LiDARデータによる物体検出を試してみた-要約



はじめに
以下3つの記事の要約を示す。
Why
最近Unityをメインで使っていて、ROSに興味が出てきたので調べているとAutowareに行き着いた。
Autowareで実装されている点群からの3D物体認識が面白そうだったのでどのような技術があるのか調べて自分で動かしてみた。
そもそも点群データって
LiDARやステカメによる測距によって算出した3次元的な点情報のかたまり。
LiDARであれば3次元座標のほかに反射率、ステカメならRGB値が手に入ったりする。
※今回の記事の内容はあくまで点群からの物体検出に絞るので反射率やRGBの情報は使用しない

点群DNN
上記サイトを簡単にまとめる。
点群DNNは以下のような分類で進化してきた。
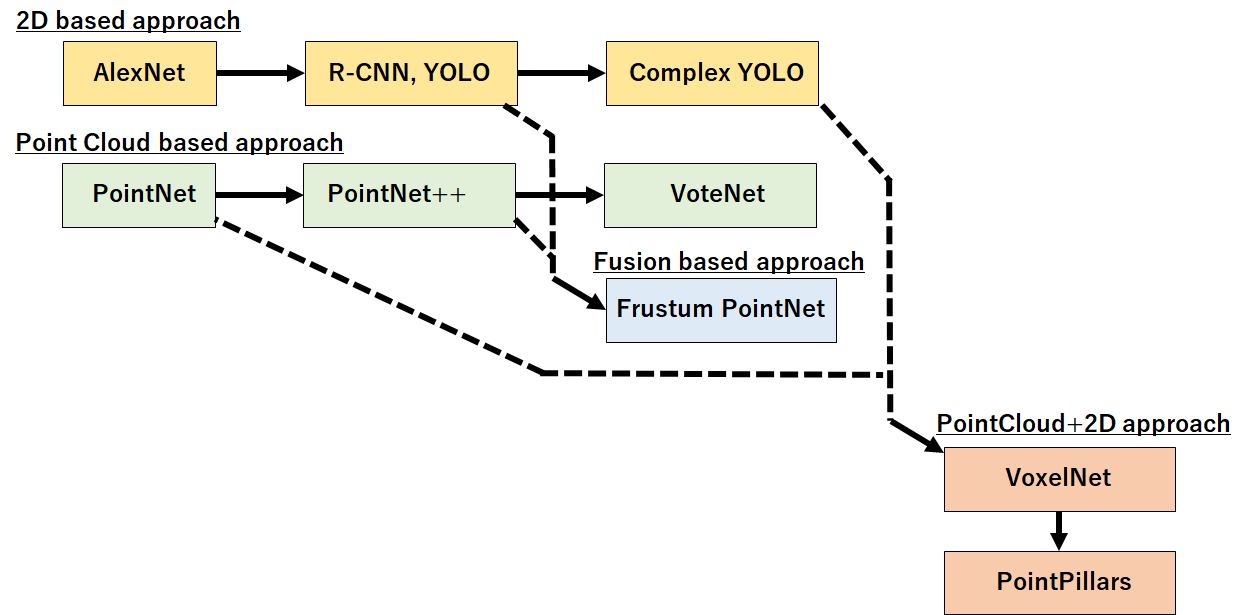
2Dベースアプローチ

YOLOなどの2D画像の物体検出タスクで培った技術を転用し、点群データを上空からの視点で見た2次元画像と見立てることで物体検出を行う手法
→既存のモデルを使えたり高速だが3次元的な情報が死ぬ
点群ベースアプローチ
点群に対してまとめてNNをかけていき最終的に特徴量へ変換する。
PointNetというモデルが有名で他のモデルの基礎になってる印象を受けた。

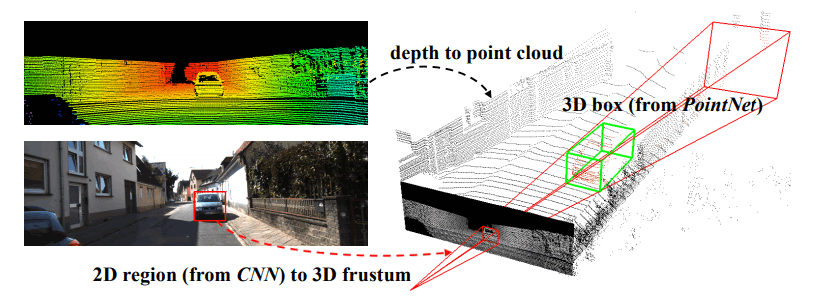
センサフィージョンベースアプローチ
カメラ映像から物体検出をかけて、そのあとで物体の存在しそうな領域に対して点群データを用いた検出を行う。
演算量が多いのが難点。
点群+2D CNNアプローチ
PointPillars
点群に対してPointNetベースのモデルを用い特徴量(疑似画像)へ変換する。変換したデータに対して2DCNN(SSD)をかけることで物体検出を行う手法
→Autowareでは類似アルゴリズムを実装しているらしいのでとりあえずPointPillarsを試してみた。

