深層学習が多層の膨大なパラメータを学習できる雰囲気を理解する
はじめに
筆者のモチベーション
本記事のキーワードは、
- 普遍近似定理(Universal Approximation Theorem)
- 二重降下(Double Descent)
- 過剰パラメータ化(Over-parameterized)
- 多層化の利点(Benefits of Depth)
といった感じで、これらのトピックを解説した素晴らしい和文資料は既にたくさん存在します。
そんな中で「とりあえずこの記事を読めば深層学習がうまく学習できる雰囲気を掴める」記事を書くことを目標にしています。深層学習を取り巻くテーマは多岐にわたるため、論文を読み始めると NotebookLM を駆使したとしてもまだまだ大変な作業であり、各事柄を個別に解説した記事もいろいろ読まねばなりません。もちろん、DeepResearch 等を使えば本記事よりも多くの情報が得られるかもしれませんが、キュレーションしつつ詳しさに濃淡をつけながら、図を駆使した説明は2025年現在の DeepResearch では「とりあえずこの記事を読めば深層学習がうまく学習できる雰囲気を掴める」水準には達しないと思っています[1]。「雰囲気を掴む」という表現をしていますが、字面だけの説明からは一歩踏み込んだ解像度の理解を目指したいと思います。
また、生成AIブームでAIに興味を持ち始めた方も増えています。そんな方々に、現在の生成AIそのものである深層学習の面白いポイントを是非伝えたいという気持ちもあります。
そして何よりも、アウトプットこそ最強の勉強法ということで、自身の勉強のためにも記事を書いています。
膨大なパラメータの不思議
生成AI等でお馴染み、Transformer や Diffusion は多層ニューラルネットワーク(深層学習)によって実現されています。2025年現在での最先端 LLM に用いられているパラメータ数は非公開なものが多いですが、オープンソースモデルである Llama 3.1 では405B(B: Billion = 10億なので、405Bは4050億)ものパラメータを持っています。その他 GPT4 や Gemini2.5 などの非公開なモデルでは兆を超えるパラメータを持つとも言われています。
一方で、昔からある統計モデルを学んだ人は次の事実もご存じのはずです。
パラメータ数が多くなると過学習が起こりやすくなる
実際、線形回帰モデルにおいては特徴量の次元数がデータ数を上回るとき、任意のラベルを完全に再現できます。これは線形代数的に明らかで、
そこで、古典的な統計学では赤池情報量基準を用いてモデルを選んだり、決定木では深さ、回帰分析では正則化パラメータを調整したりすることで、パラメータ数を調整しながら汎化性能を高めようとしてきました。しかし、近年のニューラルネットワークではデータ数をはるかに超えるパラメータ数を持つモデルが登場し[3]、見事な汎化性能を誇っています。
さて、近年の驚くべき性能を誇る深層学習モデルは、どうやって過学習を回避しながら適切なパラメータを発見しているのでしょうか。そもそも言語や画像の生成など複雑なタスクを遂行できるモデルパラメータは存在するのでしょうか。その疑問を少しでも理解できるよう、勉強した内容を本記事で解説します。
本記事の構成
本記事では、以下の流れで説明します。
- そもそも解は存在するのか(普遍近似定理[4])
- ニューラルネットワークは強い表現力を持ち、ほとんどの関数を近似できるパラメータが存在することを知る。
- 存在する解は見つかるのか(過剰パラメータ化)
- 適切なパラメータが存在することが分かったところで、それを発見できるのか。
それは過剰パラメータ化によって発見できると理解できる。
- 適切なパラメータが存在することが分かったところで、それを発見できるのか。
- 見つけた解は汎化するのか(二重降下)
- 過剰パラメータ化によって訓練誤差がほぼ0の地点が見つかるのは良いが、パラメータ数増加に伴って汎化性能が低下する「バイアスバリアンストレードオフ」が起きるのではないかという疑問が生じる。
そこで、バイアスバリアンストレードオフが生じない「二重降下」を確認し、汎化性能が高まる気持ちを理解する。
- 過剰パラメータ化によって訓練誤差がほぼ0の地点が見つかるのは良いが、パラメータ数増加に伴って汎化性能が低下する「バイアスバリアンストレードオフ」が起きるのではないかという疑問が生じる。
- 汎化する解を見つけやすいのは何故多層なのか(近似誤差レート)
- パラメータ数を過剰に増やしても汎化性能を高められるなら、浅いニューラルネットワークでも十分そうな気がするが、何故深い層のニューラルネットワークが必要なのかを考える。
深層学習の表現力
画像認識や機械翻訳にとどまらず、今日の生成AIのような複雑な関数までも表現できてしまうニューラルネットワークには、どれほどの表現力があるのでしょうか。
普遍近似定理
普遍近似定理(Universal Approximation Theorem)は次の事柄を主張しています。
2層以上のニューラルネットワークは、任意の連続関数を任意の精度で近似できる。
ただし、普遍近似定理はあくまでも存在定理であり、十分な大きなサイズのニューラルネットワークには良いパラメータが存在することを言っているだけで、そのパラメータをどのように見つけるかに関しては何も言っていません。すなわち、学習可能性や汎化問題とは分けて考える必要があります。一旦本章ではパラメータを見つける部分には触れず、存在性について確認します。
解説は以下の記事が詳しいです。
完全に理解するには時間がかかりますが、存在しそうなことだけはイメージで掴みましょう。いくつかシンプルな関数の重ね合わせで、シンプルな関数を近似するアニメーションを作りました。直観的な理解としては、ニューラルネットワークの1つの層の幅をどんどん増やせば、重ね合わせられる関数が増えます。そしてその重みをいい感じにすれば、どんな形も描けるというものです[5]。

ステップ関数で2次関数を近似する様子。

ReLU関数で2次関数を近似する様子

ReLU関数で3次関数を近似する様子
数式的なイメージの話をすると、ReLU関数の差を用いればステップ関数のようなものが作れます。

ステップ関数のような関数をReLUから作るイメージ。このようなステップ関数もどきが作れれば、それを組み合わせることで任意の関数が作れそうです。
もちろん、連続関数だけでなく、非連続な関数も近似できます。世の中のデータは非連続的な変化をするものも非常に多いです。
良いパラメータは見つかるのか
前章で良いパラメータが存在することがわかりましたが、それは現実的に見つけることはできるのでしょうか。
パラメータを見つける難しさ
ロジスティック回帰などのシンプルな機械学習モデルでは、損失関数は凸関数(以下の図)であり、勾配を下っていけば必ず最適解が見つかります。

