本記事は先日公開した記事 CVPR2024の技術調査(異常検知の観点から)1/2 の続きです。前記事ではCVPR2024の論文を、独自の基準で4つに絞り込むところまでを行いました。ご興味のある方はそちらもご参照ください。本記事ではピックアップした論文を一つずつ紹介していきます。
4 論文の報告
冒頭に引用元の論文をしめし、図表は断りが無い限り論文中の図表を改変なく引用しています。また、文章中の引用番号は原著論文の引用番号を使っています。また、4.1~4.4ではそれぞれ異なる論文を紹介していますが、図表番号は各引用論文のまま使用していることにお気をつけください。
4.1 Hyperbolic Anomaly Detection(Anomaly Detection)
Anomaly Detection の領域からは Hyperbolic Anomaly Detection を紹介します。この論文はHuimin Li等が記した論文で、産業分野における画像異常検出のための新しいアプローチ「Hyperbolic Anomaly Detection (HypAD)」を提案しています。
4.1.1 概要
- 従来のユークリッド空間ではなく、双曲空間で異常検出を行う初めての試みです。
- 画像特徴をユークリッド空間から双曲空間に写像し、双曲距離を用いて最適化します。
- MVTec ADとViSAデータセットにおいて、最先端の性能を達成しました。
- 画像データの階層的な関係を捉えることができる双曲空間の特性が、異常検出タスクに有効であることを示しています。
- 曲率パラメータcの影響を分析し、c=0.01で最良の結果を得ています。
- 画像レベルと画素レベルの両方で評価を行い、特に画素レベルの異常局在化で大きな改善が見られました。
- 視覚化結果も提示し、提案手法の有効性を定性的に示しています。
4.1.2 背景
この論文は、産業用画像の異常検出において、従来のユークリッド空間ではなく双曲空間を利用する新しいアプローチ「HypAD」を提案しています。双曲空間の特性を活かし、画像の階層的な構造をより効果的に捉えることができます。MVTec ADとVisAデータセットでの実験結果は、HypADが最先端の性能を達成し、既存手法を上回ることを示しています。画像レベルと画素レベルの両方で優れた異常検出・局在化性能を実現し、産業用画像の異常検出における双曲空間の有効性を実証しています。
双極空間の活用は様々な研究報告がありますが、Khrulkov等の双極画像埋め込み手法[20]の開発やErmolov等の双曲空間とViTアーキテクチャの組み合わせとユークリッド空間に対する有効性の報告[10]があり、Yan等によって画像タスクをデータの階層構造として効果的に捉えることを報告しています[46]。
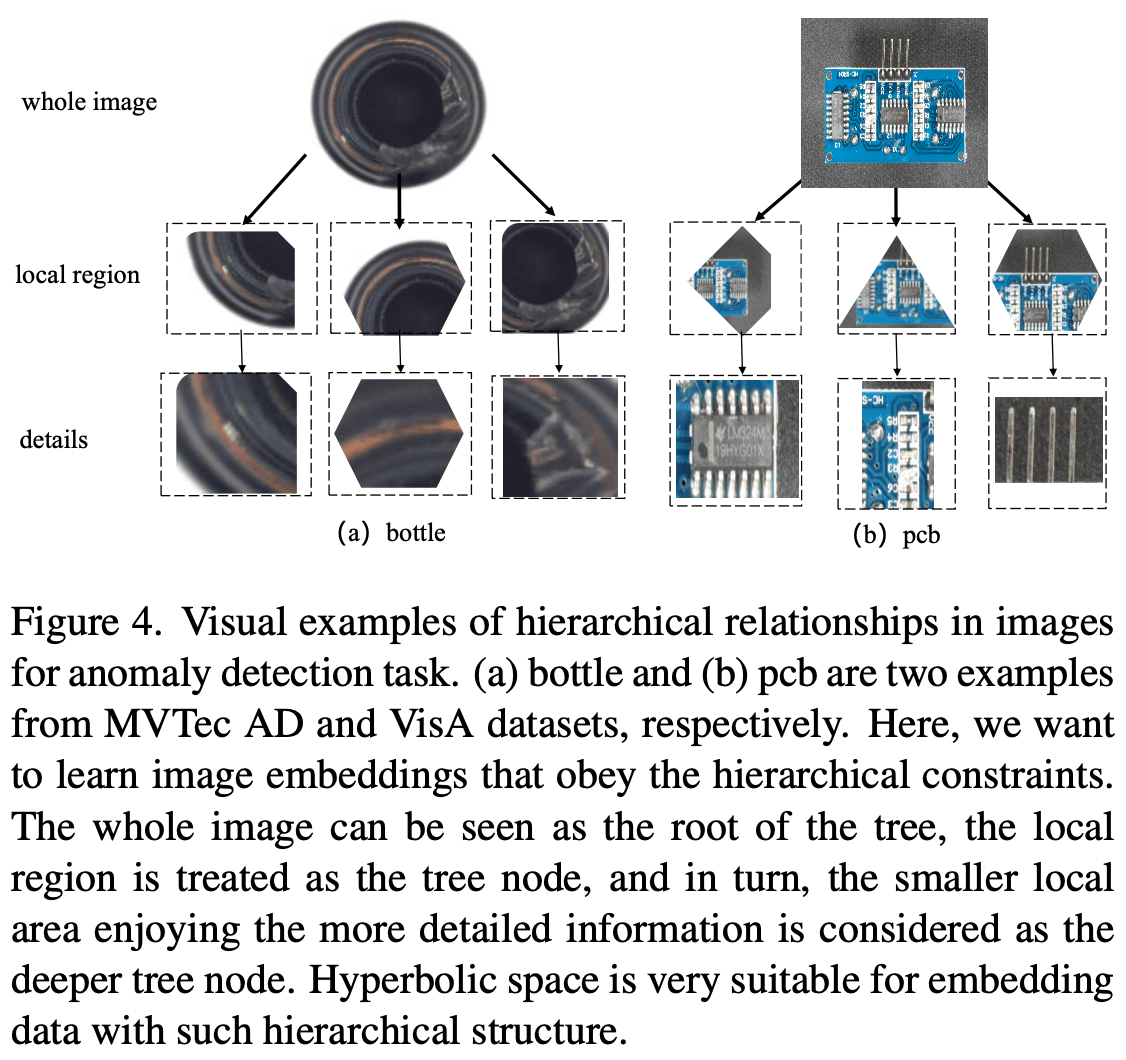
