この記事は Google Cloud Japan Advent Calendar 2022 8 日目 の記事です。
こんにちは!みなさん AI/ML やってますか!?私は AI/ML を非常に苦手としているのですが、色々な団体が発表する さまざまな 技術には 非常に興味を持っています。そして、いつかこのような技術を本番環境に組み込んだりするんだろうな、、それってどこにどうやってデプロイすることになるんだろう…ということも。
というわけで今回は OpenAI が生み出した、 Whisper を Google Cloud 上で動かすというお題を例にして、上記の場合どんなことを考えなければいけないかということを考察していこうと思います。
Whisper とは
Whisper とは、
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
(https://github.com/openai/whisper#whisper より引用)
とのことですが、ざっくりいうと、様々な言語の音声を文字に変換する、いわゆる Speech to Text を行ってくれて、さらには翻訳も行うことができる技術のことです。この項目 にもある通り、かなりの言語数に対応しているようです。そしてなんと 日本語 にも…!モデルもサイズが 5 種類用意されており、サイズの大きさが大きくなるほど精度も高くなるが、必要な VRAM が増え、処理時間も大きくなるいうトレード・オフの関係にあるようです。処理の結果は文章として出力したり、映像編集者には嬉しいSRTファイル形式で出力も可能です。
Whisper をとりあえず試してみたいが…
CPUだけでも動かそうと思えば動かせるのですが、最速で処理をさせるためには GPU を用意したほうが良いと言えるでしょう。しかし、誰もが 高性能の GPU を持っているわけではありませんし、私のような AI/ML を用いた開発をもっぱらやっていない人にとっては開発環境の構築だけでも一苦労です。そんな場合におすすめなのが、 Google Colaboratory です! Google Colaboratory とは、
Colaboratory(略称: Colab)は、Google Research が提供するサービスです。Colab では、誰でもブラウザ上で Python を記述、実行できるため、機械学習、データ分析、教育に特に適しています。具体的には、GPU などのコンピューティング リソースに料金なしでアクセスしながら、特別な設定なしでご利用いただけるホスト型の Jupyter Notebook サービスです。
GPU などのコンピューティング リソースに料金なしでアクセスしながら、特別な設定なしでご利用いただけるホスト型の Jupyter Notebook サービスです。
ん? GPU 使ってるのに無料!?
はい無料なんです。上記の引用元である FAQ にも、
本当に料金なしで利用できるのですか?
話がうますぎるように思えます。なにか制限事項があるのではありませんか?
という質問と答えが書いてありますが、無料です。詳しくはこちらをご覧ください。
というわけで試してみる
先人たちのアウトプットを使わせていただきましょう。試すためにはパソコンにマイクとスピーカーが必要です。いつも Web 会議をやられている方は問題ないかと思います。
ここ にアクセスすると、 Pete Warden 氏が作成した Notebook を Google Colaboratory で開けます。元ファイルは GitHub 上で公開されています。
アクセスしたら、メニューから Runtime の Run All を選択し、一番下までスクロールしてしばらく待ちます。
最終的に下図のような UI が表示されたら準備完了です。

Record from microphone を押下し、マイクに向かってなにか喋ってみましょう。初回はブラウザからマイクのアクセスの許可が必要です。

「こんにちは。今 OpenAI の Whisper について Advent Calendar でブログを書いています」と喋ってみた結果です。あまり上手に Speech to Text してくれませんでした。それもそのはず、 base のモデルを使用するように設定しているからです。上にスクロールして Load the ML Model の項のコードにある base の文字を medium に書き換え、そのコードブロックの左側にある三角の再生ボタンを押下後、再度試してみましょう。

完璧に Speech to Text してくれました!感動です!

