モチベーション
長い文章を読むのは全く億劫だ。
頼むから知りたいところだけピンポイントに読ませてくれ。ファスト教養万歳!
そんな、働いていると本も読めなくなる[1]私たちの嘆きを解決してくれるのがLLMです。
文書の中から自分が必要としている文章のみをLLMに抽出してもらえば良いのです。
しかし、LLMに複数行の文章を出力させるには少々時間がかかりますし、その分API利用料金も発生します。
やはり、ファスト教養主義者としては、断固として更なる高速化を目指したい。
おまけに、うちの2歳児が豚こま肉を食べず豚バラばかり食べるため、食費で家計に困っており、月々のLLM利用料金ぐらいはお安く抑えたいところです。
そんなことを考えていた最中、日頃の活動を興味深く拝見している@hotchpotchさんが、fast-bunkaiという日本語の文境界判定器を発表されていました。こちらを活用させていただいて複数文章の文単位抽出の高速化を試みます。
LLMによる文単位抽出を高速化する方法
LLMを利用して、抽出元テキストから指示に対応する範囲の文章をそのまま文字列で出力させると、出力トークン量が多くなってしまい処理時間とコストを要します。
以下の方法でこの問題を解決します。

手順は以下の通りです。
- fast-bunkaiでソーステキストを文単位に分割
- 分割された文単位に昇順でidを付与する
- LLMにidと文単位のペアを渡して、指示文に対応する箇所をid範囲で指定させる
恐らく、同様の手法は色々なところで活用されていると想定されます。
例えば上記のブログでは、AnthropicのCitations(引用)機能を模した実装方法が提案されています。LLMの回答文中に引用を付与させるために、ユーザーのクエリと合わせて、引用元として参照させたい文書を文単位に分割して渡して、引用箇所の開始文と終了文の文番号の範囲を出力させる方法を提案しています。
参考: Anthropic Citationsとfast-bunkaiによる引用付与について
蛇足ですが、筆者にて日本語文書を用いてAnthropicのCitations機能を検証してみたことがあります。しかし、日本語文書では期待した通りには機能しませんでした。
AnthropicのCitations機能は、APIリクエスト時に参考文書を渡すと、これを適切な文脈単位に分割して、出力された回答の適した箇所に引用を付与します。しかし、筆者が検証した限りでは、この自動分割が日本語文書では上手く機能しないように見えました。(分割に関する詳細仕様の記述が見つけられず、私の利用方法が誤っていた可能性もあります。)
ところが、Citations機能にはCustom content documentsオプションがあります。これは、ユーザー側で分割した参考文書を配列で渡すことで、配列内の文単位で引用を付与させることができるものです。つまり、予めfast-bunkaiで文単位分割を行なった上で、Custom content documentsオプションを介してこの配列をClaudeのAPIに送り込むことで、日本語文書でもCitations機能を適切に利用することができそうです。
fast-bunkaiの文章分割ロジック
具体的な実装に入る前に、まずはfast-bunkaiの文章分割ロジックについて説明します。
fast-bunkaiは、句読点や改行を文境界として判定するのみではなく、顔文字や絵文字に対しても細かく文境界判定条件が実装されています。つまり、フォーマルな文書だけでなくチャットテキストにおける文単位分割においても十分に活用できる点が特徴的です。
fast-bunkaiはbunkaiの実装をベースに、コアロジックをRustで書き換えることによって、処理の高速化が行われたものです。PyO3を用いて実装されており、PythonのスクリプトからRustで記述された処理を呼び出すことができます。
該当の文境界判定ロジックはsrc/lib.rsに記載されています。
文章分割の条件
以下の条件によって、ソース文章が文単位に分割されます。
| 分割ルール名 | 条件 | 具体例 | 説明 |
|---|---|---|---|
| FaceMarkDetector | 顔文字で分割 |
(*^_^*) (^^) \(^^)/ など |
括弧で囲まれた顔文字パターン |
| EmotionExpressionAnnotator | 感情表現で分割 |
(笑) (泣) … ♪♪ など |
括弧内の感情語。♪♪ などの感情記号や …。 など感情記号の後に続く句読点まで。 |
| EmojiAnnotator | 特定カテゴリの絵文字で分割 | 😊 😢 ❤️ など |
Smileys & Emotion Symbols カテゴリのみ |
| BasicRule | 句点・疑問符・感嘆符で分割 |
。 ! ? ! ? . . およびそれらの連続 |
基本的な文末記号による分割。 [。!?.!?.]+\s* パターンに一致するもの。 |
| LinebreakForceAnnotator | 改行で分割 |
\n \n\n など |
改行部分での分割。[\n\s]*\n[\n\s]* パターンに一致するもの。 |
例外条件
文中に分割条件に当たる記号や絵文字等が含まれる場合であっても、以下のようなケースにおいては分割せず一文として扱った方が良いため、例外条件が実装されています。
| 例外ルール名 | 条件 | 具体例 | 説明 |
|---|---|---|---|
