こんにちは、ハコベルでエンジニアリングマネージャー兼テックリードをやっている吉岡です。
この記事は「Hacobell Developers Advent Calendar」 16日目の記事です。
はじめに
ハコベルが提供しているサービスの一部の処理で、緯度経度からその地点がどの市区町村・行政区域に属しているかの判定をしています。その実装過程で、行政データごとの特性の違いや、MySQLにおける空間データ構造のチューニングについて多くの学びがありました。
この記事では、「国土交通省とe-Stat (国勢調査) の行政区域データの違い」、そして「MySQLでGISデータを扱う際の学び」について、実例を交えて解説します。
前提知識
GISデータベースとしてのMySQL
地理情報システム (GIS) を扱うためのデータベースとしては、一般的にPostgreSQLとその拡張機能であるPostGISの組み合わせがデファクトスタンダードとして知られています。PostGISは非常に高機能で、複雑な幾何計算や解析関数が豊富に揃っているため、地理情報がコアとなるサービスであれば第一選択肢となるでしょう。
一方で、MySQL もバージョン8.0以降、空間参照系 (SRID) のサポート強化や空間関数の拡充が進んでおり、一般的なWebサービスが必要とするレベルの空間検索であれば十分に実用可能です。
ハコベルでは、インフラ構成のシンプルさを保つため、メインデータベースであるMySQLのGIS機能を活用して実装を行っています。