損失関数が凸関数であれば、損失が下がる方向にパラメータを動かしていけば、必ず最適解が見つかります。凸関数(wikipedia)より引用。
一方で、深層学習の損失関数は非常に複雑な構造を持っています。パラメータ数が億を平気で超えるので、損失関数を可視化したり、全貌を把握することは困難ですが、次元圧縮などを駆使することで以下のような可視化がなされたことがあります。

次元圧縮などで可視化された深層学習の損失関数(
見ての通りニューラルネットワークの損失関数の形状は通常、非常に複雑で、初期値の運次第ですが、確率的な揺らぎでいくつかの山を越えて、深い谷を見つけねばならないのです[6]。ロジスティック回帰のような損失関数とは一線を画します。
しかし実際、この確率的勾配降下法は非凸な損失関数であっても、現実的な計算リソースと時間で、実用上申し分ない程良い"谷"を見つけられています。本章では訓練損失を小さくする"谷"を見つけやすくする工夫を紹介します。
損失ランドスケープの平坦性
本節では探索するパラメータ空間の「損失ランドスケープ(loss landscape)」の幾何学的性質に着目します。さまざまな論文で[7]、損失関数の収束先が平坦であるほど、汎化性能が高いと研究されてきました[8]。
直感的な理解としては以下の損失関数の可視化グラフをご覧ください。図左では、損失関数が低くなっているところが平坦であるのに対して、図右では比較的尖っています。

簡単な実験で得た損失関数の可視化グラフ。
直感的な理解としては、損失関数の平坦な領域でパラメータが決まれば、パラメータが変化しても損失は大きく変動しません。このような領域にある解はテストデータというデータの変動にも強いだろうという考えに基づいています。また、ミニバッチサイズとパラメータが収束する領域の関連は以下のように整理できます。
-
ミニバッチサイズが大きいとき: ノイズの少ない安定した勾配を計算するため、損失関数の鋭い"谷底"(Sharp Minima)に真っ直ぐ落ちていく傾向があります。この鋭い"谷"は、訓練データに特化しすぎた(過学習した)解であり、少しデータがずれる(テストデータになる)と損失が急激に悪化するおそれがあります。
-
ミニバッチサイズが小さいとき: 勾配にノイズが含まれるため、このノイズが探索の助けとなり、鋭い谷底に囚われることなく、より幅の広い"平坦な谷底"(Flat Minima)を見つけやすくなります。平坦な領域は、パラメータが多少変化しても損失が安定しているため、未知のデータに対しても頑健で、高い汎化性能を持つと考えられます。
2025年現在、損失関数の平坦性と汎化性能の関連は単純な因果関係(平坦であれば汎化する)とは思われていませんが、深く関わっているとは考えられている、と私は思っています。このように、汎化しやすい解を見つける工夫によって過学習を防ぐという考え方があります。
過剰化したパラメータが損失がほぼ0の地点を見つけてくれる
ある性能を達成するのに必要以上にパラメータを増やすこと(over-parametrization)で、解を見つけやすくする取り組みもあります。いわゆる次元の祝福と言われるものですが、一部のパラメータ更新では損失を下げられなくなっても、他のパラメータを増やすことで下げらる可能性が高まります。すなわち、イメージとしては過剰なパラメータがあれば、パラメータをどんな初期値で始めても、そこから辿り着ける損失がほぼ0の地点が存在し、結果として適切なパラメータを見つけられるという考え方です。
また、Du らの研究によると、過剰パラメータ化したニューラルネットワークに対して勾配降下法を適用すれば、損失関数が非凸目的関数にもかかわらず、訓練損失がほぼ0を達成できることを示しています。損失関数が凸関数であれば勾配降下を繰り返せば必ず損失が最も小さいところに移動できますが、そうでないなら、幸運か膨大な時間をかけなければ見つけられないはずです。この研究のすごいところは、非凸な形をしていても、必ず線形的な時間で損失がほぼ0になる地点が見つかることを示している点です[9]。雰囲気は以下の通りです[10]。
損失を以下のように定義します。
ここで、
-
f(\theta, x_i) x_i -
y_i x_i -
\theta
勾配降下法を適用すると、訓練中の各ステップ(イテレーション)
この式は、次のステップでの残差が、現在の残差に
-
I -
\eta -
G(k) \theta(k)
このグラム行列
そしてこのグラム行列
このグラム行列の安定性は、主に二段階で説明されます。
-
初期化段階での安定性: ランダムに初期化されたネットワークのグラム行列
G(0) K^{(H)} -
訓練中の安定性: 訓練が進むにつれても、グラム行列
G(k) G(0)
この安定性により、残差のダイナミクスは先の式のように近似的に線形に振る舞います。この近似的な線形ダイナミクスにより、訓練損失
論文では、ネットワークの幅
つまり、全体としての損失関数は非凸であっても、過剰パラメータ化によって、勾配降下法による損失の減少は線形システムを最適化しているかのように振る舞うため、全域(グローバル)最小解(= 訓練損失ゼロの点)に到達できるのです[11]。
膨大なパラメータで汎化する矛盾
訓練誤差ゼロを達成する解が無数に存在する中で、なぜ学習アルゴリズムは未知のテストデータに対しても「良い」解を見つけ出すことができるのでしょうか。それを紐解く二重降下に焦点を当てます。
パラメータ数が膨大になると、汎化性能が低下するということは統計の教科書によく書かれており、それはバイアスバリアンストレードオフで説明できます。
本章では、まずバイアスバリアンストレードオフを理解し、その後、それが成り立たない二重降下(Double Descent)が実験的にも、数学的にも成立することを確認し、膨大なパラメータで過学習が起きない理由を知ることを目指します。
バイアス-バリアンストレードオフ
言葉自体は聞いたことがある方は多いと思います。
概要
機械学習において、モデルの予測誤差はバイアス、バリアンス、ノイズの3つの成分に分解できます。ノイズは、データに含まれる不確実性であり、根本的に削除不可能な誤差であるため、今回はノイズなしで説明します。その上で、バイアスとバリアンスに分解することをバイアスバリアンス分解と呼びます。これはモデルの性能を理解する上で重要な概念で、以下のようなイメージです。
ここで、バイアス(Bias) とは、真の関数
左から順に、バイアスが高い状態、バリアンスが高い状態、バランスをとっている状態を作図しました。