画像の階層構造についてはややイメージし辛い部分がありますが、より一般的なイメージとしてはKhrulkov等[20]がFigure2に引用している画像がわかりやすいかもしれません。画角の違いや画像の違いなども双曲空間の中へ埋め込むことが可能そうです。

4.1.3 アプローチ
Fig3に示すように、HypADは画像Iから2つの拡張ビューI1とI2を入力として受け取ります。これら2つのビューは、まずバックボーンと簡単な投影モジュールで構成されるエンコーダfによって処理され、その後、モデル最適化のために指数写像(EM)を介して双曲空間(ポアンカレ空間)にマッピングされます。
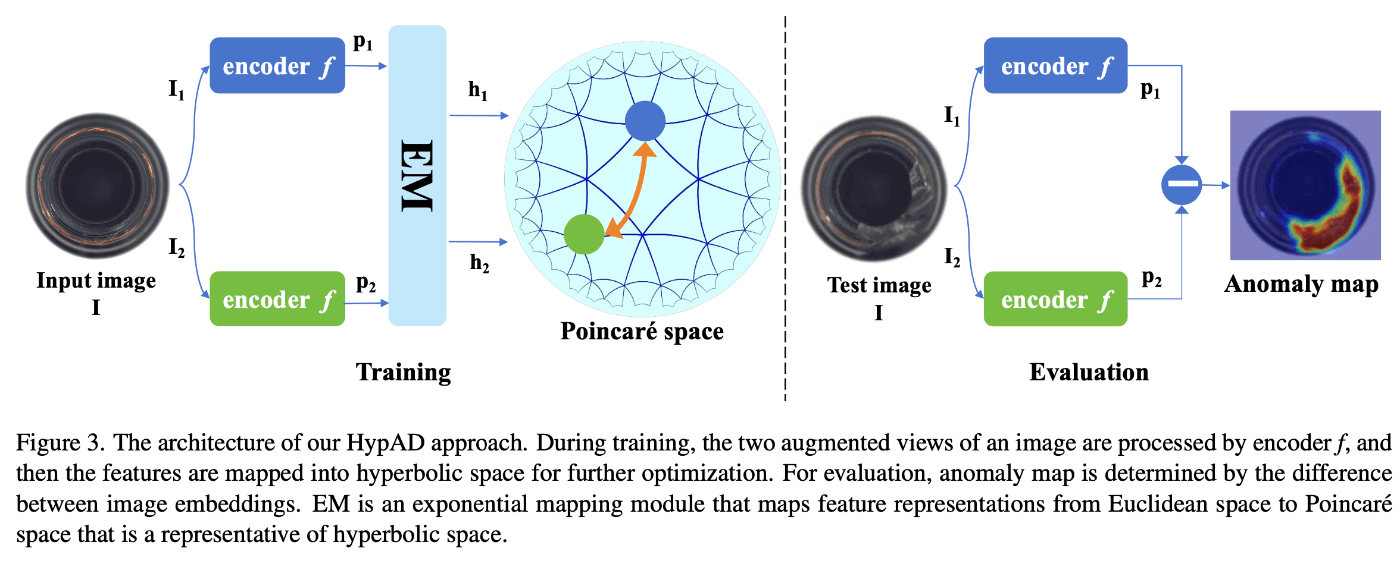
ここでencoder fはBatzner等[1]が用いているPatch Description Network(PDN)を蒸留したPDN-Sを用いています。双曲空間への写像部分がEMとなりますが、ユークリッド空間と双曲空間への相互のマッピングはそれぞれ指数写像(Exponential mapping)と対数写像(logarighmic mapping)によって空間の行き来をおこなっています。これらはKhrulkov等[20]の報告に詳細が記載されています。また、損失関数は双曲空間上での距離(6)で与えられます。
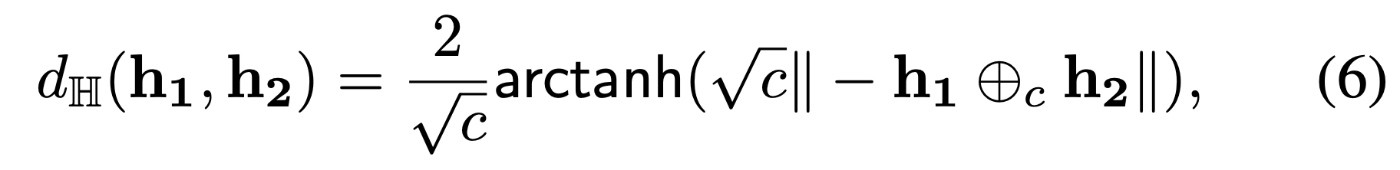
4.1.4 実験結果
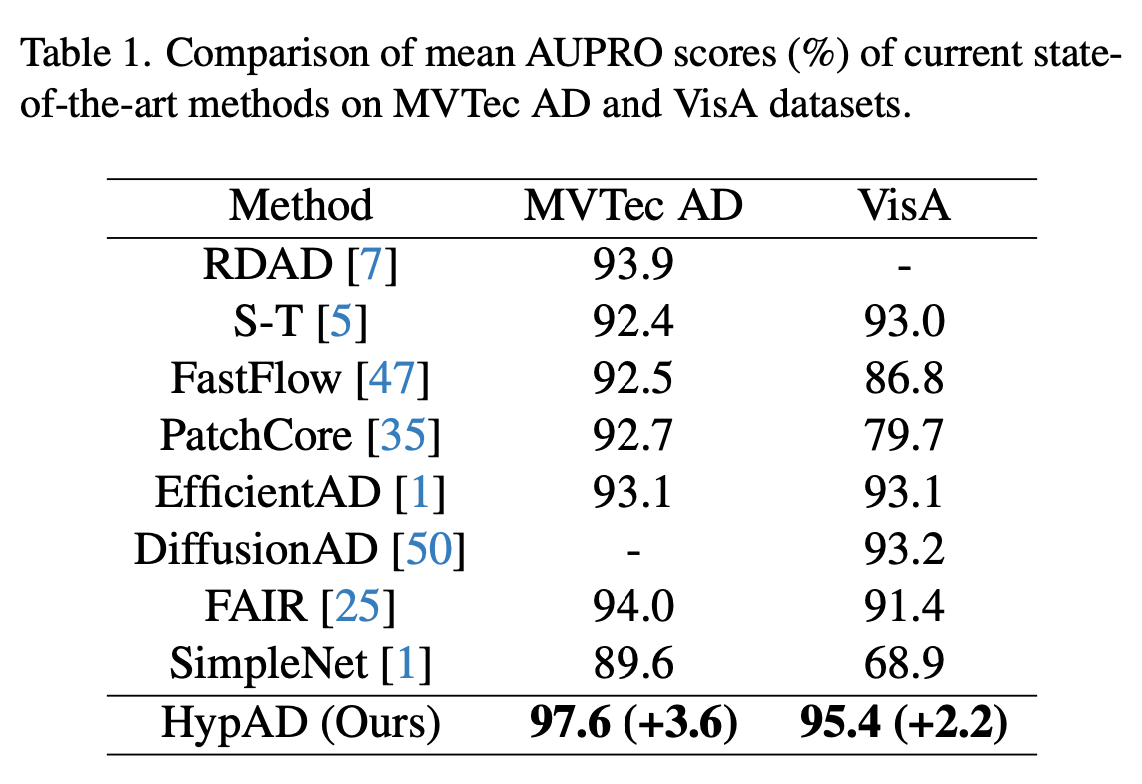
評価データとしては2019年に公開されたMVTec AD[3]とVisA[51]が使われました。Table1からHypADがいずれの手法についても安定的に良好な成績を示していることがわかります。
また、AUROCが不均衡データセットで過大評価されている可能性を棄却するため、AUPRを用いて評価しています(Table7)

4.1.5 結論
この論文では双曲異常検出(HypAD)法を構築し、双曲空間上での異常検出の有効性を示しました。ベンチマークデータセットでの広範な実験結果は、HypAD手法が最先端の性能を達成し、異常検出に対するその有効性を示しました。今後の研究の方向性としては、既存の損失関数を活用し、より強力な特徴表現を学習するために双曲空間の他のモデルを探求していくことが考えられます。
4.2 Unsupervised Universal Image Segmentation(Segmentation)
Segmentation の領域からは Unsupervised Universal Image Segmentation を紹介します。この論文はNiu等が報告した論文で、教師なしパノプティックセグメンテーションのための新しい統一フレームワークであるU2Segを提案しています。
4.2.1 概要
