🩻
[論文メモ] Towards Generalist Biomedical AI 読んだ
Abstract
- 医療は本質的にマルチモーダル (テキスト、画像、ゲノム)
- それらを柔軟に扱える汎用的なバイオメディカルAIは大きなインパクトをもたらす可能性がある
- マルチモーダルなメディカルベンチマークを作成した
- MultiMedBench
- 質問応答、マンモグラフィーや皮膚科画像の解釈といった14のタスク
- 汎用的なバイオメディカルAIのPoC
- Med-PaLM Multimodal (以降 Med-PaLM M)
- すべての MultiMedBench タスクにおいてSOTAに匹敵か越える性能を出した
- 特定のタスク特化モデルをもしばしば越える
- 新たな医療コンセプト及びタスクに対するゼロショット汎化の報告
- 放射線科医による Med-PaLM M の性能評価
- Med-PaLM Mが生成した胸部X線読影レポートに対する放射線科医師の評価を行なった
- 放射線科医の作成したレポートと比較してどちらを好むか実験した所、40.50%の症例で Med-PaLM M のレポートが好まれた
- 臨床的有意性の可能性を示唆
1. Introduction
-
医療はマルチモーダルな学問である
-
バイオメディカルAIの発展にもかかわらずそれらのほとんどは単一モーダルtask systemである
- 例: マンモグラフィの解釈
- システムの出力があらかじめ指定された可能な分類セットに制約されている
- 対話ができない
- 単一タスク・単一モーダルシステムの性能をバウンドしている
-
基盤モデルの出現によりマルチモーダルなバイオメディカルAIの可能性が見えてきた
-
マルチモーダル医療ベンチマークの不在が課題
- 無いので作った
-
マルチモーダル汎用バイオメディカルAI: Med-PaLM Mを開発した
- ファインチューニングなしで様々なタスクに対応 (generalist model)
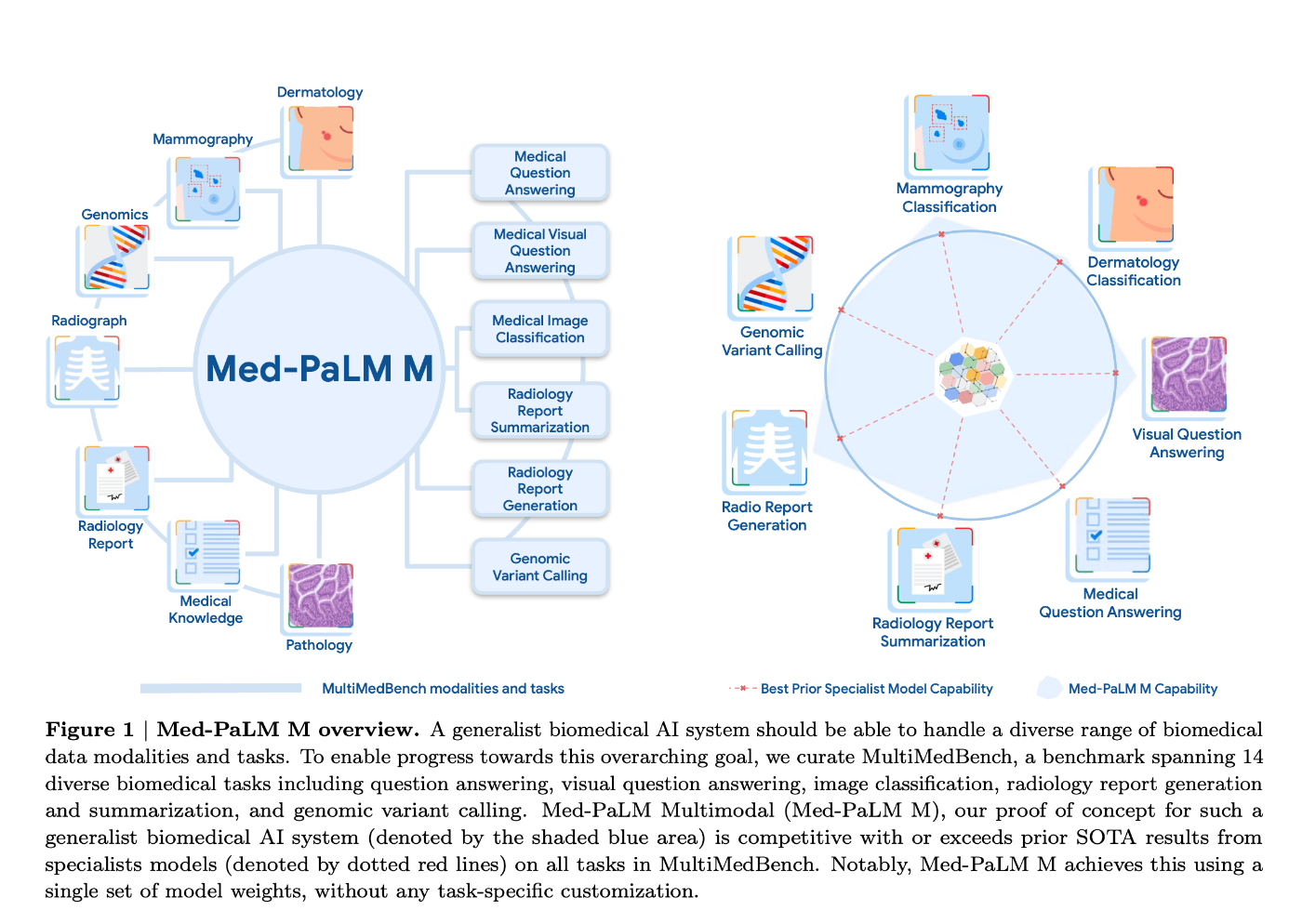
- ファインチューニングなしで様々なタスクに対応 (generalist model)
-
本論文の貢献
- MultiMedBenchのキュレーション
- Med-PaLM M, the first demonstration of a generalist biomedical AI system
- Evidence of novel emergent capabilities in Med-PaLM M
- Human evaluation of Med-PaLM M outputs
2. Related Work
- foundation model
- multimodality
- generalist model