簡単な多項式回帰での例です。薄い近似曲線はリサンプリングごとのモデル曲線を表します。
この図の内容を整理すると以下の通りです。
| 状態 | モデルの複雑さと特徴 | 訓練誤差 | テスト誤差 |
|---|---|---|---|
| 高いバイアス (Underfitting) | モデルが単純すぎて、データの特徴を捉えきれていない。 | 高い | 高い |
| 高いバリアンス (Overfitting) | モデルが複雑すぎて、データのノイズまで学習してしまっている。 | 低い | 高い |
| バランスが良い (Good Fit) | モデルの複雑さが適切で、データの主要な特徴を捉えられている。 | 低い | 低い |
理解のポイントとしては、異なるデータセットで何度も推定した時、バリアンスが高い状態だとモデルが安定せず、大きく異なるモデルを推定してしまいます。図上段(左)と(中)の薄い近似曲線を見比べると、モデルのばらつきが(中)の方が大きいことが見て取れます。これこそが、バリアンス(モデルのばらつき)が大きい状態と理解できるポイントです。
二重降下(Double Descent)
二重降下(Double Descent)とは、先のバイアスバリアントレードオフが崩れるという衝撃的な内容です。

二重降下を表した図です。左(a)は古典的なパラメータ数が比較的少ないモデルでの挙動を表し、右(b)はモダンな大量のパラメータを持つモデルでの挙動です。横軸がモデルの表現力(すなわちパラメータ数)で、縦軸がテストデータに対する予測誤差のようなものを表しています。左(a)では、従来のバイアスバリアンストレードオフのように、序盤パラメータ数が増えるにつれて性能が向上しますが、パラメータが学習データを完全に覚えられるくらいになると、汎化性能が低下(バリアンスが上がる)して、U字の形をとります。一方、右(b)では、序盤こそ(a)と同様にU字型を描きますが、その後もパラメータ数を増やし続ければ汎化性能が高まるという2段階の誤差現象(Double Descent)が観測されます。Reconciling modern machine learning practice and the bias-variance trade-off Figure1 より引用。
パラメータ数がデータ点数よりもはるかに大きい場合(過剰パラメータ化の領域)に、予測性能(汎化性能)が向上するという、従来の統計学の常識に反する Double Descent は単なる経験則だけではなく、高次元の線形回帰モデルにおいて、数式を用いて定量的に説明できます。詳細を書くとそれだけで1つの記事になる勢いなので、ごくごくかいつまんで説明します。
1. 汎化性能(予測リスク)の定義と分解
まず、モデルの汎化性能は「予測リスク(prediction risk)」
予測リスクは、以下の式で定義されます。
この予測リスクは、統計学でよく知られているように、バイアス(Bias) と バリアンス(Variance) の2つの成分に分解できます。
これらの式展開の詳細
予測リスクの式展開
ベクトル
ノーテーションとして、
が得られます。
バイアスバリアンス分解
まずは
元の式に代入して展開します。
ここで、
-
バイアス項
||E[\hat{\beta}|X] - \beta||^2_{\Sigma} \beta -
バリアンス項
\text{Tr}[\text{Cov}(\hat{\beta}|X)\Sigma]
2. リッジレス最小二乗推定器のバイアスとバリアンス
特に深層学習モデルで広く用いられる「データを完全に補間する(訓練誤差がゼロになる)」モデルの性質を捉えるため、最小2乗ノルム("ridgeless")最小二乗補間を対象とします。これは、多数の解が存在する過剰パラメータ下での状況 (
先のバイアス
-
バイアス:
B_X(\hat{\beta};\beta)=\beta^T \Pi \Sigma \Pi \beta -
バリアンス:
V_X(\hat{\beta};\beta)= \sigma^2/n \text{Tr}[\hat{\Sigma}^+ \hat{\Sigma}]
ここで
この式の意味を雰囲気で理解する
論文中では、
バイアス
線形回帰のパラメータ推定は、不偏推定量で以下のように与えられます[14]。
ここで、逆行列の部分を一般化逆行列に置き換えると、
となります。よって、
ただし、
バリアンス
まず、
ここで、ノイズの共分散は
ムーア-ペルローズの一般化逆行列の性質
となります。これをバリアンス項
が得られます。一方、本文で示されている最終的なバリアンスの式は
本文の表記
この結果と、我々が導出した
これは高次元の解析ではしばしば用いられる設定であり、この仮定を置くことで、バリアンス項がより簡潔な形で表現できるのです。
バイアスの見方に関する補足
-
p < n
-
p > n
3. 過剰パラメータ化における予測リスクの変化
ここまでは前座で、ここが肝です。パラメータ数
まず、
-
r^2 = ||\beta||^2_2 \gamma = p/n \gamma > 1
とします。
先の項で、バイアス項は
が得られ、この式からバイアス項とバリアンス項の挙動を個別に分析できます。
いきなり現れた漸近的な予測リスク
バイアス項 r^2 (1 - 1/ \gamma)
直感的な理解としては、
同じことを言っていますがもう少し言い換えると、モデルが非常に複雑になり、
バリアンス項 \sigma^2 / (\gamma - 1)
この現象は、パラメータが多くなればいろんな方法で訓練データ点を全て通る予測曲線を引けるようになるイメージを持っている方からすると、直感に反するように思えますが、次のように説明できます。
以上をもって、等方性特徴量モデルのシンプルな線形回帰のケースにおいて、予測リスクが
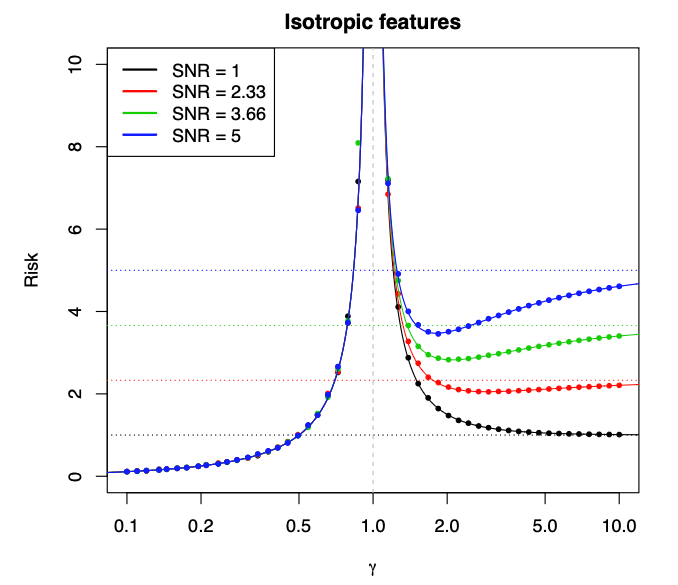
Figure 2 より引用。
ここでは設定がシンプルすぎるため、
潜在空間モデルの場合の二重降下
このモデルの基本的な設定は以下の通りです。
-
y_i \in \mathbb{R} i -
z_i \in \mathbb{R}^d i -
\theta \in \mathbb{R}^d z_i y_i z_i -
\xi_i \sim N(0, \sigma_\xi^2) y_i \sigma_\xi^2 -
x_{ij} i x_i \in \mathbb{R}^p j -
w_j \in \mathbb{R}^d j x_{ij} z_i w_j^T W j x_{ij} W j z_i -
u_{ij} \sim N(0, 1) x_{ij}
このモデルでは、データは低次元の潜在空間 (
この時の予測リスクの極限の導出も非常に大変なので割愛しますが、以下のような複雑な式になります(Surprises in High-Dimensional Ridgeless Least Squares Interpolation
Corollary 4. より)。
その結果、潜在空モデルでは

