Forest Plotの作成 by R
はじめに
Forest plotを作る機会があり、アウトプットと自分への備忘録も兼ねて、本記事を書きました。
本記事がForest plotを作成する機会のある方のお力になれれば幸いです。
目次
- Forest plot とは
- 扱うデータ
- RでForest plotを作成できるパッケージ
3.1. forestploter
3.2. forestplot - まとめ
本記事のデータ処理は{dplyr}を用いて行っている。
library(dplyr)
引用
- Rücker, G.; Schwarzer, G. Beyond the forest plot: The drapery plot. Res. Synth. Methods 2021, 12, 13–19.
- https://triadsou.hatenablog.com/entry/2024/02/27/204640
1. Forest plot とは
Forest plotはメタアナリシスや複数の群間比較の解析などで使われるグラフで、複数ある結果をまとめて一つのグラフに可視化して落とし込んだグラフである。以下のような図を指す。
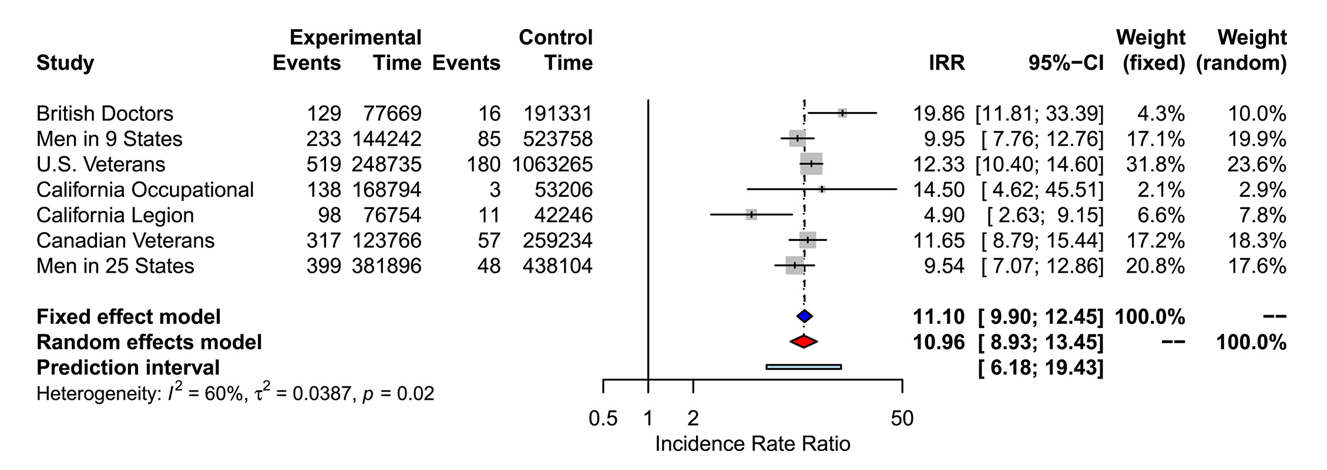
(Rücker and Schwarzer, 2020 Figure1 より:
https://onlinelibrary.wiley.com/doi/full/10.1002/jrsm.1410)
2. 扱うデータ
以下のようなデータを想定する。
| X1 | X2 | X3 | X4 | Y |
|---|---|---|---|---|
| 1.24 | 1.20 | 0 | 0 | 0 |
| 0.67 | -2.32 | 0 | 1 | 0 |
| : | : | : | : | : |
Y:何らかの関心のあるイベントの有無(1:発生, 0:未発生)
X1:連続量の変数(イベントの発生に関連)
X2:連続量の変数
X3:二値の変数
X4:二値の変数(イベントの発生に関連)
set.seed(111)
data <- data.frame(
x1=rnorm(100,1,0.5),
x2=rnorm(100,0,2),
x3=rbinom(100,1,0.5),
x4=rbinom(100,2,0.4))
data$y <- 0
for (i in 1:nrow(data)) {
data[i,5] <- rbinom(1,1, 0.5 - 0.2*data[i,1] + 0.2*data[i,4])
}
ここから先で作成するForest plotは、アウトカムYに対するX1~X4を含めた多変量ロジスティック回帰を行い、各変数の効果量とその95%信頼区間の可視化を表すようなグラフ、として想定する。
fit <- glm(y ~ x1+x2+x3+x4,
family = binomial,
data = data)
result <- data.frame(summary(fit)$coefficients)
多変量解析の結果は以下の通り(resultデータフレームの中身)
| Estimate | Std.Error | Z value | P value | |
|---|---|---|---|---|
| (Intercept) | -0.750 | 0.654 | -1.147 | 0.251 |
| X1 | -1.312 | 0.542 | -2.420 | 0.0155 |
| X2 | 0.245 | 0.139 | 1.757 | 0.789 |
| X3 | 0.353 | 0.505 | 0.700 | 0.484 |
| X4 | 1.852 | 0.413 | 4.487 | 7.23e-06 |
切片も加えた5つの要素のアウトカムに対する効果量の可視化として、点推定値およびその95%信頼区間、p値を一つのグラフに落とし込んだForest plotを作成していく。
3. RでForest plotを作成できるパッケージ
3.1 forestploter
forestploterパッケージではforest()を使って、forest plotを作成する。
その際に、あらかじめ信頼区間を示す列、点推定値と信頼区間を示すひげ図を表示する列(スペース列)を設ける必要がある。
ロジスティック回帰を行っていたので、スケールを戻してあげて、信頼区間の下限値、上限値を算出する。
result$pe <- exp(result$Estimate)
result$CIL <- exp(result$Estimate - qnorm(0.975)*result$Std..Error)
result$CIU <- exp(result$Estimate + qnorm(0.975)*result$Std..Error)
続いて、モデルに含めた説明変数の変数名を表すlabel列を作成する。
その後、信頼区間を表す文字列を作成した
(sprintf()は指定したフォーマットに従う文字列を作成する関数で、"%.2f"は小数点2桁表示を表す)。
変数名を一部見やすいように整えて、plotという列にグラフでのひげ図を表示させるために空白を返す。
そして、最後に見やすさのため、select()にてforest plotで用いる変数を抽出した。
result$label <- row.names(result)
result$CI <- ifelse(is.na(result$Estimate),"",
sprintf("%.2f(%.2f - %.2f)",
result$pe, result$CIL, result$CIU))
result$se <- result$Std..Error
result$p_value <- result$Pr...z..