- バイオメディカル分野の multimodel foundation model
- Multimodal medical AI benchmarks
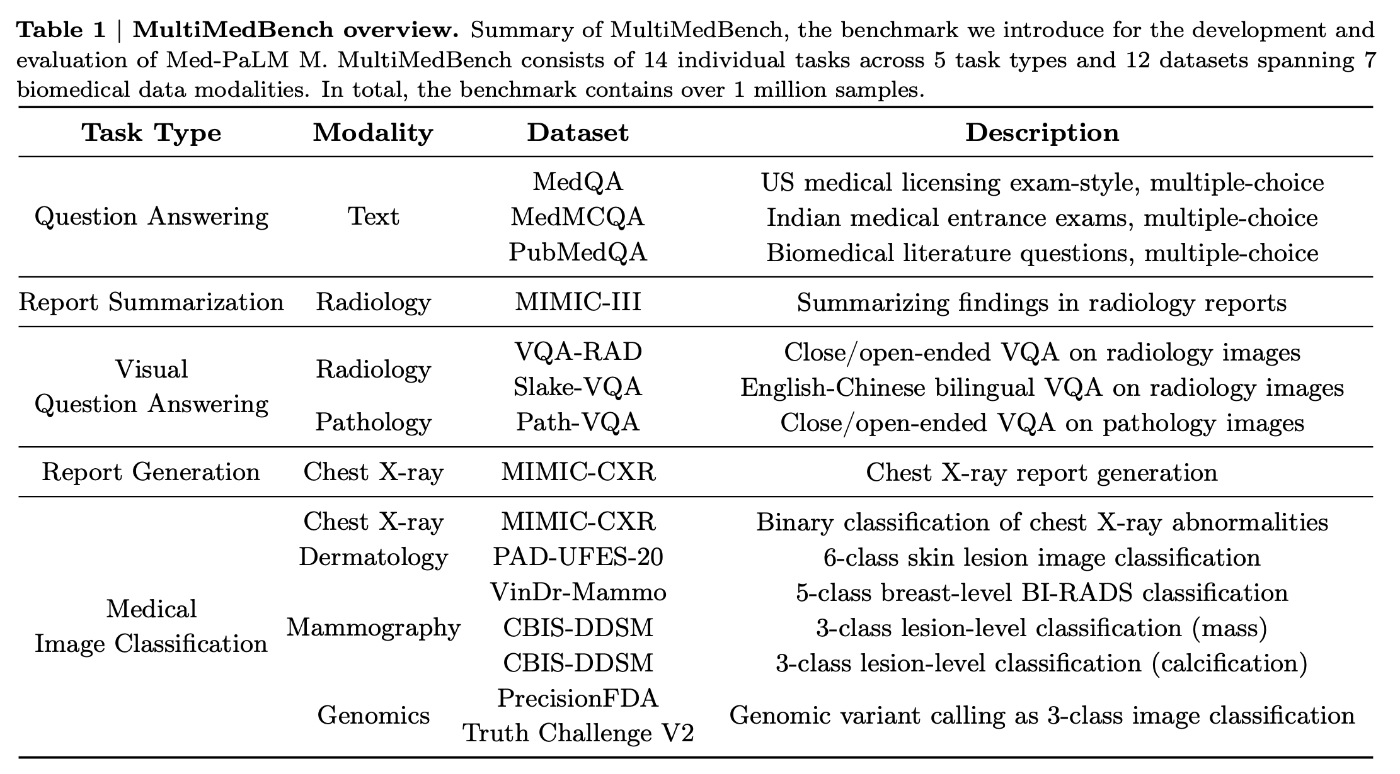
3. MultiMedBench: A Benchmark for Generalist Biomedical AI
14のタスク
4. Med-PaLM M: A Proof of Concept for Generalist Biomedical AI
- Med-PaLM M の事前学習モデルである PALM および PALM-E のレビュー
- Pathways Language Model (PaLM)
- training corpus consists of 780 billion tokens representing a mixture of webpages, Wikipedia articles, source code, social media conversations, news articles, and books
- PaLM-E
- PaLM と Vision Transformer (ViT) を事前学習モデルとしたマルチモーダルモデル
- Med-PaLM M は MultiMedBench を用いて PaLM-E モデルをバイオメディカル領域向けにファインチューニングおよびアラインメントしたもの
- ファインチューニング
- The task prompt consists of an instruction, relevant context information, and a question
- Instructions で病歴テキストを渡す
- Question で解答の候補を全て渡してその中から解答させる
- ファインチューニング
5. Evaluation
- 何をどのように評価したか
- Evaluate generalist capabilities
- MultiMedBenchすべてのタスクについて。従来のモデルやファインチューニング前のモデルとの比較
- Explore novel emergent capabilities
- 様々なタスクにわたって訓練することで得られる汎化能力
- Measure radiology report generation quality
- AIが生成したレポートの専門放射線科医による評価
- Evaluate generalist capabilities
- MultiMedBench による評価
- ゼロショット汎化の評価
- 未知の医療概念への汎化能力を調べるため、胸部X線画像から結核の有無を予測する能力を評価
- Montgomery County chest X-ray set (MC) を使用
