Numerai:トーナメントで試したモデリングを振り返る
この記事はNumerai AdventCalendar 2021の3日目の記事です。
この記事では今年の3月ごろから始めた自分のNumeraiトーナメントのモデリングについて、自分の整理がてら共有できればと思います。
モデル構築の方針
Forumなどを見た感じ、簡単なカラム方向(特徴量)の分析は実際に手を動かしながら検証しないといけないので分析にはリソースが必要だなと感じました。
実装の試行回数を増やして時間をかけるよりは正直モデルの理論を勉強したいということもあり、特徴量選択ではなく、学習するモデルの手法にフォーカスしてました。
特徴量選択関係は共通の知見だと思うので、Forum, Twitterなどで流れてきてほしい願望がありました。
今年やったことは以下の3つになります。
- semi-supervisedを利用したモデルの構築
- 既存のGBDTモデルをヘッジできるモデルの構築
- NNモデルの構築
それぞれについてお話します。
今の所うまく動いているものもありますが、検証期間が短いので参考程度に見ていただくほうがいいかもです。
semi-supervisedの枠組みでモデル構築
データ的にi.i.dの仮定は強すぎる&そもそもタスクとして難しいこともあり、通常とは異なるモデリングが必要そうということは開始時に何となく感じていました。
なので、liveデータをモデリング時に考慮する手法を試していました。
試した手法は大きく分けて2つです。
liveを含めたPCAを特徴量に利用する
こちらはシンプルに考えられる手法ということもあり、一番最初に検証していました。
以下の記事でも言及されています。
特にこだわった点などはありませんが、特徴量グループごとの主成分を利用したほうが分析しやすそうだと思い、各グループごとにPCAをかけてました。
liveから学習データのsample weightを計算する
「同一era内のサンプルはi.i.dをそれなりに仮定できるが、eraの変化でデータの分布が変わってしまう」という仮定をおいたときにeraによってモデルのパラメータを推定するために利用するデータなどは変更するべきと思い試したものです。
