Push Swap 〜座標圧縮せずにソートする方法〜


by 課題のハードルを上げようの会
課題
2つのスタックと11個の操作を使用して、ソートする課題です。
座標圧縮していますか?
突然ですが、座標圧縮していますか?
邪道です。
一度ソートしたものを、またソートして何が楽しいんですか?(煽)
冗談です
別に邪道だとは思いませんが、なんだかモヤモヤします。
push swapの解説記事を読んでいると、座標圧縮を前提に書かれているものが多いです。つまり、任意の要素に対して、それが全体中で何番目に大きいか、事前に知っていることを仮定していますが、基本的にソートアルゴリズムの中でその情報知ることはできません。
ソートというのは、乱雑な列から秩序ある列へとエントロピーを下げていくことだと思いますが、座標圧縮して「中間値で分割」や「近い値を10個を選ぶ」という操作はマクスウェルの悪魔を仮定しているみたいで、なんだか気持ち悪いです。
座標圧縮せずに、しかもできるだけ効率的にPush Swapを攻略する方法を考えます。
この記事の目標
- 座標圧縮せずに、できるだけ効率的にソートするアルゴリズムを考えます。
(『効率的にソート』とはO(Nlog(N)) - できるだけ計算量解析します。
でも僕の実力ではあまりうまくできませんでした。(泣)
ツヨツヨの方、コメントもらえると嬉しいです。
想定している読者
早く課題を終わらせたい人は座標圧縮した方がずっと楽で簡単な方法がたくさんあるので、そういう人は他の記事を参考にして下さい。
この記事は下記のような人を想定して書かれています。
- 自ら沼にはまりたい人
- ソートアルゴリズムの中でソートすることはプライドが許さない人
- この課題を解く目的を意識して、じっくり考えたい人
動画
先に動画を見せておくと、こんか感じの方針で実装しました。
簡単な例
偶然Bが下記のように、単調減少した後、単調増加する列だった場合、ソートは簡単です。
一番上と一番下を比較して、大きい順にAに運んでいけばソートできます。
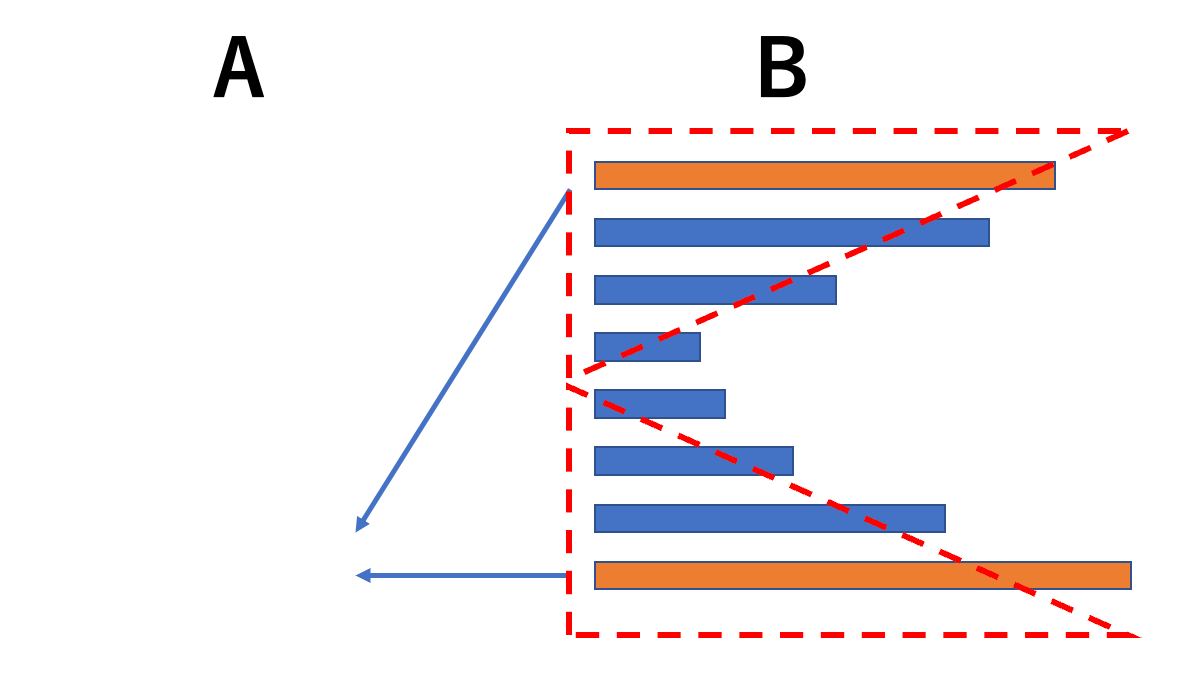
期待しているBの形にするには
ではBような形にするには、その一歩前のA’はどの様な形だと嬉しいか?
