こんにちは、HACARUS でインターンをしている山下です。
今回は、Segment Anything Model (SAM) のような高性能のセグメンテーションモデルを限られたリソース下で利用したい場合の選択肢となる NanoSAM (Apache License 2.0) を紹介します!
NanoSAM は通常の SAM とどう違うのか?
SAM は Meta によって公開された高性能のセグメンテーションモデルです。SAM の基本的な使い方 や 他のモデルと組み合わせて使う方法 は、以前の記事で紹介しました。
SAMは、入力画像を image encoder でテンソルに変換した上で座標指定などのプロンプトと組み合わせ、mask decoder でマスクを出力するという構造になっています。

SAM の構造(パラメータ数は実測値)
上の画像中にも示したとおり、NanoSAM の構造上の特徴は image encoder として ResNet18 を使用する点です。オリジナルの SAM で使われている ViT-H という image encoder モデルはパラメータ数が 608M であるのに対し、 ResNet18 のパラメータ数は 15.1M と大幅に軽いモデルとなっています(mask decoder は SAM と同じものを使います)。
NanoSAM のもう1つの特徴として、TensorRT を利用して Jetson Orin シリーズなど GPU を搭載したエッジデバイス上での動作に最適化されていることです。これにより SAM と比較して大幅に高速な動作を実現できるようで、リアルタイムでのセグメンテーションにも応用可能であると謳っています。NanoSAM は ONNX 形式のモデルファイルも提供しているので、今回は、気軽に試すために、TensorRT ではなく onnx-runtime を使って CPU または GPU で推論する方法を紹介します。
今回使用するコードは、Google Colab でも公開しているので、是非 こちらのリンク からコピーして実際に動かしてみてください。
実行手順
リポジトリのクローン
初めに NanoSAM のリポジトリをクローンし、その中で作業をしていきます。
git clone https://github.com/NVIDIA-AI-IOT/nanosam.git
cd nanosam
NanoSAM リポジトリの README に書かれたセットアップ手順は TensorRT で動かすためのものなので、ONNX で推論する場合は以下の手順で実施します。
ライブラリのインストール
NanoSAM の動作確認に必要なライブラリをインストールします。
基本的なフレームワークとして PyTorch、結果の表示などに Matplotlib、そして TensorRT なしで推論を行うために ONNX-Runtime が必要です。Google Colab を使用する場合は PyTorch と Matplotlib が予めインストールされているため、ONNX-Runtime のみインストールすれば十分です。
ONNX-Runtime は CPU にも GPU にも対応していますが、インストールコマンドが若干異なります(参考)。実行環境(Colab であればランタイムのタイプ)に適したコマンドを1つ選び、実行してください。CPU ランタイム利用時は単純ですが、GPU ランタイム利用時はやや注意が必要な場合があります。
GPU 利用時のヒントはこちら
- Colab で GPU ランタイムを利用する場合、ノートブックを開いた状態で 上部ツールバーの「ランタイム」から「ランタイムのタイプを変更」を選択し、ハードウェアアクセラレータを T4 GPU に変更して保存します。
- Colab にインストールされている CUDA のバージョンは
nvcc -Vで表示できます。本記事執筆時は 12.2 でした。必要に応じて、異なるバージョンの CUDA をインストールする手段もあるようです。 - CUDA のバージョンによっては ONNX-Runtime のバージョンを指定して合わせる必要もあるかもしれません。上手くいかない場合はバージョンの対応表なども参考にしてください。Colab ノートブックでは CUDA のバージョンに合わせて、ONNX-Runtime はバージョン 1.17 をインストールするよう指定しています。
- GPU が利用できているかの確認は、「ランタイム」から「リソースの表示」を選択することでできます。また、ノートブックを最後まで実行した上で
print(predictor.image_encoder_session.get_providers())を実行することで推論に実際に利用されているプロバイダーを表示できるため、もしCUDAExecutionProviderになっていなければバージョン不整合などを疑ってみてください。
# CPUのみを利用する場合
pip install onnxruntime
# GPUを利用し、CUDAのバージョンが12未満の場合
pip install onnxruntime-gpu
# GPUを利用し、CUDAのバージョンが12.xの場合
pip install onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
モデルファイルのダウンロード
NanoSAM を ONNX で推論するためには、画像を特徴量に変換する image encoder モデルと、特徴量をマスク画像に変換する mask decoder モデルの2つが必要です。NanoSAM 公式の README に記載されたリンクから以下のようにダウンロードします。TensorRT を利用する場合はこのファイルを変換する必要がありますが、今回は ONNX 形式のまま使用します。
mkdir -p data
curl -kL -o data/mobile_sam_mask_decoder.onnx 'https://drive.google.com/uc?export=download&id=1jYNvnseTL49SNRx9PDcbkZ9DwsY8up7n'
curl -kL -o data/resnet18_image_encoder.onnx 'https://drive.google.com/uc?export=download&id=14-SsvoaTl-esC3JOzomHDnI9OGgdO2OR'
ONNX推論用の predictor クラスの作成
nanosam/utils/predictor.py を参考にして、以下のような ONNX 推論用の predictor クラスを作成します。
class OnnxNanosamPredictor:
def __init__(self,
image_encoder_path: str,
mask_decoder_path: str,
image_encoder_size: int = 1024,
orig_image_encoder_size: int = 1024,
):
self.image_encoder_session = ort.InferenceSession(
image_encoder_path,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"]
)