| IndirectQuoteExceptionAnnotator | 特定助詞が後続する場合 |
スタッフ? と話し込み。 ちょっと風邪症状😢もあります。
|
「と」「て」「の」「って」「という」「に」「など」の単体助詞、または「くらいの」「くらいです」「くらいでし」「もあり」「ほどでし」の複合パターンが続く場合 |
| DotExceptionAnnotator | 数値の小数点、メールアドレスのドット |
3.14 1.5 user.name@example.com
|
前後が数字の場合、前後が英数字の場合 |
| NumberExceptionAnnotator | 番号表記 |
No.1 NO.10
|
「No.」「NO.」の後に数字が続く |
fast-bunkaiの実行例
from fast_bunkai import FastBunkai
splitter = FastBunkai()
text = "羽田から✈️出発して、友だちと🍣食べました。最高!また行きたいな😂でも、予算は大丈夫かな…?"
for sentence in splitter(text):
print(sentence)
出力結果は以下の通りです。
羽田から✈️出発して、友だちと🍣食べました。
最高!
また行きたいな😂
でも、予算は大丈夫かな…?
実装 -文章id範囲抽出器の実装-
それでは、LLMを用いた文単位抽出の具体的な実装を行います。
今回は、抽出元のテキストに契約書を用いることとします。
実装および検証のコードは以下のリポジトリにcommitしています。
改めて手法を説明します。
初めに、fast-bunkaiを利用して文書を文単位分割し、分割された文章ごとに0から順に昇順でidを付与します。続いて、idと文章のペアをLLMに渡して、指示文と対応する範囲のidを出力させます。最終的にLLMが出力したid範囲のテキストを抽出結果として返します。
idと文章のペアについては、以下の通りmarkdown-KV[2]のような形式でプロンプトに記載します。
0: 第 5 条(有効期間)
1: 1 .本契約の有効期間は、令和5年1月1日から令和6年12月31日までとする。
2: 2 .本契約の期間満了の●か月前までに、いずれの本契約当事者からも書面による何らの意思表示もない場合、本契約は同じ条件でさらに1年間延長されるものとし、以降も同様とする。
3: \n\n
4: 第 6 条(再委託の禁止)
5: 1 .乙は、甲の事前の書面による承諾なく、本件委託業務の全部又は一部を第三者に再委託することはできない。
抽出の指示文については、プロンプト内に以下のようなJSONを渡して、複数の指示を実行できるようにします。
[
{
"extraction_id": 0,
"instruction": "契約書の有効期限"
},
{
"extraction_id": 1,
"instruction": "再委託可否"
}
]
出力は以下のJSON形式にて、指示ごとに該当範囲のidを指定させます。
{
"extractions": [
{
"extraction_id": 0,
"sentence_spans": [
{
"start": 11,
"end": 21
}
]
},
{
"extraction_id": 1,
"sentence_spans": [
{
"start": 47,
"end": 60
}
]
}
]
}
プロンプト全文は以下の通りです。
プロンプト
import textwrap
PROMPT = textwrap.dedent(
"""
# タスク概要
以下に与えられる抽出ポイントに対応するように、「契約書テキスト」から該当箇所の文章を抽出してください。
ただし、ソーステキストには行ごとにindexが付与されていますので、開始のindexと終了のindexを指定して抽出してください。
<EXAMPLES>
# 例
## 例1
契約書テキスト:
0: 第 5 条(有効期間)
1: 1 .本契約の有効期間は、令和5年1月1日から令和6年12月31日までとする。
2: 2 .本契約の期間満了の●か月前までに、いずれの本契約当事者からも書面による何らの意思表示もない場合、本契約は同じ条件でさらに1年間延長されるものとし、以降も同様とする。
3: \n\n
4: 第 7 条(再委託の禁止)
5: 1 .乙は、甲の事前の書面による承諾なく、本件委託業務の全部又は一部を第三者に再委託することはできない。
抽出ポイント: [
{{
"extraction_id": 1,
"instruction": "契約書の有効期限"
}},
{{
"extraction_id": 2,
"instruction": "再委託可否"
}}
]
出力: {{
"extractions": [
{{
"extraction_id": 1,
"sentence_spans": [
{{
"start": 0,
"end": 1
}}
]
}},
{{
"extraction_id": 2,
"sentence_spans": [
{{
"start": 4,
"end": 5
}}
]
}}
]
}}
</EXAMPLES>
# 入力
契約書テキスト:
{contract_text}
抽出ポイント: {extraction_instructions}
# 注意事項
* 基本的には "第x条" のような条文番号の記載がある行から start indexを始めて、条文全体を end indexまで含める形で抽出してください。
"""
)
また上記のプロンプトを用いた抽出処理については以下の通りに実装しました。
