Spiceのスレッドプール設計: 並列処理とジョブ管理
- プロジェクトURL: https://github.com/judofyr/spice
-
コミットSHA:
6d2d66529c0923da27c26347c9efa3eed75aa976
Spice を手早く把握するには、このデモ から始めるのが良いでしょう。
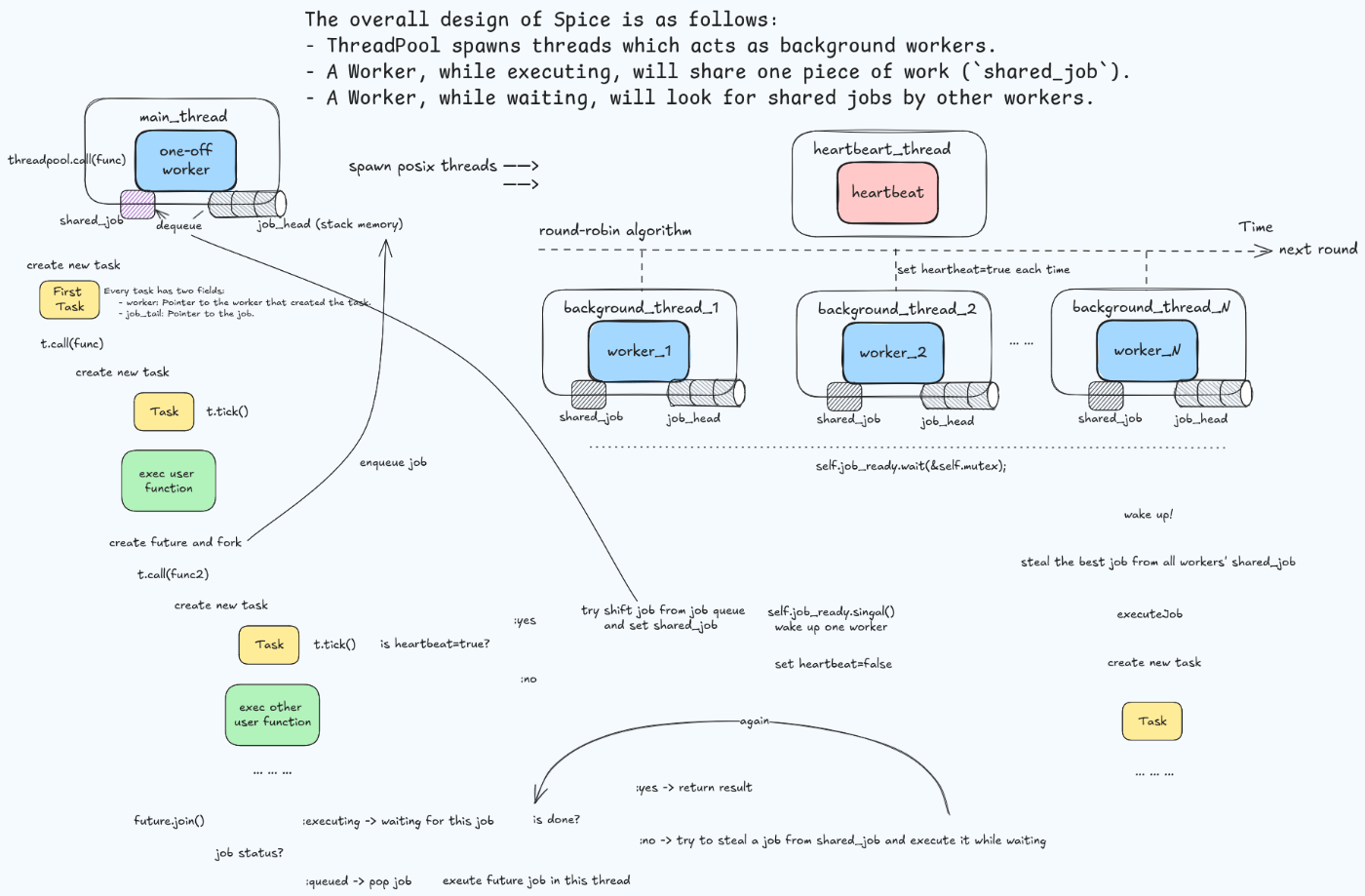
原理概要
全体的な Spice の論理構造は、以下の図に集約されます。
詳細分析
プロジェクトコードはわずか500行程度で、主要なAPIは Task.call()、Future.fork()、Future.join() です。以下では、これらの中核データ構造を詳しく見ていきます。
ThreadPool
pub const ThreadPool = struct {
allocator: std.mem.Allocator,
mutex: std.Thread.Mutex = .{},
/// List of all workers.
