開発者が知るべきキャッシュ設計でよく遭遇する問題
はじめに
分散システムの設計および開発において、キャッシュはパフォーマンス向上のための非常に重要な要素です。頻繁にアクセスされるデータをキャッシュすることで、アクセス速度が遅いデータベースへのアクセスを削減し、データへの迅速なアクセスを可能にします。これにより、システムの全体的な効率とパフォーマンスが向上します。
しかし、キャッシュは慎重に設計しないとむしろパフォーマンス上のデメリットになるケースが存在します。 この記事ではよく遭遇するキャッシュ設計の問題とその回避策について解説します。
Cache penetration
DBに存在しない値を検索したときに、DBから返された空の結果をキャッシュしない場合に発生するシナリオです。
このシナリオではDBに存在しない値を繰り返し検索することにより、その値がキャッシュされていないため検索ごとにDBへのアクセスが必要になってしまいます。
存在しない値を検索するたびに以下の図のような問い合わせを繰り返すことになります。
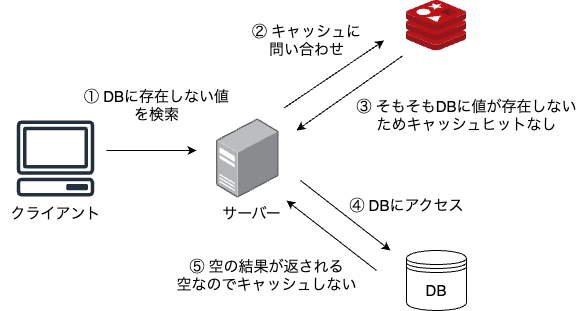
悪意のある利用者がそのようなキーで多数の検索を開始して攻撃を試みると、下層のDBレイヤーが頻繁にヒットし、最終的にダウンする可能性があります。
解決策1 空の結果をキャッシュする
クエリによって返されるデータが空であっても、結果をキャッシュすることによってこの問題を解決することができます。
下図のように2回目の検索以降ではDBアクセスが不要になります。
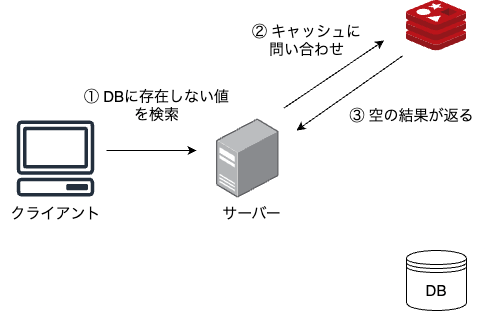
しかし、悪意のある利用者によって存在しない値を大量に検索された場合、キャッシュがデータベースに存在しない値によって埋め尽くされてしまう可能性があります。 この場合、キャッシュスペースが無駄になり、正常なリクエストにおけるキャッシュヒット率が低下してしまうことになります。
そのためこの空の結果の有効期限は通常の結果よりも短めに設定するのがポイントです。
以下にこの解決策の擬似コードを提示します。
def get_data():
# 通常は5分でexpireさせる
cache_time = 300
cache_key = "item"
cache_value = CacheHelper.get(cache_key)
if cache_value is not None:
return cache_value
else:
# データベースから問い合わせ
cache_value = get_data_from_db()
if cache_value is None:
# 問い合わせ結果が空の場合、デフォルト値を設定し、それをキャッシュ
cache_value = ""
# 空の結果をキャッシュするときはexpiration timeを短めに設定
cache_time = 30
CacheHelper.add(cache_key, cache_value, cache_time)
return cache_value
解決策2 ブルームフィルターを利用する
ブルームフィルタとは
ブルームフィルターはハッシュマップと似ていて、ある要素が集合の中に存在するかを調べることができるデータ構造です。
ブルームフィルターはハッシュマップよりも空間効率に優れていますが、確率的なデータ構造です。ブルームフィルターによって、存在しないと判定されたデータは確実に存在しないことが保証されますが、存在すると判定されたデータは実際には存在しなかったという場合がありえます。
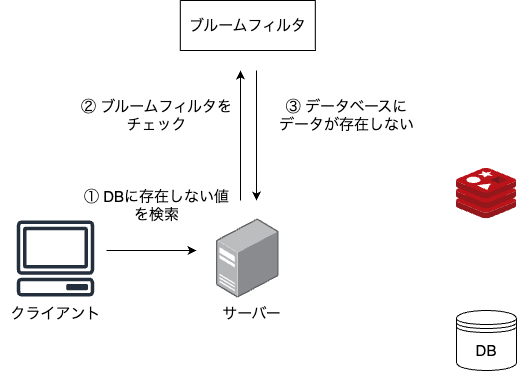
