Go 向けの Lexer Generator を自作してみた
はじめに
Go 向けの Lexer Generator を作成してみました。
flex 風の設定ファイルに書かれた正規表現から決定性オートマトン(DFA) を生成し、作った DFA を元にした Lexer のコードを自動生成します。
以下は設定ファイル・入力文字列・出力の例です。
設定
%%
if|for|while|func|return { return Keyword, nil }
int|float64 { return Type, nil }
[a-zA-Z][a-zA-Z0-9]* { return Identifier, nil }
[1-9][0-9]* { return Digit, nil }
[ \t\n\r]* { }
"(" { return LParen, nil }
")" { return RParen, nil }
"{" { return LBracket, nil }
"}" { return RBracket, nil }
"+" { return Operator, nil }
"-" { return Operator, nil }
"*" { return Operator, nil }
"/" { return Operator, nil }
":=" { return Operator, nil }
"==" { return Operator, nil }
"!=" { return Operator, nil }
[ぁ-ゔ]* { return Hiragana, nil }
. {}
%%
入力文字列
func foo123barあいう () int {
x := 1 * 10 + 123 - 1000 / 5432
y := float64(x)
return x + y
}
出力 Tokens
Keyword
"func"
Identifier
"foo123bar"
Hiragana
"あいう"
LParen
"("
RParen
")"
Type
"int"
...
車輪の再発明のなかでも Lexer Generator 自作はマイナーな分野なのか情報が少なくて実装に苦労したので、この記事では私の備忘録を兼ねてどう実装したのかについて軽く紹介します。
なぜ作ったか
私が調べた限りでは、現在日本語で読める自作 Lexer Generator に関する記事は PNF の2019年のブログ記事くらいなのではないかと思います。それより前だと2017年に Julia の Automata.jl の記事が Qiita にありましたが現在は消されています[1]。
世界に目を向けても1年間で Lexer Generator 自作に取り組む人は数人くらいなのでは?とさえ思えるくらいマイナーな Lexer Generator 自作をなぜやったのかというと以下のようなモチベーションで作りました。
- 日頃から protocol buffer や sqlc などコードの自動生成ツールを使用していて、自分でもコードの自動生成を試してみたくなった
- SQLite 風の RDBMS を作ろうと思い立ったが、ふと SQLite は lexer generator, parser generator も自作していることを思い出し(のちに間違いと気づく)、じゃあ自分でも作ってみるかという気分になった
- SQLite は parser generator は自作の Lemon というのを使っていましたが、lexer(tokenizer) は hand-coded だったので勘違いがありました
ちなみに、上記でいう SQLite 風の RDBMS とはシカゴ大学の chidb のことでこれを Go に移植しようと考えていました。chidb は lex/yacc を使っていますが、SQLite だし gererator も自作するかと思い立ち今に至ります。
実装
今回作成した lexer generator は以下のような流れで lexer を生成します。

正規表現 -> AST
まず正規表現を parse して AST を構築します。
正規表現の定義通り literal character, concatenation, alternation, Kleene star, 加えて優先順位を表す () にのみ対応すると割り切ると parse の仕方は四則演算のそれとほぼ一緒です。
- literal character <-> 数字
- concatenation <->
\times - alternation <->
+ - Kleene star <->
^(指数)
という対応付けをすれば、四則演算の parser とほぼ同じことが分かると思います。
私の場合は、下のような BNF を書いてから、再帰下降 parser を作りました。
Alter ::= Concat '|' Alter
| Concat
Concat ::= Star Concat
| Star
Star ::= Primary '*'
| Primary
Primary ::= Group
| symbol
Group ::= '(' Alter ')'
AST -> NFA
AST ができたら葉の方から NFA に変換していき、最終的に1個の NFA を構築します。
NFA の持ち方としては以下のようにつくりました。
type StateID int
type Set [T]map[T]struct{}
type NFA struct {
states Set[StateID] // NFA に含まれる全状態の id の集合
etrans map[StateID]Set[StateID] // key: 始点となる状態の id, val: ε-closure