U2Segは革新的な教師なし学習フレームワークであり、インスタンスセグメンテーションとセマンティックセグメンテーションを統合することで、教師なしパノプティックセグメンテーションを実現しています。このアプローチは、CutLER(インスタンスセグメンテーション)とSTEGO(セマンティックセグメンテーション)の強みを組み合わせ、さらに洗練されたクラスタリング技術と疑似ラベル生成方法を導入することで、高品質な教師なしラベリングを可能にしています。
U2Segの特筆すべき点は、個々のタスク(インスタンス、セマンティック、パノプティックセグメンテーション)において、それぞれのタスクに特化した最先端の手法を凌駕する性能を示していることです。これは、統合的なアプローチの有効性を実証しています。
さらに、U2Segは少量のラベル付きデータでの学習シナリオ(ラベル効率の良い学習)においても卓越した性能を発揮しています。これは、モデルが教師なし学習で獲得した強力な特徴表現が、限られたラベル付きデータでの微調整に効果的に活用できることを示唆しています。
このフレームワークは、教師なし学習の可能性を大きく広げ、高品質なセグメンテーションを実現しつつ、データのアノテーションコストを大幅に削減する道を開いています。
4.2.2 背景
画像セグメンテーションは、コンピュータビジョン分野で重要な課題であり、近年大きな進展を遂げています。しかし、多くの手法は大量の人手によるラベル付きデータを必要とし、コストと拡張性の問題を抱えています。そこで、人手によるラベルなしで画像セグメンテーションを行う教師なし手法の研究が進められてきました。また、近年の教師なしセグメンテーションとしてCulLER[60]に代表される教師なしインスタンスセグメンテーションやSTEGO[24]のような教師なしセマンティックセグメンテーションは、それぞれ背景などの領域「stuff」を認識できなかったり、物体「things」が一体化された場合切り分けることが困難だったりしました。これらの問題はパノプティックセグメンテーション[12,29,31]で克服可能ですが、教師なしで克服するための研究はなされていませんでした。
4.2.3 アプローチ
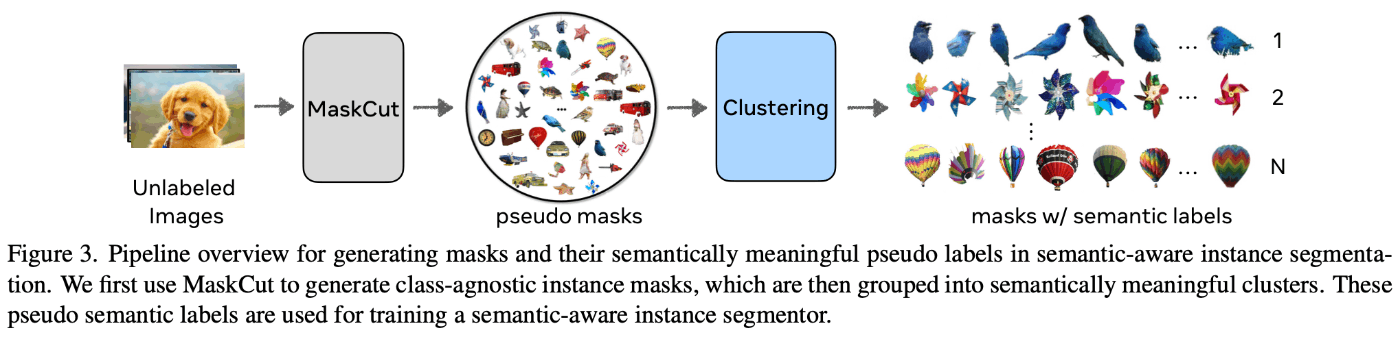
U2Segは、Fig. 2にしめすように、以下の3つのステップで構成されています。
高品質な離散的セマンティックラベルの生成:CutLER[60]を用いてマスクを生成していますが、これはDINO[8]とMaskCut[60]から得られたインスタンスマスクのアフィニティを反復的に学習することでその精度を向上させています。そして、クラスに依存しないインスタンスマスクにクラスタリング手法を適用し、セマンティックマスクを生成します。
擬似セマンティックラベルの生成:"things"ピクセル(ステップ1から)と"stuff"ピクセル(STEGOから)を組み合わせて、画像内の各ピクセルの擬似セマンティックラベルを生成します。