workers: std.ArrayListUnmanaged(*Worker) = .{},
/// List of all background workers.
background_threads: std.ArrayListUnmanaged(std.Thread) = .{},
/// The background thread which beats.
heartbeat_thread: ?std.Thread = null,
/// A pool for the JobExecuteState, to minimize allocations.
execute_state_pool: std.heap.MemoryPool(JobExecuteState),
/// This is used to signal that more jobs are now ready.
job_ready: std.Thread.Condition = .{},
/// This is used to wait for the background workers to be available initially.
workers_ready: std.Thread.Semaphore = .{},
/// This is set to true once we're trying to stop.
is_stopping: bool = false,
/// A timer which we increment whenever we share a job.
/// This is used to prioritize always picking the oldest job.
time: usize = 0,
heartbeat_interval: usize,
}
3つの変数が同期のために使用されています:
-
mutex: 構造体レベルのミューテックス。Spice 内では実質的にグローバルミューテックスとして扱われ、多くの部分がこれに依存しています。 -
job_ready: 条件変数で、新しいタスクが利用可能になったときに通知します。 -
workers_ready: セマフォで、バックグラウンド作業スレッドの初期化を待機するために使われます。
スレッドの種類は2つです:
-
background_threads: 実際のタスクを処理するための一連の作業スレッド -
heartbeat_thread: ハートビート用のバックグラウンドスレッド
ここで ArrayList ではなく ArrayListUnmanaged を使用している理由は、ArrayListUnmanaged が Allocator を構造体内に保存せず、関連するメソッドで Allocator を明示的に渡す必要があるためです。ThreadPool 内にはすでに allocator が保存されているので、内部のこれらのデータ構造には Unmanaged 型を使うことができ、これは Zig のちょっとしたテクニックと言えます。
では、主要なメソッドを見てみましょう。
/// Starts the thread pool. This should only be invoked once.
pub fn start(self: *ThreadPool, config: ThreadPoolConfig) void {
const actual_count = config.background_worker_count orelse (std.Thread.getCpuCount() catch @panic("getCpuCount error")) - 1;
self.heartbeat_interval = config.heartbeat_interval;
self.background_threads.ensureUnusedCapacity(self.allocator, actual_count) catch @panic("OOM");
self.workers.ensureUnusedCapacity(self.allocator, actual_count) catch @panic("OOM");
for (0..actual_count) |_| {
const thread = std.Thread.spawn(.{}, backgroundWorker, .{self}) catch @panic("spawn error");
self.background_threads.append(self.allocator, thread) catch @panic("OOM");
}
self.heartbeat_thread = std.Thread.spawn(.{}, heartbeatWorker, .{self}) catch @panic("spawn error");
// Wait for all of them to be ready:
for (0..actual_count) |_| {
self.workers_ready.wait();
}
}
start メソッドの役割は以下の通りです:
- 設定に従って、指定された数の
background_threadsを起動し、それぞれのスレッドはbackgroundWorker関数を実行します。 -
heartbeat_threadを起動し、このスレッドはheartbeatWorker関数を実行します。 - セマフォ
workers_readyを使用して、すべてのワーカーが準備完了になるのを待機します。
また、ensureUnusedCapacity の活用も一般的な最適化手法です。これにより、一度の拡張で複数回の拡張が発生することを避け、append 操作のたびに追加の拡張を生じないようにしています。
さらに、グローバルミューテックス mutex に関して、著者は以下のような説明をしています:
Spice のコードベースを見ると、各スレッドプールにグローバルミューテックスがあり、このロックが頻繁に使用されていることに気づくでしょう。直感的に「これは良くない」と思うかもしれませんが、実際には問題ありません。
グローバルミューテックスが問題になるのは、以下の2条件が同時に発生した場合のみです:
- スレッドが長時間ロックを保持すること。
- 複数のスレッドが同時にロックの取得を試みること。
Spice では、この2つの条件は発生しません。心拍メカニズムにより、通常は1つのスレッドだけが心拍操作を行います。また、ロック保持中にユーザーコードは実行されず、単純なメモリの読み書きのみを行っています。これらの操作は定数時間で完了します。
backgroundWorker()
fn backgroundWorker(self: *ThreadPool) void {
var w = Worker{ .pool = self };
var first = true;
self.mutex.lock();
defer self.mutex.unlock();
self.workers.append(self.allocator, &w) catch @panic("OOM");
// We don't bother removing ourselves from the workers list of exit since
// this only happens when the whole thread pool is destroyed anyway.