ちなみに現在最新のモデルは・・
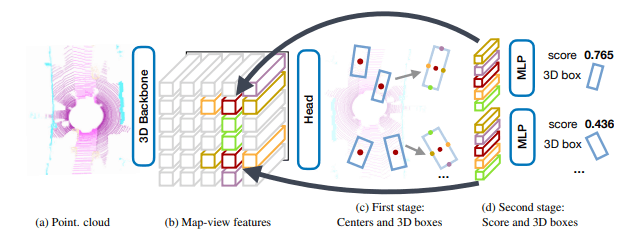
nuScenesというデータセットに対する上位モデルであるCenterPointの論文をかるーく読んでみた。
このモデルは大きく以下の3つのステップで動いているらしい
1.疑似画像特徴量変換(PointPillarsと同じアプローチ)
2.特徴量から物体の位置、高さ、サイズ、向きを推定する
3.下図(C) の5色の点のようにバウンディングボックスから5点分に対応する特徴量を抽出してさらに算出スコアと検出ボックスの調整をしている
また、このモデルではオブジェクトの速度推定も可能とのことで3Dトラッキングを可能としている。
PointPillars
実際に動かしてみた。
利用したデータセットはKittiというもの。

こんな感じの車にカメラやLiDARをくっつけて路上を走ったときのセンシングデータをフリーで提供している。(現在はよりデータの多いデータセットがあるらしいが手っ取り早いKittiを使った)
ちなみに座標系がUnityとは異なるので注意。詳しくはほかの記事からコードに飛ぶと変換をかけているのが分かると思う。
実行結果
鳥瞰視点

