分散トランザクションとsagaパターン(図解)
概要
複数のデプロイ単位が協調して動作するシステム(マイクロサービスアーキテクチャなど)において、DBの整合性を維持するための方法としてsagaパターンというものがあります。この記事ではsagaパターンが生まれるまでの流れと、sagaパターンの完璧ではないところを書いていきます。sagaパターンの中身は調べれば出てくると思うので簡単にしか書きません。
(ほとんど「マイクロサービスパターン 実践的システムデザインのためのコード解説:Chris Richardson 著/長尾高弘 訳/橂澤広亨 監修」の受け売りです)
システムを分割したい -> マイクロサービス
人々はモノリスに悩まされていました。モノリスとは1つのデプロイ単位に多大なすべての機能を詰め込んだシステムのことです。4,5人で作れる大きさならデプロイ単位は1つでいいのですが、100人くらいで1つのシステムを作るととても各エンジニアがすべてのコードを把握することはできません。しかし機能を追加するなら、自分が作成する機能に関連するコードは頭に入れないと関連する機能を壊すかもしれません。では関連するコードとはどれでしょうか?関連コードがいつくか見つかったとして、あなたが理解したコード以外に関連コードないと自信が持てるでしようか?
DBがボトルネックになるという問題もあります。なぜDBがボトルネックになるかはこの記事がとてもわかりやすかったです。
こうしてモノリスに悩まされる人々が採用したくなったのがマイクロサービスアーキテクチャです。マイクロサービスはサービスごとにデプロイ単位が分かれており、それぞれがアプリケーションサーバーとDBを持っています。このようにデプロイ単位を分けてしまうと、理解すべきコードの量がずいぶんマシになります。自分が開発しているデプロイ単位のコードと、関連するサービスのインタフェースだけわかればokです。DBも分散したので、連携する分コスパは悪くなりましたが、最大スペックは今までより上げやすくなりました。
DBの不整合
しかしここで新たな問題が発生します。DBを分けたことで、複数のDBを同時に書き換える作業がたまに必要になってしまいました。これの何が悪いかというと、書き換えられるDBを持つサービス群のうち、どれかが作業中に停止したらDBに不整合が出てしまいます。注文して決済サービスは決済に成功したけど、発送サービスが発送に失敗した場合、決済を元に戻せ、と再度命令しないと、商品は届かないのに注文者の残高が減ります。ちょっと許せませんね。

先にお伝えしておくと、この不整合を完璧に防ぐ方法はありません(技術が不足しているのか、原理的に無理なのかは知りません)。しかしエンジニアたちは不整合をなんとか軽減するための方法を考えます。
DBの不整合をなくしたい -> 2層コミットメント
まず生まれたのが2層コミットメントです。これはフェーズ1,2という2段階で他サービスのDBの変更を行うというものです。まずフェーズ1ですべてのサービスに対して、変更対象となるレコードやテーブルにDBロックをかけ、コミットする直前までの操作を行うよう命令します。フェーズ1が完了したらフェーズ2で実際にコミットを行います。もしいずれかのサービスでフェーズ1の操作が失敗したら、フェーズ2を行わず、DBの変更をやめます。イメージはこんな感じです。

詳細な解説はこの記事がわかりやすかったです。 これで不整合の問題はある程度解消されました。(調整者が死んだり、フェーズ2の途中で参加者が死んだりする場合は引き続き不整合が発生しえます)
可用性の低下
ここで大規模なトラフィックをさばきたいビッグサービスを運営している人々は考えます。
「可用性低いなあ」
可用性とは名前通り、システムが使える時間の割合です。可用性が99.9%だとしたら、1日あたり1.44分動かない時間があるかもね、ということです。1年で保証することが多いので、1年のうち9時間くらい動かない時間があっても許してね、となります。
2層コミットメントの話に戻ります。フェーズ1の時点で誰かが応答しなかったら、2層コミットメントは失敗です。可用性99.9%のサービスを10個呼び出す操作を行う場合、1回の操作が成功する確率は0.99^10=0.9900...≒99%です。通販サイトで商品を注文するとき、1/100の確率で購入が失敗するのは不愉快ですね。
シンプルに可用性99.9%だけ考えてもこの数字です。さらに困ったことに、2層コミットメントはDBにロックを作ります。並列に同じ操作を多数行ったら、最初の1つ以外はDBロックが存在する状態でフェーズ1を行います。その時の可用性はどれくらい落ちるでしょうか。99.0%になるのだとしたら、操作の成功率が90%くらいになってしまいます。注文が10回に1回失敗する通販サイトがもしあるなら、不愉快どころの話ではありません。
可用性を上げたい -> sagaパターン
こうして昔のエンジニアは可用性を上げたくなりました。そこで採用したくなったのがsagaパターンです。sagaパターンは必要な操作を順番に行い、もし失敗したらそれ以前に実行した処理の取り消し処理を行う、という方法です。sagaという名前の由来は、「この操作の冒険譚を聞かせよう、まずサービスAでAPI Aを呼び出し、サービスBでAPI Cを呼び出す、次に…」みたいなイメージでしょうか。
sagaパターンでは、失敗してから取り消し処理を完遂するまでの間、失敗より前に操作されたDBは不整合が起きている状態になりますが、結果的には整合性がとれるのでok、という考え方です。これを結果整合性を保つ、といいます。
(ちなみにこの取り消し処理のことを補償トランザクションといいます。)
sagaパターンでは操作を順番に行うため、それぞれのサービスが同時に生きている必要がなく、DBロックもトランザクションが終わるまで行う必要はありません。各サービスが自分のDBを操作している間だけでいいです。これによって可用性が上がりました。