Surprises in High-Dimensional Ridgeless Least Squares Interpolation
Figure 6 より引用。
これは一部私の解釈ですが、潜在空間モデルのような状況下では、以下の2つの事柄を考えられます。
過剰パラメータにおける予測リスクの単調減少の直感的理解
今回の設定は各特徴量ベクトル
正則化パラメータ \lambda \rightarrow 0
大規模な過剰パラメータ化において、最適な正則化パラメータ[16]の値は
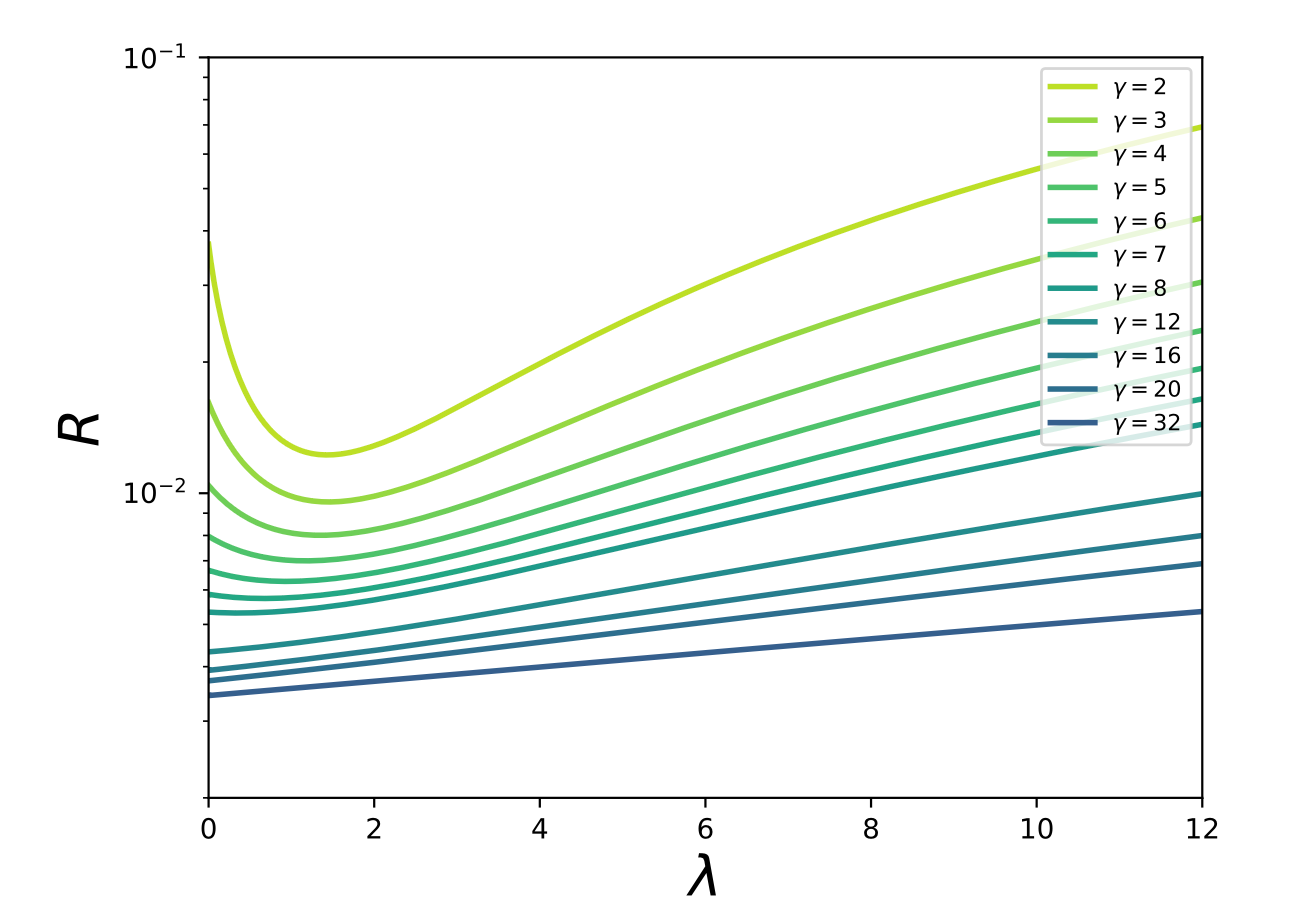
学習パラメータが増えるにつれて(パラメータ数と訓練データ数の比率を表している色に注目です)、最適な正則化パラメータ
Figure 10 より引用。
この現象は、モデルに入力ノイズが本質的に含まれている場合に、そのノイズが追加の正則化項として機能するという考え方で説明されます。特徴量行列
ただし、この暗黙的正則化の考え方は近年懐疑的な目で見られています。例えば Nagarajanらの研究では、暗黙的正則化だけでは過剰パラメータ化されたニューラルネットワークの優れた汎化性能を説明できないとしています。

