eBPF第9章

こちらはeBPF本の第9章の勉強会資料です。
今まではeBPFがシステム全体のイベントをどのように観測して、イベントに関する情報をユーザ空間のツールにどうやって報告するかについて説明してきた。
第9章では不正な活動を検出・禁止するeBPFベースのセキュリティツールを作成するためにイベント検出の概念を活用する方法を説明する。
9.1 セキュリティの可観測性に必要なポリシーとコンテクスト
まず、セキュリティツールは一般的なイベント観測ツールと違って、以下のことを区別しないといけない
- 通常の状態で起こるイベント
- 不正な活動が行われていると考えられるイベント
ローカルファイルに書き込んでいるアプリケーションがあるとして、これがローカルファイルに書き込んでいる間は大丈夫だが、セキュリティ上重要なファイルに書き込んでいる場合は管理者に通知するのが望ましい。(/etc/passwdなど)
で次にポリシーとはセキュリティを維持するための一連のルールや設定のこと。
ポリシーはシステムが完全に機能しているときの通常の振る舞いだけでなく、エラー時に想定されている振る舞いについても考慮する必要がある。
例)物理ディスクの容量が少ない、なくなった ー> 管理者に警告するが、これはセキュリティイベントではない。エラー時に振る舞いを考慮に入れると効果の高いポリシーの作成が難しくなる。
ポリシーには以下を定義する:
- 何が想定されているか
- 何が想定されていないか
セキュリティツールはある活動とポリシーを比較を、ポリシーの範囲外であれば疑わしい活動だとみなして何かしらのアクションを実行する。
利用できるコンテキストが詳細であればあるほど、なぜイベントが起きたのか調査しやすくなる。そしてそれが攻撃によるものかわかりやすくなる。イベントが攻撃によるものだとした場合、以下が判定しやすくなる。
- どのコンポーネントに影響を及ぼしうるか
- いつどのように攻撃が行われたのか
- 誰に責任があるか

まずシステムコールを例にどうやってセキュリティイベントを検知して対処するのかについて例を示す。
(システムコールはeBPFプログラムをアタッチできるイベントのひとつだが、これは必ずしも最も効率的な方法ではない。)
9.2 セキュリティイベント用のシステムコールの使用
システムコールとはユーザー空間のアプリケーションとカーネルのインタフェースである。アプリケーションが一部のシステムコールしか使えないようにすると、できることを制限できる。
e.g.) open*()系のシステムコールの呼び出しを禁止にすれば、ファイルをオープンできなくなる。オープンをきっかけにした攻撃を防げるようになる。
システムコールを制限するseccompという機能についてまずは説明していく。
9.2.1 seccomp
SECcure COMputingの略。
strict modeの場合、システムコールをRead、Write、Exit、Sigreturnに制限できる。は信頼できないコードを不正な挙動ができない状態で実行することが目的(例えばインターネットからダウンロードしてきたプログラムなど)。
多くのアプリケーションはまともに動くにはStrictモードでは厳しい。ただ400以上のシステムコールをすべて使える必要はない。これをきめ細かく設定できると便利ということで、seccomp-bpfがコンテナの世界では使われてきた。このモードでは、BPFのコードを用いて許可・禁止するシステムコールを決める。
seccomp-bpfではBPF命令のセットをフィルタという形でロードし、動作させる。システムコールを呼ぶたびにフィルタがトリガーされる。フィルタ用のコードはシステムコールに渡される引数にアクセスできる。これを使ってシステムコールの種類と、引数の両方を使ってフィルタ結果を決定することができる。
その結果に指定できるのは:
- システムコールの実行を許可する
- 所定のエラーコードをユーザ空間のアプリケーションに返す
- スレッドをKillする
- ユーザー空間のアプリケーションに通知する seccomp-unotifyと呼ばれる
ここで注意しないといけないのはポインタ渡しではだめで値渡しでないといけないことと、プロセスが開始されたときに設定しないといけないということ。
Dockerで似たようなものが見られるらしい。
コンテナ化されたアプリケーションが使うために作られた汎用的なプロファイル:
...
{
"architecture": "SCMP_ARCH_RISCV64",
"subArchitectures": null
}
],
"syscalls": [
{
"names": [
"accept",
"accept4",
"access",
"adjtimex",
...
reboot は禁止されている(ALLOWと書いてあるが。。。?)