A’の黄色の部分は大きい順にBに運ぶ
A’の緑色の部分は小さい順にBに運ぶ
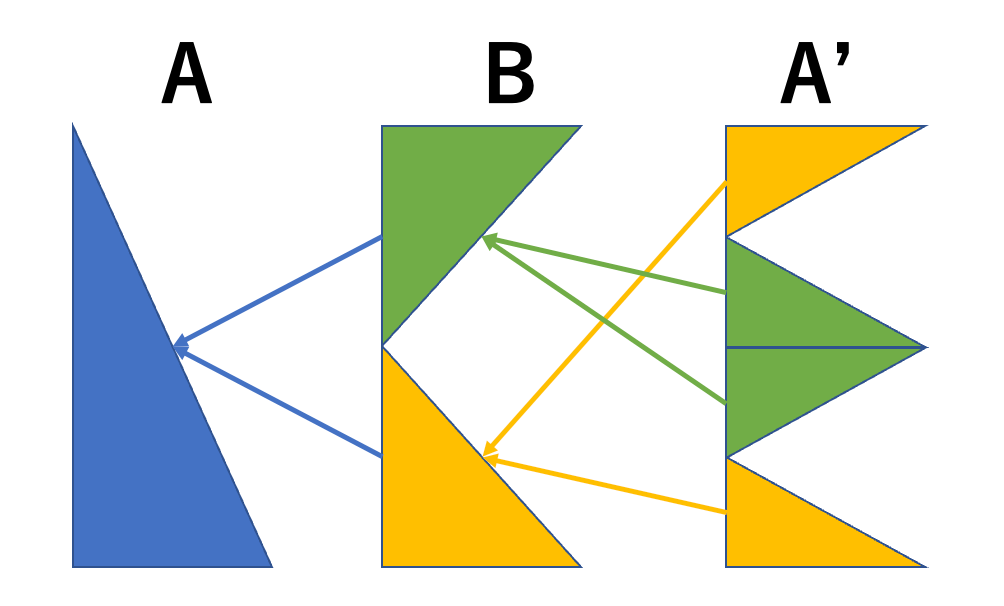
要素が2個以下になるまで繰り返す
同様にしてA’の一歩前のB’の形がきまり、その一歩前のA’’の形も決まり・・・
最終的に山に含まれる要素が2個以下になるまで分割します。
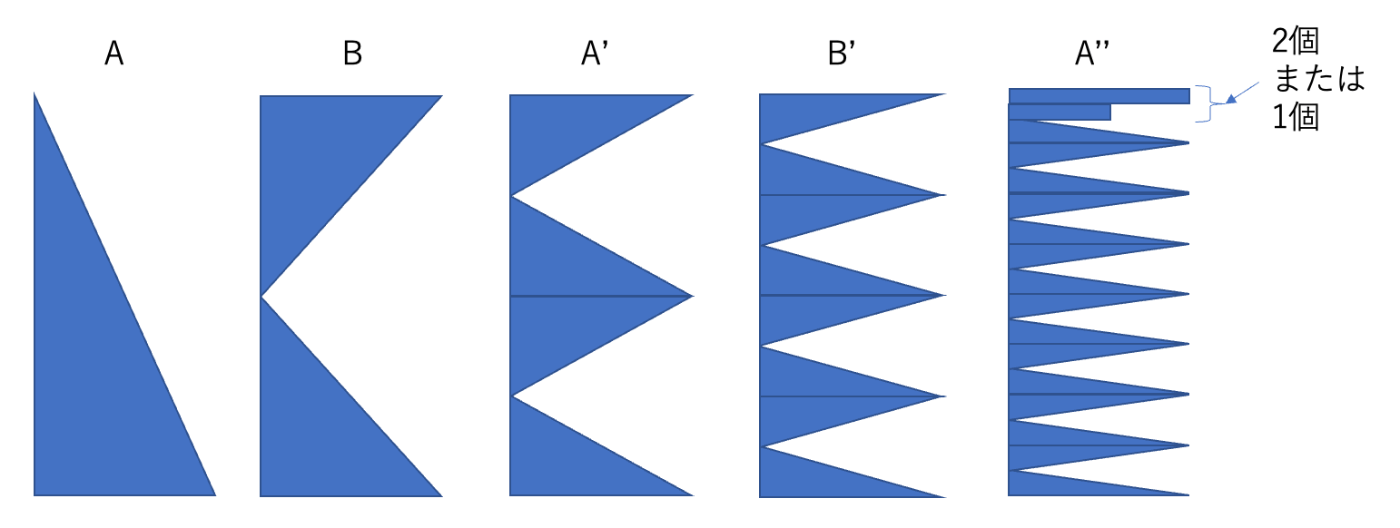
なんとなくできそう
なんとなくソートできそうですね。
では早速作っていきま・・・せん。
まだ作りません。
PDFのObjectivesに