カメラ映像に重畳

テストデータ適合率
==========Overall==========
bbox_2d AP: 80.5103 74.5816 71.4745
AOS AP: 74.9297 68.1301 65.2554
bbox_bev AP: 77.8518 69.7950 66.6673
bbox_3d AP: 73.3250 62.7918 59.6403
大体73%の適合率で実際の動作画像もそこそこの精度で検出できていることがわかる。
また、今回はKittiの事前学習データを利用しているのでただcloneして適当にコマンドを打てばここまで試すことができる。
→画像の検出は手軽なイメージがあったが3Dでもある程度NNに理解があれば簡単に試せる
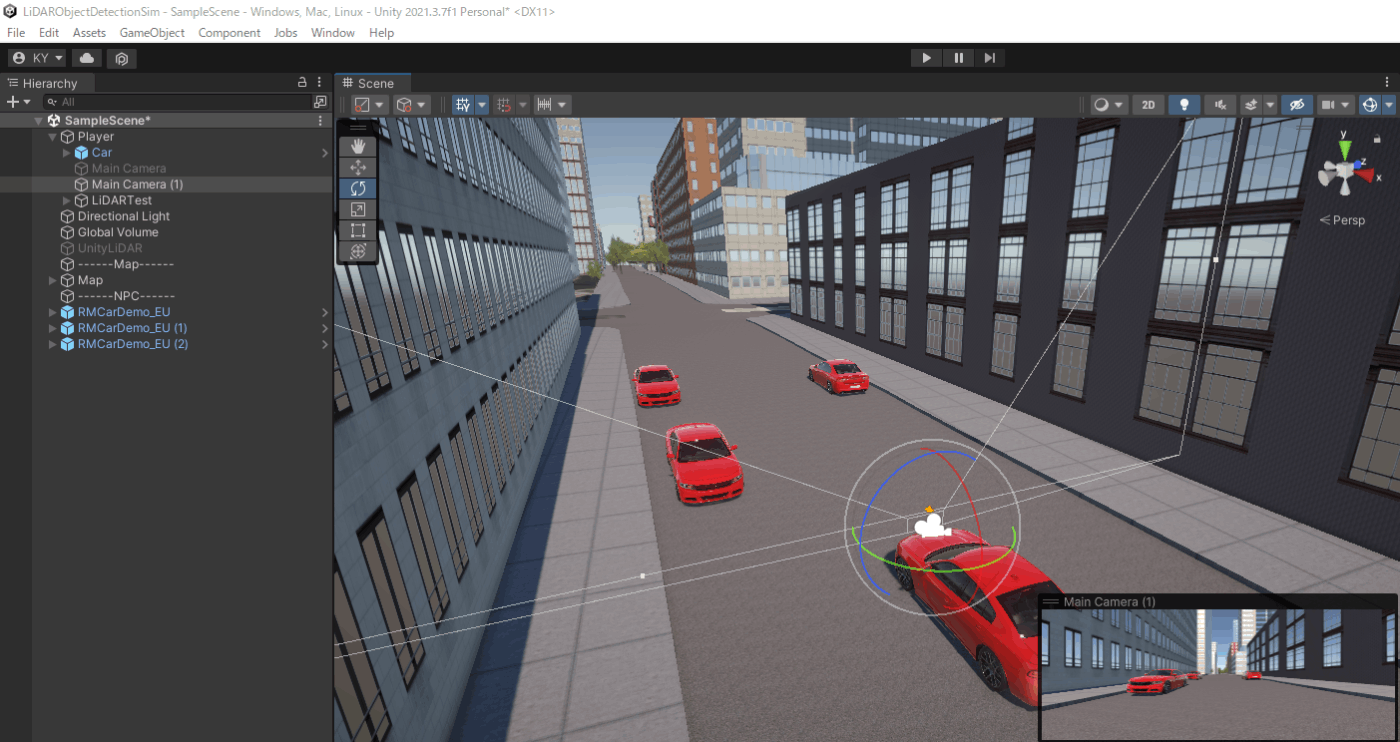
Unityの仮想LiDARデータを入力
結局のところデータセットのデータだけでは面白くないのでUnity上にLiDARっぽいものを実装して自作の点群データを作って入力してみた。
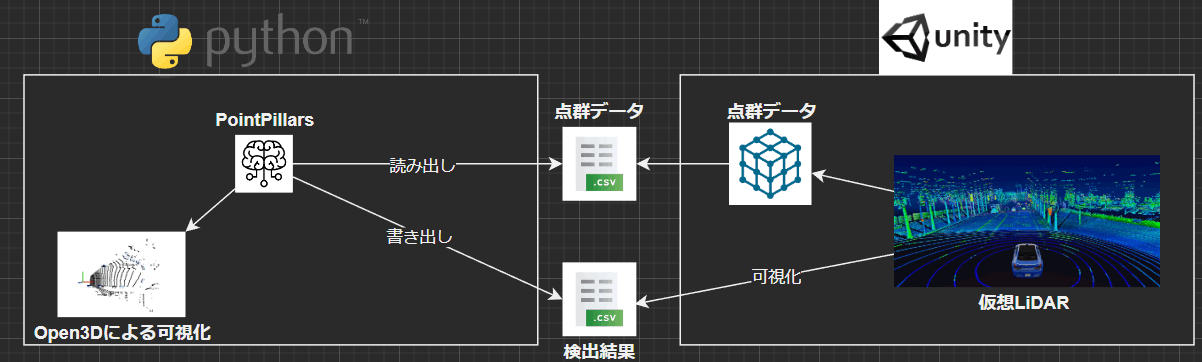
作ったマップはこちら
実行結果
鳥瞰視点
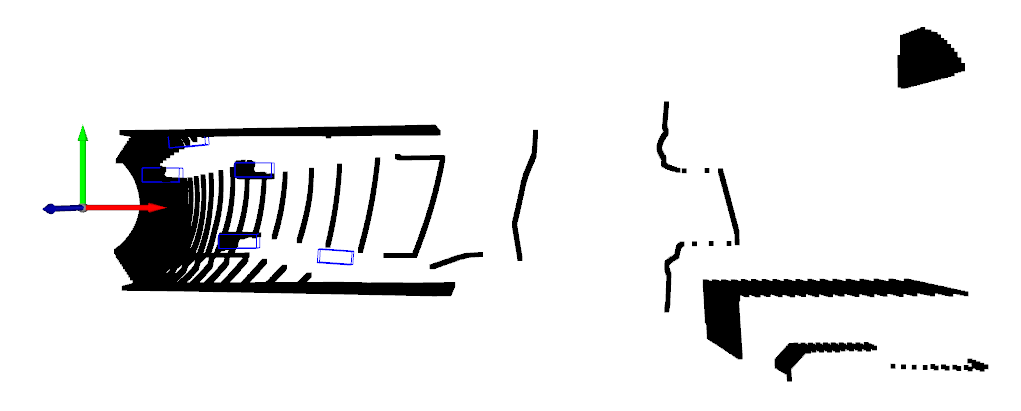
立体視点