?https://github.com/moby/moby/blob/master/profiles/seccomp/default.json#L688
{
"names": [
"reboot"
],
"action": "SCMP_ACT_ALLOW",
"includes": {
"caps": [
"CAP_SYS_BOOT"
]
}
},
9.2.2 seccompプロファイルの自動生成
最近のプログラムは高水準なためシステムコールまわりは隠蔽されている。なので普通のアプリケーションエンジニアにseccompの生成をお願いすることは難しい。
これを解決するためstraceを使ってシステムコールを呼び集めて、プロファイルを生成するなどの自動化が進められてきたが、K8s上でいちいちやるのは面倒なのでクラウド時代には適していない。また、プロファイルはAPIやりとりのためにJSON形式であることが望ましい。これができるツールとして
- Inspektor Gadget https://www.inspektor-gadget.io/
- Red Hat のツール https://github.com/containers/oci-seccomp-bpf-hook
などが挙げられる。注意点としてプロファイルを作成するためにまずアプリケーションを走らせないといけないことと、エラー時に使うシステムコールも考慮して挙動について考えないといけないことがある。そしてアプリケーション開発者もプロファイルが正しいかどうか検証するのは難しい。
OCIランタイムフックを例にとると、eBPFプログラムはsyscall_enter Raw Tracepointにアタッチして呼ばれたシステムコールを追跡し、記録するeBPF Mapを作成して管理する。
...
BPF_HASH(seen_syscalls, int, u64);
...
// enter_trace : function is attached to the kernel tracepoint raw_syscalls:sys_enter it is
// called whenever a syscall is made. The function stores the pid_namespace (task->nsproxy->pid_ns_for_children->ns.inum) of the PID which
...
int enter_trace(struct tracepoint__raw_syscalls__sys_enter* args)
{
struct syscall_data data = {};
...
record_and_exit:
seen++;
seen_syscalls.update(&id, &seen);
return 0;
このツールのユーザ空間の部分はGolangで書かれている。
src := strings.Replace(source, "$PARENT_PID", strconv.Itoa(pid), -1) // 1
m := bcc.NewModule(src, []string{})
defer m.Close()
logrus.Info("Loading enter tracepoint")
enterTrace, err := m.LoadTracepoint("enter_trace") // 2
if err != nil {
return errors.Wrap(err, "error loading tracepoint")
}
logrus.Info("Loading exit tracepoint")
checkExit, err := m.LoadTracepoint("check_exit")
if err != nil {
return errors.Wrap(err, "error loading tracepoint")
}
logrus.Info("Loaded tracepoints")
if err := m.AttachTracepoint("raw_syscalls:sys_enter", enterTrace); err != nil { // 3
return errors.Wrap(err, "error attaching to tracepoint")
}
if err := m.AttachTracepoint("sched:sched_process_exit", checkExit); err != nil {
return errors.Wrap(err, "error attaching to tracepoint")
}
- PARENT_PIDをプロセスIDの数値で置き換えている
- enter_traceという名前のeBPFプログラムをロードする
- enter_traceプログラムをraw_syscalls:sys_enter Tracepointにアタッチしているので、あらゆるシステムコールの呼び出しに対応する。どのシステムコールを呼んでもこのTracepointに到達する。
これらのプロファイラはsys_enterにアタッチされたeBPFプログラムを使い、使われたシステムコールの情報を集めてseccompプロファイルを生成する。このプロファイルを実際にseccompがプログラムに適用することになる。
このあとに述べるeBPFツールもsys_enterにアタッチする。
9.2.3 システムコール追跡ベースのセキュリティツール
システムコールベースのツールとして有名なのはFalco.カーネルモジュールとしてインストールするものと、eBPFで実装したバージョンもある。
ユーザはルールを定義してイベントがセキュリティ関連のものであるか決定する。
e.g.)
