google/LangExtractとは
LangExtractは2025年7月にGoogleが発表したLLMを用いた項目抽出ライブラリです。
LangExtractは単なる項目抽出ができるに留まらず、抽出した項目が抽出元テキストのどの位置に存在しているかを特定する機能を有している点が特徴的です。
LLMを活用した項目抽出における難点として、元のテキストに忠実な抽出結果が得られない場合があることが挙げられます。以下のように、極端な例ではありますが、抽出項目のテキストと原文が部分的に異なるような揺れが発生するケースがあります。
## 抽出元テキスト(原文)
The Contractor shall provide all necessary services and deliverables
as outlined in Appendix A within the agreed timeframe.
## 抽出項目
Contractor must provide necessary services and deliverables
("shall" → "must" の言い換え、"all" の欠落)
LangExtractでは、このような表記揺れが発生していても、なるべく位置特定ができるように、ファジーマッチングも活用して位置取得を試みるロジックが実装されています。
LLMを用いたシステムを作る際、ユーザーに提示する回答の根拠となる箇所を文書内でハイライトしたいケースも多いかと思います。 このようなニーズに対して、LangExtract にて実装されている抽出項目の文書内位置特定ロジックが参考になるものでしたので、これについて本稿では深掘りします。
抽出項目の文書内位置特定機能
上述の通り、LangExtractでは抽出項目の文書内位置を特定する機能が搭載されています。
位置特定ロジックによって、抽出項目の文書内位置が特定された場合には、抽出元の文書内における開始点start_pos と終了点 end_pos が出力されます。この2点を用いて、位置をHTMLで分かりやすくビジュアライズする機能まで付属しています。
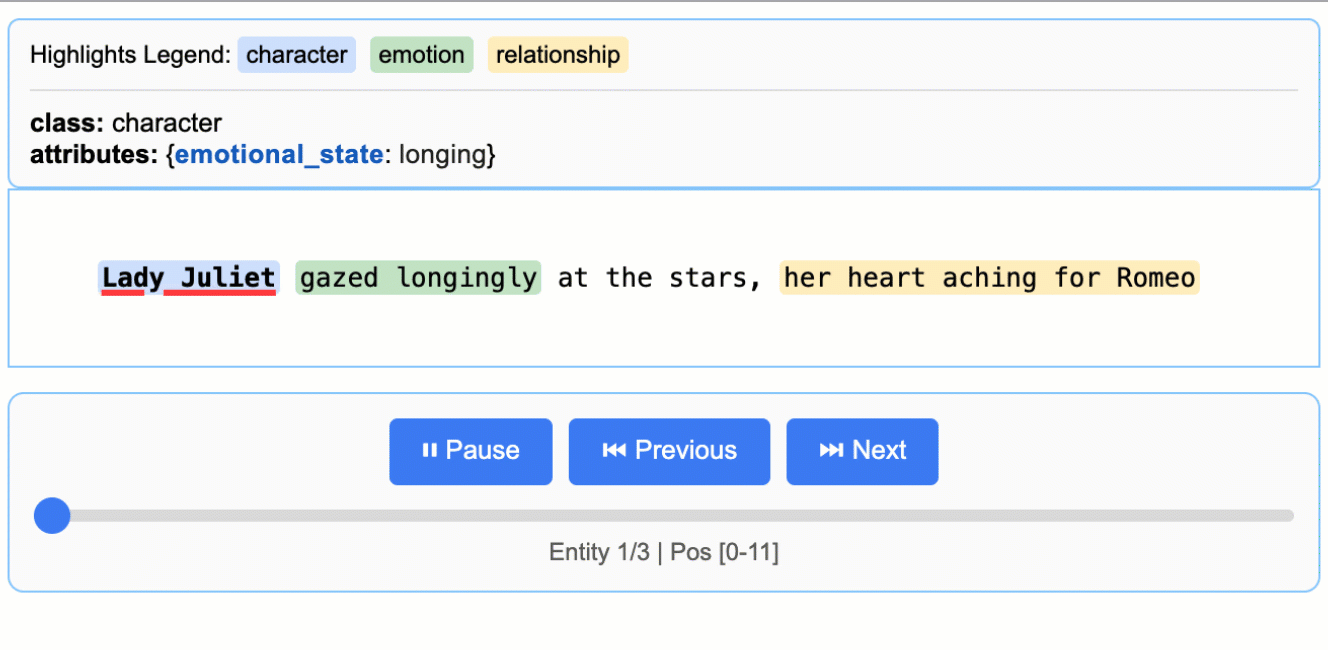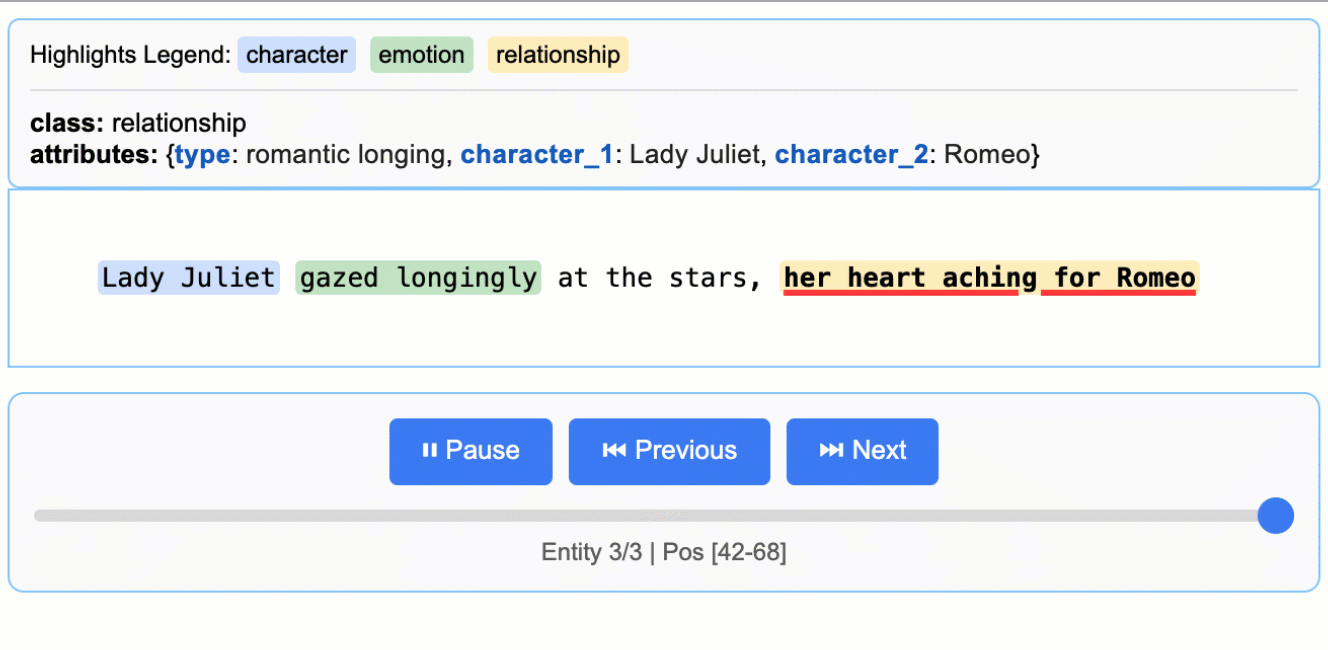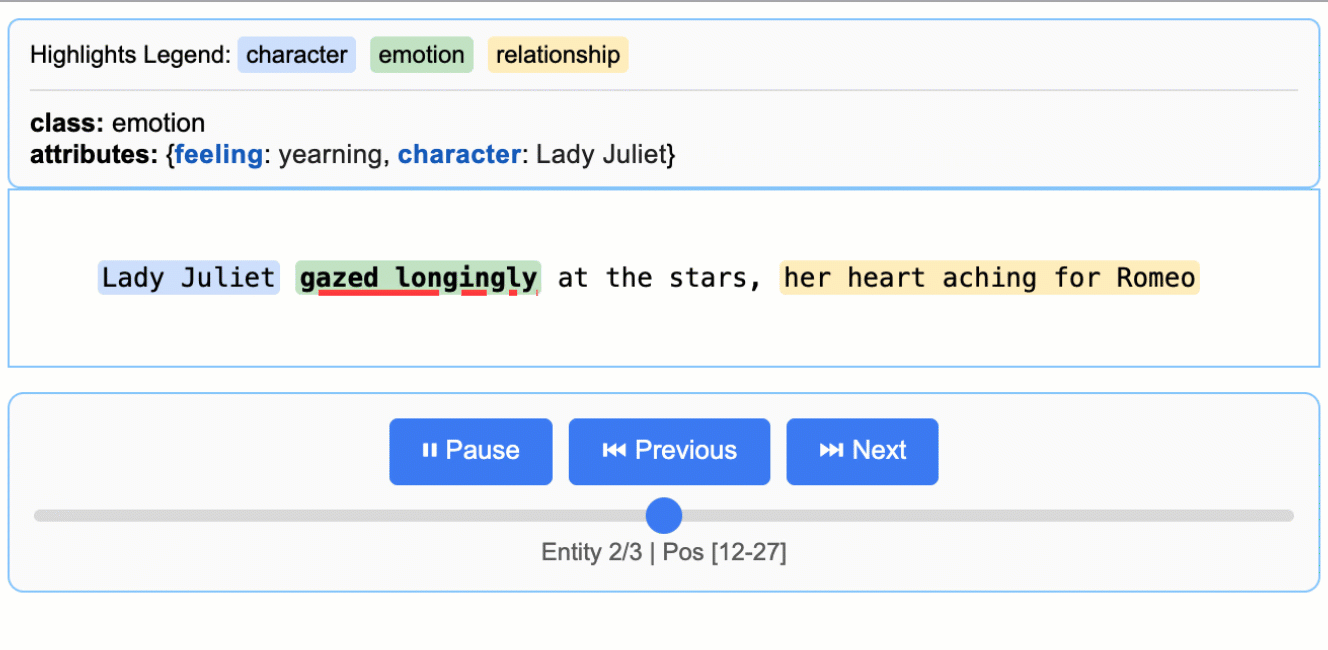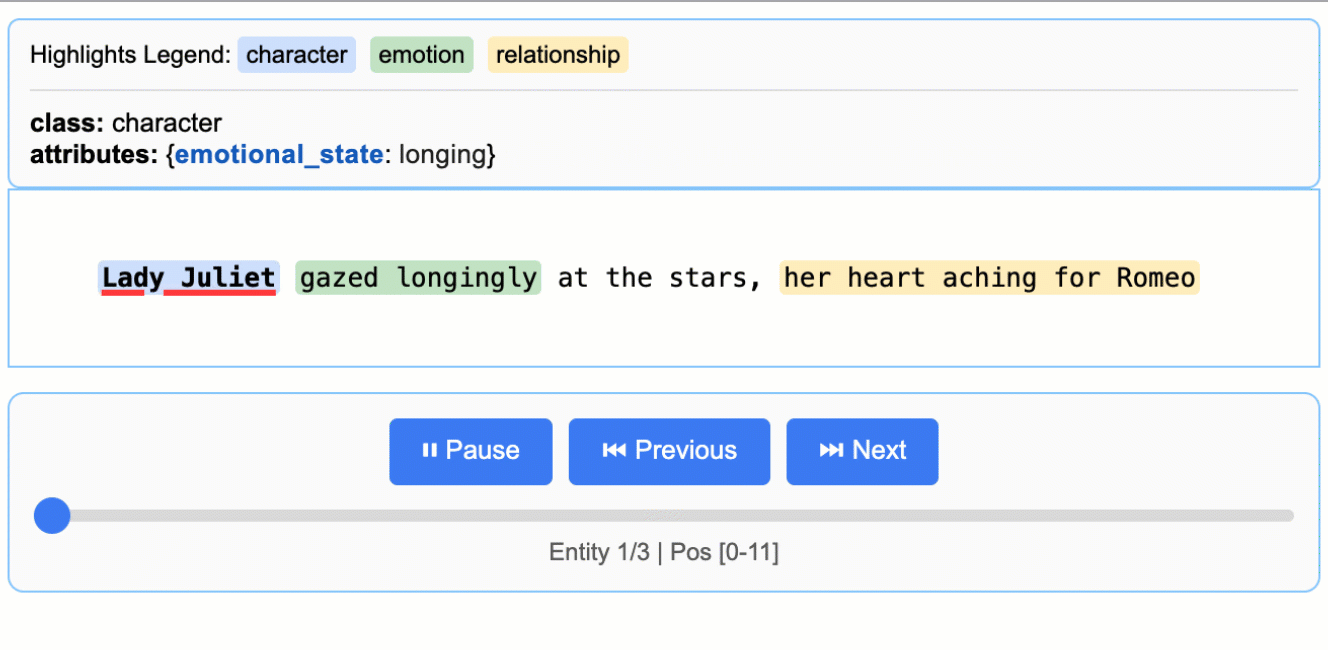
https://github.com/google/langextract/tree/6e36c378994121c2b8d9a25b32cff149d9bfc61c より画像引用
使い方
ロジックについて説明する前に、公式のTutorialに沿ってLangExtractの使い方を簡単に説明します。
1. 抽出プロンプトを定義
LLMに対して、抽出タスクを指示するためのプロンプトを定義します。
import textwrap
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
2. Few-shotのためのデータ定義
Few-shot promptingを行うためのデータ定義を行います。(以下はOne-shotとなっています。)
import langextract as lx
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
3. 抽出実行