SentenceSpanPickerの実装
import json
from dataclasses import dataclass
from fast_bunkai import FastBunkai
from openai import OpenAI
@dataclass
class Sentence:
text: str
start: int
end: int
@dataclass
class Extraction:
extraction_id: int
instruction: str
sentences: list[Sentence]
@dataclass
class UsedTokens:
prompt_tokens: int
completion_tokens: int
total_tokens: int
@dataclass
class Response:
extractions: list[Extraction]
used_tokens: UsedTokens
class SentenceSpanPicker:
MODEL = "gpt-4.1-mini"
def __init__(self) -> None:
self.client = OpenAI()
self.splitter = FastBunkai()
def _bunkai_text(self, text: str) -> list[str]:
return [sentence for sentence in self.splitter(text)]
def _generate_lines_with_id(self, splitted_lines: list[str]) -> str:
lines_with_id = []
for i, line in enumerate(splitted_lines):
lines_with_id.append(f"{i}: {line}")
return "\n".join(lines_with_id)
def _genereate_extraction_instructions_with_id(self, extraction_instructions: list[str]) -> str:
return str(
[
{"extraction_id": i, "instruction": instruction}
for i, instruction in enumerate(extraction_instructions)
]
)
def _request_to_llm_service(self, prompt: str) -> tuple[str, dict]:
completion = self.client.chat.completions.create(
model=self.MODEL,
messages=[
{
"role": "user",
"content": prompt
}
]
)
res_content = completion.choices[0].message.content
used_tokens = {
"prompt_tokens": completion.usage.prompt_tokens,
"completion_tokens": completion.usage.completion_tokens,
"total_tokens": completion.usage.total_tokens,
}
return res_content, used_tokens
def _generate_response(
self,
splitted_lines: list[str],
extraction_instructions: list[str],
res_content: str,
used_tokens: dict) -> Response:
res_body = json.loads(res_content)
extractions = []
for extraction in res_body["extractions"]:
sentences = []
for sentence in extraction["sentence_spans"]:
start_idx = sentence["start"]
end_idx = sentence["end"]
# 末尾の空行(改行のみの行)をスキップしてend indexを調整
while end_idx >= start_idx and splitted_lines[end_idx].strip() == '':
end_idx -= 1
# テキストを結合
text = "".join(splitted_lines[start_idx:end_idx + 1])
# 念のため末尾の\nを全て削除
text = text.rstrip('\n')
sentences.append(
Sentence(
text=text,
start=start_idx,
end=end_idx,
)
)
extractions.append(
Extraction(
extraction_id=extraction["extraction_id"],
instruction=extraction_instructions[extraction["extraction_id"]],
sentences=sentences
)
)
return Response(