アプローチとしてはliveデータと近いかどうかをもとに学習データに重みをつけて学習しています。
重みの計算方法は色々あると思いますが、イメージとしては各eraごとの確率分布を推定してliveの分布との近さを重みにしています。
なので、データごとにではなくeraごとに重みを計算をしています。
liveのパフォーマンス
上の学習手法は特にモデルの種類に制約などはないので、線形モデル、GBDT、MLPで試してました。
学習で利用した特徴量は思考停止で310全特徴量とオプションでPCA特徴量です。
結論としてはNN以外は一応パフォーマンスの向上が見られて、特にCatboostがなぜか良かったです。
liveのパフォーマンスはこちらで確認しています。
| モデルの種類 | PCA特徴量 | 検証期間(Round) | weightを追加して学習したときのCorr+MMCの平均変化 |
|---|---|---|---|
| XGBoost(Example script) | なし | 271 ~ 288 | +0.0009 |
| LightGBM | あり | 267 ~ 288 | +0.0015 |
| Linear Model(Ridge) | あり | 267 ~ 288 | +0.0018 |
| MLP | あり | 267 ~ 288 | -0.035 |
| Catboost | なし | 261 ~ 288 | +0.0156 |
こちらは通常の学習とlive重みつき学習とのパフォーマンスを比較したものですが、Catboostだと差が如実にでてます。
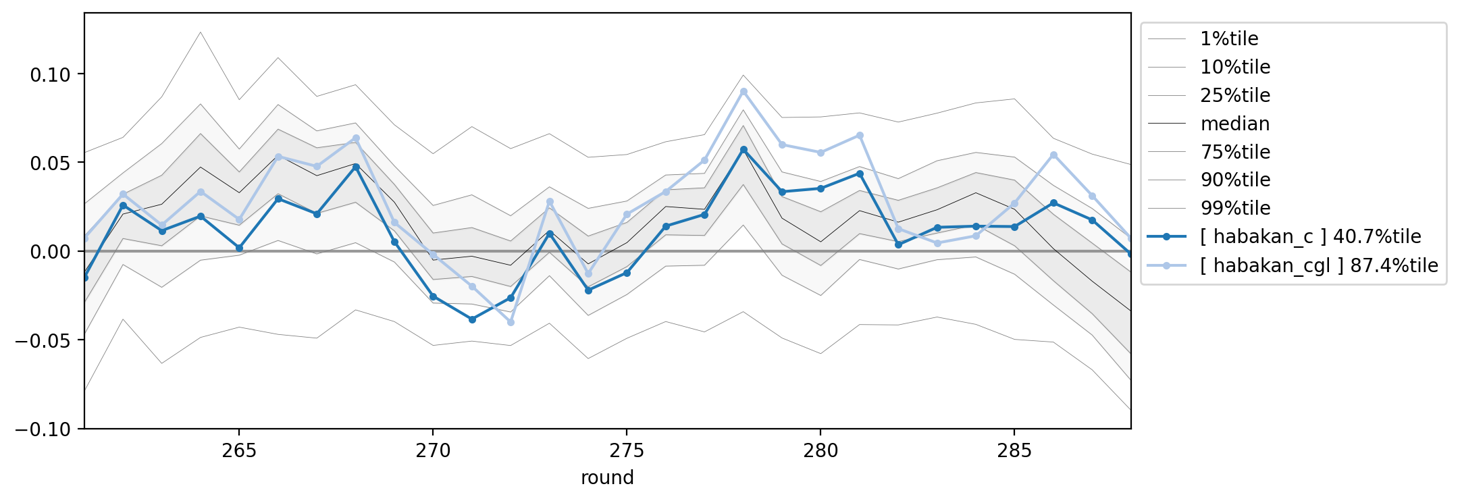
Catboostの通常学習(habakan_c)とweight付き学習(habakan_cgl)の比較 Round: 261~288
なぜCatboostだとここまで差がでるかは検証中ですが、現在のLBも高めなので結果的に自分のメインモデルになっています。
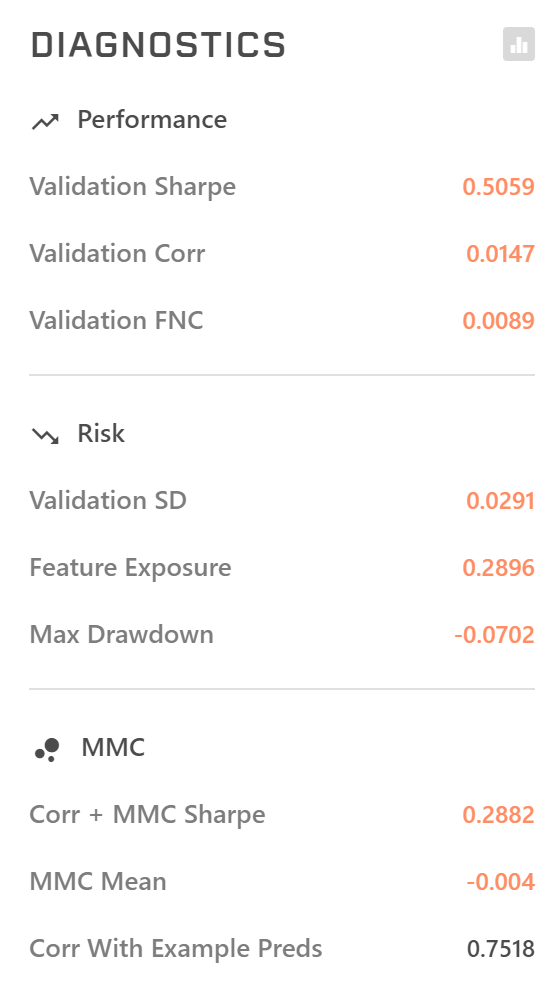
ちなみにDiagnosticsは、なかなかひどいです。