行政区域ポリゴンとは
行政区域ポリゴンとは、都道府県や市区町村といった行政区画の境界線を、緯度経度の座標をつなぎ合わせた多角形 (Polygon) として表現したデータのことです。
DB上では以下のようなクエリで、「ある座標 (住所) がどの市区町村に属するか」を判定します。
-- 座標(Point)がポリゴン(Shape)に含まれているか判定するイメージ
SELECT * FROM polygons
WHERE ST_Contains(shape, ST_GeomFromText('POINT(35.xxxx 139.xxxx)', 4326));
私たちは当初、このポリゴンデータのソースとして国土交通省が提供する「行政区域データ」を採用していました。
1. 行政区域データごとの「定義の違い」と実住所とのギャップ
ある日、CSチームによるデータチェックの中で、「特定の住所に対するエリア判定が正しくないのではないか?」という報告が2件上がりました。
報告された事例
- ケース1: 座標は「さいたま市緑区」なのに、システム上は「川口市」と判定される
- ケース2: 座標は「東京都荒川区」なのに、システム上は「北区」と判定される
調査の結果、システムの実装ミスではなく、使用しているポリゴンデータと実際の住所境界との間に乖離があることが判明しました。
解決の糸口: 過去の開発経験からの再発見
調査に行き詰まっていた時、過去に自分が携わっていた行政区域データを活用したプロダクトの開発案件のことを思い出しました。 そのプロジェクトでも、地図上のエリアを正確に特定するために行政区域ポリゴンを活用していたのです。
当時の記憶を頼りに調査を進めた結果、総務省統計局が提供する統計データポータルサイト「e-Stat」にて、国勢調査に基づいた境界データが公開されていることが分かりました。
このデータを活用すれば、今回の課題も解決できるのではないか?と考え、検証を開始しました。
データ精度の比較検証
両者を地図上にプロットして比較した結果が以下です。
川口市のパターン
- 赤枠: 国土交通省データの川口市の境界線
- 青枠: e-Statデータの川口市の境界線
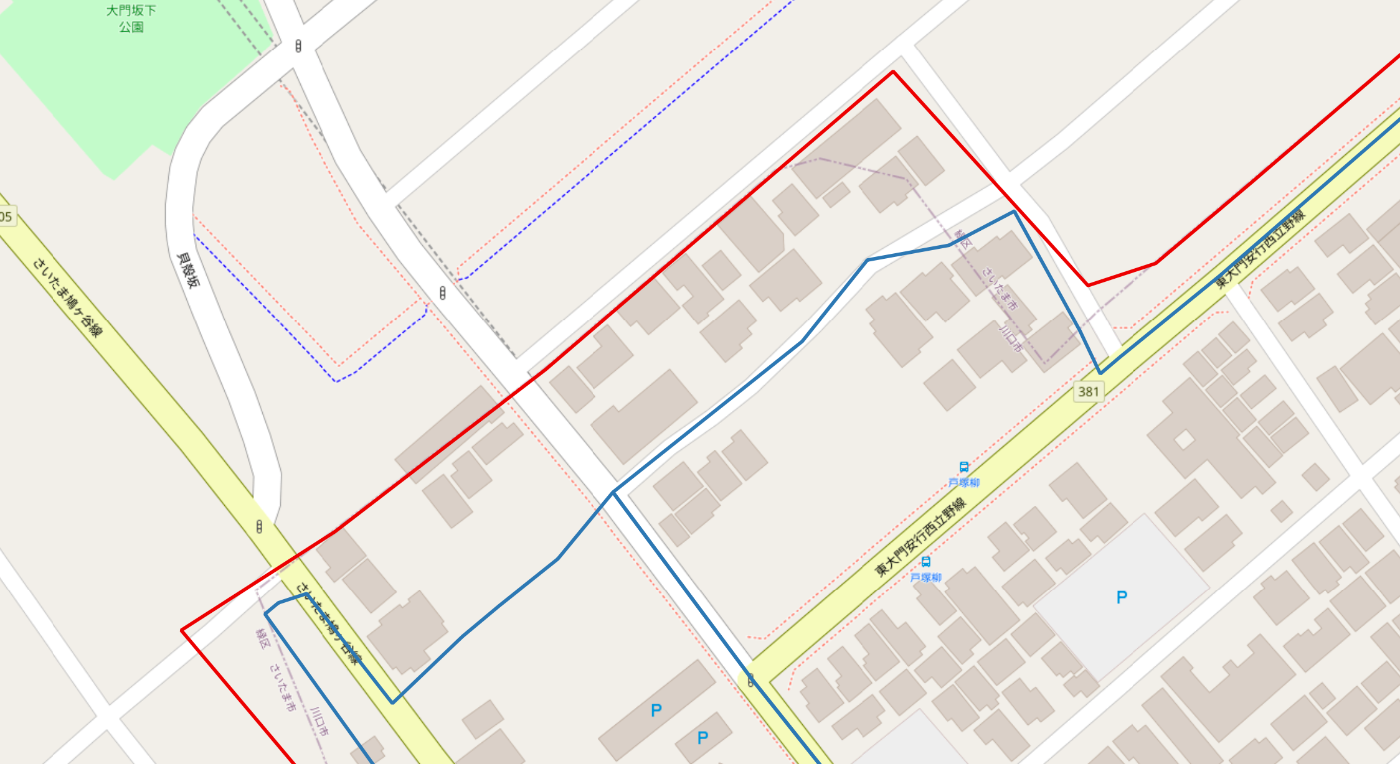
画像の中心付近にある、赤枠と青枠に挟まれたエリアが、本来は「さいたま市緑区」であるにもかかわらず、「川口市」判定されてしまっていた箇所です。
北区のパターン
- 赤枠: 国土交通省データの北区の境界線
- 青枠: e-Statデータの北区の境界線
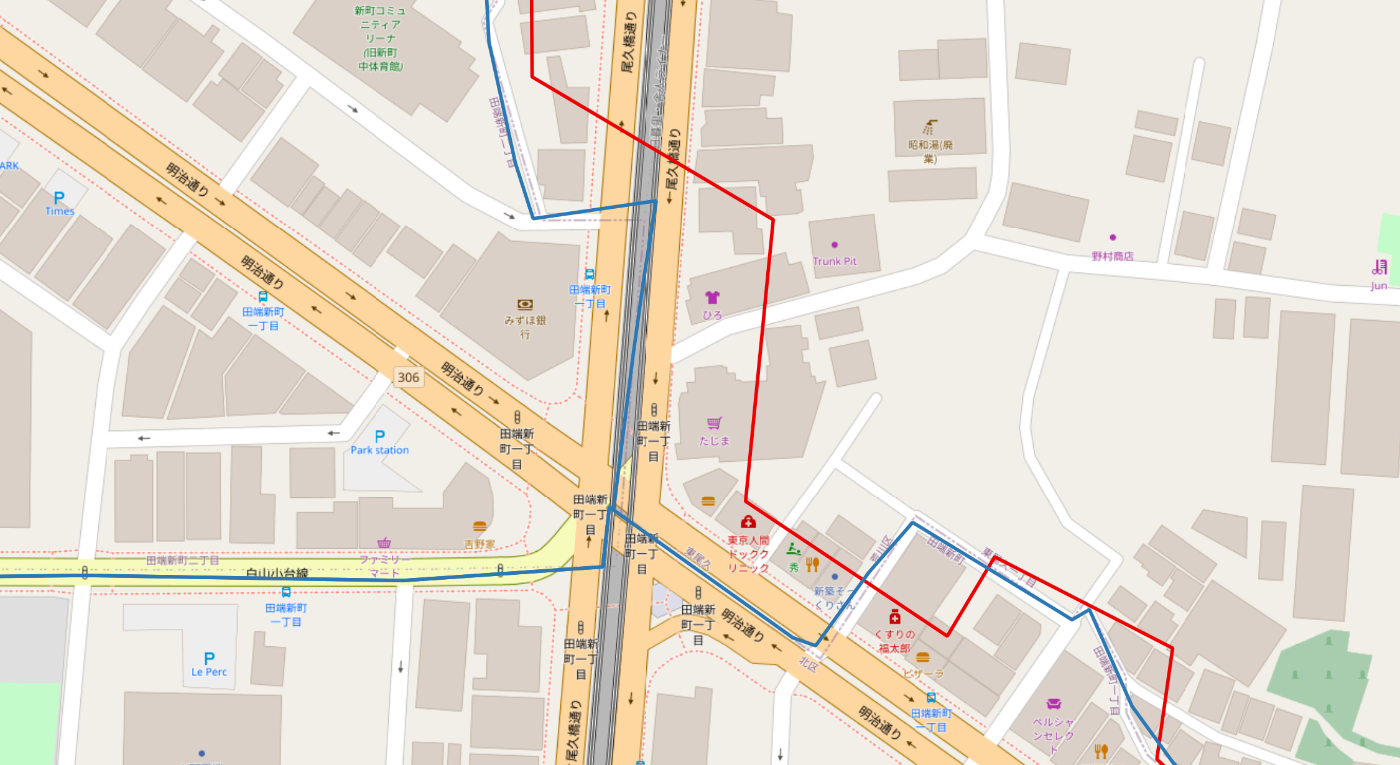
画像の中心付近にある、赤枠と青枠に挟まれたエリアが、本来は「荒川区」であるにもかかわらず、「北区」判定されてしまっていた箇所です。
両パターンともに、赤色のラインと青色のラインが微妙にズレていることがわかります。なぜこのような差が生まれるのか?