trans map[StateID]map[rune]Set[StateID] // 状態 i にいるときに、文字 x が入力されたときの遷移先
initStates Set[StateID] // 開始状態の集合。NFA の開始状態を1つとするか複数とするかは流儀があるようですが、ここでは複数としています
finStates Set[StateID] // 終了状態の集合
}
literal character の場合
開始状態・終了状態をそれぞれ1つずつ作り、該当する文字での遷移を作ります
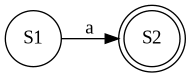
NFA{
states: Set[StateID]{1: struct{}{}, 2: struct{}{}},
etrans: map[StateID]Set[StateID]{},
trans: map[StateID]map[rune]Set[StateID]{
1: map[rune]Set[StateID]{
'a': Set[StateID]{2: struct{}{}},
},
},
initStates: Set[StateID]{1: struct{}{}},
finStates: Set[StateID]{2: struct{}{}},
}
alternation の場合
2つの NFA のうち、片方の中身をもう片方にコピーしてくればよいです。このとき StateID が衝突しないように、StateID を振るときは global unique になるようにしました。
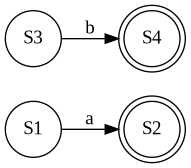
func (nfa NFA) Alter(other NFA) NFA {
for k, v := range other.states {
nfa.states[k] = v
}
for k, v := range other.etrans {
nfa.etrans[k] = v
}
for k, v := range other.trans {
nfa.trans[k] = v
}
for k, v := range other.initStates {
nfa.initStates[k] = v
}
for k, v := range other.finStates {
nfa.finStates[k] = v
}
return nfa
}
concatenation の場合
正規表現

func (nfa *NFA) Concat(other NFA) NFA {
for k, v := range other.states {
nfa.states[k] = v
}
for k, v := range other.etrans {
nfa.etrans[k] = v
}
for k, v := range other.trans {
nfa.trans[k] = v
}
for s := range nfa.finStates {
for f := range nfa.initStates {
nfa.etrans[s] = f
}
}
nfa.finStates = other.finStates
return *nfa
}
Kleene star の場合
新しい状態
この
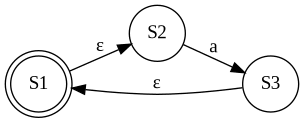
func (nfa *NFA) Star(other NFA) NFA {
newID = NewID() // global unique な id を生成する
for i := range nfa.initStates {
nfa.etrans[newID] = i
}
for f := range nfa.finStates {
nfa.etrans[f] = newID
}
nfa.initStates = Set[StateID]{newID: struct{}{}}
nfa.finStates = Set[StateID]{newID: struct{}{}}
return *nfa
}
NFA -> DFA
正規表現から NFA を作成するところまでは、Lexer Generator 用に特化した処理はありません。
問題は NFA -> DFA 変換からで、ここでは Lexer Generator のための DFA を作る必要があります。
正規表現の優先順位
「ための」とはどういうことか説明するために、例として次のように3つの正規表現 a, ab, a*bb* が Lexer Generator の設定ファイルに書かれていたとします。
a { action 1 }
ab { action 2 }
a*bb* { action 3 }
ここで ab が入力として与えられたとします。Lexer Generator は最長マッチするパターンを採用するためここでは ab, a*bb* が候補になります。最長マッチするパターンが複数ある場合、より先に書かれているパターンを採用するため最終的に ab の action である action 2 を実行します。
問題は ab, a*bb* のどちらにマッチしたかを区別しなければならないということです。
単純に a|ab|a*bb* から NFA を作って DFA に変換するとこの区別ができなくなってしまいます。そのため終了状態がどのパターンに対応するのかという情報が必要になります。
私の実装ですと終了状態がどの正規表現由来かを区別するために、終了状態の ID とどの正規表現由来かを表す ID (regex id)を対応付ける map を NFA の field としてもたせました。このとき regex id は最初に定義されている regex を 1 とし連番で振っています。
type NFA struct {
...