よくダミーテキストとして使われる宮沢賢治ポラーノの広場の一節をものすごくたどたどしく読んでみましたが、すごい精度です。ちなみに今回は日本語で試しましたが、日本語以外の言語が喋れる場合はぜひ別言語でもやってみてください。
Whisper がどのようなものか、実際に試すことでおわかりいただけたかと思います。これだけでひとしきり遊べますが、本来の目的である、これをどうやって Google Cloud で動かすか?という考察に戻りましょう。
状況を整理する
これをどうやって動かすか?と考えるといっても様々な条件があります。今回は下記のような状況で考えてみます。
- コンテナ化され WebAPI を提供する形で Whisper を使えるようにしたこれを動かす
- 1 時間以上の動画ファイルや音声ファイルも処理にかけたい
- できるだけ早く処理を完了させたい
- できるだけマネージドサービスを使い、管理運用を最小化したい
今回デプロイしたいコンテナをとりあえず実行してみる
では、今回デプロイしたいコンテナをとりあえず実行してみましょう。ローカル環境に Docker があればそれを使ってもよいのですが、私はローカル環境には入っていないので、 Cloud Shell を使いたいと思います。 Cloud Shell とは、5 GB の永続ストレージを持った、ある程度開発に必要なツール群がセットアップ済のサーバを無料で提供してくれるサービスのことです。ブラウザ上からアクセスできるのが特徴で、わざわざ SSH する必要すらありません。 Cloud Shell を開くためには、 Google Cloud のウェブコンソールを開いて、右上のアイコンをクリックします。

しばらくするとブラウザ下部にターミナルが表示されるので、 Readme 通り
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest
を実行します。
Port 9000 で Webサーバが立ち上がっているはずなのでアクセスしてみます。アクセスするためには、「ウェブでプレビュー」の下図ボタンをクリックし、ポート番号を変更してアクセスします。