パノプティックセグメンテーションモデルの学習:生成された擬似的なインスタンスおよびセマンティックラベルを使用して、ピクセルレベル(セマンティックおよびクラス不可知インスタンスセグメンテーション)とインスタンスレベルのセマンティックラベルを同時に予測できるモデルを学習させます。

4.2.4 実験結果
U2Segの性能評価は、COCO、PASCAL VOC、UVO、Cityscapesなどの複数のデータセットで行われました。評価指標としてインスタンスセグメンテーションはAP、AR、セマンティックセグメンテーションはPixelACC、mIoU、パノプティックセグメンテーションとしてはPQ::Panoptic Quality、SQ:Segmentation Quality、RQ:Recgnition Qualityが用いられています。尚、PQ、SQ、RQの定義はAlexander Kirillov等によって2019年のCVPRで報告されています。主な実験結果はTable1に示す通りです。
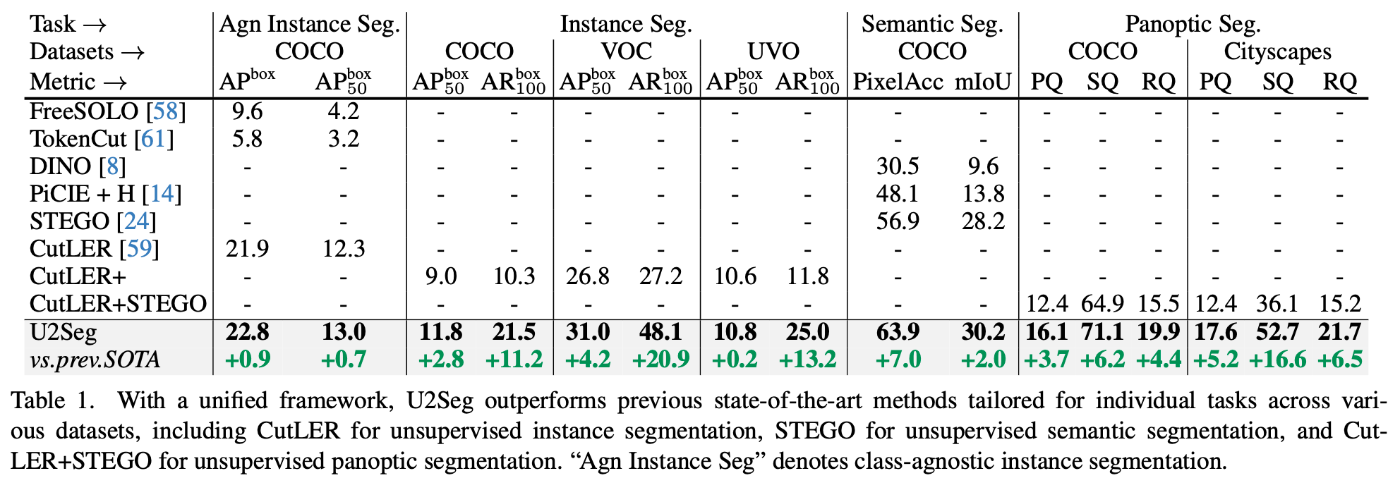
いずれの手法に対してもU2Segが数値的な優位を示しています。詳細には以下のとおりです。
教師なしインスタンスセグメンテーション:COCOデータセットでAP_box50で+2.8、AP_mask50で+2.6の性能向上、教師なしセマンティックセグメンテーション:COCOStuffデータセットでPixelAccで+7.0、mIoUで+2.0の向上をしました。教師なしパノプティックセグメンテーション:新たにベースラインを確立し、COCOデータセットでPQで+3.7、SQで+6.2の性能向上を達成しています。
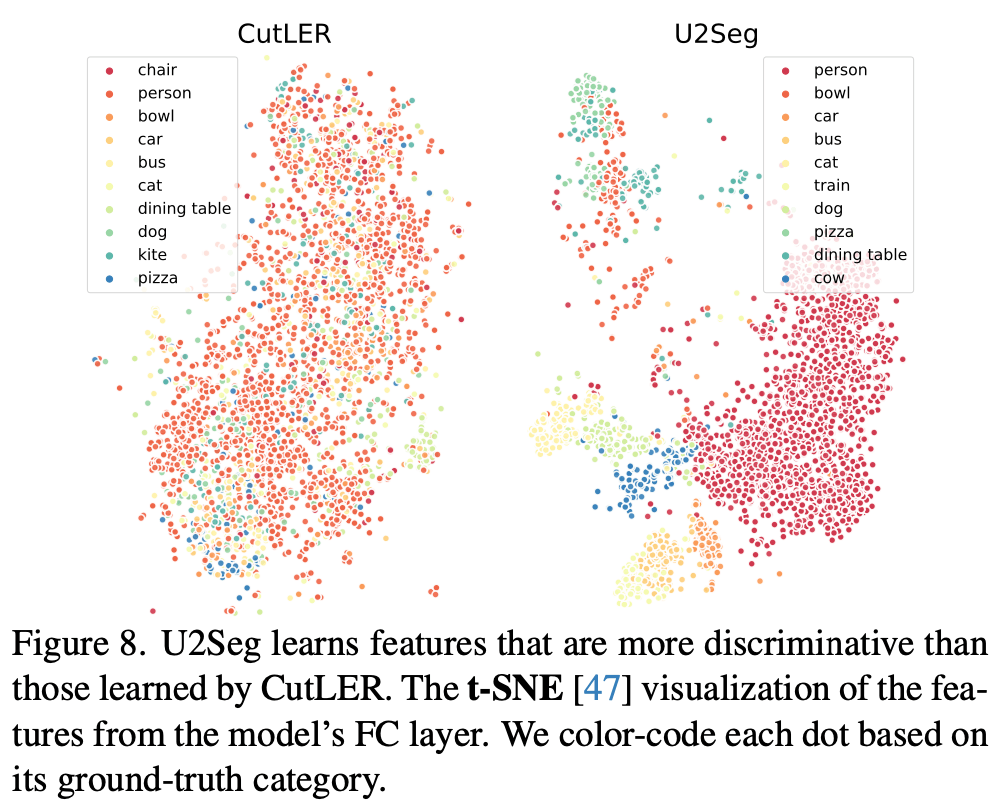
ラベル効率の良い学習:COCOデータセットの1%のラベルのみを使用した場合、CutLERと比較してAP_maskで+5.0の向上を示しました。さらに、t-SNE可視化により、U2Segが学習した特徴表現がCutLERよりも識別力が高いことが示されました(Fig.8)。
4.2.5 結論
U2Segは、教師なし普遍的画像セグメンテーションのための統一されたフレームワークを提供し、インスタンス、セマンティック、パノプティックセグメンテーションタスクを単一のモデルで実行できることを示しました。既存の個別タスクに特化した最先端手法を一貫して上回る性能を達成し、特にラベル効率の良い学習シナリオで優れた結果を示しました。この研究は、人手によるアノテーションに依存しない画像理解の新たな可能性を開き、より多くのトレーニングデータでスケールアップした際のさらなる性能向上が期待されます。今後の研究方向として、より大規模なデータセットでの学習や、モデルアーキテクチャの改良などが考えられます。