while (true) {
if (self.is_stopping) break;
if (self._popReadyJob()) |job| {
// Release the lock while executing the job.
self.mutex.unlock();
defer self.mutex.lock();
w.executeJob(job);
continue; // Go straight to another attempt of finding more work.
}
if (first) {
// Register that we are ready.
self.workers_ready.post();
first = false;
}
self.job_ready.wait(&self.mutex);
}
}
各 background_thread は起動時に Worker オブジェクトを作成し、これを ThreadPool オブジェクトの workers リストに追加します。これにより、ThreadPool レベルで全スレッドに共有メモリとして可視化されます。
特に、初回実行時にはセマフォ workers_ready を変更します。もし _popReadyJob() が実行可能なタスクを見つけた場合、mutex を解放し、そのタスクを実行します。ここでは、タスクがなくなるまで最大限実行し続ける戦略が採用されています。タスクがない場合、self.job_ready.wait(&self.mutex) によりスレッドは条件変数 job_ready を待機し、新しいタスクが到着するまでブロックされます。wait 操作中に mutex は自動的に解放され、スレッドが再開される際に再取得されます。
この関数のクリティカルセクションを要約すると、以下の通りです:
- 初期化時に、スレッドが自分自身を
workersリストに追加し、構造体レベルの状態を変更する。 - タスクキューからタスクを取得する (
self._popReadyJob) - 条件変数のロックが解除されたとき
標準的なスレッドプールの実装といえるでしょう。次に _popReadyJob を見ていきましょう。
/// Finds a job that's ready to be executed.
fn _popReadyJob(self: *ThreadPool) ?*Job {
var best_worker: ?*Worker = null;
for (self.workers.items) |other_worker| {
if (other_worker.shared_job) |_| {
if (best_worker) |best| {
if (other_worker.job_time < best.job_time) {
// Pick this one instead if it's older.
best_worker = other_worker;
}
} else {
best_worker = other_worker;
}
}
}
if (best_worker) |worker| {
defer worker.shared_job = null;
return worker.shared_job;
}
return null;
}
ここでは job_time を比較して最適なワーカーを選択するための O(n) のループを使用しています。そして、選ばれたワーカーの shared_job を取得して返します。O(n) の複雑度については、ワーカーの数が CPU コア数と同等の規模であるため特に問題なく、最適化は不要です。
heartbeatWorker()
fn heartbeatWorker(self: *ThreadPool) void {
// We try to make sure that each worker is being heartbeat at the
// fixed interval by going through the workers-list one by one.