self.mask_decoder_session = ort.InferenceSession(
mask_decoder_path,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"]
)
self.image_encoder_size = image_encoder_size
self.orig_image_encoder_size = orig_image_encoder_size
def set_image(self, image):
self.image = image
self.image_tensor = preprocess_image(image, self.image_encoder_size)
self.features = self.image_encoder_session.run(
["image_embeddings"],
{
"image": self.image_tensor.numpy(),
}
)[0]
def predict(self, points, point_labels, mask_input=None):
points = preprocess_points(
points,
(self.image.height, self.image.width),
self.orig_image_encoder_size
)
mask_iou, low_res_mask = run_mask_decoder(
self.mask_decoder_session,
self.features,
points,
point_labels,
mask_input
)
hi_res_mask = upscale_mask(
low_res_mask,
(self.image.height, self.image.width)
)
return hi_res_mask, mask_iou, low_res_mask
このクラスでは、はじめに set_image() を実行し画像に対する image_encode による特徴量を算出しておき、 predict() で、この特徴量とクリックポイントなどのプロンプトからマスクを生成します。では、この predictor を使って、実際の画像に適用してみましょう。
ONNX推論の実行
まず、以下のように ONNX ファイルのパスを指定して、 predictor のインスタンスを作成し、対象の画像に対して、 set_image() で特徴量を求めます。
# ONNX files
image_encoder_path = "data/resnet18_image_encoder.onnx"
mask_decoder_path = "data/mobile_sam_mask_decoder.onnx"
# Instantiate ONNX-Runtime predictor
predictor = OnnxNanosamPredictor(
image_encoder_path,
mask_decoder_path
)
# Read image and run image encoder
image = PIL.Image.open("assets/dogs.jpg")
predictor.set_image(image)
プロンプトの設定
NanoSAM のプロンプトは、SAM と同様で、クリックポイントによるプロンプトとバウンディングボックスによるプロンプトの両方に対応しています。NanoSAM の README にもある通り、point label を以下のように指定すると使い分けができるようです。
| Point Label | Description | 説明 |
|---|---|---|
| 0 | Background point | クリックポイントを含むように指定 |
| 1 | Foreground point | クリックポイントを含まないように指定 |
| 2 | Bounding box top-left | バウンディングボックス左上の点を指定 |
| 3 | Bounding box bottom-right | バウンディングボックス右下の点を指定 |
ここでは、以下のように (100, 100) を左上の点、 (850, 759) を右下の点としたバウンディングボックス形式のプロンプトを設定してみます。
bbox = [100, 100, 850, 759] # x0, y0, x1, y1
points = np.array([
[bbox[0], bbox[1]],
[bbox[2], bbox[3]]
])
point_labels = np.array([2, 3])
そして、 set_image() で得られた特徴量と、上記のプロンプトからマスクを求めると以下のようになります。
mask, _, _ = predictor.predict(points, point_labels)
mask = (mask[0, 0] > 0).detach().cpu().numpy()
# Draw results
plt.imshow(image)
plt.imshow(mask, alpha=0.5)
x = [bbox[0], bbox[2], bbox[2], bbox[0], bbox[0]]
y = [bbox[1], bbox[1], bbox[3], bbox[3], bbox[1]]
plt.plot(x, y, 'g-')
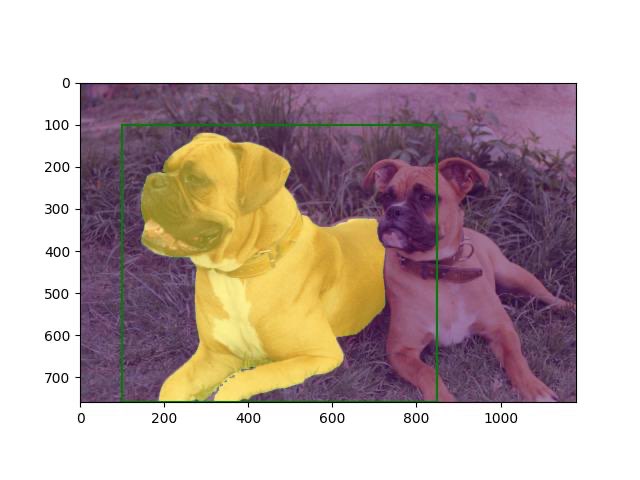
生成されたdata/basic_usage_out.jpg
緑色の枠がプロンプトとして与えたバウンディングボックスで、その中の物体である大きな犬がしっかりとマスクされている様子が見て取れます。
これまでの SAM についての連載記事に倣って寿司画像に対するセグメンテーションも試してみました。上記のサンプルスクリプトを基に、以前の記事と同様のタスクを実行した結果が以下の画像です。

寿司画像にNanoSAMによるマスクを適用した結果
緑色の星印がプロンプトとして与えた点で、指定点が示すネタであるサーモンをマスクできています。概ね満足のいくセグメンテーションができている様子です。
ONNX推論の速度について
推論部分にかかる時間を Colab 上で%%timeit -n 10 コマンドにより計測すると、CPU 実行で 1.86 秒、GPU 実行で 0.16 秒程度となりました。ONNX Runtime で動かす場合でも、GPU を使った方が圧倒的に速くなるようです。ちなみにオリジナルの SAM を Colab の CPU ランタイムで動かしてみたところ、画像1枚の処理に2分以上かかりました。CPU での実行だけで比較しても NanoSAM の軽さ・速さは大きな利点となり、実用性は高そうです。
まとめ
SAM の軽量版である NanoSAM を ONNX-Runtime により実行する手順を整理し、実行結果を確認しました。今回の手順を再現すれば TensorRT 対応のエッジデバイスに限らず、様々な環境で比較的軽量なセグメンテーションが実施できることでしょう。
また次回以降の記事で他モデルとの具体的な性能の比較や、動作の速さを活かした活用事例が紹介できたら幸いです。

Discussion
残念、Google Drive の場所からダウンロードできなくなってしまっている。