result$plot <- paste(rep(" ", 40), collapse = " ")
df <- select(result, label, CI, plot, p_value)
いよいよForest plotの作成に移る。
fig <- forest(df[,c(1:4)],
est = df$pe,
lower = df$CIL,
upper = df$CIU,
sizes = 0.75,
ci_column = 3,
ref_line = 1,
xlim = c(0,5),
ticks_at = c(0.5,1,2,3,4,5),
theme = forest_theme(base_size = 12,
ci_pch = 16,
ci_Theight = 0.3,
refline_lwd = 2),
title = "フォレストプロットの参考図"
)
始めの引数ではforest plotで表示させる部分を指定している(変数名、信頼区間、ひげ図用のスペース列、p値)。
est:点推定値
lower:信頼区間下限値
upper:信頼区間上限値
sizes:点推定値のプロット点の大きさ
ci_column:ひげ図をどこに書くか(スペース列の列番号を指定)
ref_line:基準線の位置(今は、オッズなので1としています)
xlim:ひげ図の横軸の幅(データに合わせて調整してください)
ticks_at:ひげ図の横軸の目盛
theme:その他の体裁の指定
base_size:グラフのサイズ
ci_pch:点推定値のプロット点の種類
ci_Theight:信頼区間のひげのサイズ
refline_lwd:基準線の線のスタイル
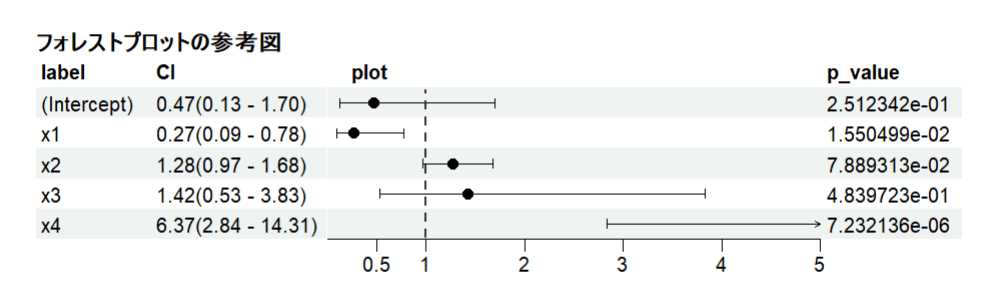
この図では一番下のX4がプロットもなく、右端が矢印となっているが、これは横軸の範囲に収まりきっていないことによるものなので、グラフとして扱うデータの数値などから適宜調整する必要がある。
調整したものはこちら(他の変数と同様の表示となっていることが確認できた)。
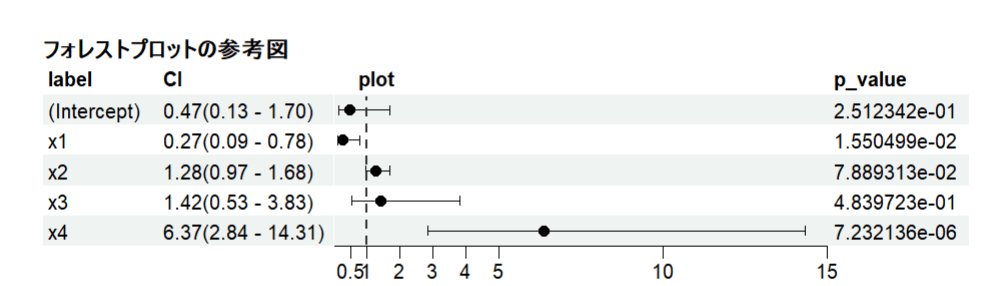
調整前のグラフに比べて、少し窮屈を印象を受けるが、横軸が広がり相対的に縮小されたことによるので、スペース列の空白の数を増やす(現在は40)、プロット点のサイズを小さくするなど工夫していただきたい。
3.2 forestplot
こちらはTriad Sou.さんのブログに説明があり、こちらを読むことお勧めします。
{forestplot}に関しては、より様々な体裁のアレンジがオプションで実装されていて、便利そう。
ただ、ヘルプの事例が少ないとのことで、慣れるまで大変そうであるが、雰囲気で書けそうとのこと。
4. まとめ
本記事では、
- {forestploter}
- {forestplot}
を取り上げた(forestplotはTriad Sou.さんのブログのおすすめ)。
本記事で扱ったパッケージの他にも、Forest plotが作成できるパッケージは多々あり、自分の使いやすいもの、扱うデータや出力すべき情報に応じて最適なものを扱うことができればいいのではないかと思う。
本記事に対して、コメントや感想でも下さると嬉しいです。
もし間違いやおかしな箇所がありましたら、後学のためにも教えてくださると幸いです。
Discussion