はじめましての方ははじめまして、そうでない方はこんにちは!どうも菊池宣明(@kikulabo)です!
僕は今、エンジニアと食を囲む感覚で気軽に話せるマッチングサービス「ハッカー飯」 の開発に携わっているのですが、先日このハッカー飯にアクセス出来ない状態が起きてしまいました。
今日はこの障害に関することについて簡単に書いていこうかなと思います。
何が起きたの?
事の発端としてはハッカー飯を動かしている EC2 インスタンスを再起動したところ、 500 系のエラーを返すようになってしまいました。
再起動前はサービスが正常に機能していることは確認していたため、最初は何が原因で動かなくなってしまったのか見当がつきませんでした。
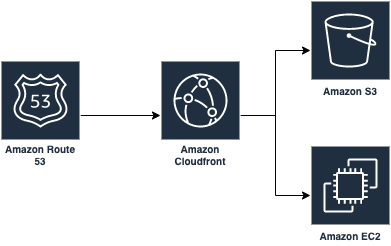
構成図の確認
ここで一旦ハッカー飯の構成図をおさらいしておきます。とはいえかなりシンプルな構成ではあるのですが、S3 に静的ファイルを保存し CloudFront 経由で配信を行い、それ以外の処理は全て EC2 で行うようにしています。
AWS Health Dashboard を確認
AWS Health Dashboard では AWS のサービスで障害が起きているかどうかを確認することが出来ます。
原因切り分けを一応行うために確認してみましたが特にこの時点では障害が起きてないことを確認しました。
EC2 に接続して調査
やっぱり EC2 側で何か問題が起きているんだろうなと思いつつ、 EC2 に入って何か障害が起きていないか調査しました。
EC2 では .Net が動いているのですがアプリ側はどうやら正常に動いていそうなことを確認できました。
となると、 Nginx 側かな?と思い Error ログを確認すると以下のようなメッセージを発見…!
[emerg] 3503#3503: module "/usr/lib64/nginx/modules/ngx_http_geoip_module.so" version 1020000 instead of 1022000 in /usr/share/nginx/modules/mod-http-geoip.conf:1
おや?と思って確認してみると Nginx が動いていないことが判明。
エラーメッセージを調べてみるとこんな記事を発見して、古いモジュールがある状態で Nginx のバージョンが上がると起きるもののようで、 Nginx を再インストールすると直りそうなことが分かりました。
ほんとかなぁ?と思いつつも一旦 AMI を取得してから Nginx の再インストールを行ったところ、 Nginx が正常に起動されサービスが復旧されたのを確認できました。
結局何が起きたの?
あとで他の開発メンバーに聞いてみたところ、ちょくちょく気軽に yum update を実行してパッケージの更新を行っていることが分かりました。
この時 Nginx のバージョンが上がったものの再起動を行わなかったためこれまでずっと古い Nginx のバージョンが使われていたのかなと予想しています。(半年ぶりぐらいに再起動を行いました)
今回僕が再起動したことによって Nginx のバージョンが上がってしまい、その際正常に起動できなかったため今回のような障害が起きてしまったのかなと考えています。
反省
yum update でパッケージを更新してサービスが止まるのはあるあるな障害かなと思うものの、リスクについてちゃんと僕が事前に説明できてなかったのは良くなかったなと考えてます。
今回は仕組みで制御するということはせず、開発メンバーも少ないので気軽に yum update は行わないというのをチーム内で決めて再発しないようにしました。
また、サービスが動いていない時に公式アカウントでアナウンス等も行えるようにしておくと、ユーザに安心感を与えることが出来るのかなとも考えています。(外部向けへの連絡が遅くなってしまった)
最後に
サービスが停止していた時間帯にハッカー飯上でイベントが行われていなかったので影響範囲は小さかったのですが、大体30分間ほどサービスを止めてしまい申し訳ございませんでした!
また、この記事読んでもしハッカー飯に興味を持った方、(大体)毎週水曜日の20時から「ハッカーとFika」という雑談会をやっているので来てくれると嬉しいです!
ここまで読んで頂きありがとうございました!

Discussion