4.3 AiOS: All−in−One−Stage Expressive Human Pose and Shape Estimation(Pose Estimation)
Pose estimation 領域からは AiOS: All−in−One−Stage Expressive Human Pose and Shape Estimation を紹介します。この論文はSun等が報告した論文でExpressive Human Pose and Shape Estimation(EHPS)を画像からOne-shotで推論するフレームワークの提案となります。
4.3.1 概要
この論文はWang等が報告した研究で、表現力豊かな人体姿勢と形状推定(EHPS)のための革新的なAll-in-One-Stage (AiOS)フレームワークを提案しています。従来の2段階アプローチの限界を克服するため、AiOSは追加の人体検出ステップを必要とせず、複数人のEHPSを進歩的な集合予測問題として扱います。主要な特徴として、「Human-as-Tokens」デザインを導入し、グローバルとローカルの特徴表現を効果的に集約します。また、アテンションメカニズムを活用して人物間および人体部位間の複雑な関係性を分析し、混雑したシーンでの性能向上を実現しています。AGORAやUBody、EHFなどの複数のデータセットでの実験結果は、AiOSが最新のSOTA手法を大幅に上回るパフォーマンスを示しています。特に、NMVEとNMJEの指標で顕著な改善が見られました。本研究は、EHPSタスクに対する新しいアプローチを提示し、今後の研究方向性として、より多様なデータセットでのトレーニングや、トラッキング、3D位置推定などの関連タスクへの拡張可能性を示唆しています。
4.3.2 背景
表現力豊かな人体姿勢と形状の推定(EHPS)は、人体、手、表情の同時推定を行う重要なタスクです。従来の手法の多くはSMPL-X[30]などのパラメトリックな人体モデルを使用して身体各部位のパラメータを回帰する手法が一般的です。既存手法では、2段階アプローチを採用し、まず人体検出を行い、その後各部位の推定を個別に行っています(Fig. 1a)。この多段ステップはFig.1bのように抽象化されますが、最初に人物のバウンディングボックスを何らかの手法で獲得する必要があります。しかしこの方法では、1) クロッピングによる文脈情報の損失、2) ノイズの混入、3) 人物間や身体部位間の関連性の欠如といった問題があります。特に混雑したシーンでは性能が低下する傾向にあります。これらの課題に対処するため、追加の人体検出ステップを必要としない新しいワンステージのフレームワークが求められています。

4.3.3 アプローチ