Gradient Boosting Decision Treeモデルの後半iterationの利用
ヘッジ手法としてGBDTの後半iterationのみを利用するとうまくいかないかと思い検証していました。
勾配ブースティングアルゴリズムはご存知の通り、定義した損失関数に対する勾配情報をもとに弱学習器を作成するアルゴリズムです。
以下はXGBoostの最適化する損失関数です。
この損失関数がMSEを利用した回帰問題のとき、第一項目は
ここで、Numeraiの目線に立つと、もし仮にベースとなる学習器が線形モデルであった場合、
ただ、XGBoostの場合は、テイラー展開による近似で二次微分も利用していること・
上記のことを考えた上で、以下の仮説を立ててみました。
学習したGBDTの
iteration以降のモデルは n+1 iterationまでのモデルに対してproportionのある直交化した予測であり、 n iteration 以降の学習は n+1 iterationまでのモデルをメタモデルとした場合のMMCを学習することに相当する n
真のMMCを学習できるわけではありませんが、もしこちらがある程度当たっていれば、学習したGBDTに対するヘッジモデルとして後半iterationモデルも並行して提出することもありかもしれません。
以下が予測のコアとなるコードで、2000iterationで学習したGBDTに対して、500iteration以降のモデルを使って予測しています。
model = LGBMRegressor(n_estimators=2000)
model.fit(X_train, y_train)
start_iteration = 1500
prediction = model.predict(X_test, start_iteration_predict=start_iteration)
学習のメインコードは以下のURLのものとほぼ同じです。
簡易的に全iterationを利用した結果と1500iteration以降で比較した結果で検証していました。
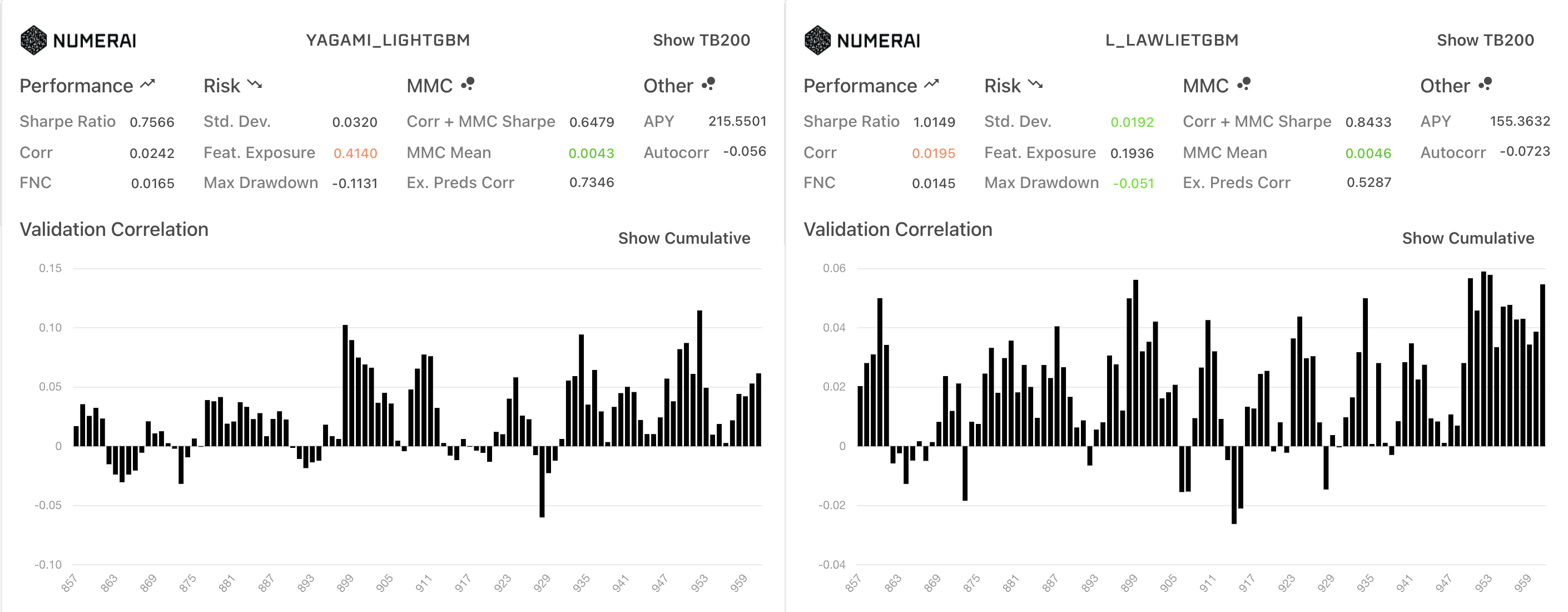
全iteration(左)と1500以降のDiagnostics比較