そうすると新しいタブが開かれ、 WebAPI のドキュメントが表示されるはずです。このように特にパスを指定せずにアクセスするとドキュメントを表示し、 POST で /asr, /detect-language にアクセスするとそれぞれ処理が実行されるような Web サーバであることがわかります。
Google Cloud のコンピューティングプロダクト
Google Cloud では下図のようなコンピューティングプロダクトを有しています。
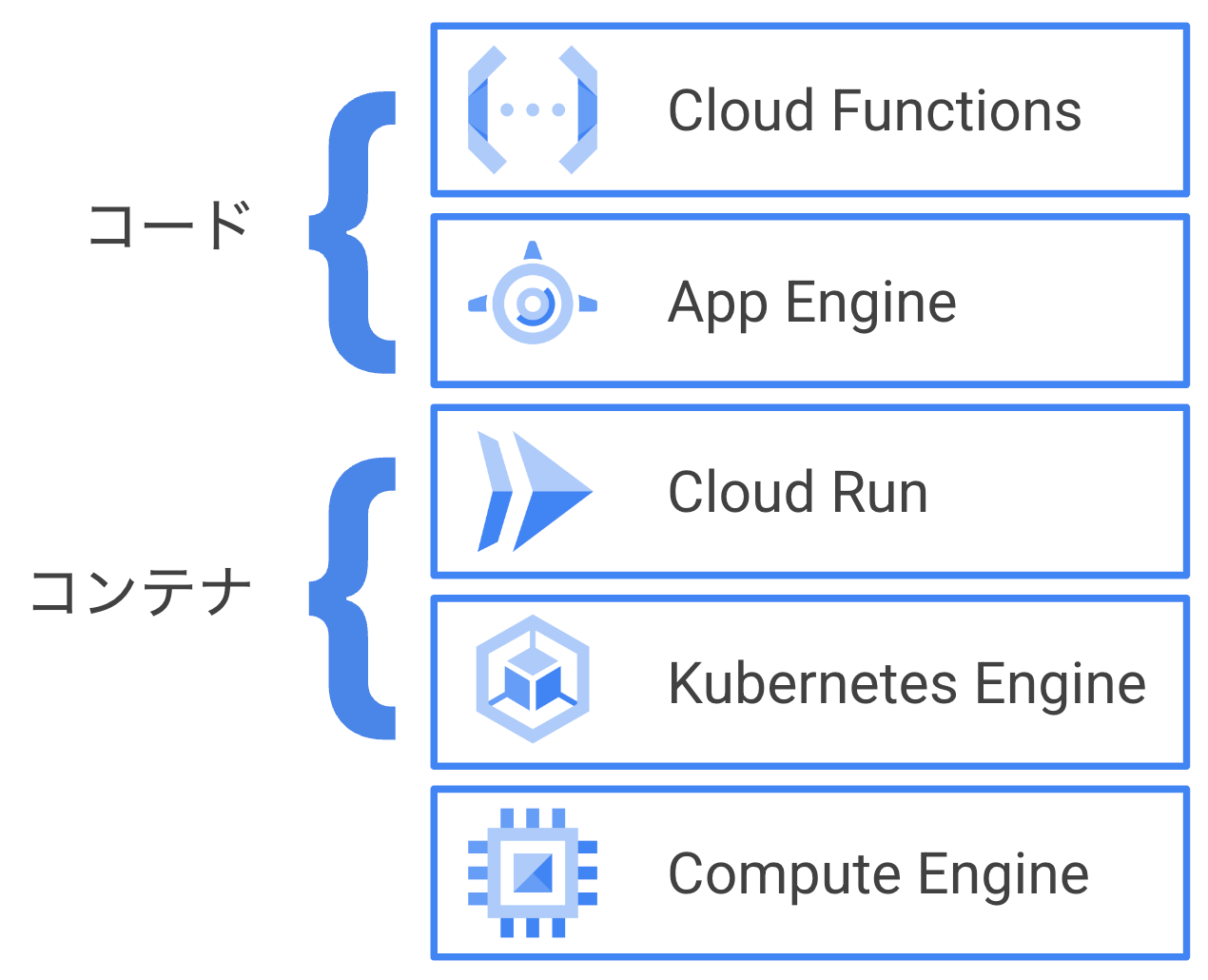
今回はコンテナを動かすので、よりマネージドな Cloud Run を使いたいところはやまやまですが、1時間以上の処理時間が必要であったり、GPU を可能であれば使いたいことから、残念ながら要件に適しません。つまり、Googe Kubernetes Engine (以下 GKE) を使う必要があるということです。Cloud Run であれば、非常に簡単にアプリケーションをデプロイできますが、 GKE を使うとなると Kubernetes の知識や、Cloud Run と比較してより多くのコンポーネントを自分で管理する必要があります。そこで、 GKE Autopilot です!
GKE Autopilot とは
GKE は実は 2 つの運用モードがあります。 GKE Standard と GKE Autopilot です。GKE Standard と比較して GKE Autopilot は Node の管理までをマネージドで行います。よって、
- Node で使うインスタンスタイプの考慮
- 使用するインスタンス数の計算
- Pod の配置構成
などの管理運用が最小になります。また、課金体系が Node 単位ではなく、 Pod が使用したリソース単位での課金となります。課金について詳しく知りたい場合はこちらをご参照ください。
GKE Autopilotの概要を詳しく知りたい場合はこちらをご参照ください。また、Standard と Autopilot の比較についてはこちらをご参照ください。
また、つい最近 GKE Autopilot でも GPU のサポートが発表されました!(この記事執筆時は Preview です)
GKE Autopilot のクラスターを作る
それでは実際に使ってみましょう。
先程使っていた Cloud Shell で下記コマンドを実行し、 whisper-demo というクラスターを us-central1 に作成します
gcloud container --project [project-id] clusters create-auto "whisper" \
--region "us-central1" \
--release-channel "regular"
しばらく待つと、クラスターの作成が完了します。Autopilot モードを使うため、クラスター作成時に Node の設定は行う必要はありません。作成が完了したら ウェブコンソール から状況を確認してみましょう。モードが Autopilot 、 vCPU の合計数や合計メモリが 0 になっているかと思います。
Manifest を作成する
今回は GPU を用いて試験的にデプロイしてみたいと思います。 Deployment と、それに対応する Service を作成する Manifest を記述します。
ローカル環境からこのプロジェクトにアクセスしたり、manifest を apply するのは非常に面倒です。私はよく Cloud Shell Editor を使って開発をしています。 Cloud Shell Editor はここからアクセス可能です。アクセスしたら、 Visual Studio Code ライクな IDE がブラウザ上に表示されるかと思います。前項で使っていた Cloud Shell サーバ上のファイルがここからアクセスでき、もちろんターミナルもこの IDE 上から使うことが可能です。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: whisperweb
name: whisperweb-gpu
spec:
replicas: 1
selector:
matchLabels:
app: whisperweb
template:
metadata:
labels:
app: whisperweb
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-tesla-a100
cloud.google.com/gke-spot: "true"
containers:
- image: onerahmet/openai-whisper-asr-webservice:latest
name: whisperweb-gpu
resources:
limits:
nvidia.com/gpu: "1"
apiVersion: "v1"
kind: "Service"
metadata:
name: "whisperweb-gpu-service"
namespace: "default"
labels:
app: "whisperweb"
spec:
ports:
- protocol: "TCP"
port: 80
targetPort: 9000
selector:
app: "whisperweb"
type: "LoadBalancer"
GKE Autopilot では、 spec に nodeSelector として cloud.google.com/gke-accelerator: nvidia-tesla-a100 のように指定するだけで、 GPU が使用可能です。現状、nvidia-tesla-t4 と nvidia-tesla-a100 の指定が可能です。また、今回は費用節約のため、 cloud.google.com/gke-spot: "true" も指定しています。この指定することにより、 Spot Pod を利用しています。Spot Pod を利用することにより、かなり安く利用可能です。ただし、Spot Pod はコンピューティング リソースのニーズに基づいていつでも強制排除されるため、止まってはいけない重要なワークロードの場合は十分注意しましょう。料金の詳細はこちら
Autopilot モードのクラスタにデプロイする
すべての準備が整ったので、順次デプロイしていきましょう。Cloud Shell Editor を使っている場合は、下記コマンドを実行するだけで完了します。
kubectl apply -f whisper-deployment.yaml
kubectl apply -f whisper-service.yaml
しばらく待って、ウェブコンソール の、「ワークロード」のメニューと、Services と Ingress のメニューを確認してみます。正常にデプロイが完了していたら緑のチェックマークアイコンが表示されているはずです。
それでは最後に、デプロイしたワークロードにブラウザでアクセスしてみましょう。Services と Ingress のメニューまたは、kubectl get services で作成された Service の 外向きIPアドレスを確認し、アクセスしてみましょう。ローカル開発環境や、Cloud Shell で試してみた表示と同じ表示がされることを確認して、デプロイ確認は完了です。
まとめ
今回は GKE Autopilot に、 OpenAI の Whisper のワークロードをデプロイしてみました。このワークロードは GPU が必要なため、Cloud Run の選択肢はなく、GKE を選ぶこととなりました。しかし、Autopilot モードのおかげで、自分自身で管理運用しないといけない部分を少しでも減らせたのではないかと思います。
私個人的には Cloud Run は非常にお気に入りのプロダクトではありますが、1時間以上処理時間が必要なワークロードや、 GPU を用いたワークロードのデプロイ先としては使えず、かといって GKE を管理運用するのはなぁ…と思っていたことも多々ありました。しかし今回の GKE Autopilot は、少なくともバッチ処理のようなものや、MLのワークロードを実行するプラットフォームとして非常に優秀であり、どんどん使っていきたいなという感想を懐きました。今回のハンズオンを機会に、ぜひ皆様も GKE Autopilot を試して、活用していただければと思います。

Discussion