この方法ではデータを検索する前にブルームフィルタを使用して、DB内にデータが存在しないかどうかを判定します。存在しないデータに対しては早期リターンをして、キャッシュやデータベースへのアクセスが発生しないようにします。
存在する可能性があるデータについてはまずキャッシュを検索し、データがなければDBにアクセスして結果をfetchします。
以下がこの解決策の擬似コードです。
def get_data(key):
# ブルームフィルタでデータが存在しないと判定された
if not bloomfilter.might_contain(key):
return None
value = redis.get(key)
# キャッシュヒットしなかった
if value is None:
# DBをフェッチ
value = db.get(key)
redis.set(key, value)
return value
解決策の使い分け
検索キーの繰り返し率が高い場合は空の結果をキャッシュする手法が有効です。
逆に検索キーの繰り返し率が低く、検索キーの種類が非常に多い場合はこの手法を使用するとキャッシュスペースが圧迫されてパフォーマンスの低下に直結します。
このような場合はブルームフィルタを使用するのが有効です。
Cache breakdown
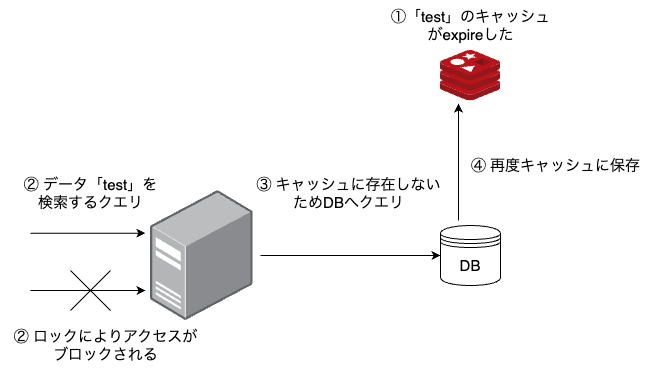
マルチスレッド環境で発生するシナリオです。キャッシュデータが期限切れになった際に、その期限切れしたデータへのアクセスが並行して発生するとデータベースへの問い合わせが同時に複数回発生するため負荷が急増します。
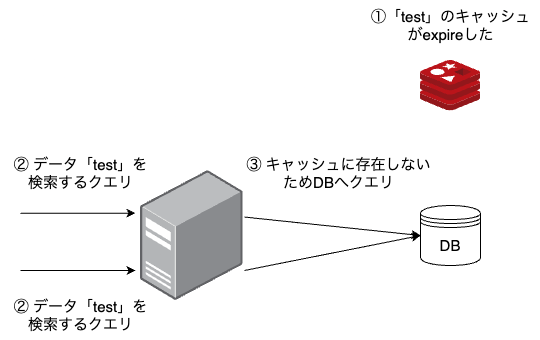
解決策1 検索キーにロックをかける
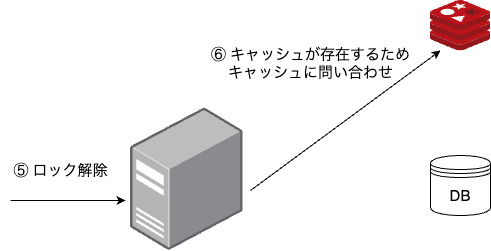
一度に一つのスレッドだけがデータベースに問い合わせをできるようにします。
他のスレッドはデータベースを問い合わせるスレッドが実行を終えてデータを再度キャッシュに追加するのを待ち、他のスレッドはキャッシュからデータを取得することができます。
以下が擬似コードです。
def get_data(key):
# キャッシュからデータを取得
value = redis.get(key)
# キャッシュにデータが存在しない場合
if value is None:
# ロックを取得
if lock.acquire():
# データベースからデータを取得
value = db.get(key)
# キャッシュをアップデート
if value is not None:
redis.set(key, value, expire_secs)
lock.release()
# ロックの取得に失敗
else:
time.sleep(0.1)
# キャッシュに再登録されるまで待つ
value = redis.get(key)
return value
解決策2 頻繁にアクセスされるデータがキャッシュでexpireしないようにする
キャッシュの有効期限をredisとは別にデータ自体にも持たせ、データに持たせた期限を過ぎたときにバックグラウンドの非同期スレッドでキャッシュを更新させます。
こうすることで頻繁にアクセスされるデータはキャッシュ上でexpireしなくなります。
def get_data(key):
v = redis.get(key)
value = v.get('value')
# データ自体に持たせた期限
timeout = v.get('timeout')
# キャッシュがexpireした場合
if timeout <= time.time():
# 非同期でキャッシュをアップデート
def run():