var i: usize = 0;
while (true) {
var to_sleep: u64 = self.heartbeat_interval;
{
self.mutex.lock();
defer self.mutex.unlock();
if (self.is_stopping) break;
const workers = self.workers.items;
if (workers.len > 0) {
i %= workers.len;
workers[i].heartbeat.store(true, .monotonic);
i += 1;
to_sleep /= workers.len;
}
}
std.time.sleep(to_sleep);
}
}
周期的なハートビートの実装には、ラウンドロビンアルゴリズムが用いられています。to_sleep はワーカーの数に応じて均等に分配され、interval は一定です。ワーカーの数が多いほど sleep の時間は短くなります。このスレッドの目的は、定期的に対応するワーカーの heartbeat フィールドを原子的に true に設定することです。heartbeat フィールドが true のときのみ、ワーカーは shared_job を設定できます。これは後に説明する tick() と heartbeat() 関数の実装で参照されます。
この実装の核心的な考え方は、ローカルでスケジューリングを行い、頻度を低く保つことです。約100マイクロ秒ごとに、各スレッドはそのローカル作業キューを確認し、作業を異なるスレッドに送信します。この低頻度は、全体的なオーバーヘッドを削減するための鍵です。100マイクロ秒ごとにスケジューリングを実行すれば、実際には100ナノ秒のコストで、0.1% のオーバーヘッドしか導入されません。
オペレーティングシステム自体はシグナルをサポートしていますが、これらのシグナルは扱いが難しいです。ユーザーコードは任意のタイミングで中断されることがあり、安全に再開するのが困難です。そこで、Spice では協調的なアプローチを採用しています。Task.call() を使用すると、自動的に tick() が呼び出されます。ハートビートが発生しない場合、この関数は非常に効率的でなければなりません。結局のところ、ハートビートは約100マイクロ秒ごとに発生するため、これは一般的な状況です。
pub inline fn tick(self: *Task) void {
if (self.worker.heartbeat.load(.monotonic)) {
self.worker.pool.heartbeat(self.worker);
}
}
fn heartbeat(self: *ThreadPool, worker: *Worker) void {
@setCold(true);
self.mutex.lock();
defer self.mutex.unlock();
if (worker.shared_job == null) {
if (worker.job_head.shift()) |job| {
// Allocate an execute state for it:
const execute_state = self.execute_state_pool.create() catch @panic("OOM");
execute_state.* = .{
.result = undefined,
};
job.setExecuteState(execute_state);
worker.shared_job = job;
worker.job_time = self.time;
self.time += 1;
self.job_ready.signal(); // wake up one thread
}
}
worker.heartbeat.store(false, .monotonic);
}
ここで注目すべきは、inline と @setCold(true) タグが使用されている点です。これらは分岐コンパイルの最適化に役立ちます。
-
inline: このキーワードは、関数を呼び出すのではなく、呼び出し元のコードに直接挿入することを指示します。これにより、関数呼び出しのオーバーヘッドが削減され、パフォーマンスが向上します。 -
@setCold(true): このタグは、特定のコードパスがあまり頻繁に実行されないことを示します。コンパイラはこの情報を基に、実行時のパフォーマンスを最適化するために、特定のコードを冷たい(低頻度の実行)パスとして扱います。これにより、より効果的なキャッシュ利用やスケジューリングが可能になります。
これらの最適化手法を用いることで、全体の性能を向上させ、特に性能に敏感な部分の効率を高めることができます。
call()
pub fn call(self: *ThreadPool, comptime T: type, func: anytype, arg: anytype) T {
// Create an one-off worker:
var worker = Worker{ .pool = self };
{
self.mutex.lock();
defer self.mutex.unlock();
self.workers.append(self.allocator, &worker) catch @panic("OOM");
}
defer {
self.mutex.lock();
defer self.mutex.unlock();
for (self.workers.items, 0..) |worker_ptr, idx| {
if (worker_ptr == &worker) {
_ = self.workers.swapRemove(idx);
break;
}
}
}
var t = worker.begin();
return t.call(T, func, arg);
}
これはエントリポイント関数で、ルートタスクを生成します。
この関数では、現在のスレッドが Spice 内で作業スレッドとして扱われるため、テンポラリなワーカーを作成します。このワーカーは、ルートタスクの実行が完了した後に返されます。これにより、タスクの実行中に適切なコンテキストが維持され、必要なリソースが管理されます。
Worker / Task
background thread は物理的な実行単位であり、worker は論理的な実行単位です。一方、Task はユーザーが定義するタスクを指します。この三者の関係は、次のように表すことができます:
-
1:1:N:
- 1つの
background threadは、1つのworkerに対応しています。 - 1つの
workerは、複数のTaskを実行することができます。
- 1つの
このように、物理的なスレッドは論理的なワーカーによって利用され、ワーカーはユーザーが指定したタスクを実行する構造になっています。
pub const Worker = struct {
pool: *ThreadPool,
job_head: Job = Job.head(),
/// A job (guaranteed to be in executing state) which other workers can pick up.