この論文では、All-in-One-Stage (AiOS)と呼ばれる新しいフレームワークを提案しています。AiOSはDETRベースの構造を採用し、複数人のEHPSタスクを進歩的な集合予測問題として扱います。具体的には、「Human-as-Tokens」デザインを導入し、人体をボックストークンと関節トークンの集合として概念化しています。これらのトークンは、異なる教師信号と位置情報を用いて、グローバルとローカルの特徴表現を集約します。また、セルフアテンションとクロスアテンションのメカニズムを活用して、人物間および人物内の関係性を深く分析し、混雑したシーンでのパフォーマンスを向上させています。
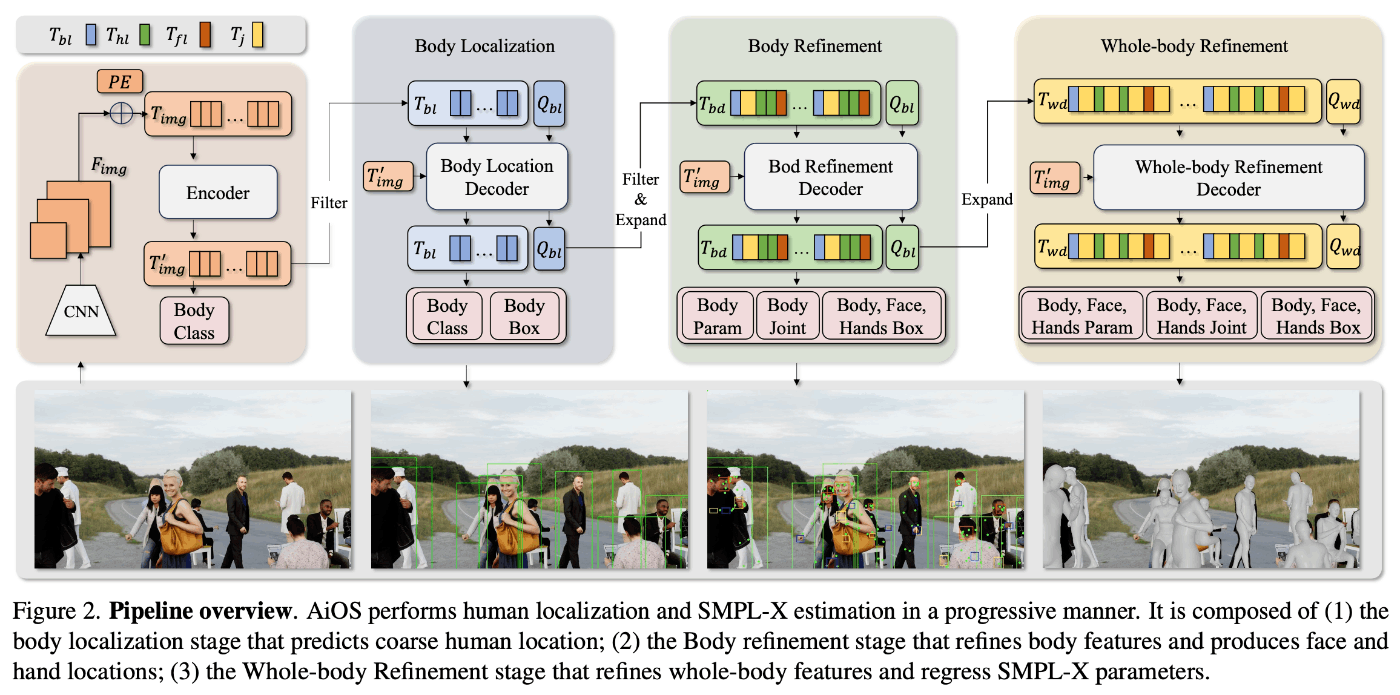
より具体的な計算としてはCNNバックボーンにより画像を
4.3.4 実験結果
提案手法の有効性を検証するため、AGORAやUBody、EHFなどの複数のデータセットで実験を行いました。Table 1では、AGORAテストセットにおいて、AiOSが比較手法を大幅に上回るパフォーマンスを示しており、Bodyの指標ではNMVE、MVE、MPJPEのいずれでも顕著な改善が見られます。それ以外の部分でも2番目あるいはそれに近いスコアを提示していることから、全体的な性能の改善がなされていることがわかります。

また、論文中の Table 2~5 において、
- AiOSが他のワンステージ手法と比較して大幅な性能向上を達成していること
- UBodyのデータセットを使った評価において、AiOSはファインチューニングなしに既存のファインチューニングモデルと同等程度の性能を出していること
- EHFデータセットを用いた評価において、全身ではAiOSが最もよい性能を示しており、Hands、Faceでも最高に準じる性能であること
- Attentionフォーマットを変えた場合と、SMPL−Xのフィードバックのかけ方を変えたときのAblation Studiesを示しており、いずれの場合であってもAiOSの方法が最も優れた性能を示していること
が言及されています。
Fig. 3とFig. 4では、視覚的な比較結果を示しており、AiOSが他の手法と同等以上の品質で人体姿勢と形状を推定できていることが確認できます(以下にFig.4のみを示します)。

4.3.5 結論
この論文では、表現力豊かな人体姿勢と形状推定のための初のAll-in-One-Stageモデルを提案しました。身体、顔、手に関連するトークンの組み込み、ローカルとグローバルな特徴の集約、様々な教師信号の活用を探求しました。さらに、人物間および身体部位間の関連性を確立するためのセルフアテンションメカニズムを設計し、最高のパフォーマンスを実現しました。SOTAの結果は、EHPSを進歩的な集合予測問題として扱うワンステージパイプラインが全体的なパフォーマンスに大きく貢献していることを示しています。この研究がEHPS研究コミュニティに新たな洞察をもたらすことを期待しています。ただし、さらなる改善の余地があり、特に多人数の実データを含むデータセットでのトレーニングや、トラッキングや3D位置推定などのタスクへの拡張が今後の課題として挙げられます。