key_mutex = "mutex:" + key
# ロックを取得
if redis.setnx(key_mutex, "1"):
redis.expire(key_mutex, 3 * 60)
db_value = db.get(key)
redis.set(key, db_value)
redis.delete(key_mutex)
thread = threading.Thread(target=run)
thread.start()
return value
解決策の使い分け
1番目の方法はシンプルですが、データベースアクセス時にロックを取得する必要があります。
2番目の方法はパフォーマンス上の優位性がありますが、キャッシュの更新中に他のスレッドが古いデータにアクセスする可能性があり、キャッシュの一貫性を厳格に保証することは困難です。
保証する必要のある一貫性のレベルに応じて使い分けましょう。
Cache avalenche

大量のキャッシュデータが同時に期限切れになる、またはキャッシュサービスがダウンして突然すべてのデータの検索がDBにヒットし、DBレイヤーに高負荷をかけてパフォーマンスに影響を与えるシナリオのことを指します。
解決策1 有効期限をランダムに設定する
キャッシュの有効期限を同じ値に設定するのは避け、ランダムな値を設定することで期限切れになる時間を均等に分散させます。
このようにすると、各キャッシュの有効期限の繰り返し率が減少し、同時に大量のキャッシュが期限切れになることを避けることができます。
def getRandomExpiry(originalExpiry, deviationPercentage = 15):
# 有効期限のとりうる値を指定
deviation = originalExpiry * (deviationPercentage / 100)
# とりうる最小の期限と最大の期限を算出
minExpiry = originalExpiry - deviation
maxExpiry = originalExpiry + deviation
# 指定された範囲で有効期限をランダムに取得
randomExpiry = random.uniform(minExpiry, maxExpiry)
return randomExpiry
解決策2 キャッシュサーバーの可用性を高める
キャッシュサーバーを冗長化して可用性を高めることにより、キャッシュサーバーがダウンする状況を減らすことができます。
例えばRedisを使用する場合はRedisクラスターを使用することができます。Redisクラスターはデータを複数のRedisノードに分散することでキャッシュの可用性と耐障害性を向上させます。
これにより一部のノードで問題が発生しても他のノードで引き続きリクエストを処理することができるようになります。
解決策3 Rate Limit
指定された時間枠内でキャッシュ再生成をトリガーできるリクエストの数に上限を設けることで、サーバーへの負荷急増を防止します。
データベースへのアクセスリクエストの急増が防止され、サーバーリソースが枯渇することを防ぎます。これにより、システムの安定性とパフォーマンスが維持されます。
まとめ
Cache penetration, Cache breakdown, Cache avalancheについて解説しました。
キャッシュは慎重に設計しないとむしろパフォーマンスを悪化させる要因にもなりかねません。上記の問題とその解決策を理解しておくことは重要です。
また、これらの問題に対する解決策はビジネス要件に応じて適切なものを選択することが必要となります。
参考資料
Discussion