shared_job: ?*Job = null,
/// The time when the job was shared. Used for prioritizing which job to pick up.
job_time: usize = 0,
/// The heartbeat value. This is set to `true` to signal we should do a heartbeat action.
heartbeat: std.atomic.Value(bool) = std.atomic.Value(bool).init(true),
pub fn begin(self: *Worker) Task {
std.debug.assert(self.job_head.isTail());
return Task{
.worker = self,
.job_tail = &self.job_head,
};
}
fn executeJob(self: *Worker, job: *Job) void {
var t = self.begin();
job.handler.?(&t, job);
}
};
pub const Task = struct {
worker: *Worker,
job_tail: *Job,
pub inline fn tick(self: *Task) void {
if (self.worker.heartbeat.load(.monotonic)) {
self.worker.pool.heartbeat(self.worker);
}
}
pub inline fn call(self: *Task, comptime T: type, func: anytype, arg: anytype) T {
return callWithContext(
self.worker,
self.job_tail,
T,
func,
arg,
);
}
};
// The following function's signature is actually extremely critical. We take in all of
// the task state (worker, last_heartbeat, job_tail) as parameters. The reason for this
// is that Zig/LLVM is really good at passing parameters in registers, but struggles to
// do the same for "fields in structs". In addition, we then return the changed value
// of last_heartbeat and job_tail.
fn callWithContext(
worker: *Worker,
job_tail: *Job,
comptime T: type,
func: anytype,
arg: anytype,
) T {
var t = Task{
.worker = worker,
.job_tail = job_tail,
};
t.tick();
return @call(.always_inline, func, .{
&t,
arg,
});
}
各 worker は双方向リンクリストのヘッダーを含みます。そして、各 Task はそのタスクを作成した worker と、リンクリストの末尾へのポインタを持っています。job はキューから取り出され、shared_job に昇格することができ、これにより他のワーカーからもこのジョブが見えるようになり、タスクの盗難が可能になります。
タスクを盗むワーカーは、新しい Task を作成し、自身の worker とこのジョブを関連付けます。このプロセスについては、executeJob の実装を参照してください。
Job
なぜ Task があるのに Job が存在するのか、疑問に思うかもしれません。ユーザー関数が call() API を呼び出すたびに Task が生成されますが、Job は fork を使用したときにのみ作成されます。Job は、並行して実行される必要があるタスクを表します。
このように、Task は基本的な単位として機能し、通常のタスク実行に使用されますが、Job は並行処理が必要な場合に特化した構造です。この区別により、システムは柔軟性と効率を持ってタスクを管理できます。
pub const JobState = enum {
pending,
queued,
executing ,
};
const max_result_words = 4;
const JobExecuteState = struct {
done: std.Thread.ResetEvent = .{},
result: ResultType,
const ResultType = [max_result_words]u64;
fn resultPtr(self: *JobExecuteState, comptime T: type) *T {
if (@sizeOf(T) > @sizeOf(ResultType)) {
@compileError("value is too big to be returned by background thread");
}
const bytes = std.mem.sliceAsBytes(&self.result);
return std.mem.bytesAsValue(T, bytes);
}
};
// This struct gets placed on the stack in _every_ frame so we're very cautious
// about the size of it. There's three possible states, but we don't use a union(enum)
// since this would actually increase the size.
//
// 1. pending: handler is null. a/b is undefined.
// 2. queued: handler is set. prev_or_null is `prev`, next_or_state is `next`.
