものと思われます。
もしかしたら「テストケースを1つ追加して実行」を何度も繰り返していくような手法のほうがうまくこなすのかもしれません。
もっと精度がほしい
ライブラリやモデルなど単純なクラスならわりとうまく出力するのですが、業務で扱うような複雑な処理を含むクラスに対してはうまく出力できないことが多いです。
ただ、うまくいかなかった場合でも100個のテストケースを出力したけど20個はエラーが出ている。テストデータ側を直せば15個は通って、あとの5つはテストケース自体を削除するなど、それくらいの印象でしょうか。
今後やりたいこと
- 設定ファイルのパスを引数で渡せるように修正する
- テスト対象ファイルのパスを引数で渡せるように修正する
- 他言語のテストにも対応する
- OpenAIでの動作にちゃんと対応する
おわりに
最後まで読んでくださりありがとうございます。
今はまだまだ課題がたくさんある状況ではありましたが、今後LLMの精度が上がっていく中で、進化したGitHub CopilotがローカルPC内で高い精度の生成を行ってくれることを楽しみにしています。
よろしければ、ハート・フォロー・シェアをいただけますと喜びます :)
失礼いたします。

Discussion