「complexity大事だよ。job interviewで聞かれるよ」
と書いてあるので、計算量を調べます。
山を結合する手数
2つの山を結合させるには
上(紫色)から運ぶのは1手ですが、
下(赤色)から運ぶには一度上に持ってくる必要がるので2手必要です。
要素数がNとしたとき、1回の山の結合には3/2N回操作が必要になります。
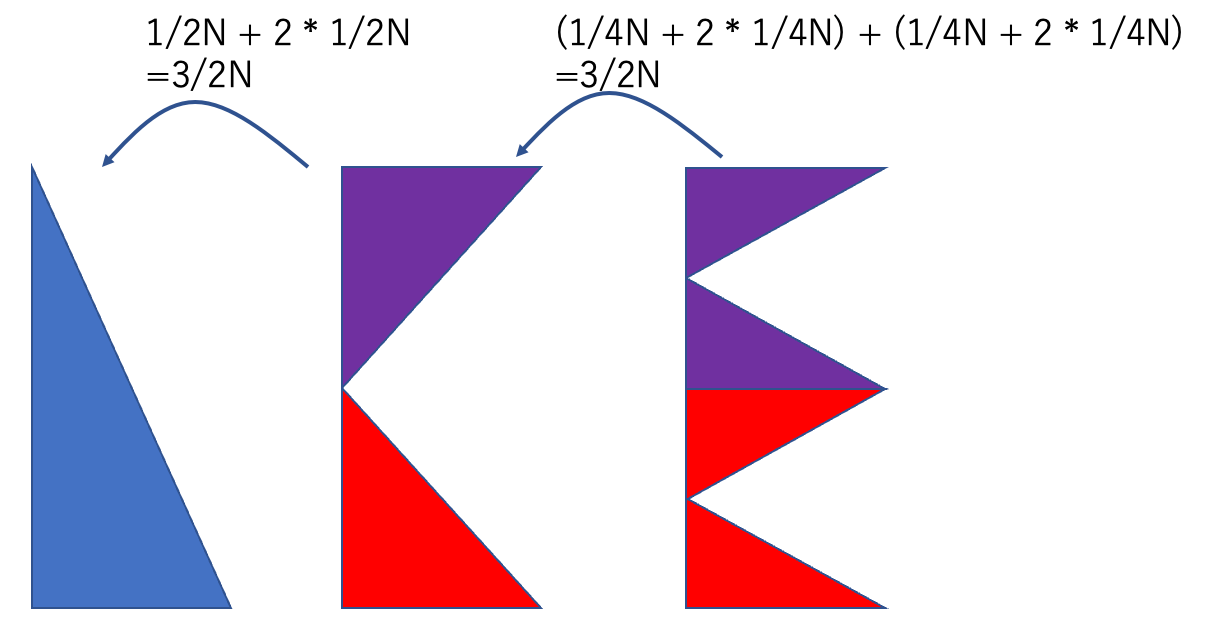
山の結合を何回繰り返せばよい?
ではAとBを何回行ったり来たりすれば、ソートできるでしょうか?
言い換えると、要素数がN個あった場合に何回2で割れるか?
あるいは、2を何乗するとNになるのか?