// 3. executing: handler is set. prev_or_null is null, next_or_state is `*JobExecuteState`.
const Job = struct {
handler: ?*const fn (t: *Task, job: *Job) void,
prev_or_null: ?*anyopaque,
next_or_state: ?*anyopaque,
}
Job は双方向リンクリストのデータ構造で、以下の操作関数を提供します:
-
head(): 新しい空のJobを返し、キューの先頭を表します。 -
pending(): 新しいJobを返し、状態がpendingです。 -
state():Jobの状態を返します。 -
isTail():Jobがキューの末尾であるか(つまり、次のJobがないか)を判断します。 -
getExecuteState():Jobの実行状態を取得します。このとき、Jobは実行中である必要があります。 -
setExecuteState():Jobの実行状態を設定します。このときも、Jobは実行中である必要があります。 -
push()/pop()/shift(): 要素操作関数です。
通常の実装とは異なり、この構造は特別に最適化されており、2つの透明ポインタと1つの関数ポインタを使用しています。第一に、データはスタック上に存在します。第二に、サイズを小さくするために、フィールドの特別な値を用いて状態列挙を実現しています。state() 関数の実装を見てみると、これらの最適化の具体的な実装がわかるでしょう。
pub fn state(self: Job) JobState {
if (self.handler == null) return .pending;
if (self.prev_or_null != null) return .queued;
return .executing;
}
-
pending:
handlerがnullの場合、Jobはまだ実行の準備ができていないことを示します。このとき、prev_or_nullとnext_or_stateは無意味です。 -
queued:
handlerが設定されており、prev_or_nullがnullでない場合、Jobはキューの中で実行を待っていることを示します。この場合、prev_or_nullとnext_or_stateの型はJobです。 -
executing:
handlerが設定されており、prev_or_nullがnullの場合、Jobは現在実行中であることを示します。このとき、next_or_stateの型はJobExecuteStateです(理由については後で説明します)。
もう一つの最適化として、分岐を減らすためにセントネルノードを使用しています。典型的な双方向リンクリストにおける追加操作は通常次のようになります:
pub fn append(list: *Self, new_node: *Node) void {
if (list.last) |last| {
// 插入到最后一个节点之后。
list.insertAfter(last, new_node);
} else {
// 空链表。
list.prepend(new_node);
}
}
ここで一つ条件があります。もしリンクリストが空であれば、特別な処理が必要です。しかし、ほとんどの場合、リストは空ではありません。この条件分岐を解消するため、リンクリストが常に空でないようにする工夫がされています。特別なノードを定義し、これを常にリストの開始を表すノードとして設定します。この結果、テールポインタは常にこの先頭ノードを指すようになり、最初からリストが空でない状態になります。
こうすることで、push() や pop() の操作において分岐判断が完全に不要となり、効率が向上します。
Future
pub fn Future(comptime Input: type, Output: type) type {
return struct {
const Self = @This();
job: Job,
input: Input,
pub inline fn init() Self {
return Self{ .job = Job.pending(), .input = undefined };
}
/// Schedules a piece of work to be executed by another thread.
/// After this has been called you MUST call `join` or `tryJoin`.
pub inline fn fork(
self: *Self,
task: *Task,
comptime func: fn (task: *Task, input: Input) Output,
input: Input,
) void {
const handler = struct {
fn handler(t: *Task, job: *Job) void {
const fut: *Self = @fieldParentPtr("job", job);
const exec_state = job.getExecuteState();
const value = t.call(Output, func, fut.input);
exec_state.resultPtr(Output).* = value;
exec_state.done.set();
}
}.handler;
self.input = input;
self.job.push(&task.job_tail, handler);
}
/// Waits for the result of `fork`.
/// This is only safe to call if `fork` was _actually_ called.
/// Use `tryJoin` if you conditionally called it.
pub inline fn join(
self: *Self,
task: *Task,
) ?Output {
std.debug.assert(self.job.state() != .pending);
return self.tryJoin(task);
}
/// Waits for the result of `fork`.