国土交通省のデータが行政区画の概略を示すのに対し、e-Statのデータは「国勢調査 (人口統計)」のために作られています。国勢調査は人が住んでいる場所を正確に把握する必要があるため、町丁目・字 (あざ) レベルで細かく、かつ実態に即した境界線が引かれているのです。
さらに、ランダムにピックアップした2,000件の住所データを用いて検証を行いました。その結果、国土交通省のデータでは数件の判定ミスが発生していましたが、e-Statのデータではそれらが全て正しく判定できていることが確認できました。
これを受け、私たちはデータソースをe-Statへ移行することに決めました。
2. MySQLにおける空間データのパフォーマンス問題
しかし、e-Statへの移行に際して、パフォーマンスの問題に直面しました。原因は「データの粒度」の違いです。
データの粒度とMultiPolygon化の落とし穴
これまで利用していた国土交通省データも、実は最初から市区町村単位で1つのポリゴンになっているわけではありませんでした。インポート時に我々がマージ処理を行い、市区町村単位の MultiPolygon として格納していました。
しかし、国土交通省データは元々の粒度が比較的大きく、構成するポリゴンの数も少なかったため、この方法でパフォーマンス上の問題は起きていませんでした。
一方、今回採用したe-Statデータは「大字・町丁目」単位という非常に細かい粒度で提供されています。
既存アプリケーションのロジックに合わせて、国土交通省データの時と同様に 「e-Statの細かいポリゴンを、市区町村ごとに1つの巨大なMultiPolygonにまとめる」 というアプローチを取りました。
その結果、スループットが約4倍悪化してしまいました。
| データソース | 処理内容 | 1000件あたりの処理時間 |
|---|---|---|
| 国土交通省 | MultiPolygon (粒度:粗) | 約8秒 |
| e-Stat | MultiPolygon (粒度:細) | 約32秒 |
なぜ遅くなったのか? (空間検索の計算量)
原因は ST_Contains などの空間関数の計算コストにあります。計算量は一般的に以下に依存します。(m=インデックス探索、n=ジオメトリ内の頂点数・構成要素数)
まず、EXPLAIN ANALYZE の結果を見てみましょう。
-- 国土交通省のマルチポリゴンデータに対してST_CONTAINS
-> Filter: st_contains(...) (actual time=3.494..3.563 rows=1 loops=1) -> Index range scan ... (actual time=1.486..1.629 rows=2 loops=1)
-- e-Statのマルチポリゴンデータに対してST_CONTAINS
-> Filter: st_contains(...) (actual time=13.188..13.228 rows=1 loops=1) -> Index range scan ... (actual time=6.629..7.369 rows=2 loops=1)
この結果から、特に注目すべきは以下の2点です。
-
Index range scan:
巨大なMultiPolygonをインデックスから読み出すコストが増大し、探索だけで約1.6ms → 約7.4msへと悪化しました。
-
Filter:
読み出した後の ST_Contains 関数による精密計算も、頂点数の爆発的増加によりCPU時間(Filter終了時間 - Scan終了時間)が約1.9ms → 約5.9msへと3倍になっています。
これにより、データの粒度を無視した安易なMultiPolygon化が、インデックスとCPU計算の両面でパフォーマンスを悪化させることが実証されました。
ポリゴン結合 (ST_Union) の限界
配列のように束ねる (MultiPolygon) のが重いなら、物理的に1つのポリゴンに融合 (Union) すれば頂点は減るはずです。