- 入力画像中の結核の有無を答えさせた
- 1つの汎用モデルを多くのバイオメディカルタスクを解かせる事で訓練した事と task transfer の関係を証明
- MIMIC-CXR 分類タスクを除外して訓練したモデルとの比較
- 生成した胸部X線レポートの品質と臨床応用性の人間による評価
- 4人の有資格胸部放射線科医
- 評価者が複数のレポート所見を比較し、全体的な質に基づいてランク付けするside-by-side評価
- 全246症例
- 各症例は4人の中から無作為に選ばれた1人によって評価
- 評価者が個々のレポート所見の質を評価する独立評価
- 記述が足りない部分 omissions
- 記述が間違っている部分 error
- 工夫
- レポート所見の出所について盲検化
- レポートをランダムな順序で評価者に提示
- 評価セットとは異なる25ケースのパイロットセットを用いて評点を補正
- 評価
- side-by-side評価
- データセットのリファレンス所見とMed-PaLM Mの3つのバリアントによって生成された所見、全てで4つの所見についてランキング
- 独立評価
- 胸部X線画像を見て生成された所見の質を評価
- 同意できない箇所と、欠落しているすべての箇所に注釈を付けた
- side-by-side評価
6. Results
- Med-PaLM M はすべての MultiMedBench タスクで SOTA に近いかそれを上回る性能
- Med-PaLM M が負けていてSOTAと差が大きいのはTextのみの Question Answering Task
- 他は勝ったかほぼ同じ
- 言語推論タスクはパラメータ数のスケール恩恵を受ける
- マルチモーダルタスクは vision encoder がボトルネックに
- モデルのパラメータ数12B, 84B, 562Bの比較で性能の上昇が限定的
- Med-PaLM M は新しい医療概念・未知のタスクへの汎化性能を示した
- Montgomery County (MC) dataset の胸部X線画像から結核を検出する実験
- Med-PaLM M 自体はタスク特化画像(ここでは MC dataset) を訓練に用いていないにも拘わらずMC datasetの画像138件を訓練に用いた特化モデルに近い性能が出せた
- 新規タスクへの汎化性能
- Med-PaLM M は 正面胸部X線画像のみで訓練したが、正面と側面画像のレポート生成タスクでも正面のみのレポート生成タスクに匹敵するゼロショット性能が達成できた
- task transfer
- 訓練時に MIMIC-CXR 分類タスクを除外したモデルと含めたモデルでの MultiMedBench の比較。後者のモデルがレポート生成と分類の両方で全体的に高い性能だった
- 放射線画像レポート
