Google Cloud Japan Advent Calendar 2024 の 10 日目にリリースすることを目指していた記事です。
本日のテーマは Cloud Run で Gemma 2 を動かす方法、そして GKE を利用した場合との違いについて簡単にご紹介する記事です。GKE で Gemma 2 を動かす方法については今年のアドベント カレンダーの 3 日目の記事である Gemma2 を GKE 上でいい感じに動かしたい (推論編) に解説がありますので、よろしければそちらも併せて読んでいただけますと幸いです。
なお、本記事はあくまでも Cloud Run がメインなので推論ライブラリのパラメータなどのチューニングは扱いません。また、Cloud Run と GKE のどちらかのみをおすすめするという趣旨でもありません。言語モデルをホストする際に Cloud Run と GKE のどちらを使えばいいのかをご選択いただく際の参考情報になればと思っています。
tl;dr
- Cloud Run は使った分だけの課金が発生するサーバーレスのサービスであり、NVIDIA 社の L4 GPU を 1 枚アタッチすることが可能
- GPU が利用できるために言語モデルのホスティングがこれまで以上に簡単に行えるようになり、かつ高いスケーラビリティを持つ
- 中 ~ 大規模なモデルのホストは GKE など、Compute インスタンスをフルに使えるサービスの方が適している
Gemma を自社でホストする背景
3 日目の記事の兄弟ブログのような内容なので背景なども似通っているため、Gemma についての説明や言語モデルを API ベースではなく Cloud Run や GKE でホストしたい背景などの説明は基本的に省略しつつも簡単に記載します。
Gemma は Google DeepMind が今年の 2 月に公開したモデルで、2B もしくは 7B と軽量ながら高性能であることが最大の特徴です。さらに 6 月には新しい世代である Gemma 2、10 月には日本語性能を向上した Gemma for Japan が発表され、多くの Varient が利用可能です。
ここで言語モデルの利用に焦点を当てると、Gemini のように API ベースで利用する方法が最も簡単、かつ馴染み深いかと思います。しかしこのような利用方法では以下のような懸念もあるかと思います。
- トークン数に応じた課金が一般的な API ベースのサービスではユーザーが無邪気に膨大なトークンを送信してコストが肥大化する可能性がある
- API のバージョンがアップデートされてしまい同じプロンプトでも得られる結果が異なる
- クローズドな環境でホストしている自社サービスに組み込みたい (外部接続をしたくない)
上記のような背景もあり、Gemini 1.5 Pro などの大規模言語モデルと比較すると多少精度が落ちても良いので軽量な Gemma を Cloud Run や GKE でホストするといったニーズはあるかと思います。特に RAG アプリケーションの場合は回答するための知識がモデルのみに閉じないので、モデルの精度が多少落ちた場合の影響はモデルを単体で利用する場合と比較して低くなるかと思います。
Cloud Run 上に Gemma 2 2B をデプロイする
なるべく同じような前提での比較のため、本記事でも GKE の記事と同様に vLLM を利用して Gemma 2 をホストします。まずは公式チュートリアルがある Gemma 2 2B をデプロイし、負荷をかけてどれだけのリクエストに耐えうるかを確認してみます。ブログの後半では Gemma 2 9B のデプロイ、および負荷テストの結果も書いています。なお、本ブログではプロジェクトの作成や Cloud Shell の設定などは省略します。
API の有効化と環境変数の設定
まずは必要な API を有効化します。
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
secretmanager.googleapis.com \
artifactregistry.googleapis.com
続いて必要な環境変数を設定します。Hugging Face のトークン取得方法はこちらをご参照ください。
HF_TOKEN=<YOUR_HUGGING_FACE_TOKEN>
PROJECT_ID=<YOUR_PROJECT_ID>
REGION=us-central1
SERVICE_NAME=vllm-gemma-2-2b-it
AR_REPO_NAME=vllm-gemma-2-2b-it-repo
SERVICE_ACCOUNT=vllm-gemma-2-2b-it
SERVICE_ACCOUNT_ADDRESS=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
サービス アカウントの作成と権限付与
今回は専用のサービス アカウントを作成し、Hugging Face トークンを格納する Secret Manager へのアクセス権限などの必要最小限の権限を付与します。まずはサービス アカウントを作成し、Secret Manager へのアクセス権限を付与します。
gcloud iam service-accounts create $SERVICE_ACCOUNT \
--display-name="Cloud Run vllm SA to access secrete manager"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$SERVICE_ACCOUNT_ADDRESS \
--role=roles/secretmanager.secretAccessor