最後に実際のソース文書を定義して lx.extract に、先ほど定義したプロンプトやFew-shotのためのexamplesを渡します。これにより抽出処理がLLMに発行されます。LLMから抽出結果が返ってきた後、文書内の位置特定ロジックが走ります。
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
参考までに実際に出力された内容を以下に添付します。各種項目が抽出されており、抽出元テキスト内における位置についても char_interval に格納されています。
出力結果
AnnotatedDocument(
extractions=[
Extraction(
extraction_class="character",
extraction_text="Lady Juliet",
char_interval=CharInterval(start_pos=0, end_pos=11),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=1,
group_index=0,
description=None,
attributes={"emotional_state": "longing"},
),
Extraction(
extraction_class="emotion",
extraction_text="longingly",
char_interval=CharInterval(start_pos=18, end_pos=27),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=2,
group_index=1,
description=None,
attributes={"feeling": "yearning"},
),
Extraction(
extraction_class="emotion",
extraction_text="her heart aching",
char_interval=CharInterval(start_pos=42, end_pos=58),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=3,
group_index=2,
description=None,
attributes={"feeling": "sorrowful pain"},
),
Extraction(
extraction_class="relationship",
extraction_text="for Romeo",
char_interval=CharInterval(start_pos=59, end_pos=68),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=4,
group_index=3,
description=None,
attributes={"type": "romantic affection"},
),
],
text="Lady Juliet gazed longingly at the stars, her heart aching for Romeo",
)
抽出項目の位置特定ロジック
LangExtractでは、以下のステップによって抽出項目の文書内の位置特定が行われます。
- LLMによる項目抽出
- トークン分割
- 位置特定ロジック1(複数項目まとめて位置特定)
- 位置特定ロジック2(残項目ごとにファジーマッチングでフォールバック)