- 放射線科医が提供したリファレンスレポートが37.14%の症例で最高と評価
- 次に高かったのが Med-PaLM M(84B)の25.78%
- 所見レポートの放射線科医による添削
- レポート1枚あたりの記述漏れの平均 0.12
- 記述の誤り率の平均 0.25
- 誤り率は人間の放射線技師のベースラインと同程度
7. Discussion
- ベンチマークの欠如がボトルネック
- バイオメディカルタスクでの性能向上にはドメイン固有のデータによるファインチューニングが重要
- マルチモーダル汎化モデルのスケーリングは困難、訓練に使える医療画像データが少ない
- などなど
感想・気になりポイント
-
ベンチマーク用のデータセットから作ってしまうのは強い
-
汎用モデルがタスク特化型モデルの性能を上まわってしまうとなると、タスクに特化した学習データに限定してモデルを小さくする試みはどうなるんだろう
-
レポート生成の評価方法は参考になる
- omission,error と 臨床医学的に重要かどうか の2軸
- omission,error は 偽陰性と偽陽性みたいな
-
MultiMedBench でファインチューニングしたモデルなので MultiMedBench でSOTAなのは当り前のような気がした
- 評価用に一部を訓練に使わず残しておいたのかどうかまで読み取れなかった
-
ファインチューニングの説明で回答候補をプロンプトで渡して一つを選ばせるとあったが、どうやって選んだのか?
- 流石に全てはトークンサイズ的に無理な気がする、何を候補としたのかが気になる
-
Given the classification task was set up as an open-ended question answering taskとあるので自由回答のタスクもある? (ほとんどは選択形式に読めたが) - MedQA と Med-PaLM2 の論文をあとで読む
-
皮膚病変データセット(PAD-UFES-20)の分類タスクで病歴テキストを渡しているがこれはどう作ったのか?
- 元のデータはテーブルデータなので良い感じに自然言語化した?
- 回答候補6個って少なくない?

次に読む
MedQAの病名回答タスクでSOTA、 Med-PaLM M との差が最も大きいモデル
MedQA自体の論文
Discussion
素晴らしい記事をありがとうございます!
なにげに凄いこと書かれててびっくりしました😳💦💦
MultiMedBench でファインチューニングしたモデルなので MultiMedBench でSOTAなのは当り前のような気がした
ここの部分が引っかかったのですけど、テストデータの精度は如何だったのでしょうか?🤔 もし読み飛ばしてたらごめんなさい🙇💦
ごめんなさい!論文読んだってことでした…。早とちりしてしまいました💦💦