続いて Hugging Face トークン用のシークレットを作成し、上記で作成したサービス アカウントにアクセス権限を付与します。このあとの Cloud Run にデプロイするイメージをビルドしますが、その中でこのシークレットを利用して Gemma 2 2B のモデルを Hugging Face から取得します。
printf $HF_TOKEN | gcloud secrets create HF_TOKEN --data-file=-
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member serviceAccount:$SERVICE_ACCOUNT_ADDRESS \
--role='roles/secretmanager.secretAccessor'
コンテナ イメージの作成と格納
今回は Gemma 2 2B のモデルを含むコンテナ イメージを作成し、Artifact Registry に格納します。Cloud Run は Artifact Registry を参照し、本章で作成したイメージを利用してインスタンスをデプロイします。まずは Artifact Registry を作成します。
gcloud artifacts repositories create $AR_REPO_NAME \
--repository-format docker \
--location us-central1
続いて Cloud Run 上にデプロイするコンテナの Dockerfile、およびイメージのビルドや Artifact Registry へのイメージの Push を行うための Cloud Build 用の yaml ファイルを作成します。
FROM vllm/vllm-openai:latest
ENV HF_HOME=/model-cache
RUN HF_TOKEN=$(cat /run/secrets/HF_TOKEN) \
huggingface-cli download google/gemma-2-2b-it
ENV HF_HUB_OFFLINE=1
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8000} \
--model ${MODEL_NAME:-google/gemma-2-2b-it} \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
steps:
- name: 'gcr.io/cloud-builders/docker'
id: build
entrypoint: 'bash'
secretEnv: ['HF_TOKEN']
args:
- -c
- |
SECRET_TOKEN="$$HF_TOKEN" docker buildx build --tag=${_IMAGE} --secret id=HF_TOKEN .
availableSecrets:
secretManager:
- versionName: 'projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest'
env: 'HF_TOKEN'
images: ["${_IMAGE}"]
substitutions:
_IMAGE: 'us-central1-docker.pkg.dev/${PROJECT_ID}/vllm-gemma-2-2b-it-repo/vllm-gemma-2-2b-it'
options:
dynamicSubstitutions: true
machineType: "E2_HIGHCPU_32"
最後に Cloud Build へ作成して yaml ファイルを Submit します。コマンドの実行に 10 分程度かかります。
gcloud builds submit --config=cloudbuild.yaml
Cloud Run のデプロイとアクセス
上記の手順でイメージの準備が整ったので GPU がアタッチされた Cloud Run をデプロイします。Cloud Run のデプロイに 5 分程度かかります。
gcloud beta run deploy $SERVICE_NAME \
--image=us-central1-docker.pkg.dev/$PROJECT_ID/$AR_REPO_NAME/$SERVICE_NAME \
--service-account $SERVICE_ACCOUNT_ADDRESS \
--cpu=8 \
--memory=32Gi \
--gpu=1 --gpu-type=nvidia-l4 \
--region us-central1 \
--no-allow-unauthenticated \
--max-instances 5 \
--no-cpu-throttling
Cloud Run のデプロイが完了したら実際にアクセスしてみます。アクセスには Service proxy を利用する方法もありますが、今回は Cloud Run の URL へ直接アクセスしてみます。まずはサービスの URL を取得します。
SERVICE_URL=$(gcloud run services describe $SERVICE_NAME --region $REGION --format 'value(status.url)')
そして Curl で先ほど取得した URL にプロンプトを POST します。
curl -X POST $SERVICE_URL/v1/completions \
-H "Authorization: bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-2-2b-it",
"prompt": "Cloud Run is a",
"max_tokens": 128,
"temperature": 0.90