# detect and log shell activity within containers
- rule: shell_in_container
desc: notice shell activity within a container
condition: >
evt.type = execve and
evt.dir = < and
container.id != host and
(proc.name = bash or
proc.name = ksh)
output: >
shell in a container
(user=%user.name container_id=%container.id container_name=%container.name
shell=%proc.name parent=%proc.pname cmdline=%proc.cmdline)
priority: WARNING
ポリシーに適合しないイベントが起きたときにアラートを生成することができる。
カーネルモジュール、eBPFプログラム両方ともシステムコールにアタッチする。どちらもsys_enter, sys_exitにアタッチされている。
eBPFプログラムは動的にロードでき、動作中のプロセスからトリガーされたイベントも検知できる。アプリケーションのコードや設定の変更をせずルールを変更、適用できるのでこれはseccompと違う長所の一つ。
ただ、問題としてTOCTOU(Time of check time of use)があげられる。TOCTOUはデータを確認したときと利用するタイミングのずれによって生じうる場合に攻撃される脆弱性の一般的な呼び方。
システムコールの入り口でトリガーされた場合、プログラムはシステムコールの引数にアクセスできる。引数がポインタであれば、カーネルはポインタが指し示すデータをカーネル内にコピーしてから利用する。eBPFプログラムがデータを確認してデータをコピーするまでの間に攻撃者がデータを変更する可能性がある。このため、カーネルが使うデータはeBPFプログラムが使うデータと異なる可能性がある。

それに比べてseccomp-bpfは値渡しなのでこの問題はない。
だがseccomp-unotifyには同じことが起こりうる。
seccomp_unotify: 最近のカーネルモジュールに追加された、検知したイベントをユーザ空間にレポートするためのseccompのモード。
seccomp_unotifyはユーザ空間通知のメカニズムはセキュリティポリシーの実装のためには利用できないと書かれている。
It should thus be absolutely clear that the seccomp user-space
notification mechanism can not be used to implement a security
policy!
可観測性のためには非常に便利だが、厳密なセキュリティツールにとっては不十分と言える。
Linux向けのSysmonはTOCTOU問題に対してシステムコールの入り口と出口の両方にアタッチすることで対応している。システムコールの呼び出しが完了したら、Sysmonはカーネルのデータ構造を確認する。ファイル記述子を返していたら、出口にアタッチされたeBPFプログラムはプロセスのファイル記述しテーブルを確認することによって参照しているオブジェクトについて正確な情報を取得できる。これはロギングはできるが、確認した時点でシステムコールの呼び出しは終わっているので攻撃を防ぐことはできていない。
確実にカーネルが使うことになるデータをeBPFプログラム内で確認するには引数がカーネルメモリにコピーされたあとのイベントにeBPFプログラムをアタッチするべきだが、このような都合のよいイベントは存在しないので難しい。
これに対処するためのBPF LSMについて説明する。
9.3 BPF LSM (Linux Security Modules)
LSMインタフェースは元々カーネルモジュールの形で実装されるセキュリティツールのために提供されたものである。
LSMのフレームワークはカーネルがその内部のデータ構造にアクセスする直前に起動するフックを提供する。このフックから呼び出す関数によって、対応するアクションを継続すべきか否かを決定できる。
以下はfile_mprotect LSM hookにアタッチする例。
"lsm/file_mprotect" indicates the LSM hook that the program must be attached to
mprotect_audit is the name of the eBPF program
SEC("lsm/file_mprotect")
int BPF_PROG(mprotect_audit, struct vm_area_struct *vma,
unsigned long reqprot, unsigned long prot, int ret)
{
/* ret is the return value from the previous BPF program
* or 0 if it's the first hook.
*/
if (ret != 0)
return ret;
int is_heap;
is_heap = (vma->vm_start >= vma->vm_mm->start_brk &&
vma->vm_end <= vma->vm_mm->brk);
/* Return an -EPERM or write information to the perf events buffer
* for auditing
*/
if (is_heap)
return -EPERM;
}
LSM hookは100種類以上存在し、カーネルソースコード上で詳しく説明されている。
/*
* Table of the static calls for each LSM hook.
* Once the LSMs are initialized, their callbacks will be copied to these
* tables such that the calls are filled backwards (from last to first).
* This way, we can jump directly to the first used static call, and execute
* all of them after. This essentially makes the entry point
* dynamic to adapt the number of static calls to the number of callbacks.