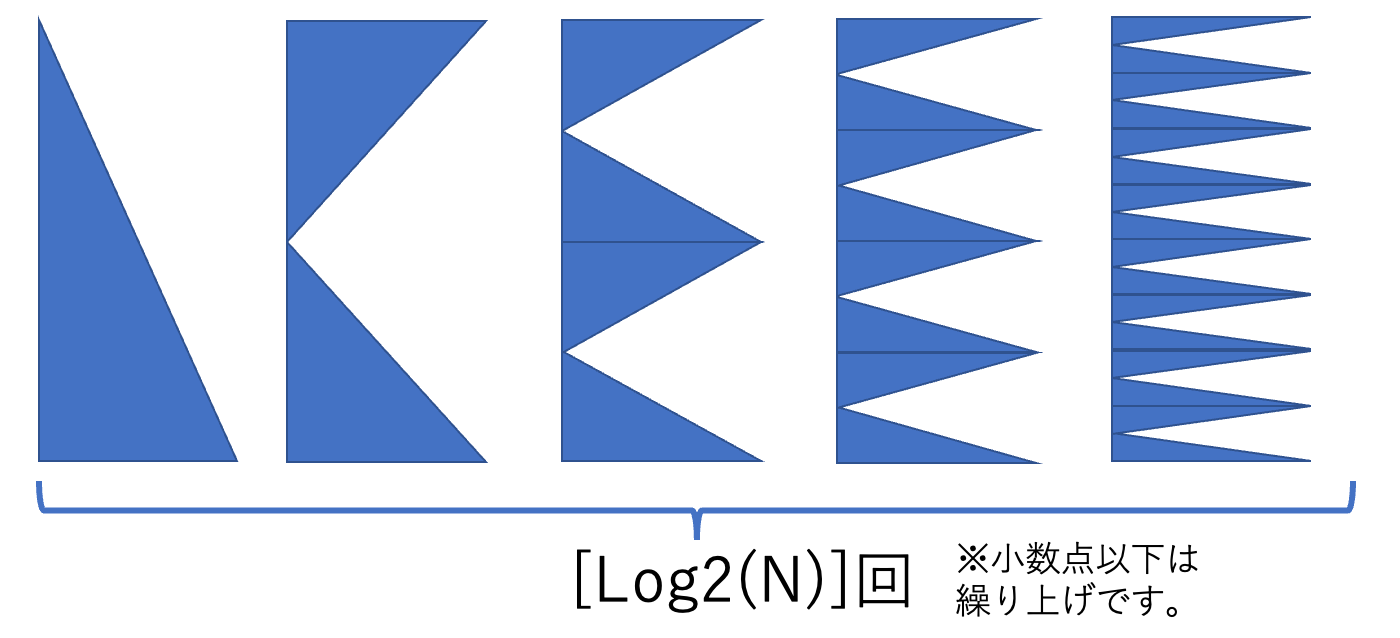
計算量の見積もり
1回の山の結合に
ソートするには
悪くないですが、
定数倍早くして、
ぐらいを目指したいです。
参考までに、
となります。
このアルゴリズムのポイント
- 常に一番上と一番下の2個の値としか比較していない
(魔法(座標圧縮)を使って「真ん中の値と比較」とか、気持ち悪いことをしなくてよい) - 最悪計算量が
O(N log (N))
ちなみにこのソート方法はマージソートと言います。
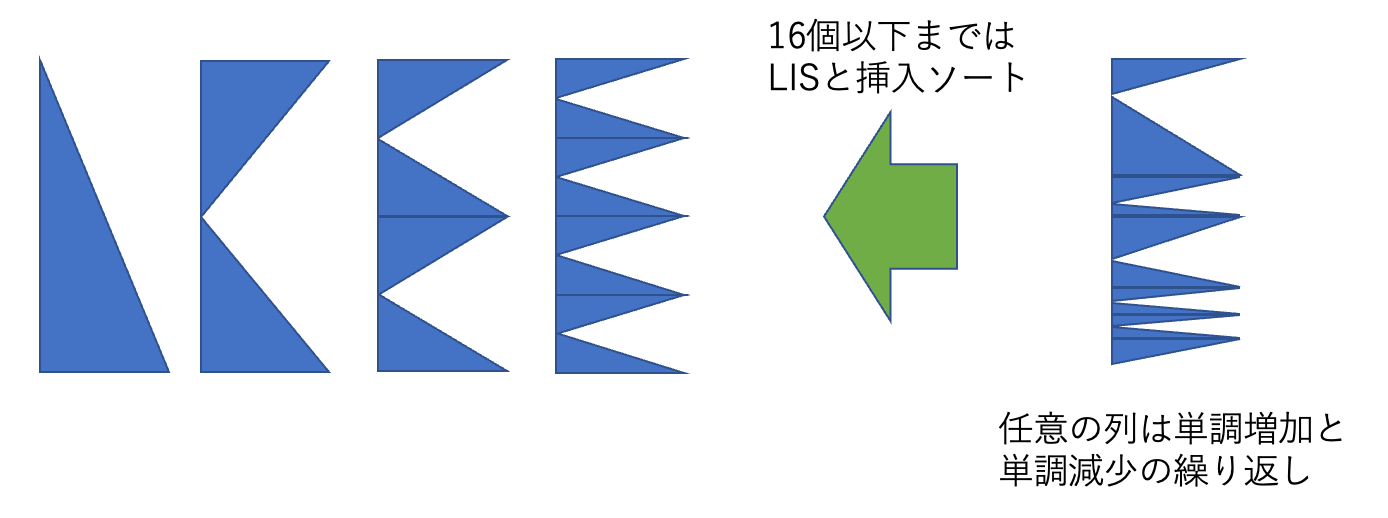
最適化(1) 初期は挿入ソートにする
最初に律儀に2個まで分割するのは効率悪そうに見えます。そもそも任意の列は「単調増加と単調減少の繰り返し」と考えられます。適当に間引いて上げれば、その単調増加(減少)の列はもう少し長くとれます。
最長増加部分列(LIS)のアルゴリズムを少し改良して、
単調増加と単調減少の繰り返しを見つけ、余ったものを適当に間に挿入して、一つの山が8~16個程度にする。
最適化(2) マージの最適化
毎回AからBに全部送るのは無駄です。特に下から値を取るのは2手必要で効率が悪いです。
AからBに全部送らずに、少し手を抜けば3/8N回減らせます。詳細は省略
(もっといい方法があるかも?)
最適化(3) ランレングス圧縮
最後にランレングス圧縮をして、まとめて操作できるところをまとめます。
pa pb→削除
ra rb→rr
など、色々あるので考えてみて下さい。
ランレングス圧縮の解説はこの動画が面白いです。
注意点
- 座標圧縮していないので、最初に重複チェックすることができません。重複があっても問題なくソートできる必要があります。ソートし終わった後、最後に重複チェックをします。
- 適当に分割してマージすると最後にBで揃ってしまう可能性があるので、最後Aで揃うように工夫する必要があります。
