Google Cloud Japan Advent Calendar 2024 Gemini 特集版 25 日目です。
こんにちは、カスタマーエンジニアの下門 (しもじょう) です。
2024 年は RAG (Retrieval-Augmented Generation) が非常に盛り上がりましたが、そんな年の締めくくりに Vertex AI の RAG Engine というサービスが GA (正式版) になりましたので RAG Engine + Gemini API を利用して簡単に RAG を構成する方法を紹介いたします。
RAG Engine の概要
RAG Engine は、カスタム RAG アプリケーションを簡単に実装するためのフルマネージドなデータフレームワークおよびランタイムです。

元々は Google I/O 2024 のタイミングで LlamaIndex on Vertex AI として発表され、その後 Knowledge Engine に名称変更されたあと、現在の RAG Engine にリブランディングされました。
旧称に LlamaIndex の名前が入っていた経緯もあり、OSS LlamaIndex のマネージドサービスであると想像してしまいそうですが、実際には Google Cloud のネイティブな RAG API を提供するもので、LlamaIndex とは別物と考えていただいた方が良さそうです。
他方で LlamaIndex 同様に人気のフレームワークである LangChain のマネージドサービス LangChain on Vertex AI (a.k.a. Reasoning Engine) では、OSS LangChain をラップした Prebuilt のテンプレート (LangchainAgent クラス) によりエージェント開発が楽にできたり、カスタムテンプレートを利用した場合には既存の LangChain 資産も持ち込めたりします。
Reasoning Engine については「LangChain on Vertex AI(プレビュー) で Vertex AI Search と RAG する」の記事にて詳細な解説がされていますので、興味のある方はそちらもご参考ください。
利用の流れ
RAG Engine を利用する流れは次の通りです。
- RAG コーパスを作成
- RAG コーパスにファイルをインポート
- RAG コーパスを指定して検索ツールを作成
- Gemini (LLM) へのリクエスト送信時に 3 のツールを指定して回答を生成
1 のコーパス作成時には、任意でエンベディングモデルおよび RAG ベクトル DB を指定することが可能です。
4 にてリクエスト (クエリ) が送信されると、まずはじめに 3 で作成した検索ツールを介して関連するドキュメントを検索し、そこで抽出した情報を Gemini (LLM) に対してコンテキストとして提供することで、最終的に Gemini がデータに基づいた回答を生成してくれます。
エンベディングモデルの選択
Vertex AI のテキストエンベディングモデルに加えて、Vertex AI Model Garden からワンクリックでデプロイ可能な OSS の E5 モデルも選択可能です。
Vertex AI Text Embedding Models
- textembedding-gecko@003
- textembedding-gecko-multilingual@001
- text-embedding-004 (default)
- text-multilingual-embedding-002
- textembedding-gecko@002 (fine-tuned versions only)
- textembedding-gecko@001 (fine-tuned versions only)
OSS Text Embedding Models (via Model Garden)
- e5-base-v2
- e5-large-v2
- e5-small-v2
- multilingual-e5-large
- multilingual-e5-small
何れも multilingual のモデルを選択すれば日本語でも利用可能です。
データコネクタの選択
サポートされているデータソースとしては、ローカルファイルアップロード、Google Cloud Storage、Google Drive に加えて、Slack、Jira、SharePoint 用のデータコネクタが提供されています。
データ取り込み・変換
データを取り込む際に、各ドキュメントは複数のチャンクという単位に分割されるのですが、RAG Engine では chunk_size と chunk_overlap という 2 つのパラメータが指定可能です。
前者は各チャンクのサイズ (トークン数) を指定するパラメータで、その際にデフォルトでは隣り合うチャンクが一部重なるように分割されます。後者のパラメータはその重複する部分のトークン数を指定します。

一般論として、チャンクサイズを小さくすると、作成されるエンベディングにおいては粒度の高い詳細な情報まで考慮されますが、情報の網羅性は減ってしまい関連する情報を取りこぼしてしまう可能性があります。一方でチャンクサイズを大きくすると情報の網羅性が上がるため再現率は向上しそうですが、不要な情報も含まれてしまうため適合率は下がる可能性があります。
RAG においてはこれらのパラメータが精度を決める上で鍵となるのですが、最適値を決めることは一概には難しく、ご自身の環境やデータに合わせてチューニングしていく必要があると考えます。
尚、サポートされているドキュメントタイプはこちらに一覧があります。
Google Drive のファイルフォーマットに加えて、DOCX や PPTX などもサポートされているのは有用そうですね。
ベクトルデータベースの選択
組み込みの RAG マネージド DB に加えて、ファーストパーティの Vertex AI Feature Store、Vertex AI Vector Search または RAG 用途で非常に人気の高いサードパーティの Weaviate、Pinecone をベクトルデータベースとして選択することが可能です。(RAG コーパス作成時に指定します)
ベクトル DB の特徴・比較
公式ドキュメント内の各ベクトル DB の比較を抜粋・抄訳した表は次の通りです。