左から2番目の図では、訓練データが増えるほど重みパラメータの2乗ノルムが増加している様子を表しています。暗黙的正則化が効くのであれば(左から3番目のようにテスト誤差が下がっている状況)、重みパラメータのノルムは0に近づくはずですが、そうはなっていない例です。Deep Double Descent: Where Bigger Models and More Data Hurt Figure 1より引用。Uniform convergence may be unable to explain generalization in deep learning Figure 1 より引用。
多層ニューラルネットワークでの二重降下
浅い層を持つリッジレス回帰だけでなく、深い層を持つモデルでも二重降下は現象として観測されています。例えば以下の図のように、ResNet18 のような多層ニューラルネットワークでもパラメータ数を増やし続けた時に二重降下が確認されています。

Deep Double Descent: Where Bigger Models and More Data Hurt Figure 1より引用。
学習データを増やすと性能が悪化する?
二重降下の考え方を思い出すと、パラメータ数とデータ数の比率で、パラメータ数が膨大になることで予測リスクがもう一度下がるとのことでした。したがって、同じパラメータ数であれば、データ数が増えることで汎化性能が悪くなる領域に戻ってしまうことも起きてしまいます。この現象は、多層ニューラルネットワークの世界においてはEMC(Effective Model Complexity)で説明されます(先の線形回帰の例での
EMCは、様々な深層学習のタスクで見られる二重降下を統一的に説明することを目指して定義された指標です(が、経験的指標で、タスク依存性があることには注意です)。詳細はこの論文です。
訓練手順
と表されます。ここで、
EMC が訓練サンプルの数
| 領域 (Region) | 条件 | モデルや訓練手順を複雑にした時のテスト誤差の変化 |
|---|---|---|
|
過少パラメータ化領域 Under-paremeterized regime |
減少する | |
|
過剰パラメータ化領域 Over-parameterized regime |
減少する | |
|
臨界パラメータ化領域 Critically parameterized regime |
増加または減少 |
EMC の導入により、モデルパラメータ数以外でも生じる二重降下を説明できるようになりました。
- エポックごとの二重降下(モデルが固定されていても、訓練時間を増やすことで EMC が増加し、テスト性能が二重降下する)
- サンプル数の非単調性(訓練サンプルを増やすことで、データ数が EMC と近くなるポイント(テスト誤差がピークに達するところ)が右にシフトする効果と、誤差全体を下に下げる効果)