トークン分割についてはソースコードの langextract/core/tokenizer.py にて、 位置特定ロジックについては langextract/resolver.py にて実装されており、以降の説明はこれらのソースコードを踏まえた内容となっています。
1. LLMによる項目抽出
初めにLLMによる項目抽出が行われます。
上記の「使い方」で記載した通り、事前に定義した指示プロンプト、抽出元となる文章、Few-shotのためのデータが、1つのプロンプトとして組み立てられてLLMにリクエストされます。
参考までに、上述のTutorialを実行した際に、LLMにリクエストされたプロンプトを添付します。
プロンプト全文
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.
Examples
Q: ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.
A: {
"extractions": [
{
"character": "ROMEO",
"character_attributes": {
"emotional_state": "wonder"
}
},
{
"emotion": "But soft!",
"emotion_attributes": {
"feeling": "gentle awe"
}
},
{
"relationship": "Juliet is the sun",
"relationship_attributes": {
"type": "metaphor"
}
}
]
}
Q: Lady Juliet gazed longingly at the stars, her heart aching for Romeo
A:
2. トークン分割
続いて、抽出元の文章および抽出されたテキストを、それぞれ同一のロジックでトークン単位に分割していきます。
トークン分割のロジックは非常にシンプルで、以下4つの正規表現のいずれかに一致したものをトークンとして分割していきます。
| no | トークンカテゴリ名 | パターン | 値の例 |
|---|---|---|---|
| 1 | WORD(単語) | [A-Za-z]+ |
Hello, world
|
| 2 | NUMBER(数値) | [0-9]+ |
123, 2024, 42
|
| 3 | ACRONYM(略語/スラッシュ区切り) | [A-Za-z0-9]+(?:/[A-Za-z0-9]+)+ |
TCP/IP, HTML/CSS, 24/7, and/or
|
| 4 | PUNCTUATION(句読点・記号) | [^A-Za-z0-9\s]+ |
., ,,, !?, ..., ---
|
以下のようなイメージです。

因みに、「こんにちは、私はロボットです。」などの日本語テキストは、上記の正規表現と照合すると こんにちは、私はロボットです。 がそのまま非ASCII文字の連続として PUNCTUATION に分類され、1トークン扱いされてしまいます。これにより、ユースケースによっては日本語文書に対して適切に位置特定の対応ができません。本稿の後半では、トークナイザーの日本語対応を試みます。
3. 位置特定ロジック1 (複数項目まとめて位置特定)
抽出元のテキストおよび抽出されたテキストのトークン分割が行われた後、位置特定ロジックが実行されます。
初めに実行される位置特定ロジック1では、抽出元テキストから複数の抽出項目の位置をまとめて取得する効率的な演算が実行されます。
先ずは、抽出項目ごとのトークン配列を、セパレータを介して1つの配列として結合します。