/// This function is safe to call even if you didn't call `fork` at all.
pub inline fn tryJoin(
self: *Self,
task: *Task,
) ?Output {
switch (self.job.state()) {
.pending => return null,
.queued => {
self.job.pop(&task.job_tail);
return null;
},
.executing => return self.joinExecuting(task),
}
}
fn joinExecuting(self: *Self, task: *Task) ?Output {
@setCold(true);
const w = task.worker;
const pool = w.pool;
const exec_state = self.job.getExecuteState();
if (pool.waitForJob(w, &self.job)) {
const result = exec_state.resultPtr(Output).*;
pool.destroyExecuteState(exec_state);
return result;
}
return null;
}
};
}
future が初期化された後、その対応する job の状態はデフォルトで pending になります。そして future.fork() を呼び出すと、job の状態が queued に変わります。さらに future.join() を呼び出すと、その時点の job の状態に応じて異なる動作が行われます。
-
pending: 理論上、この状態であることはありません。 -
queued: タスクを取り出してnullを返します。通常、この状態では現在のスレッドがタスクを実行します。 -
executing: タスクがshared_jobに昇格しているが、まだ他のスレッドに取られていない場合は、現在のタスクを返します。他のスレッドに取られ、完了していない場合は、指定されたタスクが終了するまでこのスレッドがさらに多くのタスクを実行します。
この最適化が興味深いのは、fork/join プログラムが完了すると join 操作が完了するという点です。以下のような fork/join 形式でコードを並列実行する場合を考えてみましょう:
join(
fork { code1 }
fork { code2 }
fork { code3 }
)
Spice での表現は次のようになります:
job1 = fork { code1 } // キューに追加
job2 = fork { code2 } // キューに追加
code3 // 即時実行
if (job2.isExecuting()) {
// タスクが他のスレッドに取られている場合は、完了を待機
job2.wait()
} else {
code2
}
if (job1.isExecuting()) {
// タスクが他のスレッドに取られている場合は、完了を待機
job1.wait()
} else {
code1
}
注意すべきは、code1 と code2 が関数内部で繰り返されていることです。これは実際にはメリットがあります。多くの場合、タスクは他のスレッドに取られることはありません。この場合、コードは実質的に順序版に変換され(ただし逆順)、予測可能な分岐のみが発生します。これにより、コード最適化や CPU パフォーマンスが向上します。たとえば、インライン関数呼び出しが可能になり、CPU のパイプラインにフレンドリーなコードとなります。
また、このように state が必須でないため、Spice が execute_state_pool と呼ばれる小さなオブジェクトのメモリプールを利用している理由も理解できます。つまり、待機中で実行されていない job はこの state を必要としません。このため、next_or_state ポインタを直接再利用することで Union による追加のメモリ負荷を回避しています。要するに、あまり使用されないフィールドを二次構造に移動し、ポインタ参照を通してアクセスしています。
next_or_state の再利用は問題にならないのかという疑問もあるかもしれません。しかし、実行時には問題ありません。これはロジックフローに関係しています。job が execute 状態であるときは next_or_state の値は無意味です。なぜなら、job は shared_job から派生し、shared_job は他のワーカーからの shift() 操作によってキューの末尾に配置されているためです。
最後に waitForJob の実装を見てみましょう
/// Waits for (a shared) job to be completed.
/// This returns `false` if it turns out the job was not actually started.
fn waitForJob(self: *ThreadPool, worker: *Worker, job: *Job) bool {
const exec_state = job.getExecuteState();
{
self.mutex.lock();
defer self.mutex.unlock();
if (worker.shared_job == job) {
// This is the job we attempted to share with someone else, but before someone picked it up.
worker.shared_job = null;
self.execute_state_pool.destroy(exec_state);
return false;
}
// Help out by picking up more work if it's available.
while (!exec_state.done.isSet()) {
if (self._popReadyJob()) |other_job| {
self.mutex.unlock();
defer self.mutex.lock();
worker.executeJob(other_job);
} else {
break;
}
}
}
exec_state.done.wait();
return true;
}
もしこの job がすでに shared_job にプッシュされている場合、それを取り下げます。それ以外の場合は、この job の実行完了を待つ間、他のタスクを試みて実行します。このロジックは backgroundWorker の動作と似ています。
Discussion