}'
無事に Cloud Run に関する説明が返ってきたら Gemma 2 2B が正常に Cloud Run で動作しています。
負荷をかけてみる
推論のパフォーマンスとひとことに言ってもさまざまな指標があり、GenAI-Perf を利用することで Time to first token や Throughput などが測定できます。ただし、今回のブログはインフラ側に焦点を当ててスケール性などを見たいので GKE のブログと同様に一般的な Web アプリケーションの負荷テストにも利用できる vegeta を利用してリクエストを送り続けます。
また、本ブログでも Google Cloud Managed Service for Prometheus を利用して vLLM のメトリックを取得しています。Cloud Run の場合はメトリックをスクレイピングするサイドカー コンテナをデプロイすることで簡単にメトリックが確認できます。詳細な手順はこちらに記載されておりますので適宜ご参照ください。
Gemma 2 2B に 10rps の負荷をかける
vegeta の結果を見ると 10rps であれば問題なくリクエストを処理できていそうです。
$ vegeta attack --rate=10 -duration 600s -targets targets.txt | vegeta report
Requests [total, rate, throughput] 6000, 10.00, 9.93
Duration [total, attack, wait] 10m4s, 10m0s, 4.081s
Latencies [min, mean, 50, 90, 95, 99, max] 476.308ms, 7.327s, 7.456s, 7.721s, 7.853s, 7.969s, 8.471s
Bytes In [total, mean] 5639460, 939.91
Bytes Out [total, mean] 1632000, 272.00
Success [ratio] 100.00%
Status Codes [code:count] 200:6000
vLLM の num_requests_waiting や Cloud Run のインスタンス数のメトリックを見ても 1 インスタンスですべてのリクエストが処理できていることがわかります。
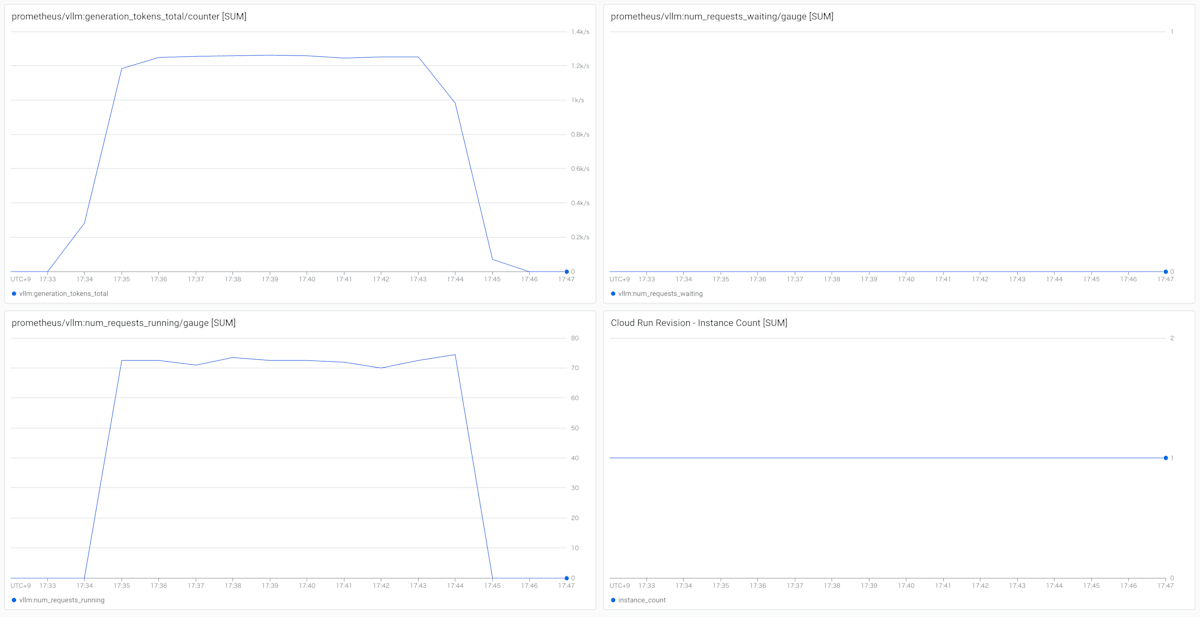
Gemma 2 2B に 20rps の負荷をかける
20rps の負荷をかけても問題なく処理できていそうですが、少しだけ Success ratio が下がっています。
$ vegeta attack --rate=20 -duration 600s -targets targets.txt | vegeta report
Requests [total, rate, throughput] 12000, 20.00, 18.98
Duration [total, attack, wait] 10m4s, 10m0s, 4.116s
Latencies [min, mean, 50, 90, 95, 99, max] 395.8ms, 10.13s, 7.793s, 20.063s, 29.494s, 30.001s, 30.001s
Bytes In [total, mean] 10771148, 897.60
Bytes Out [total, mean] 3118752, 259.90
Success [ratio] 95.55%
Status Codes [code:count] 0:534 200:11466
メトリックを見るとインスタンスがスケール アウトしてはいますが num_requests_waiting の値が上がっているわけではなく、また HTTP エラーが返っているわけではありません。Cloud Run がリクエストをキューイングしつつ頑張って処理を続けてはいますが、クライアント (vegeta) に 10 分以内にレスポンスを返せなかった状況 (これが Status Code 0 の扱い) と想定されます。現実世界では 10 分でクライアントが終了することはないと思いますので、レイテンシは長くはなりますが待っていればレスポンスは返ってくることが期待できるかと思います。

Gemma 2 2B に 30rps の負荷をかける
30rps の場合も 20rps と同じように Success ratio が下がっています。
$ vegeta attack --rate=30 -duration 600s -targets targets.txt | vegeta report
Requests [total, rate, throughput] 18000, 30.00, 25.13
Duration [total, attack, wait] 10m4s, 10m0s, 3.988s
Latencies [min, mean, 50, 90, 95, 99, max] 62.845ms, 11.229s, 6.746s, 30s, 30.001s, 30.001s, 30.01s
Bytes In [total, mean] 14262312, 792.35
Bytes Out [total, mean] 4128960, 229.39
Success [ratio] 84.33%
Status Codes [code:count] 0:2820 200:15180
こちらもメトリックを見ると 20rps の場合と比較してインスタンスがさらにスケール アウトしてはいますが基本的に同じ状況かと思います。

これらの結果から、Gemma 2 2B などの軽量なモデルであれば Cloud Run で非常に簡単、かつ高いスケーラビリティでホストできることがわかります。