| ベクトル DB | 特徴 | 距離指標 | 検索タイプ | ステージ |
|---|---|---|---|---|
RagManagedDb (デフォルト) |
一貫性と高可用性を提供するリージョン分散型のスケーラブルなデータベースサービス。 セットアップ不要なためクイックスタートやライトなユースケースに最適。 |
cosine |
KNN | Preview |
| Pinecone | フルマネージドのクラウドネイティブベクトルデータベース。 スケーラビリティとパフォーマンスに優れておりフィルタリングやメタデータ検索などの高度な機能を備えたベクトル検索が可能。 |
cosineeuclideandot-product
|
ANN | GA |
| Weaviate | 柔軟性とモジュール性を重視したオープンソースのベクトルデータベース。 テキストや画像など様々なデータ型とモジュールをサポートし組み込みのグラフ機能も提供。 |
cosinedot-productL2 squaredhammingmanhattan
|
ANN + Hybrid Search | Preview |
| Vector Search | スケーラビリティと信頼性が高く機械学習タスクに最適化された Vertex AI 内のベクトルデータベースサービス。 |
cosinedot-product
|
ANN | GA |
| Feature Store | ベクトル検索機能を備えた Vertex AI 内の特徴量ストア。 BigQuery と直接統合されておりシームレスに同期が可能。 |
cosinedot-productL2 squared
|
ANN | Preview |
デフォルトの RagManagedDb では KNN のみをサポートしていますが、社内のドキュメント検索などデータ件数がそこまで多くないライトなユースケースであれば十分に活用できる場面も多いのではと考えています。Weaviate および Pinecone を選択される場合は何れも Google Cloud Marketplace 経由で購入いただけます。
尚、デフォルト以外を利用する場合は、各ベクトル DB のセットアップおよび認証周りの設定が事前に必要となります。
余談ですが、Feature Store および Vector Search のドキュメントに RAG Engine uses a built-in vector database powered by Spanner to store and manage vector representations of text documents. と説明があることから、組み込みの RAG マネージド DB は Spanner がバックエンドになっていることが分かります。(もちろんユーザーは Spanner のレイヤを意識する必要はありません)
回答生成モデル (LLM) の選択
これまで Gemini 前提で説明してきましたが、Gemini モデルに加えて、RAG Engine では Model Garden 上の全てのモデルをサポートしています。
Vertex AI エンドポイントにセルフデプロイした OSS モデル、または Mistral や Llama などの MaaS (Model as a Service) も選択可能です。
実際に試してみよう
RAG Engine API (Python SDK) および Vertex AI Studio (GUI) 経由で RAG Engine を実際に試してみましょう。
RAG Engine API を利用した RAG コーパス作成&クエリ実行
事前にデータを準備する必要があるため、データの格納用として GCS バケットを作成します。
BUCKET_NAME = "MY-BUCKET-NAME" # Replace with your actual bucket name
! gcloud storage buckets create gs://$BUCKET_NAME --location=us-central1
今回利用するデータは RAG Engine の公式ドキュメント 17 ページを HTML ファイルとして保存します。具体的には次の Python コードを実行して HTML を取得してファイルを GCS バケットに保存します。
urls = [
'https://cloud.google.com/vertex-ai/generative-ai/docs/rag-overview',
'https://cloud.google.com/vertex-ai/generative-ai/docs/rag-quickstart',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-data-connectors',
'https://cloud.google.com/vertex-ai/generative-ai/docs/supported-rag-models',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-embedding-models',
'https://cloud.google.com/vertex-ai/generative-ai/docs/supported-documents',
'https://cloud.google.com/vertex-ai/generative-ai/docs/fine-tune-rag-transformations',
'https://cloud.google.com/vertex-ai/generative-ai/docs/layout-parser-integration',
'https://cloud.google.com/vertex-ai/generative-ai/docs/vector-db-choices',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-feature-store-with-rag',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-weaviate-db',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-pinecone',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-vertexai-vector-search',