図左(a)は、は5層 CNN の、データセットサイズを変えた場合のモデルごとの二重降下を表します。上側は2倍のサンプル数で訓練してもテスト誤差が改善されないモデルサイズの範囲(緑色の網掛け)が生じます。下側は4倍のサンプル数で学習してもテスト誤差が改善されないモデルサイズの範囲(赤で網掛け)があります。図右(b)は、サンプル数が多いほど性能が低下する領域があることを示しています。Deep Double Descent: Where Bigger Models and More Data Hurt Figure 11 より引用。
二重降下(Double Descent)のまとめ
- 単純な線形回帰モデルでも、予測リスクが補間境界 (
p=n - バリアンスがパラメータ数の増加とともに減少するという直感に反する現象が、L2ノルムが最小化される特性によって説明できる。
- この線形モデルから得られる知見は、非線形で複雑なニューラルネットワークにも適用できる可能性が示唆されており、実験的にその現象は確認されています。
(参考)三重降下(Triple Descent / Multiple Descent)
異なるランダム特徴を組み合わせて予測を行うアンサンブルモデルにおいて、一定の条件の元、3回以上の予測リスク降下も確認されています(あくまでも参考資料)。
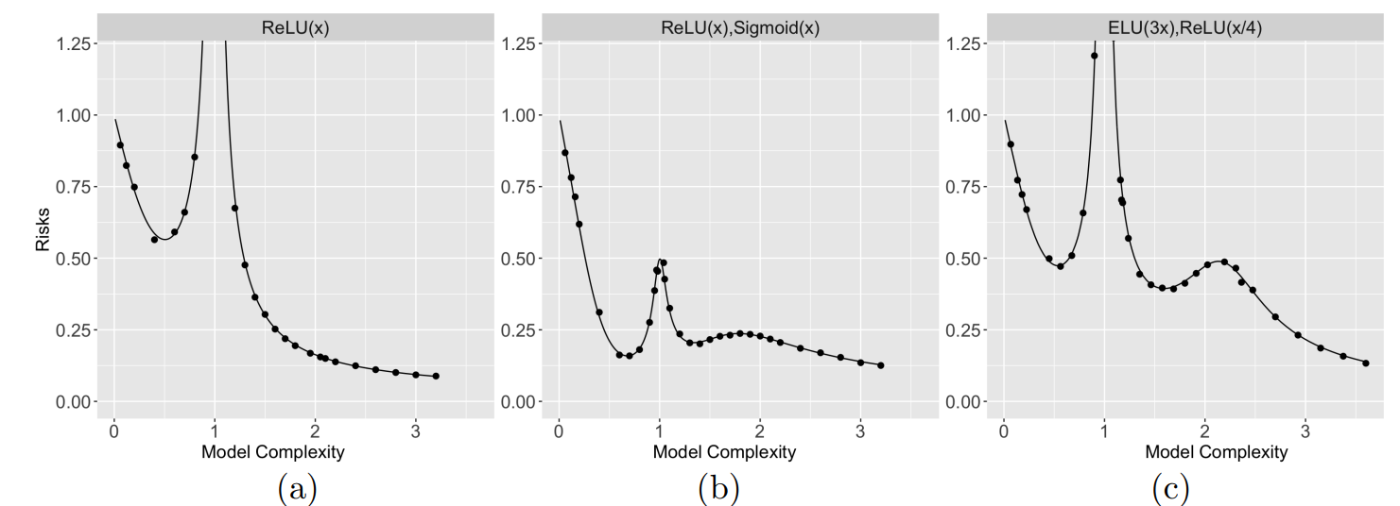
三重降下。Multiple Descent in the Multiple Random Feature Model Figure1 より引用。
スケーリング則
話の本筋からは外れてしまいますが、スケーリング則に触れないわけにもいかないという気持ちがあり、ちょっとだけ脱線します。
二重降下では「モデルがある規模を超えると一度性能が悪化し、その先でまた良くなる」という非単調性を見てきました。しかし実務では どこまでモデルを大きく、長く訓練するのが望ましいかを定量的に決めたい場面があります。
そこで近年は Neural Scaling Laws(NSL)という経験則が大規模実験と理論の両面から整備されつつあります。
パラメータ数とデータ数は別々に効く
言語モデルを対象とした Kaplan らの研究では、モデルサイズ
ここで、
さらにこれらを組み合わせて、モデルサイズ
このことから、指数の
Chinchilla 則
Hoffmann らの研究 は 70M〜70B パラメータ、5B〜500B トークンのモデルを 400 個以上訓練し、
- 同じ FLOPS[17] なら
N D - 実際に
N=70B, D=1.4T N=280B, D=300B
ことを実証しました。これは訓練データサイズ数より過剰なパラメータ数という状況になっていませんが、計算資源に見合っていない過剰パラメータ下ではモデルの潜在能力を引き出せていない状況になることを主張しています。
多層化の謎
これまでの章で、過剰パラメータ下において汎化するパラメータが見つかりそうな兆しは見えてきました。しかし、今までの議論では、1層あたりに大量のパラメータを持たせて、2~3層で構成する方法もあり得るはずです。一方で深層学習の進化の歴史は、AlexNet の8層から始まり、ResNet では数十~数百、現在では1000層を超えるモデルすら登場するなど、深層化の歴史と言えます。本章ではこの深層化の不思議を効率性の観点で説明していきます。
階層的合成による表現効率の良さ
定性的な説明
浅いネットワークと深いネットワークの最大の違いは、関数の作り方にあり、深いネットワークは複雑な関数を表現する際の効率が良いです(少ないパラメータで表現できます)。
浅いネットワークでは、幅を広げることで表現力を高めます。1つの隠れ層にニューロンをたくさん並べ、それらを足し合わせることで関数を表現します。これは、たくさんの単純な関数を並べて(例えば、記事前半で確認したReLU関数の重ね合わせの可視化)、目標の関数を少しずつ組み立てていくイメージです。これによって表現できる関数の複雑さを加算的に増大させられます。
深いネットワークでは、層を重ねることで表現力を高めます。層を1つ重ねることは、数学的には関数を1つ合成することに対応します。つまり、
この深いネットワーク特有の関数の合成という構造は、現実世界の問題を解く上で非常に有利に働きます。例えば、画像認識では、ピクセルがエッジを形成し、エッジが形を、形が物体を構成します。深い層を持つニューラルネットワークは、これらの中間的な特徴を各層で学習し、後の層で再利用することができます。この特徴の再利用こそが、深い層を持つニューラルネットワークが高い表現効率を達成できる理由の1つです。
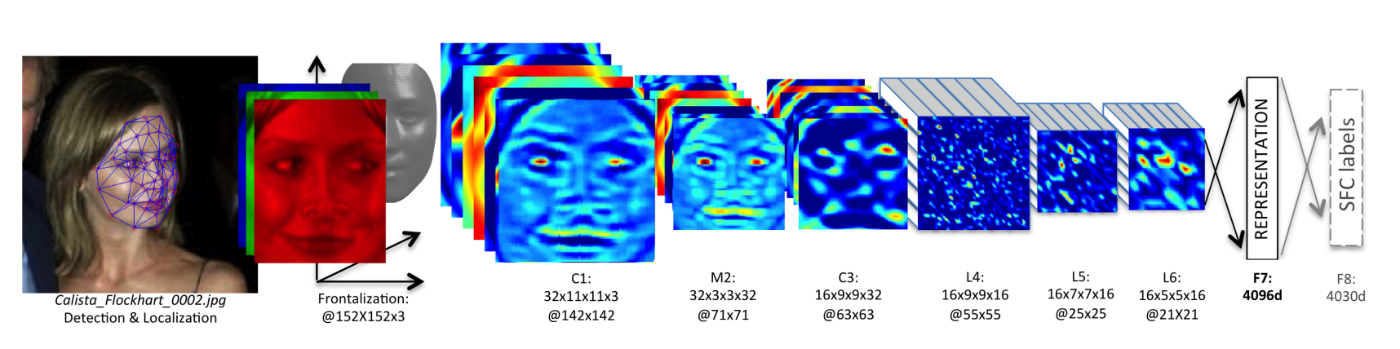
ニューラルネットワークの前半で特徴量を抽出している様子を表しています。DeepFace: Closing the Gap to Human-Level Performance in Face Verification Figure2 より引用。
数学による説明
この表現効率は数学的にも示されています。Benefits of depth in neural networks によると、
漸近記法について
見る人が見ると怒られるような書き方をしていますが、本記事のモットーは雰囲気を理解することなので、雰囲気で書いてます。形式的な定義は Wikipedia をご覧ください。
-
\Theta -
O -
o -
\Omega
この主張の気持ちは、
- 層の数が少ないニューラルネットワークは表現できる振動の数が少ない
- 層の数が多いニューラルネットワークは多くの振動を表現できる
- 振動の数が少ない関数は振動の数が多い関数を近似できない
よって、層の深いニューラルネットワークは複雑な(振動の数が多い)関数を、層の浅いニューラルネットワークに比べて、はるかに近似しやすいのです。
深層化によって振動が増えることを掴むために、以下のような関数
(
これは以下の図のように、三角波のような形をしています(右下のstep.6で三角波になっています)。
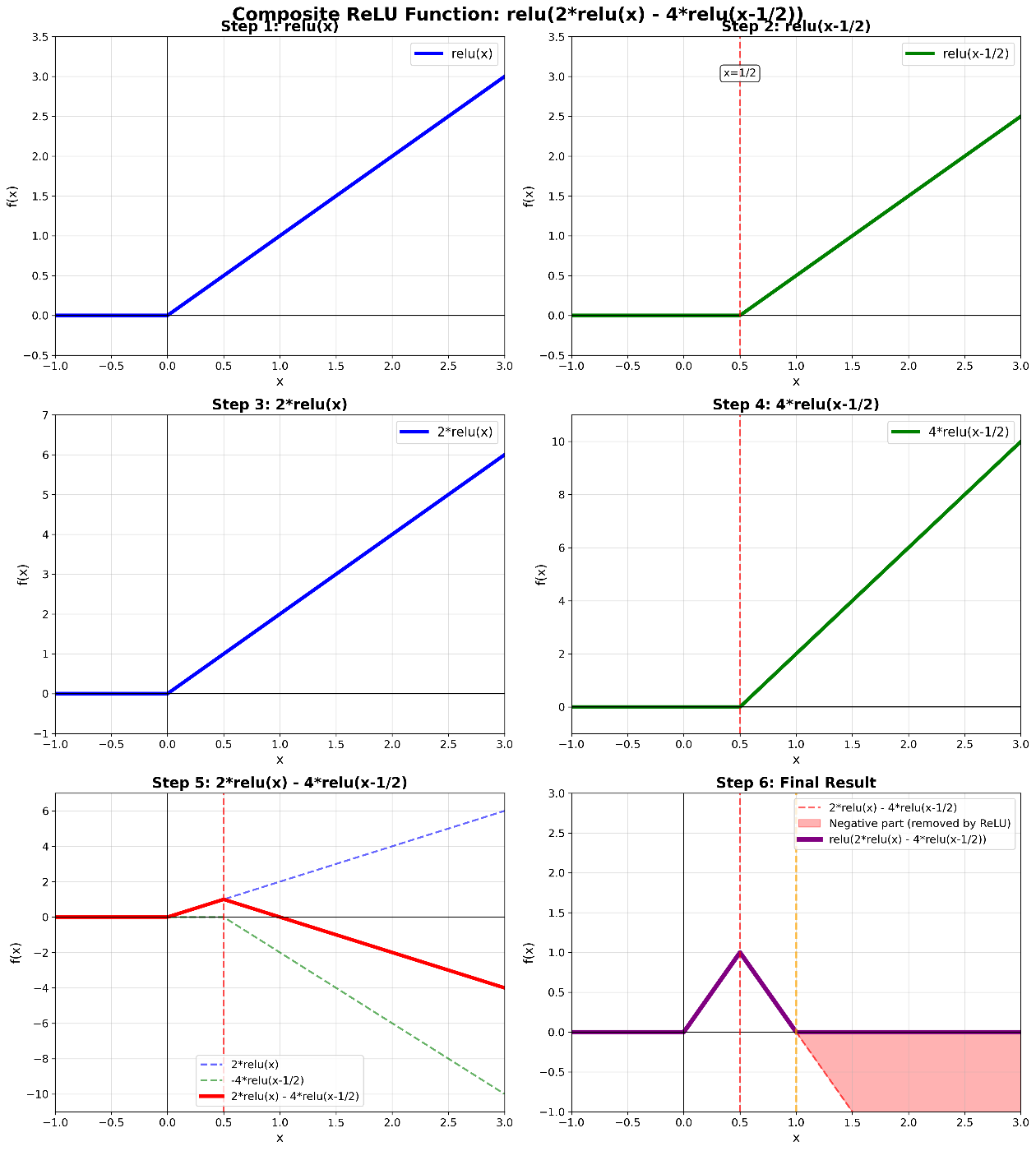
この関数は定数個のパラメータで表現できるので、1層、
深いニューラルネットワークの事情
この関数