Cloud Run 上に Gemma 2 9B をデプロイする
続いて Gemma 2 9B をデプロイしてみます。Gemma 2 2B と比較してモデルサイズも大きいため、コンテナ イメージにモデルを含めるのはインスタンス デプロイ時のイメージ Pull の時間も長くなり、実運用においては現実的ではありません。試しに上記の手順で google/gemma-2-9b を含むコンテナ イメージを作成したところ、およそ 40GB になりました。そのため、Gemma 2 9B の場合はあらかじめモデルをストレージにダウンロードしておき、vLLM のみを含むイメージを Cloud Run で動かす際にストレージからモデルをダウンロードするように構成します。
モデルのダウンロード
Cloud Run では Cloud Storage や NFS でストレージをマウントできます。検証に際して Cloud Storage と Filestore の両方を試した結果、Cloud Storage ではモデルのダウンロードに時間がかかるため、今回は Filestore を利用します。
基本的な流れは Filestore、およびモデルをダウンロードするための NFS クライアント (今回は Compute Engine) をデプロイし、Hugging Face から google/gemma-2-9b をダウンロードするというものです。ただすべてを書いていると文字数が多くなってしまうので Filestore や Compute Engine のデプロイ、Filestore のマウントまではこちらをご参照ください。注意点としては Filestore は Cloud Run と同じリージョンにデプロイする必要があること、モデルのダウンロード時に相応のスループットが必要になるので HDD ではなく Zonal Filestore などの利用がおすすめであることです。
Filestore などの準備が完了したら以下のコマンドで Gemma 2 9B のモデルをダウンロードします。今回は /data/model ディレクトリに Filestore をマウントしてその配下に gemma-2-9b ディレクトリを作成しておりますが、適宜ご変更ください。また、huggingface-cli のインストールはこちらをご参照ください。
huggingface-cli download google/gemma-2-9b --local-dir /data/models/gemma-2-9b
Cloud Run のデプロイとアクセス
Gemma 2 2B の場合はコンテナ イメージを指定して gcloud beta run deploy コマンドでデプロイしましたが、Cloud Run は yaml ファイルを利用したデプロイも可能です。今回はご紹介も兼ねて yaml ファイルを利用して Cloud Run をデプロイします。
まずは以下の yaml ファイルを作成します。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: vllm-gemma-2-9b
labels:
cloud.googleapis.com/location: us-central1
annotations:
run.googleapis.com/ingress: all
run.googleapis.com/ingress-status: all
run.googleapis.com/minScale: '1'
spec:
template:
metadata:
labels:
run.googleapis.com/startupProbeType: Default
annotations:
autoscaling.knative.dev/maxScale: '5'
autoscaling.knative.dev/minScale: '1'
run.googleapis.com/vpc-access-egress: private-ranges-only
run.googleapis.com/network-interfaces: '[{"network":"my-vpc","subnetwork":"my-subnet"}]' # Filestore が接続された VPC / Subnet を指定
run.googleapis.com/cpu-throttling: 'false'
run.googleapis.com/startup-cpu-boost: 'true'
spec:
containerConcurrency: 80
timeoutSeconds: 300
serviceAccountName: <YOUR_SERVICE_ACCOUNT_NAMED>
containers:
- name: pytorch-vllm-serve-1
image: us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20240910_0916_RC00 # GKE のブログと同じイメージを利用
args:
- python
- -m
- vllm.entrypoints.api_server
- --host=0.0.0.0
- --port=8000
- --gpu-memory-utilization=0.95
- --enable-chunked-prefill
- --model=/models/gemma-2-9b # NFS のディレクトリ構成によって適宜変更
- --max-model-len=3968 # GPU メモリの都合上 --max-model-len を指定
ports:
- name: http1
containerPort: 8000
env:
- name: MODEL_ID