stateIDToRegexID map[StateID]RegexID
}
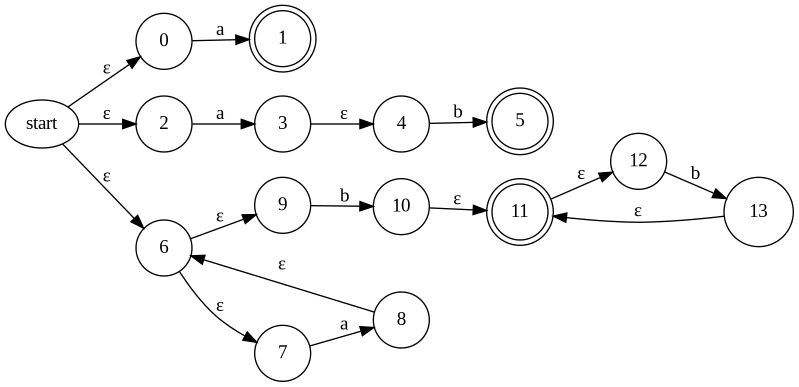
先に上げた正規表現 a, ab, a*bb* からは上図の NFA が生成されますが、このとき a 由来の場合は regex id = 1, ab 由来の場合は regex id = 2, a*bb* 由来の場合は regex id = 3 としているので
stateIDToRegexID: map[StateID]RegexID{
1: 1,
5: 2,
11: 3,
}
となっています。
上記の下準備をしたあとに subset construction をすると下図のような DFA が得られます。
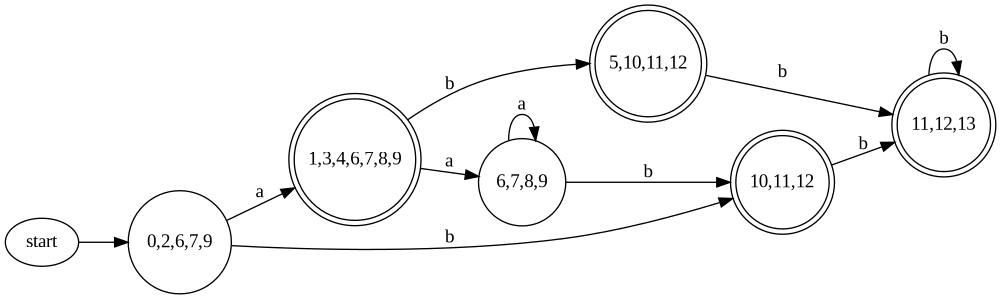
ここで状態の中に書いてある数字は元の NFA の状態の id です。元の NFA で終了状態だったものを含む DFA の状態は終了状態になります。ここで 5, 10, 11, 12 の状態は正規表現 ab 由来の 5 と、a*bb* 由来の 11 の2つを含みます。先に書いたようにこの状態は ab の正規表現にマッチしたと判定したいので、状態 5, 10, 11, 12 は regexID = 2 として情報を保存します。
regex id を選択する処理は具体的には次のような実装にしました。
regexID = RegexID(math.MaxInt)
for s := range dfaState { // dfaState = {5, 10, 11, 12}
if nfa.finStates.Contains(s) {
regexID = Min(regexID, nfa.stateIDToRegexID[s])
}
}
優先順位の高い正規表現のパターンは、より小さい regex id を持っているので、終了状態に振られている regex id のうち最小のものを採用するようにしています。
集合の集合をもつ
さて、サラッと subset construction すると書きましたが、これをするためにはデータの持ち方を工夫する必要があります。
subset construction ではある subset から別の subset を探して、その subset からまた別の subset を探して・・・と繰り返し、新しい subset が見つからなくなったら停止しますが、停止するためには今見つけた subset がすでに探索済みの subset か、はたまた新しいものなのかの判定が必要になります。この判定を高速に行いたいので気持ちとしては「集合の集合」のデータ構造が欲しくなります。
プログラミング言語によっては集合型のなかに集合型をつめることができますが、Go の場合そもそも集合型がありません。map[T]struct{} のようにして集合型を表すというやり方もあるので、気持ちとしては map[map[T]struct{}]struct{} という構造を作りたいですが、map の key に map を入れることはできないのでこの方法では集合の集合を作ることはできません。slice を map の key にすることも考えましたが、slice も map の key とすることはできませんでした。一方で array であれば map の key として使うことができます。
そこで私の場合は次のようにして集合の集合を表現しました。
type Bitset {
length int
data []byte
}
type SetOfSet {
mp map[[sha256.Size]byte]Bitset
}
func (s SetOfSet) Insert(bs Bitset) {
sha := sha256.Sum256(bs.data)
s.mp[sha] = bs
}
含まれる要素を bitset で表し、その bitset を sha256 にしたものを key とする map を持つようにしました。Toy 言語用の Lexer を作成するための regex pattern から生成される NFA の状態数でも 600 個くらいになったので、全通りの subset が列挙されると sha256 では確実に衝突が起こってしまいますが、現実問題としてそこまでの subset の種類数はできないし、衝突するくらいの subset が生成された場合、現代のコンピュータでは一生掛かっても計算が終わらないので、そんなケースのことは考えなくてもよいだろうという楽観視した実装にしました。
DFA minimization
subset construciton でできた DFA は状態数が多いので等価な2つの状態を一つにまとめることを繰り返し状態数を減らします。
私の場合は ドラゴンブック p.181 Algorithm 3.39 の疑似コードを見て自分なりに実装しました。書かれているアルゴリズムとしては GeeksforGeeks の Mimimization of DFA と同じです。おそらく Hopcroft Algorithm と言われるものだと思います。