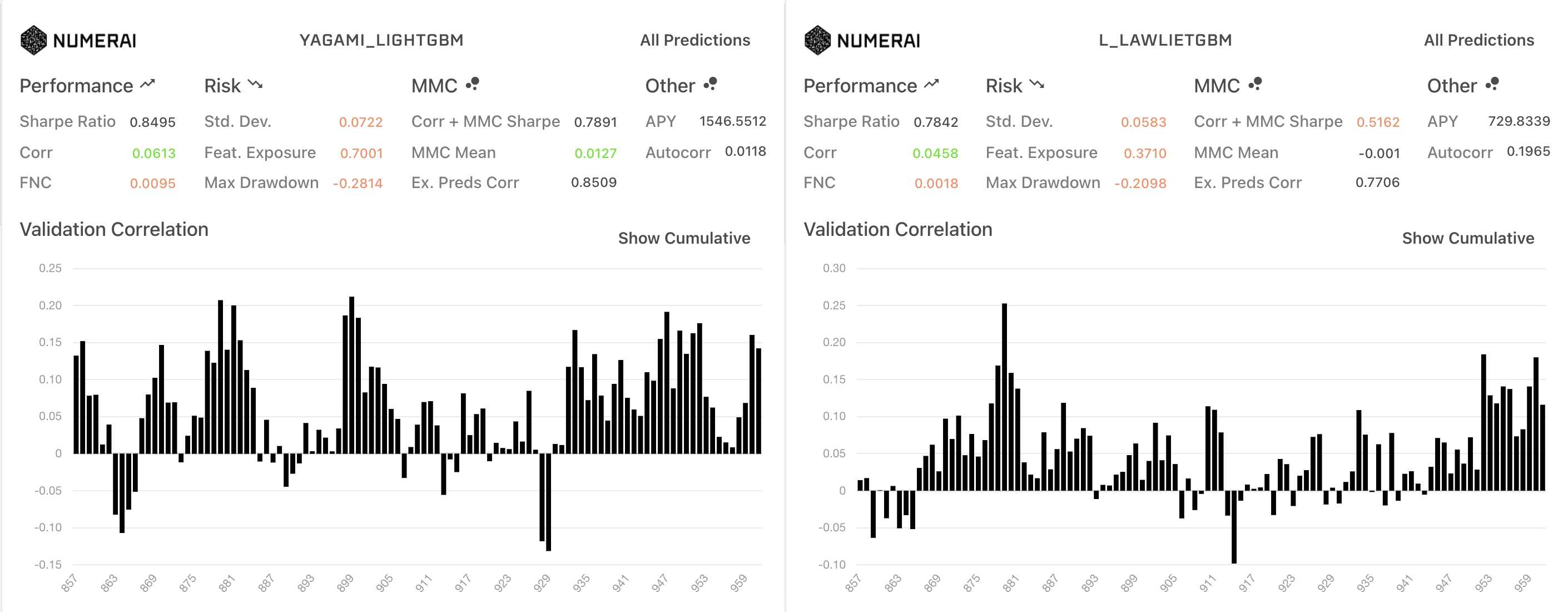 TB200での比較
TB200での比較
DiagnosisticsではAllPredictionsにおいてはベースラインより1500以降がcorr meanが低い一方、sharpe ratioやmmcなどの向上が見られました。
一方で、TB200だと1500以降のMMCはほとんどなくなっているのも興味深いです。
こちらが、全iterationのモデルをメタモデルとしたときのMMCの推移ですが、後半になるにつれてMMCが向上していました。
| 予測に利用したiterationの範囲 | (0~2000をメタモデルとした)MMC |
|---|---|
| 0~500 | -0.00187713 |
| 500~1000 | 7.60351e-05 |
| 1000~1500 | 0.000836491 |
| 1500~2000 | 0.00256483 |
Liveではそれぞれ以下のモデルとしてモニタリングしています
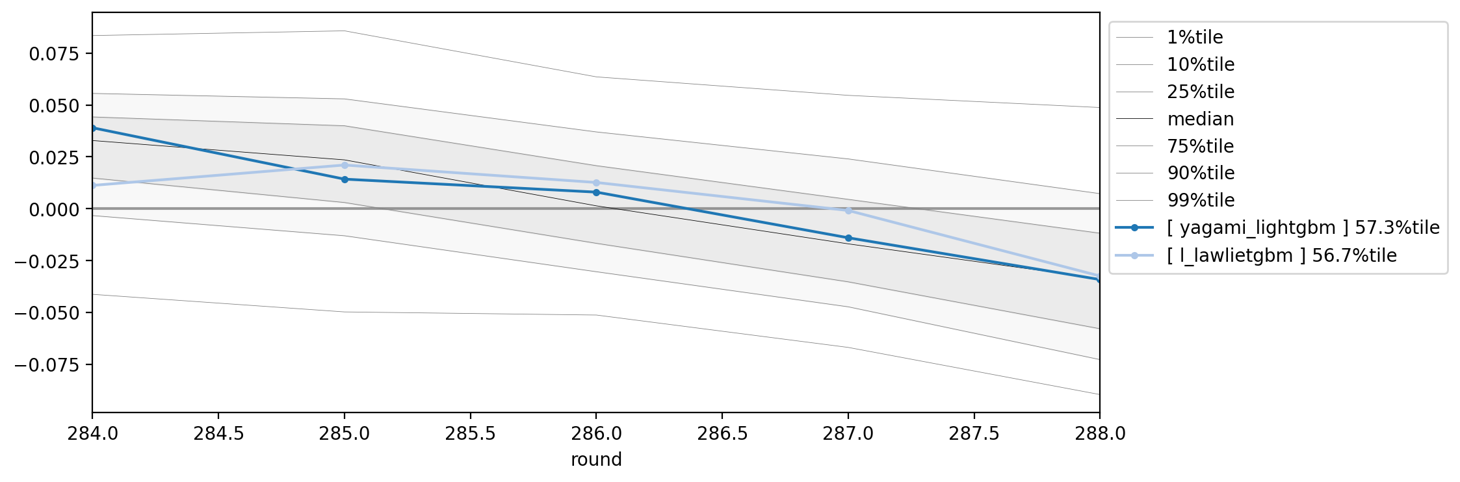
Round 284 ~ 288
そもそもモデル自体が調子悪いですが、これでヘッジできてるか結論づけるかは微妙な感じですね。
validationでもできそうですが、liveの結果が蓄積されたらPyPortfolioOptとか使うといいんですかね。
今後次第という感じです。
NNモデルの構築の方針
NNについてはsemi-supervisedの結果のように考察が難しく、NNの構築は時間がかかり難しそうです。
ただ、GBDT系がメジャーな以上はMMC・FNCを狙うモデルとしてNNは採用される可能性もあると思っています。
NNの構築自体に時間をかけたくなかったので、主にやらないことを中心にNNの構築方針を決めていました。
NNのみで高いcorrを狙わない
そもそも単体であればGBDTの方がパフォーマンス良いというのはありますが、Validationを構築してCorrを高くするように試行してもNNのパラメータ数的に過学習につながりやすいと考えてました。
なので、アンサンブルでMMC, FNCなどに少しでも寄与するモデルを構築することに焦点をあてています。