もしPostGISを使っていれば ST_Union で綺麗に結合できた可能性がありますが、MySQLの同関数では、飛び地があったり境界が完全に接していなかったりすると、一部の領域が欠損してしまう問題がありました。例として、札幌市をST_Collectで集約した時のMULTIPOLYGONのイメージが以下です。
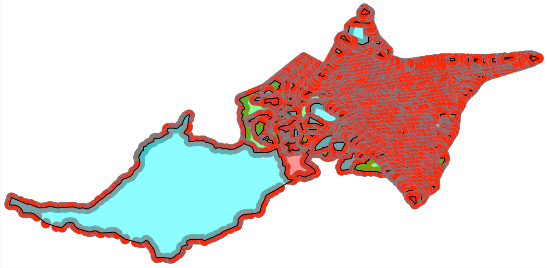
細かいポリゴンの集合からできていることが見て取れます。これをST_UNIONすると以下のような一つのポリゴンになります。
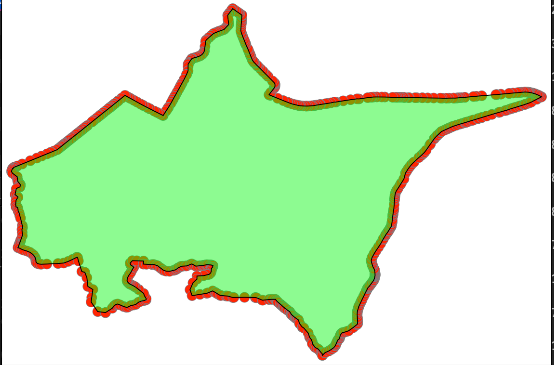
ただ、見ての通り、札幌市の左半分が消滅しているのが分かります。
3. 解決策: あえてまとめない
最終的にたどり着いた解決策は、空間インデックスの効率を最優先に考え、データの持ち方を根本から見直すことでした。
「e-Statの細かいレコード (町丁目単位)をそのまま保存し、市区町村テーブルとリレーションさせる」
無理に1つのShapeにまとめるのをやめ、本来の細かい粒度のまま扱う設計に切り替えました。
データ構造の変更
これまではポリゴンのテーブル自体が「市区町村単位」になっていましたが、これを「e-Statの粒度(町丁目単位)」に合わせ、市区町村テーブルとはIDで紐付ける形に変更しました。
変更前: 1レコード = 1市区町村
| id | city_name | shape |
|---|---|---|
| 1 | 札幌市中央区 | MULTIPOLYGON(...) ← 市区町村全域を含む巨大なジオメトリ |
変更後: 1レコード = 1町丁目 + 市区町村ID
| id | city_id | town_name | shape |
|---|---|---|---|
| 1001 | 1 | 札幌市中央区宮ヶ丘 | POLYGON(...) ← 小さな単一ジオメトリ |
| 1002 | 1 | 札幌市中央区円山 | POLYGON(...) ← 小さな単一ジオメトリ |
なぜこれが速いのか?
MySQLの空間インデックス (R-tree) は非常に優秀です。
対象エリアを細かく分割しておくことで、検索対象の座標が含まれる「小さなポリゴン1つだけ」をインデックスが一瞬で特定してくれます。他の無関係な町丁目のポリゴンは計算対象にすらなりません。
結果として、巨大なMultiPolygon全体をメモリに展開して計算するよりも、はるかに効率的に処理ができるのです。
最終的なパフォーマンス
この構成変更により、スループットは劇的に改善しました。
| データソース | 構造 | 1000件あたりの処理時間 |
|---|---|---|
| 国土交通省 | MultiPolygon | 約8秒 |
| e-Stat | MultiPolygon | 約32秒 |
| e-Stat | Polygon | 約1.5秒 |
元の国土交通省データ利用時と比較しても、5〜6倍の高速化を実現できました。
まとめ
今回の事例から得られた知見は以下の通りです。
-
「実住所」との照合にはe-Statデータが適している
国土交通省データと比較して、境界線の精度が高く、住所ベースの判定においては国勢調査データが有利です。
-
MySQLでMultiPolygonは要注意
空間検索において、巨大なMultiPolygonは計算コストの温床になります。PostGISほど柔軟な関数が揃っていないMySQLだからこそ、データ構造の工夫が求められます。
-
「細かく持ってインデックスに頼る」が正解
空間データに関しては、無理にデータを結合するよりも、細切れのまま空間インデックスのフィルタリング能力を最大限に活かす方が、圧倒的にパフォーマンスが出ます。
行政区域データやMySQLでGISデータを取り扱う際は是非参考にしてみたください。

「物流の次を発明する」をミッションに物流のシェアリングプラットフォームを運営する、ハコベル株式会社 開発チームのテックブログです! 【エンジニア積極採用中】t.hacobell.com//blog/engineer-entrancebook
Discussion