浅いニューラルネットワークの事情
関数の振動をある閾値を跨ぐ回数として定義します。
浅いニューラルネットワークでは、関数
そして、1つの層で次数を増やすことは容易ではありません。同じ層内でノードを増やすことは、関数の足し算(または線形結合)に対応します。1つの層のノードを増やすような操作、すなわち2つの多項式を足し合わせると、結果として得られる多項式は、せいぜい項の数が2倍になり、多項式次数はどちらかの最大次数を超えることはありません。こういうわけで、振動数に寄与する項(
高い振動数(多くの折れ曲がり)を効率的に得るには、これらの区分的線形関数をさらに重ねて合成することが必要であり、「深さ」には到底及ばないのです。
まとめ
ニューラルネットワークが作れる振動の数
その関係性は層の数
私の感想ですが、深層学習の真髄は普遍近似定理ではなく、深層学習が持つアーキテクチャにあると思います。多層化されたニューラルネットワークによる合成的構造は、強力な帰納バイアス[22]として機能しており、現実世界で頻繁に見られる階層的または合成的な構造を持つ関数の学習に適しています。深層学習のアーキテクチャ自体が、合成性を活用する解へと学習を誘導する一種の事前知識なのです。
近似誤差レートの改善
近似誤差レート(Approximation Error Rate)の観点でも考えてみましょう。先の表現効率の良さの話と雰囲気が似ているため、この節は簡単めな紹介にとどめます。
近似誤差レートとは、ニューラルネットワークがある関数を近似する際、パラメータを増やしたときの誤差の減少率を表します。
で表されます(
滑らかな関数の近似
まず、近似したい関数
滑らかではない関数の近似
例えば画像のエッジ部分のような不連続な点や、音声波形のように尖った点を持つ関数は滑らかではありません。不連続な点や尖った点を表現するためには、その点の周辺に非常に多くのパラメータを集中させる必要があり、パラメータ効率が著しく低下します。この場合、近似誤差レートは入力特徴量次元
しかし、(ReLU を活性化関数に持つ)深いニューラルネットワークは、前の節で見たように、層を重ねることで効率的に「折れ曲がり」を作り出し、滑らかでない関数の特異点[24]を捉えて、近似誤差レートを改善すると示されました。
非均一な滑らかさを持つ関数の近似
最後に、非均一な滑らかさ(non-uniform smoothness)を持つ関数の近似を考えます。関数の大部分は非常に滑らかなのに、一部分だけが急激に変化したり、複雑な構造を持っていたりするような関数です。例えば、背景がぼやけた写真の中の、ピントが合った人物の輪郭などがこれにあたります。
深いネットワークはその階層構造を活かして、関数の場所ごとの滑らかさに応じてリソース(パラメータ)を効率的に配分できます。この「適応性」のおかげで、深いネットワークは非均一な滑らかさを持つ複雑な関数に対しても、高い近似誤差レートを維持できるのです。