4.4 HomoFormer: Homogenized Transformer for Image Shadow Removal(Others)
Othersの領域からは HomoFormer: Homogenized Transformer for Image Shadow Removal を紹介します。この論文はXiao等が報告した論文で、影を画像中の不均一な分布と捉え均質化することによって影を除去し、画像の品質の向上を図った報告となります。
4.4.1 概要
この論文では、画像の影除去タスクにおいて、影の不均一な分布と多様なパターンという課題に取り組む新しいアプローチを提案しています。HomoFormerと名付けられた局所ウィンドウベースのTransformerモデルを開発し、ランダムシャッフル操作とその逆操作を導入することで、不均一な影の分布を均質化しています。これにより、重み共有モデルでも複雑な影の劣化を効果的にモデル化できるようになりました。HomoFormerは入力解像度に対して線形の計算量を実現しつつ、不均一に分布した影の劣化をモデル化する課題を克服しています。
4.4.2 背景
影は自然のシーンで光源が部分的または完全に遮られるときに、撮影された画像に遍在しています。しかし、影は画像の視覚的品質を損なうだけでなく、物体追跡[40]や検出[36]、顔認識[56]など、様々な下流の視覚タスクに深刻な制限を課します。そのため、影のある画像からきれいな画像を復元することは重要です。しかし、影の空間分布が不均一で多様なパターンを持つため、CNNやウィンドウベースのTransformerなどの主流モデルでは効果的にモデル化することが困難でした。これらのモデルは重み共有の性質を持つ一方で、影による品質の劣化の程度は部分部分で異なり、複雑な劣化度の影のケースに対して単一のパラメータセットで妥協点を探る必要がありました。既存のアプローチでは、この不均一性の課題に十分に対処できていませんでした。
4.4.3 アプローチ
この論文では、不均一な分布を均質化するという新しい視点から問題にアプローチしています(Fig. 1)。ランダムシャッフル操作とその逆操作を導入し、元の非均一な影の分布を均質化空間に射影します。これにより、重み共有モデルでも効果的に影の劣化をモデル化できるようになります。概念的な図がFig.1に示されています。

Fig.2 にHomoFormerのスキームを示します。全体的にU-net様の構造をもっており、各コンポーネントにHomoBlockを含みさらにその中に、局所的な自己注意機構と組み合わせることで、HomoFormerは入力解像度に対して線形の計算量を実現しつつ、不均一に分布した影の劣化をモデル化する課題を克服しています(Fig.3)。また、構造情報のモデル化のために、位置情報を考慮したフィードフォワードネットワーク(SMLP)も導入しています(Fig.3)。