結果整合性が破綻する場合
ここで新たな問題が起きます。結果整合性を重視したことで、途中の不整合が起きた状態を参照されたとき、不整合が波及していくという問題です。
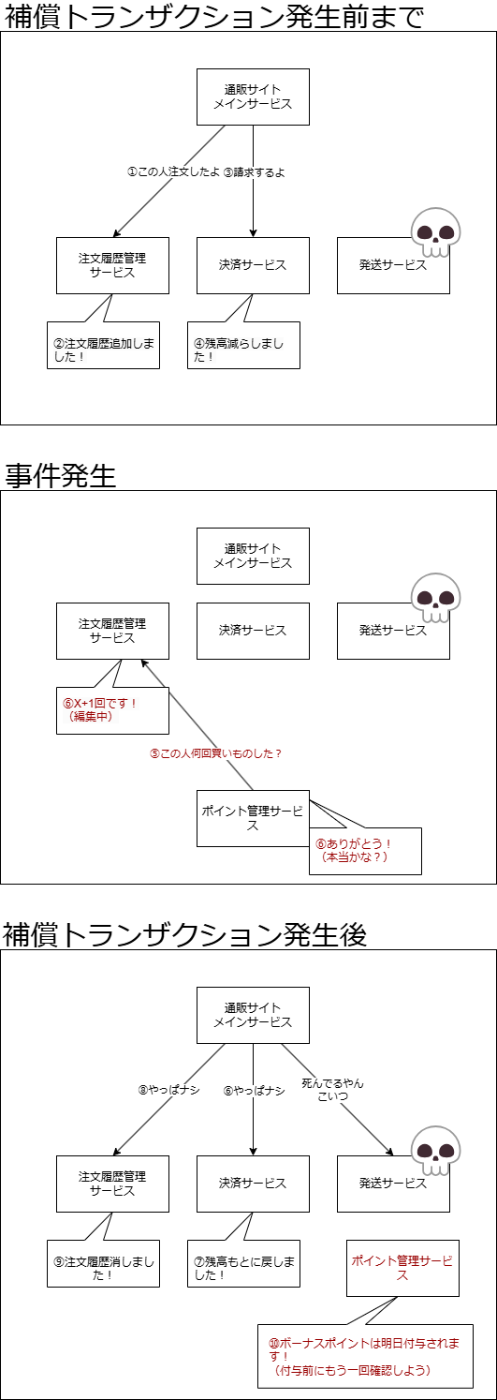
sagaパターンでは不整合が発生したら補償トランザクションを実行します。補償トランザクションが完遂されるまでは不整合が起きた状態のDBが存在しえます。では補償トランザクションが終わる前にそのレコードにアクセスされたらどうなるでしょうか?不整合状態のデータが読み取られ、何かに使われてしまいます。
たとえば通販サイトで、商品の購入時に発送サービスの実行が失敗し、ユーザーの購入履歴を削除する補償トランザクションが実行されるとします。しかし補償トランザクションが実行される前に、購入履歴が残った状態で買い物をされたとします。これだけならいいですが、◯天のように買い物をした店舗の数に応じてポイントを付与するといった場合、ポイントサービスが不正に購入数が多い状態を参照し、不当に多くポイントを獲得する人が生まれます。サイト運営からしたら困りますね。
このような不整合のことをダーティリードといいます。他にも更新の消失、ファジー・反復不能読み取りといった不具合も存在しますが、ここでは説明しません。

sagaパターンによる不整合の軽減
これを軽減するためにカウンターメジャー(countermeasure)が生まれました。"countermeasure"は「対策」「相殺のための方法」みたいな意味で、名前が具体的な方法を表しているわけではありません。
ここでは1つだけ例を紹介します。
semantic lock
さっきのポイントの例を考えます。ポイントを付与するとき、購入履歴を見てポイントの倍率を変える必要があるので、ポイントサービスは購入履歴サービスから購入履歴を取得します。この購入履歴が更新中だったのが悪かったのでした。
更新中であるとわかるようにすれば、対策のしようがありそうです。というわけで購入履歴に更新中フラグをつけてみましょう。
更新中フラグが立っているので、ポイントサービスは取得した購入履歴が正しくないかも?と疑うよう実装できます。ポイント計算時にこの購入数を使い、付与時に購入数が同じか確認するよう実装すれば、不整合中にポイントが付与される確率が減ります。
(更新中フラグが立っていたらポイント付与を失敗させてもいいですが、可用性は下がります。)
このような対策によって、不整合が発生する確率は多少下がるでしょう。しかしどの対策を行っても、理論的に不整合を完全に防げるというわけではなく、起きにくくする程度の効果しかありません。できればデータの更新は単一のデプロイ単位内で行い、複数システムのデータを更新する処理は最小限に、というかゼロにしたいところです。
参考資料
- マイクロサービスパターン 実践的システムデザインのためのコード解説:Chris Richardson 著/長尾高弘 訳/橂澤広亨 監修
- https://jp.quora.com/Web-sa-bisu-nioite-de-tabe-su-ga-botorunekku-ni-nari-gachi-na-riyuu-ha-nani-desu-ka
- https://ja.wikipedia.org/wiki/可用性
- https://zenn.dev/ryogo123/articles/426f697a8bb4e8
- https://qiita.com/yoshii0110/items/4ae10eb071565cb90b37
- https://scrapbox.io/showa-93/カウンターメジャー
Discussion