因みに、セパレータには \u241F という、データセパレーションのために用意されている制御文字が利用されています。Unit SeparatorというUnicode文字のため、以下画像では us と表現します。

その後、抽出元テキストのトークン配列と、先ほど結合した配列を比較して、一致している部分を探していきます。
一致を探索する処理においては、Pythonの標準ライブラリであるdifflibモジュールの SequenceMatcher が利用されています。
具体的には difflib.SequenceMatcher.get_mathing_blocks() というメソッドが利用されています。こちらのメソッドに比較対象の2つの配列を渡すことで一致箇所を探索することができます。

抽出ロジック1では一致を捕捉できないケース
抽出ロジック1では完全もしくは部分一致していても、文書内位置を捕捉できないケースがあります。
以下ソースコード内のコメントに、この点についての記載があります。
該当部分を日本語訳すると以下の通りです。
この処理ではPythonのdifflibモジュールに含まれるSequenceMatcherを使用して、ソース文書内のトークンと抽出項目のトークンを照合します。
抽出結果の順序がソーステキストの順序と大きく異なる場合、difflibは一部の一致をスキップする可能性があり、その結果、特定の抽出結果が未照合のまま残ることがあります。
要点として difflib.SequenceMatcher の仕様により、条件によっては一部の一致を取得できずスキップしてしまうことが記載されています。これは SequenceMatcher にて利用されているゲシュタルトパターンマッチングの特性に起因します。
どのような場合にこのスキップが発生するか、簡単な具体例を用いてステップを追って説明します。
以下の2つの文章が比較対象であると仮定します。
- a:
["x", "x", "y", "y", "y", "z", "z"]# xxyyyzz - b:
["y", "y", "y", "x", "x", "z", "z"]# yyyxxzz
ゲシュタルトパターンマッチングでは、初めに最長の一致を特定します。

その後、一致箇所を除く形で前後をブロックに分けて、分割されたブロックごとにそれぞれ比較が行われます。この処理は、一致が見つからなくなるまで、再帰的に実行されます。

ここで考えているケースにおいては、["x", "x"] も一致として取得されて欲しいところではありますが、最長の一致箇所から前後をブロックに分けて比較を繰り返すというロジックにより、aとbの ["x", "x"] は比較されることなく探索が終了してしまいます。
加えて、SequenceMatcher の特性だけでなく、LangExtract の実装ロジックの都合上、位置特定ロジック1では位置取得ができないケースがあります。以下のようなケースです。
ソース文書: "Findings consistent with degenerative disc disease at L5-S1."
抽出項目: "mild degenerative disc disease" # "mild"がソースにない
このケースでは、SequenceMatcher により、 ["degenerative", "disc", "disease"] の部分は一致として取得されるのですが、抽出テキストの先頭トークンの "mild" の一致が存在しないことにより、LangExtractの内部実装の都合上、スキップされてしまいます。