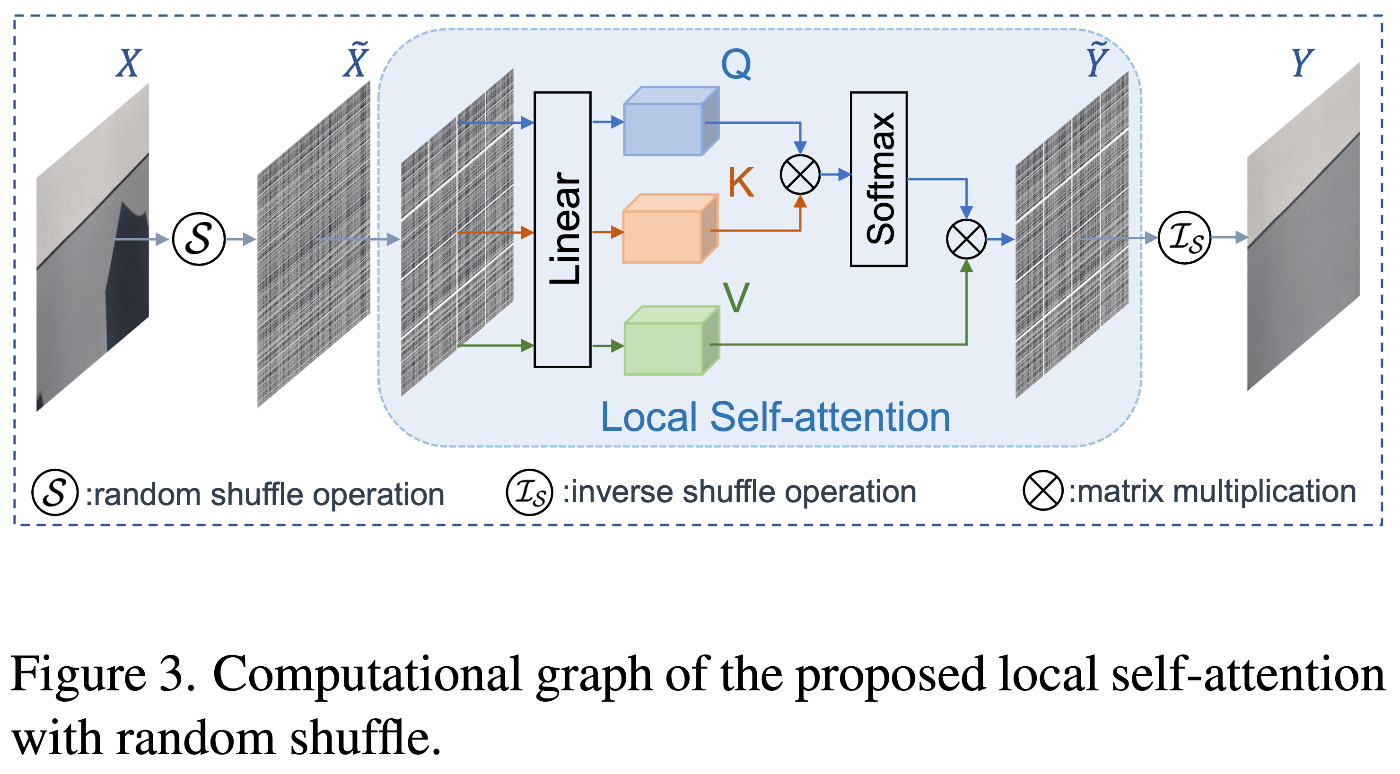

4.4.4 実験結果
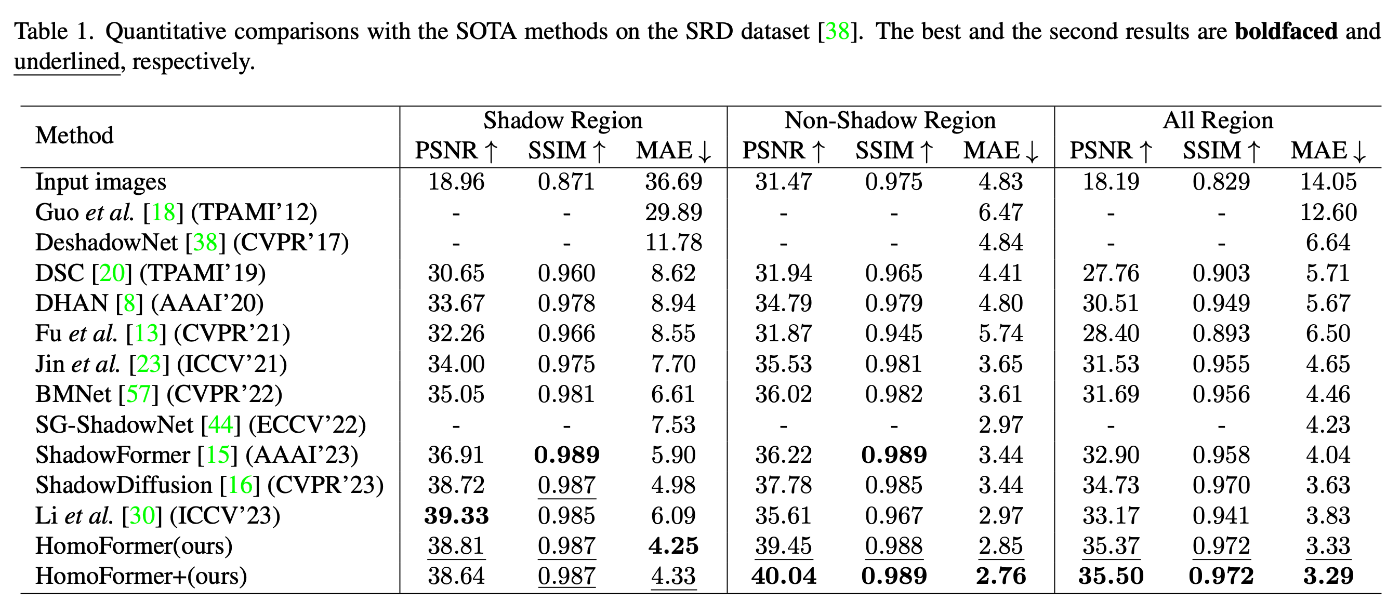
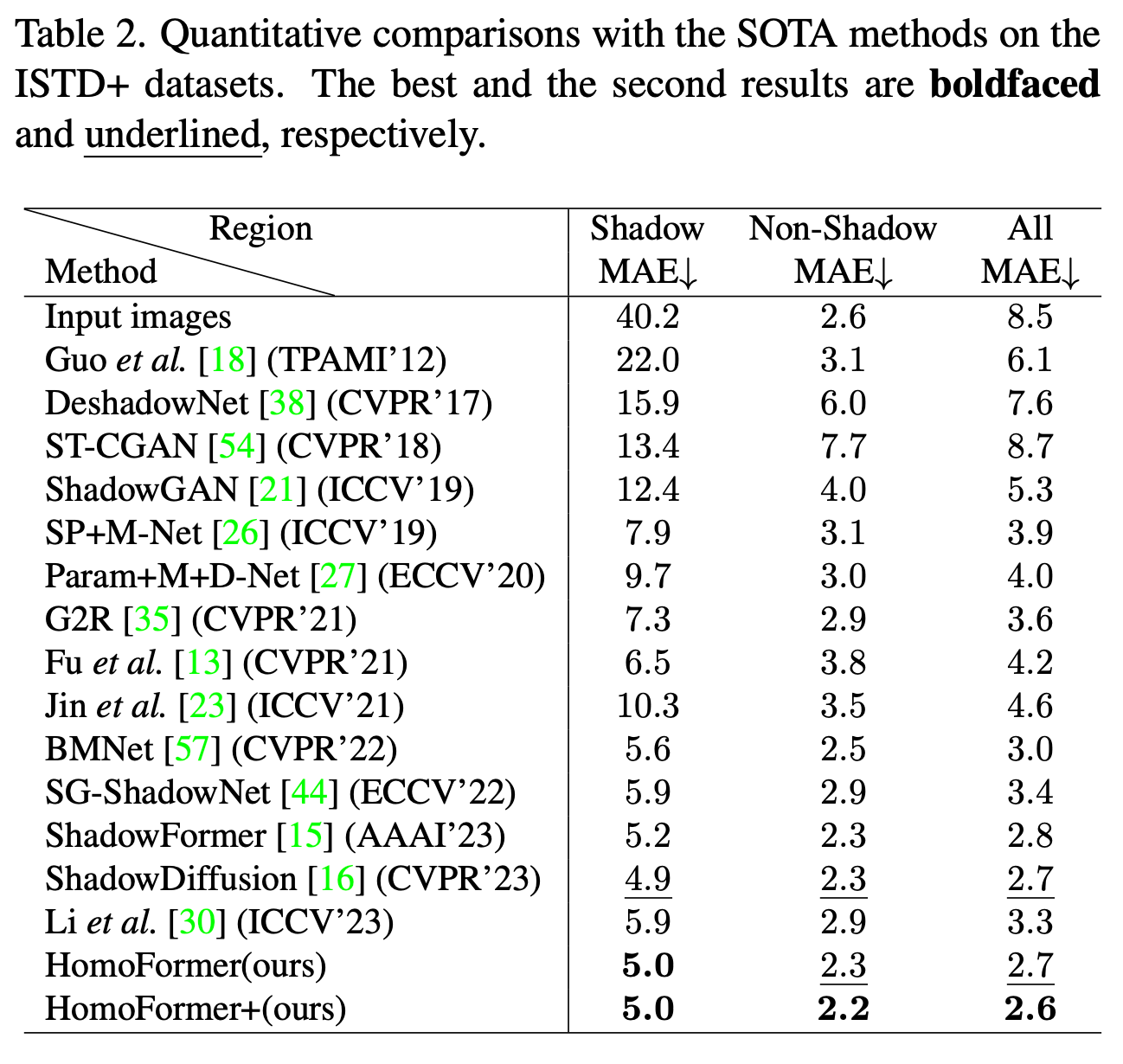
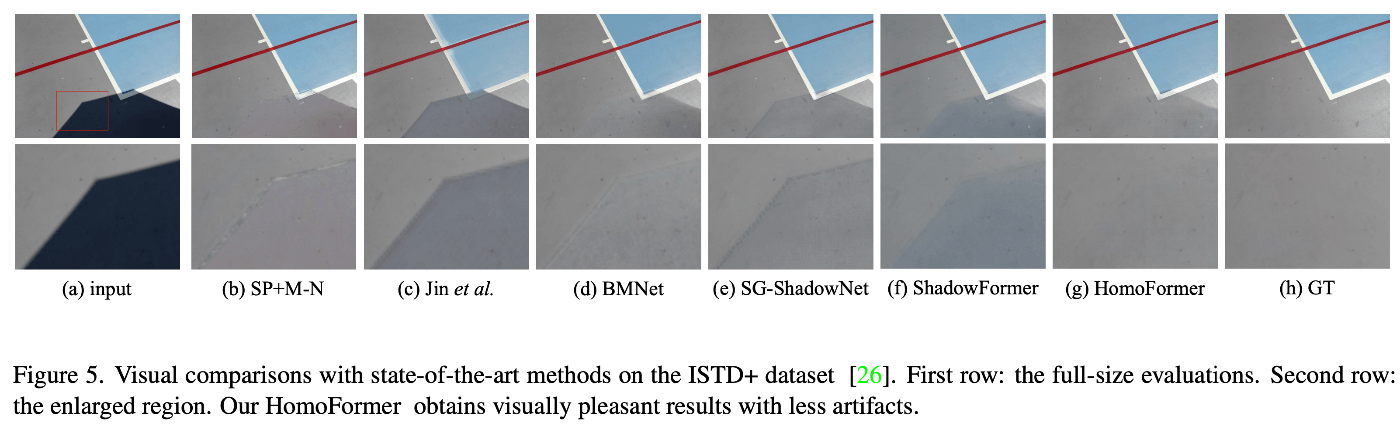
ISTD+データセットとSRDデータセットを用いて評価を行い、最先端の手法と比較しています。Table 1とTable 2に示すように、HomoFormerは両データセットにおいて最高のMAE、PSNR、SSIMスコアを達成しています。視覚的な比較はFigure 5とFigure 6に示されており、HomoFormerがより少ないアーティファクトで影を除去できていることがわかります。

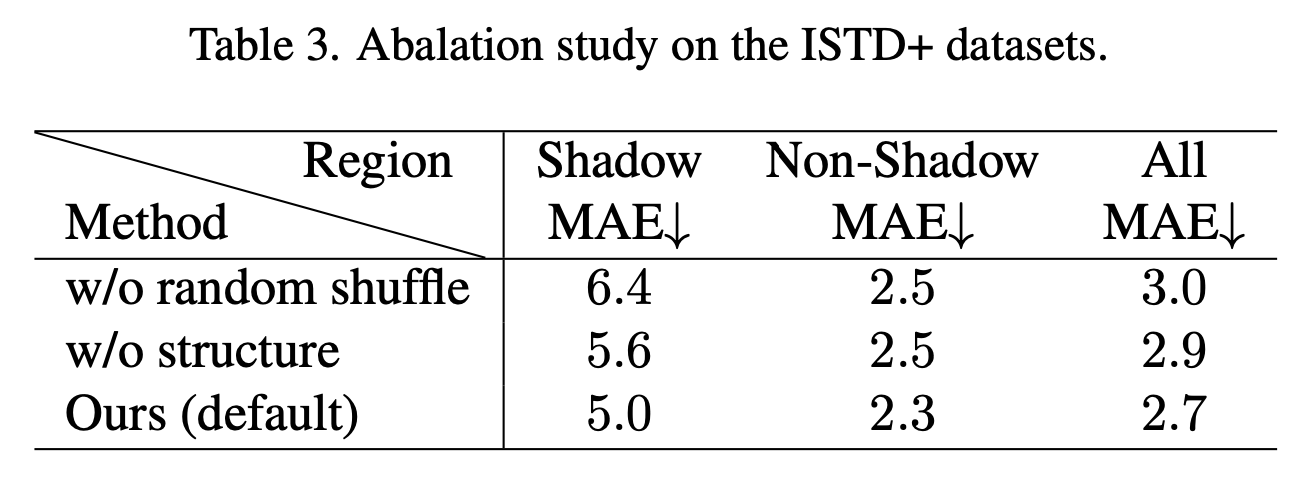
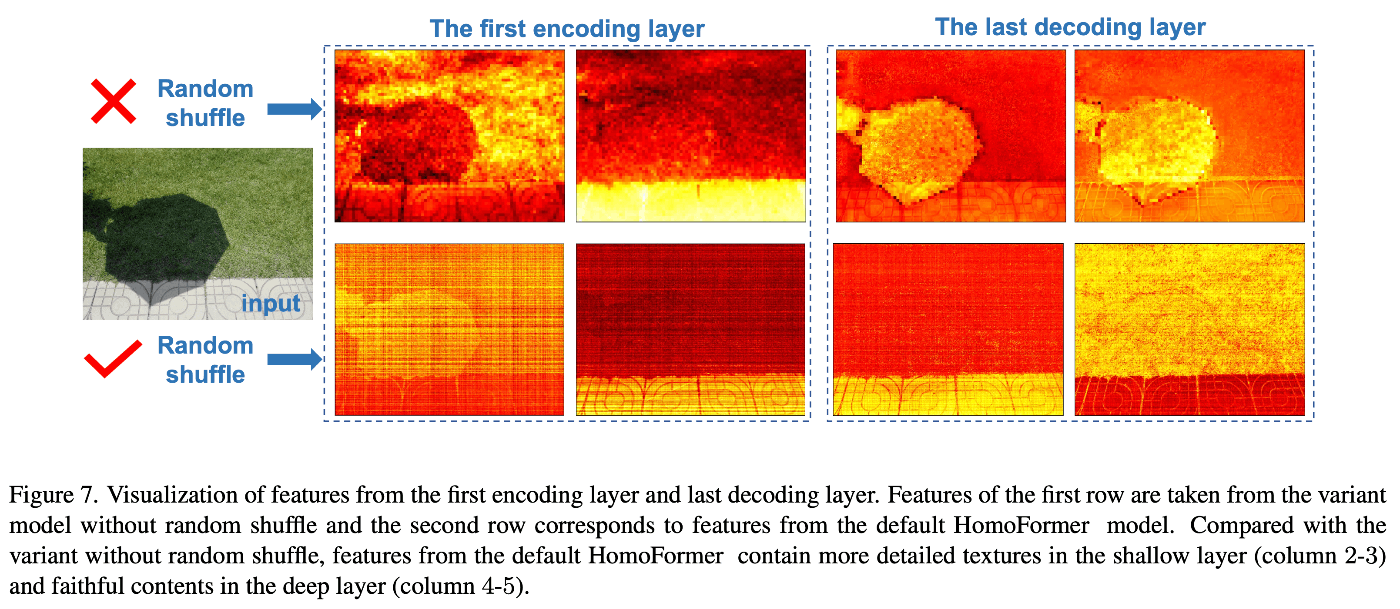
アブレーション実験(Table 3)では、ランダムシャッフルと構造モデリングの効果を検証しています。それぞれのコンポーネントを用いなかった場合の影領域は性能が大きく低下している一方、非影領域は大きく変わっていないことから提案手法が影の除去に大きな役割を果たしていることが示唆されます。ランダムシャッフルを用いない場合の視覚的な効果はFig.7に示されています。
4.4.5 結論
この論文は、画像の影除去タスクにおいて、影の不均一な分布と多様なパターンという課題に対する新しいアプローチを提案しました。ランダムシャッフル操作とその逆操作を導入することで、不均一な分布を均質化し、重み共有モデルでも効果的に影の劣化をモデル化できるようになりました。提案されたHomoFormerは、最先端の手法を上回る性能を達成し、視覚的にも優れた結果を示しています。この均質化アプローチは、影除去以外の画像復元タスクにも応用できる可能性があり、今後の研究の方向性として示唆されています。
参考文献
[1] CVPR2020
[2] CVPR2021
[3] CVPR2022
[4] CVPR2023
[5] CVPR2024
[6] Hyperbolic Anomaly Detection
[7] Unsupervised Universal Image Segmentation
[8] AiOS: All−in−One−Stage Expressive Human Pose and Shape Estimation
[9] HomoFormer: Homogenized Transformer for Image Shadow Removal

Discussion