extractions=extractions,
used_tokens=UsedTokens(
prompt_tokens=used_tokens["prompt_tokens"],
completion_tokens=used_tokens["completion_tokens"],
total_tokens=used_tokens["total_tokens"],
)
)
def run(
self, contract_text: str, extraction_instructions: list[str]) -> Response:
splitted_lines = self._bunkai_text(contract_text)
lines_with_id = self._generate_lines_with_id(splitted_lines)
extraction_instructions_with_id: str = self._genereate_extraction_instructions_with_id(extraction_instructions)
prompt = PROMPT.format(
contract_text=lines_with_id,
extraction_instructions=extraction_instructions_with_id
)
res_content, used_tokens = self._request_to_llm_service(prompt)
return self._generate_response(splitted_lines, extraction_instructions, res_content, used_tokens)
検証 -文章id範囲抽出 vs 直接抽出-
前章で実装した、文章id範囲抽出の有効性を証明するため、以下2つの手法を比較検証します。
| No | 抽出方法名 | クラス名 | 説明 |
|---|---|---|---|
| 1 | 文章id範囲抽出 | SentenceSpanPicker | 抽出対象の文章のid範囲を出力させる手法 |
| 2 | 直接抽出 | DirectPicker | 抽出対象の文章をそのまま出力させる手法 |
検証条件は以下の通りです。
| No | 項目名 | 説明 |
|---|---|---|
| 1 | 利用モデル | GPT-4.1 mini |
| 2 | ソーステキスト | 3,000文字程度の業務委託契約書 |
| 3 | 抽出項目 | "受託者の責務" "秘密保持条項" "反社条項" の3つ |
比較検証はこちらのnotebookにて行いました。
文章id範囲抽出については、上述した構造にて以下のようなシンプルなJSONがLLMから返ります。
文章id範囲抽出 LLMレスポンス
{
"extractions": [
{
"extraction_id": 0,
"sentence_spans": [
{
"start": 11,
"end": 21
}
]
},
{
"extraction_id": 1,
"sentence_spans": [
{
"start": 47,
"end": 60
}
]
},
{
"extraction_id": 2,
"sentence_spans": [
{
"start": 78,
"end": 88
}
]
}
]
}
方や、直接抽出については該当範囲の文章をそのまま出力させるため、文字数の多いJSONがLLMから返ります。
直接抽出 LLMレスポンス
{
"extractions": [
{
"extraction_id": 0,
"sentences": [
{
"text": "第2条(受託者の責務)\n1. 受託者は、委託業務を善良な管理者の注意義務をもって実施するものとする。\n2.
受託者は、委託者より要請があった場合、委託業務の進捗状況その他委託者が\n
報告を要求する事項について、速やかに委託者へ報告を行わなければならない。\n3.
受託者が委託業務に関連して作成または取得した帳簿、台帳、報告書等の資料に\n
関する所有権はすべて委託者に帰属するものとし、委託業務実施の過程において\n
生じる発明、考案に関わる知的財産権を受ける権利およびこれに基づき取得される\n 知的財産権は委託者に帰属するものとする。"
}
]
},
{
"extraction_id": 1,
"sentences": [
{
"text": "第8条(秘密保持)\n1.
委託者および受託者は、本契約締結の事実、および本契約に関連してまたは委託業務実施上知り得た相手方の技術上、営業上その他の情報で相
手方が秘密と指定\n
したもの(以下「秘密情報」という。)を、相手方の事前の書面による同意を得ることなく第三者へ開示・漏洩してはならず、本契約の履行以外
の目的\n に使用してはならない。ただし、次の各号のいずれかに該当するものについては、この限りでない。\n\n (1)
開示を受けた時点で、すでに自己が保有していた情報\n (2) 開示を受けた時点で、すでに公知となっていた情報\n (3)
開示を受けた後、自己の責めによらず公知となった情報\n (4) 法令の規定に基づき官公庁から開示を強制されたもの\n\n2.
前項の義務は、本契約期間中に限らず、本契約終了後5年間存続する\n ものとする。"
}
]
},
{
"extraction_id": 2,
"sentences": [
{
"text": "第11条(反社会的勢力の排除)\n1.