深いニューラルネットワークは局所的に滑らかさを変えられます。深層学習の汎化誤差のための近似性能と複雑性解析 スライドp.14より引用。
結び
Zenn の記事にはアイキャッチ絵文字を設定できます。毎度毎度どの絵文字にしようか腐心するのですが、今回は「Deep Learningといえばイルカ!」[25]ということで即断即決でした。多くの実務ですぐには役に立ちにくい話題でしたが、この手の話題は勉強していてとても楽しいですね。くどいようですが、誤りなどがございましたらコメント欄やXなどでご指摘いただけますと幸いです。
なお、本記事で引用元が明記されていない図やアニメーションは、Claude Code に筆者が指示して生成したPythonスクリプトから作ったものです。ソースコードの妥当性は筆者が目視で確認しています。
本記事のまとめ
- ニューラルネットワークはどんな関数も近似する強力な表現力を持つ(普遍近似定理)
- そして、過剰パラメータ化された状況で学習方法やモデルを工夫すれば、訓練誤差がほぼ0の"谷"を見つけることができる
- 過剰パラメータ化によって汎化する現象二重降下は、一部数学的にも経験的にも確認されている
- 多層化によって表現力が指数関数的に増加し、それは近似誤差レートの観点からも説明できる
参考文献
- A Survey on Universal Approximation Theorems, Midhun T Augustine, 2024.
- Benefits of depth in neural networks, Matus Telgarsky, 2016.
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification, Yaniv Taigman, et al., 2014.
- Reconciling modern machine learning practice and the bias-variance trade-off, Mikhail Belkin, et al., 2018.
-
Surprises in High-Dimensional Ridgeless Least Squares Interpolation
, Trevor Hastie, et al., 2019. - Deep Double Descent: Where Bigger Models and More Data Hurt Preetum Nakkiran, et al., 2019.
- Visualizing the Loss Landscape of Neural Nets, Hao Li, et al., 2017.
- On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima, Shirish Keskar et al., 2016.
- Fantastic Generalization Measures and Where to Find Them, Yiding Jiang et al., 2019.
-
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
, Jonathan Frankle, et al., 2018. - Gradient Descent Finds Global Minima of Deep Neural Networks, Simon S. Du, et al., 2018.
- Universal approximation bounds for superpositions of a sigmoidal function, Andrew R. Barron, 1993.
- Error bounds for approximations with deep ReLU networks, Dmitry Yarotsky, 2017.
- Multiple Descent in the Multiple Random Feature Model, Xuran Meng, et al., 2024.
- Training Compute-Optimal Large Language Models, Jordan Hoffmann, et al., 2022.
- Scaling Laws for Neural Language Models, Jared Kaplan, et al., 2023.
- Uniform convergence may be unable to explain generalization in deep learning, Vaishnavh Nagarajan, J. Zico Kolter, 2019.
- 深層学習の原理に迫る, 今泉 允聡, 岩波書店, 2021.
-
実際、Gmini2.5 pro とChatGPT o3 Pro でResearchしても達しなかったと感じたので、あれこれ調べながらこの記事を書きました。 ↩︎
-
ラベルの異なる点が重なっていたら分離できない、という突っ込みは一旦なしでお願いします。 ↩︎
-
パラメータ数とデータ数の関係はそれほど単純ではなく、帰納バイアスなども関わってきます。あくまでも雰囲気の話をします。 ↩︎
-
Universal Approximation Theorem. 万能近似定理と訳されることもあります。 ↩︎
-
フーリエ変換やテイラー展開のようなイメージを私は持っています。 ↩︎
-
ここまで興味を持って読んでくださった方であれば、深層学習は確率的勾配降下法によってパラメータ空間を探索していることはご存知のはずです。 ↩︎
-
[On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima(https://arxiv.org/abs/1609.04836) やFantastic Generalization Measures and Where to Find Them
] ↩︎ -
ただし、完全に相関するわけではなく、逆の相関を示すケースも報告されています。 ↩︎
-
いくつかの前提条件がある点には注意です。 ↩︎
-
厳密な証明は追いきれませんでした。 ↩︎
-
論文中では特に、残差接続を持つ ResNet アーキテクチャは、一般的な全結合型ニューラルネットワークと比較して、必要な幅
m H -
p n -
\hat{\Sigma}^+ -
この推定量の導出はお手元の統計の教科書をご確認ください。 ↩︎
-
訓練データは
p n n -
これはハイパーパラメータです。 ↩︎
-
1秒間に浮動小数点演算が何回できるかの指標値です。 ↩︎
-
Gemini 登場以前の DeepMind 製の大規模言語モデルです。 ↩︎
-
Gemini 登場以前の DeepMind 製の大規模言語モデルです。 ↩︎
-
論文中では、ある閾値を跨ぐ回数で定義しています。 ↩︎
-
言い換えです。個々のReLUゲートは入力空間に1つの「折れ曲がり」を導入しますが、1つの層で多くのReLUゲートを線形結合しても、その結果は区分的線形関数であり、折れ曲がりの数はノード数に比例してしか増えません。 ↩︎
-
機械学習モデルが持っている仮定や構造のことです。ボールを投げた時の軌跡を予測する際、二次関数を用いることでデータに寄らない精度改善が見込めますが、これは立派な帰納バイアスです。Wikipediaも参照してください。 ↩︎
-
無限回微分できるくらいの理解です。 ↩︎
-
不連続点や尖った点のことです。 ↩︎
Discussion