ドラゴンブックも GeeksforGeeks も言葉では説明されてますが、実際にどうコードに落とし込むのかまでは書かれていなかったので、効率性を無視した Brute Force 実装しました。
初期 partition の工夫
先のアルゴリズムでは非終了状態と終了状態の2つのグループから始めていますが、これに素直に則ると、どの正規表現由来か区別できていた終了状態が区別できなくなってしまいます。そこで終了状態とひとくくりにするのではなく、異なる正規表現由来の終了状態は異なるグループに入れることで区別できなくなることを回避できます。(ドラゴンブック p.184 State Minimization in Lexical Analyzer)
具体的にいうと、subset constructon してできた DFA の id を ' を付けた id で下記のように振り直したとします。
このとき、Hopcroft algorithm の初期の partition は regex id ごとに分ければよいので以下のようになります。
この partition 構成から始めれば、異なる正規表現由来の状態が同じグループ内に入ることはないので、あとは Hopcroft algorithm を愚直に適用していけばどの正規表現由来かを区別できつつ状態を減らした DFA を得ることができます。
ちなみに、私の実装ですとグループの管理は union find を使いました。
コード生成
作成した DFA を元にした Lexer のコードをファイルに出力すればいよいよ Lexer Generator の完成です。
雰囲気としては以下のようなコードを生成しました。
func (dfa DFA) step(currentID StateID, r rune) StateID {
...
}
func (dfa DFA) IsFinalState(id StateID) bool {
...
}
func (dfa DFA) IsDeadState(id StateID) bool {
...
}
type Lexer struct {
dfa DFA
src string
currStateID StateID
currPos int
startPos int
finPos int
YYtext string
}
type TokenID = int
func (lex *Lexer) NextToken() (TokenID, error) {
Begin:
for {
sid := lex.dfa.step(lex.currStateID, src[lex.currPos])
if lex.dfa.IsFinalState(sid) {
lex.finPos = lex.currPos
} else if lex.dfa.IsDeadState(sid) {
lex.YYtext = src[lex.startPos:lex.finPos+1]
lex.finPos++
lex.startPos = lex.finPos
lex.currPos = lex.finPos
lex.currStateID = (初期状態の id)
{
最終的にマッチした終了状態の Action を実行する
}
goto Begin
}
lex.currPos++
lex.currStateID = sid
}
}
やっていることとしては与えられた文字列から、DFA で受理される最長の文字列を抜き出すことを繰り返しています。
Lexer で肝となるのは遷移を止めるタイミングで遷移の途中である終了状態に到達したからといってそこで遷移を止めてはいけません。なぜならば Lexer は正規表現の最長マッチするものを採用するので、はじめに到達した終了状態では最短マッチになってしまい不適です。入力を止めるタイミングは入力に対して遷移先がなくなったら止めます。上記の疑似コードの場合は、遷移先がなくなった判定の代わりにあらゆる入力に対して自分自身に返ってくる非終了状態 DeadState を用意し、そこに遷移した場合は入力を止めるということにしています。
Unicode 対応
上記までの方法でおおよそ Lexer Generator といっても差し支えないものはできました。ですが、利便性を考えると設定ファイルに書く正規表現では範囲を表す [a-z] や改行除く任意の文字 . などもさすがに使いたくなります。
ASCII の範疇では 7 bits の情報しかないので状態遷移は全文字分作っても大した量になりませんが、Unicode の範疇になると文字の種類数が
そこで遷移を表す型を map[StateID]map[rune]StateID から map[StateID]map[Interval]StateID と rune での遷移から、ある Interval に入力文字が含まれていたら遷移するという形にしました。
type Interval struct {
l int
r int
}
// [a-z] の場合
Interval{l: 97, r: 122} // int(rune('a')) = 97, int(rune('z')) = 122
// [あーう] の場合