結果
Test 1000 cases: arg_length=100 range=(-2147483648, 2147483647)
---- Result ----
max : 697
median: 636
min : 578
(※maxは1万回に数回、700回を超えます)
Test 1000 cases: arg_length=500 range=(-2147483648, 2147483647)
---- Result ----
max : 5251
median: 4979
min : 4796
課題
- 最適化(1)でLISと挿入ソートを使いましたが、そこであまり効率的なアルゴリズムが思いつかず、計算量解析もできなかったのが心残りです。内部の計算効率が悪く、遅くなってしまいました。
- 結局
N=100 - 最適化(1)の計算量解析をちゃんとできず、場当たり的な最適化しかできませんでした。
感想
学生の頃、物理学史の先生が「科学と技術は違う」と話していたことが印象に残っています。
科学と技術は相補的な関係(科学が進歩すれば技術が進歩し、技術が進歩すれば科学が進歩する)ではありますが、歴史的成り立ちから言っても、問題に対するアプローチの仕方から言っても科学と技術は異なるものだと話していました。
Push Swapは科学的なアプローチと技術的なアプローチの両方が必要で面白かったです。座標圧縮してしまうと、黒魔術で中間値が分かったり、隣接する値が分かってしまって、ただ手数を減らすだけの技術的な作業になってしまって、もったいない気がします。
現象を見つめ、エントロピーと戦うことは楽しかったです。(おかげでめちゃくちゃ時間がかかってしまいましたが・・・)
念の為もう一度書きますがPush Swapの中で座標圧縮する事を否定するつもりはありません。
この記事はpush swapの限られた命令でも座標圧縮しなくても
Discussion