モデルサイズを小さくする
よほど大きなパフォーマンスの向上が見られない限り、サイズはミニマムにしたほうがいいと考えています。
もちろん過学習を防ぐという理由もありますが、それよりもパラメータを増やしたことによって学習が安定しないほうがきつい印象を個人的には持っています。
Forumを見たり実際に触った感じ、dropoutの寄与が高そうで、個人的にはdropoutによるサブネットワークのbagging効果が影響しているのかなと考えると、小さいモデルにしたほうがNN自体の検証はしやすいと思っています(これは完全に経験則なのであっているかはわかりません)。
パフォーマンスが良くなかったときに考察しにくい手法は検証しない
分析次第ではありますが、うまくいかなかったときにデータの考察につながりにくい手法はNNのせいにして悲しくなるだけなので検証しないようにしています。
基本、NNで検証する手法はデータ構造に基づくアーキテクチャの設計(アーキテクチャエンジニアリング)のみにしています。
損失関数の設計などもNNを採用する上での特徴として上げられますが、損失関数を変えると他のハイパーパラメータを再調整しないといけないので、自分は検証せずMSEのみ利用しています。
損失関数を検証するならNNの前に線形モデルで学習してみてもいいかもしれません。
とまあ、上記の方針を考えると「本当にNN必要か?」って話ですが、新データのexample predictionとNNをアンサンブルするとexampleに対してある程度オーバーパフォームしているのもあるので、悪くはないのかなと思っています。
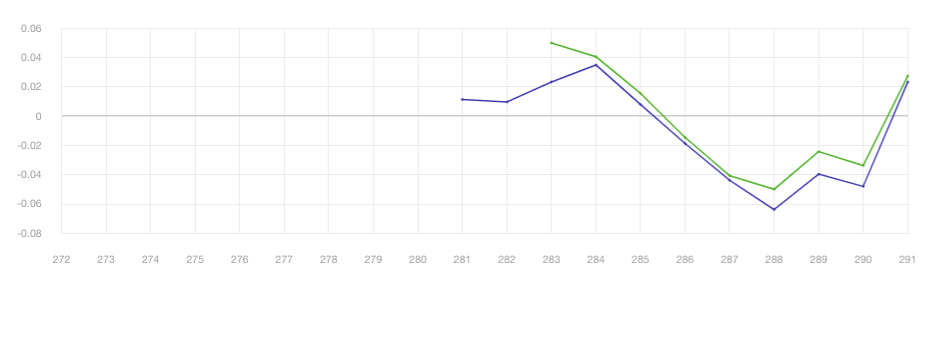
ちなみにDiganosticsは、(Corr, FNCが)なかなかひどいです。
終わりに
今思えば、特徴量選択がパフォーマンスに大きく寄与しそうなので、稼ぐという意味では遠回りなのかもしれませんね笑
ただ、Numeraiを通してモデリングとMLOpsの知見を得ることができて満足しています。
Numeraiは評価に時間がかかる分、短期的に時間を割かなくても楽しめるのはいいですね。
Discussion