カメラ映像に重畳

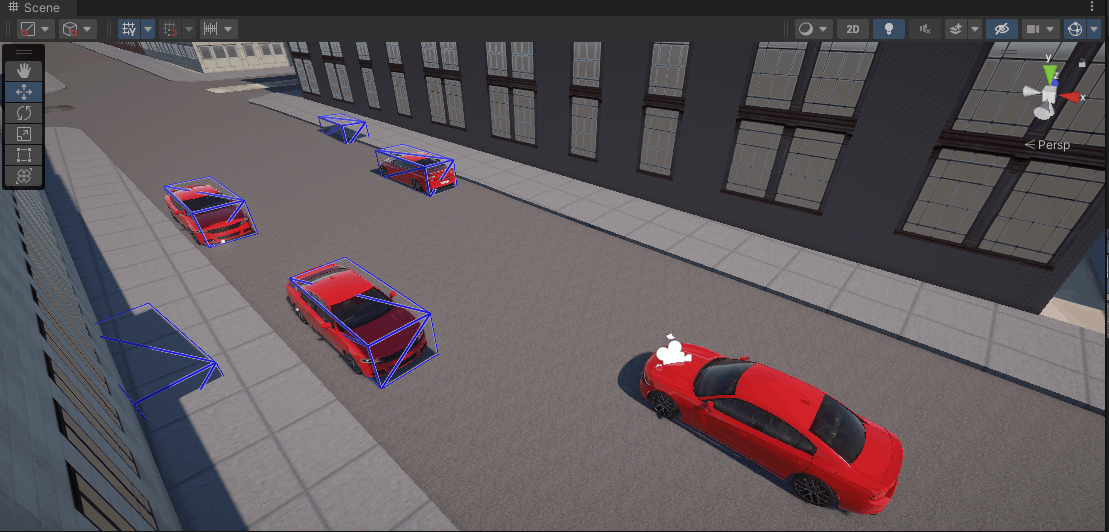
オブジェクトの検出自体は非常にうまく行っている。
ただし点群の穴が開いている区間で誤検出が目立つ
→Unity環境のデータだから起きているのか、そもそも傾向として誤検出の多いシチュエーションなのかもう少し見極める必要あり
※ただし点群の密集度などで閾を設ければ普通に使えそう
まとめ
- 点群DNNは様々なアプローチが存在し、現在も発展を続けている
- 画像の検出は手軽なイメージがあったが3Dでもある程度NNに理解があれば簡単に試せる
-
Unity環境のデータでも検出自体は問題なくできた
→ただし誤検出が目立つので改良は必要
記事の内容を追っていけばここまでの内容はトレースできるはずなので暇な人はぜひ。
Discussion
良くまとまっていて大変勉強になりました。この辺りの領域、大変興味があります。
Unityの仮想LiDARデータなど、簡単に実装されたように見受けられましたが、結構容易に実装できるものなのでしょうか。続編があればまた楽しみにお待ちしております。
コメントありがとうございます!
回答としては「点群データを作るだけ」なら割と簡単に実装が可能です。
Unityには特定の地点から任意方向に透明なレーザ光線のようなものを照射して衝突した地点を取得する機能があり、ほんの数行で記述できます。(正式名称はRayCastといいます)
今回はVelodyneのデータシートを参照し、分解能を合わせて上記のレーザを大量に照射することで本物のような点群データを生成しています。
ただし本手法で実装するだけではLiDAR特有の反射率の概念が全く含まれていないので現実とはどうしても差が生じているものと思います。(今回は反射率は特に不要だったので妥協しました)
上記を突き詰めたい場合には既にAutowareさんがオープンソースで提供されているUnity製のAWSIMというプロジェクトの参照をお勧めします。(以前展示会で直接うかがったのですがレイトレーシングという技術を用いて反射の概念を踏まえてLiDARを物理的にシミュレーションしているそうです)
以上、何か参考になりましたら幸いです。