4. 位置特定ロジック2 (残項目ごとにファジーマッチングでフォールバック)
前ステップでは、 difflib.SequenceMatcher の特性および LangExtract の実装の都合上、一致している項目を取り逃がしてしまう可能性があることを説明しました。
この点に対する対策として、続く位置特定ロジック2では位置特定ロジック1で特定できなかった抽出項目に対してフォールバックする処理が行われます。こちらの処理は langextract/resolver.py の WordAligner._fuzzy_align_extraction メソッドにて実行されます。メソッド名が示す通りファジーマッチングによる照合が行われます。
位置特定ロジック2では、前段の位置特定ロジック1とは異なり、トークン分割された抽出項目ごとに抽出元テキストとの比較を丁寧に行います。
まず、抽出項目のトークン数と同じ長さのウィンドウを用意して、ソーステキストの頭からローリングウィンドウで、 SequenceMatcher による探索を繰り返します。

さらに、抽出元テキストの末尾までローリングウィンドウが完了したら、続いてウィンドウサイズを1増やして再び文末までローリングウィンドウを行います。ウィンドウサイズが抽出元テキストのトークン配列長と一致するまでこれを実行します。
上記の処理を繰り返した中で、 一致したトークン数 / 抽出項目のトークン数 の割合が最も高く、かつ割合が事前に指定された閾値以上であれば、該当のウィンドウの開始点から終了点までを文書内位置として特定します。この閾値については fuzzy_alignment_threshold として、ユーザー自身が設定することも可能です。デフォルト値は 0.75 となっています。
ロジックについて補足すると、全てのウィンドウで SequenceMatcher の実行が走ることにより演算量が増大してしまうことを防ぐための事前のフィルタ処理が存在しています。ウィンドウに含まれるトークンと抽出項目のトークンの重複数が、fuzzy_alignment_threshold と抽出項目トークン数を積算した数未満であれば、一致箇所である見込みが低いと考えられるため、SequenceMatcher の実行がスキップされます。
ここまで上述した通り、位置特定ロジック2は位置特定ロジック1よりも多くの計算量を必要とします。LangExtractは、計算量は少ないが正確性はそこまで高くない位置特定ロジック1で大半の項目の位置特定を行った後、残った項目については計算量は多いが正確性が高い位置特定ロジック2を実行することで、全体効率を図る設計になっていると言えるでしょう。
日本語対応してみる
LangExtractを日本語で利用する際の問題
上述したLangExtractのトークナイズ方法についてですが、英語には適した効率的なロジックですが、日本語には適していないように考えられます。例として、以下のようなケースで考えてみます。
from langextract.core.tokenizer import tokenize
txt = "株式会社ハッチュウと株式会社ヤリマスは、新商品デザイン制作に関し、以下の通り契約を締結する。"
print([txt[t.char_interval.start_pos : t.char_interval.end_pos] for t in tokenize(txt).tokens])
> ['株式会社ハッチュウと株式会社ヤリマスは、新商品デザイン制作に関し、以下の通り契約を締結する。']