value: /models/gemma-2-9b # NFS のディレクトリ構成によって適宜変更
resources:
limits:
cpu: 8000m
nvidia.com/gpu: '1'
memory: 32Gi
volumeMounts:
- name: nfs-1
mountPath: /models
startupProbe:
timeoutSeconds: 240
periodSeconds: 240
failureThreshold: 1
tcpSocket:
port: 8000
volumes:
- name: nfs-1
nfs:
server: 172.16.0.2 # Filestore の IP アドレスを指定
path: /models # Filestore のマウント先ディレクトリを指定
nodeSelector:
run.googleapis.com/accelerator: nvidia-l4
続いて以下のコマンドで Cloud Run をデプロイします。
gcloud beta run services replace service.yaml
モデルのダウンロードが必要なのでデプロイに少し時間がかかりますが、デプロイが完了したら実際にアクセスしてみます。まずはサービスの URL を取得します。サービス名は yaml ファイル内の metadata.name プロパティに設定した文字列です。
SERVICE_URL=$(gcloud run services describe vllm-gemma-2-9b --region us-central1 --format 'value(status.url)')
そして Curl で先ほど取得した URL にプロンプトを POST します。Gemma 2 2B の場合と比較して利用している vLLM コンテナのイメージが違うので少しパスが異なります。
curl -X POST $SERVICE_URL/generate \
-H "Authorization: bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Cloud Run is a",
"max_tokens": 128,
"temperature": 0.90
}'
負荷をかけてみる
デプロイが完了したので今回も vegeta を使って負荷をかけてみます。
Gemma 2 9B に 10rps の負荷をかける
Gemma 2 2B と場合と同じ負荷をかけてみると Success ratio が 1.63% なのでほぼリクエストを処理できていません。ただし、Status Codes を見るとエラーが起きているということではないようです。
$ vegeta attack --rate=10 -duration 600s -targets targets.txt | vegeta report
Requests [total, rate, throughput] 6000, 10.00, 0.16
Duration [total, attack, wait] 10m30s, 10m0s, 30.001s
Latencies [min, mean, 50, 90, 95, 99, max] 1.601s, 29.842s, 30s, 30.001s, 30.001s, 30.001s, 30.004s
Bytes In [total, mean] 63991, 10.67
Bytes Out [total, mean] 23128, 3.85
Success [ratio] 1.63%
Status Codes [code:count] 0:5902 200:98
メトリックを見てみると Gemma 2 2B では常に 0 だった num_requests_waiting の値が大きく増えていることが確認できます。また、vegeta では 10 分間負荷をかけていますが 20 分ほどは処理を続けていることが確認できます。

これらの情報から以下のような考察ができるかと思います。
- Gemma 2 2B と比較して Gemma 2 9B では 1 プロンプトあたりの処理時間が長い
- 1 プロンプトあたりの処理時間が長いので vLLM がすべてのリクエストをリアルタイムに処理しきれずリクエストがキューイングされている (処理できないリクエストは即エラーが返るわけではない)
- Cloud Run ではキューイングされたリクエストは可能な限り処理を続けるので Gemma 2 9B でもレイテンシは増えるものの待っていればレスポンスは得られる可能性が高い
今回は負荷を与える時間やインスタンス数が有限であったので Success ratio がかなり低く見えていますが、すぐにエラーを返すというわけではなく HTTP エラーも記録されていないのでインスタンス数の上限を増やすなどの対応で Gemma 2 9B でも Cloud Run 上でホストできる可能性はあるかもしれません。
まとめ
今回はあくまでもインフラのスケーラビリティに焦点を当てていたためにアプリケーション側のチューニングなどはしていませんが、小さいモデルであれば Cloud Run でも十分にホストできることを示す結果になったかと思います。GKE の違いとしてはコンテナの知識があれば簡単にデプロイができること、サーバーレスのサービスなので使った分だけの課金 (かつスケール アウトやスケールインもすぐに行われる) であることかと思います。
一方で現状 L4 GPU が 1 枚のみアタッチ可能であるために中 ~ 大規模なモデルのホストにはスペックが足りず、GKE が優位なユースケースももちろんあります。今回はかなり実験的な内容ではありましたが Google Cloud のサービスで言語モデルをホストする場合にどのサービスを使えばいいかを判断する材料のひとつになっておりましたら幸いです!

Discussion