委託者および受託者は、それぞれ、自己および自己の役員ならびに委託業務に従事する者が、暴力団、暴力団員、暴力団員でなくなった時から
5年を経過しない者、暴力団準構成員、暴力団関係企業、総会屋、社会運動等標ぼうゴロ、特殊知能暴力集団またはその他これらに準ずる者(以
下「反社会的勢力」という。)に該当しないことを表明および保証する。\n2.
委託者および受託者は、自らまたは第三者を利用して、相手方に対する脅迫的な言動または暴力を用いる行為、および威力・偽計により相手方
の業務を妨害する行為をしてはならない。\n3.
委託者および受託者は、相手方が前各項に違反した場合、相手方に対して何らの催告をすることなく直ちに本契約を解除することができる。こ
の場合であっても、相手方に対する損害賠償請求を妨げない。\n4.
前項の規定に基づき解除がなされた場合、解除をした当事者は、相手方に対して、解除により生じる一切の損害について賠償する責任を負わな
い。"
}
]
}
]
}
抽出結果比較
本検証ではソースの業務委託契約書から3つの項目(3条文)を抽出しました。

抽出箇所は2つの手法で完全に一致しました。
因みに、今回の検証により、抽出対象となった3条文の文字数は計1,090文字となります。
処理時間比較
処理時間の比較は以下の通りです。
5回連続して抽出処理を行い平均を取得しています。
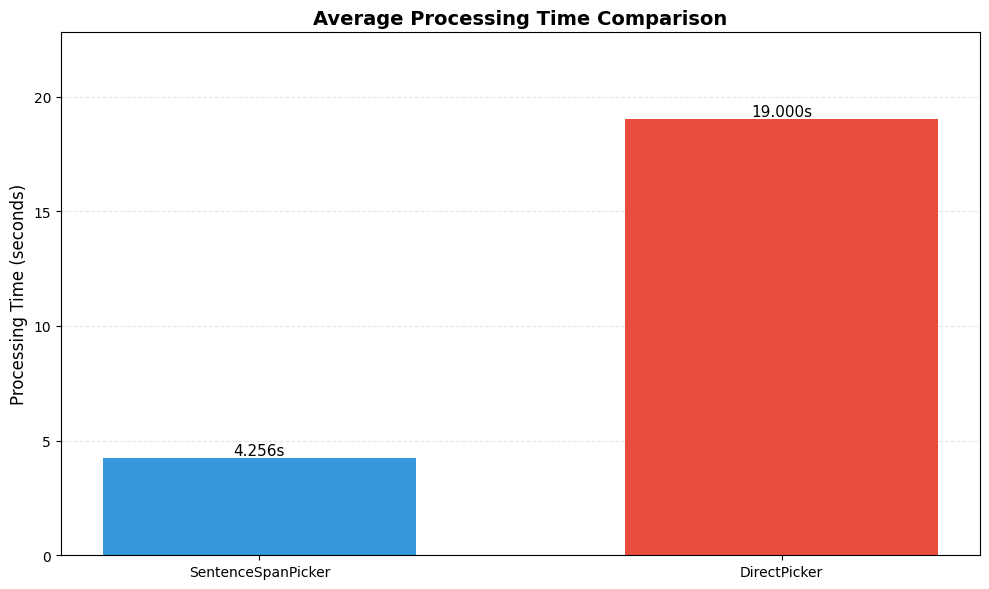
表から分かる通り、文章id範囲抽出(SentenceSpanPicker)は、直接抽出(DirectPicker)と比較して大幅に処理時間を削減できています。
文章id範囲抽出の処理時間には、fast-bunkaiによる抽出元テキスト分割の処理時間も含まれています。
出力トークン量の比較
出力トークン量の比較は以下の通りです。
こちらも狙い通り大幅な低減が実現できています。

まとめ
文章id範囲抽出によって、ファスト教養主義者の私も満足な文単位抽出の高速化を実現することができました。
出力トークン量の低減によるコストも削減できたので、家計も安心できる状況になりました。今日はよく食べる子供のためにミスタードーナツを買って帰ろうかなと思っています。
ところで、弊社AIチームでは Python および Rust を利用して、AI・LLMを活用した法務部門向けのサービスを開発しています。興味がありましたら是非一緒にお仕事しましょう!

Discussion