*/
struct lsm_static_calls_table {
#define LSM_HOOK(RET, DEFAULT, NAME, ...) \
struct lsm_static_call NAME[MAX_LSM_COUNT];
#include <linux/lsm_hook_defs.h>
#undef LSM_HOOK
} __packed __randomize_layout;
システムコールとLSMフックは一対一対応していないが、あるシステムコールにおいてセキュリティの観点で好ましくないことが起こりうる場合は、システムコールにはフックが存在する可能性が高い。
LSMフックにアタッチするサンプルコードはこちら:
SEC("lsm/path_chmod")
int BPF_PROG(path_chmod, const struct path * path, umode_t mode)
{
bpf_printk("Change mode of file name %s\n", path->dentry->d_iname);
return 0;
}
このプログラムはchmodの対象となるファイル名を出力して、常に0を返すだけあが、ファイル名を使ってアクセス権の変更をすべきか否かを判断するプログラムが作りやすいことがわかる。0以外の戻り値はアクセス権の変更を拒否するという意味になる。このポリシーチェックはカーネル内のみで実施されるので、性能的に有利。
LSM BPFはカーネル5.7から使えるようになった。
9.4 Cilium Tetragon
TetragonはCiliumプロジェクトの一部。
eBPFプログラムをLSMフックにアタッチするのではなく、Linuxカーネルの任意の関数に対してアタッチするフレームワーク。
TetragonはK8s環境で使うように設計されていて、TracingPolicyというK8sのカスタムリソースを定義している。このリソースはeBPFプログラムがアタッチすべきイベントの集合とeBPFがチェックすべき条件、条件に一致したときに取るべきアクションを定義している。
spec:
kprobes:
- call: "fd_install"
...
matchArgs:
- index: 1
operator: "Prefix"
values:
- "/etc/"
上記はfd_install関数が呼び出されたときにアタッチすべき一群のkprobeを定義している。
9.4.1 カーネル関数へのアタッチ
システムコールとLSMインターフェースは安定したインターフェースとして定義されていて、後方互換性が壊れる形で変更されることはない。なので将来も安定して動き続ける保証がある。
だが、おれらのインターフェースは3千万行を超えるLinuxカーネルのコードのうちのごく一部しかカバーできない。Linuxのコードベースの一部には長期間に渡って変更されず、将来も変更されない部分が存在する。このようなコードは公式では宣言されていないものの、安定しているとみなせる。このようなカーネル関数にアタッチするeBPFプログラムは一定の期間機能すれば良いと割り切れるのであれば書いても問題ない。(<=本当?)
Tetragonのコントリビュータにはカーネル開発者がたくさんいる。
TracingPolicyの書き方
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "sys-write"
spec:
kprobes:
- call: "sys_write"
syscall: true
args:
- index: 0
type: "int"
- index: 1
type: "char_buf"
sizeArgIndex: 3
- index: 2
type: "size_t"
# follow any non-init pids stdout e.g. exec into container
selectors:
- matchPIDs:
- operator: NotIn
followForks: true
isNamespacePID: true
values:
- 1
matchArgs:
- index: 0
operator: "Equal"
values:
- "1"
fd_installのコード
/*
* Install a file pointer in the fd array.
...
*/
void fd_install(unsigned int fd, struct file *file)
{
struct files_struct *files = current->files;
struct fdtable *fdt;
ファイルがオープンされたときに、ファイルのデータ構造がカーネル内部で作成されてから呼ばれる。先ほどの例では、一つ目のポリシーは/etcで開始するファイル名のものを対象としている。この関数でファイルの名前を確認すると、TOCTOU問題は発生しないので、安全に判定できる。
Tetragonでもコンテキスト情報へのアクセスが可能で、セキュリティ的な決定を全部カーネル内部で行えるようにしている。
9.4.2 予防的セキュリティ
ほとんどeBPFベースのセキュリティツールは悪意のあるイベントの検知にeBPFプログラムを使っている。この場合、eBPFプログラムはユーザ空間のアプリケーションに検知後にアクションを起こすようにしている。
図の通り、非同期にアクションが取られており、タイミングが遅すぎることもありえる。
これでは攻撃者がデータを抜き取ったり、悪意のあるコードを永続化したあとに通知が届く可能性がある。

カーネルv5.3以降にはbpf_send_signalというヘルパ関数が存在する。Tetragonはこの関数を予防的なセキュリティの実現に利用している。ポリシー定義がSigkillアクションだった場合、マッチしたイベントの発生時にTetragonのeBPFコードはSIGKILLシグナルを発生させ、プロセスを強制終了させることができる。これは同期的に発生し、攻撃を未然に防げる。ただこれは問題のないアプリケーションを落としてしまわないようになど、細心の注意を払う必要がある。
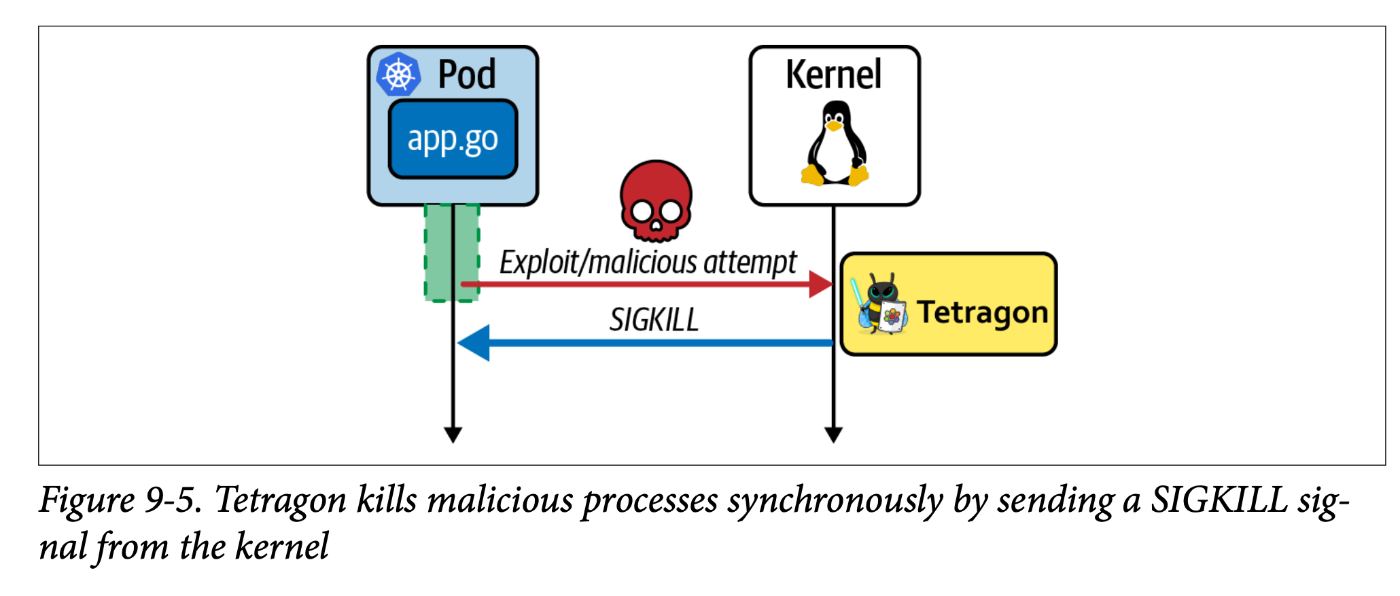
Cilium Tetragonによるセキュリティイベントの検知はこちらの本でより詳しくわかるらしい。
9.5 ネットワークセキュリティ
第8章では
- ファイアウォールやDDoS防衛の実装には、パケットがネットワークイングレスを通る初期段階にアタッチしたeBPFプログラムが適している。ハードウェアにオフロードされたXDPプログラムによって悪意のあるパケットはCPUすら到達させないこともできる。
- 高度なネットワークポリシーを実現するには、ネットワークスタックの各ポイントにeBPFプログラムをアタッチして、ポリシー外と判断したパケットをドロップすればよい。高度なネットワークポリシーの例としてK8sにおいてどのサービス同士であればお互いに通信できるか定義する例が挙げられる。
ネットワークセキュリティツールを予防的モードで使って悪意のあるパケットを監査するだけでなく、ドロップすることがよくある。ネットワーク上は攻撃を試しやすく、デバイスをインターネットに接続してパブリックなIPアドレスを割り当てるとすぐに攻撃と疑わしいトラフィックがやってくるため、このように運用せざるをえない。
でもその一方で、監査モードで使用する組織も多い。疑わしいイベントが悪意のあるイベントだったか判定してどのように対策を取るか決めている。偽陽性が多いツールの場合はしょうがないとも言える。
これからはeBPFは今あるものよりも高度な、粒度の細かい、正確な制御ができるセキュリティツールが実現できるはずと筆者は考えている。これからは予防的モードで走らせるのが主流となっていくだろう。
Discussion