結果を見て分かる通り、1文が丸ごと1つのトークンとして扱われており、全く区切られていない状態です。そのため抽出項目の位置特定が困難になることが想定されます。
実際にこちらのテキストを利用して「取引先」を抽出して見ましょう。自社を「株式会社ハッチュウ」とします。以下のコードでLangExtractを実行します。
実行コード
import pprint
import textwrap
import langextract as lx
prompt = """
契約書から取引先の会社名を抽出してください。
自社名は「株式会社ハッチュウ」です。
"""
examples = [
lx.data.ExampleData(
text=textwrap.dedent(
"""\
株式会社ハッチュウと株式会社ウケオイは、
Webアプリケーション開発業務委託に関し、以下の通り契約を締結する。"""
),
extractions=[
lx.data.Extraction(
extraction_class="取引先",
extraction_text="株式会社ウケオイ",
attributes=None
)
]
)
]
# LangExtract実行
result = lx.extract(
text_or_documents=textwrap.dedent(
"""\
株式会社ハッチュウと株式会社ヤリマスは、新商品デザイン制作に関し、以下の通り契約を締結する。"""
),
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)
pprint.pprint(result)
# HTML出力
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
抽出および位置特定の結果は以下の通りになりました。
AnnotatedDocument(
extractions=[
Extraction(
extraction_class="取引先",
extraction_text="株式会社ヤリマス",
char_interval=None,
alignment_status=None,
extraction_index=1,
group_index=0,
description=None,
attributes={},
)
],
text="株式会社ハッチュウと株式会社ヤリマスは、新商品デザイン制作に関し、以下の通り契約を締結する。",
)
取引先の「株式会社ヤリマス」は抽出できていますが、char_interval が None となっており位置を特定することができなかったようです。株式会社ヤリマス と一致するトークンが、抽出元テキストには存在しないためです。
SudachiPyによるトークナイズ
解決策として、日本語の形態素解析が可能なSudachiPyを利用してトークナイズを実行します。
langextract/core/tokenizer.py をSudachiPyを利用して書き換えたコードを、以下にcommitしました。AIを活用して記述したコードのため改善の余地があるとは思います。ご容赦ください。
この状態で上記のケースを再度実行した結果、抽出項目(株式会社ヤリマス)の位置を特定することができるようになりました。出力されたHTMLは以下の通りです。

まとめ
LangExtractのソースコードから、LLMで抽出した項目を表記揺れも考慮しながら、効率的に位置特定するロジックを紐解きました。このような手法を応用しながら、利用者に対して回答根拠をしっかりと提示できる、信頼性があり理解しやすいアプリケーションを作っていきたいと思います。

Discussion