Interval{l: 12354, r: 12358} // int(rune('あ')) = 12354, int(rune('う')) = 12358
Interval で持つようになっても全体的な処理の流れは変わりませんが、subset construction をするときに overlap している区間の扱いには注意が必要です。
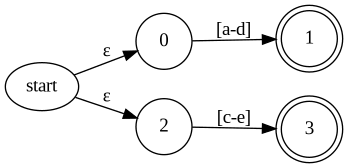
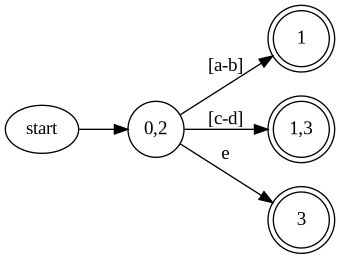
上図の場合ですと [a-b], [c-d], e の3つに分ける必要があります。
予め、NFA に含まれる Interval をすべて抜き出し重複しない区間に分解することで、1文字の入力の遷移を考えるのと同様の処理にすることができます。
おわりに
以上、自作 Lexer Generator の紹介でした。理論の勉強と実装合わせて1ヶ月くらい掛かりましたが、なかなか有意義な時間を過ごすことができました。
既存の Lexer Generator のコードはどこから読めばいいのかわからず結局ほとんど読まなかったので大部分の処理が非効率な実装になっていると思いますが、この記事のはじめに書いた正規表現パターンから Lexer 生成まで 0.5 秒切る目標でやっていてそれは無事に達成したので(生成にかかる時間は 0.08 秒くらい)とりあえずよしとします。
参考文献
正規表現エンジンを作る連載なので Lexer Generator とは違いますが、共通点も多いので参考にしていました。Python だと集合の集合を frozenset というのを使うと表現できると知って羨ましいなぁと思った記憶があります。
"A Programmer's Perspective" とあるようにコードを書きながらオートマトン理論を学ぶ構成になっています。コードを書きながら学べるのでどうやって実装するのかというイメージをつけるのに役立ちました。一方で数学的な証明は Hopcroft, Ulmann を読んでねという感じなので数理的な部分を学ぶには不向きです。
ドラゴンブックでおなじみの本です。購入してから長らくインテリアとして活躍していましたが、Lexer Generator 用の DFA minimization の方法を探して RE2C の論文をパラパラ読んでいるときに、ドラゴンブックにその方法が書いてあるという記述を見つけて読み始めました。
字句解析の章だけで80ページもあるので手っ取り早くコンパイラを作ってみたい人にとっては読むのが辛いようですが、Lexer Generator を作ろうという私のような人にはこれ以上の参考図書はないと思います。私が持っている言語処理系の本の中で Lexer Generator の内部について扱っているのはドラゴンブックだけだったので本当に助かりました。
Unicode 対応するために Interval を持てばよいということは rflex のコードを見てなんとなく察したのですが、私は Rust の読み方がわからなかったので結局どう実装したらよいのだろうなぁと途方にくれているときにこの stackoverflow のコメントを見つけました。
重複しない区間を作るには priority queue を使えば
priority queue を実装するときに参考にしました。始めは Go 公式の container/heap を使って実装しようかと思ったのですが、Example にある priority queue の実装がパット見で理解できなかったのでこの本を見ながら自分で実装しました。
ある Interval と重なる Interval を探す場合は interval tree がないときついかなと思って軽く読みました。現状の私の使い方だと interval tree を使うほどではないと判断して使いませんでしたが、この辺がボトルネックになったときにはまた参考にしようと思っています。
flex の設定はどんな感じに書くのか知るために読みました。この本はあくまでツールの使い方の本なので読んでも flex の内部のことはわかりません。私の場合は設定ファイルを flex 風につくりましたが、flex に倣うよりも JSON とか YAML で書く方式にしたほうが設定ファイル用の parser を作らずに済むので楽だとは思います。
この本は、flex/bison を使った SQL parser の例が載っているので、クエリ言語として SQL に対応したい自作 DBMS 勢におすすめです。
タイガーブックでおなじみの本です。
実装時には参考にしてませんでしたが、改めてパラパラ読んでみると NFA -> DFA 変換のところは疑似コード付きで解説があったのでこれを読んでいればもう少し早く実装できたかもと思いました。
-
元の記事のリンク https://qiita.com/bicycle1885/items/b9ae737bb1655a3b7252 。Internet Archive からは読めます。Automata.jl は Lexer Generator というより、Lexer Generator としても使えるといった表現のほうが正しいかもしれません。 ↩︎
Discussion