'https://cloud.google.com/vertex-ai/generative-ai/docs/use-vertexai-search',
'https://cloud.google.com/vertex-ai/generative-ai/docs/retrieval-and-ranking',
'https://cloud.google.com/vertex-ai/generative-ai/docs/manage-your-rag-corpus',
'https://cloud.google.com/vertex-ai/generative-ai/docs/rag-quotas'
]
from google.cloud import storage
import requests
import re
# Initialize Google Cloud Storage client
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
# Define the base URL path to be removed from file names
base_url_path = "https://cloud.google.com/vertex-ai/generative-ai/docs/"
# Iterate through each URL in the 'urls' list
for url in urls:
response = requests.get(url)
# Construct the blob name, removing base URL path and adding .html extension
blob = bucket.blob(response.url.replace(base_url_path, "") + ".html")
# Write the fetched content to the blob in the bucket
with blob.open ("w") as f:
f.write(response.text)
データが準備できましたので Vertex AI Python SDK 経由で RAG Engine API を実行していきます。
念のため SDK を最新版にアップデートしておきます。
! pip install -U google-cloud-aiplatform google-genai
# IMPORTANT: Added the new 'google-genai' package.
必要なモジュールをインポートして SDK を初期化します。
# IMPORTANT: Migrated to google.genai due to deprecation of vertexai.generative_models
import os
from vertexai import rag
# from vertexai.generative_models import GenerativeModel, Tool
import vertexai
from google import genai
from google.genai.types import GenerateContentConfig, Retrieval, Tool, VertexRagStore
PROJECT_ID = "PROJECT_ID" # Replace with your actual project ID
LOCATION = "us-central1"
display_name = "rag_engine_doc_corpus"
# Initialize Vertex AI API once per session
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Set environment variables for Gen AI SDK
os.environ['GOOGLE_GENAI_USE_VERTEXAI'] = 'True'
os.environ['GOOGLE_CLOUD_PROJECT'] = PROJECT_ID
os.environ['GOOGLE_CLOUD_LOCATION'] = LOCATION
ここから RAG Engine 関連のリソースを作成していきます。
はじめに RAG コーパスを作成しますが、この際に使用するエンベディングモデルやベクトル DB を指定することが可能です。
今回ベクトル DB はデフォルトの RagManagedDb を利用しますので明示的には何も指定していません。エンベディングモデルについても特に指定しない場合はデフォルトの text-embedding-004 が自動で選択されるのですが、今回はあえて明示的に指定しています。
# Create a RAG Corpus
# Configure embedding model, for example "text-embedding-004".
rag_embedding_model_config = rag.RagEmbeddingModelConfig(
rag.VertexPredictionEndpoint(
publisher_model=f"projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/text-embedding-004"
)
)
# Create RagCorpus
rag_corpus = rag.create_corpus(
display_name=display_name,
backend_config=rag.RagVectorDbConfig(
rag_embedding_model_config=rag_embedding_model_config
)
)
作成した RAG コーパスにファイルをインポートします。この際に chunk_size や chunk_overlap を指定しています。
# Import Files
# Cloud Storage bucket
paths = [f"gs://{BUCKET_NAME}"]
# Optional: Configure text chunking during ingestion
transformation_config = rag.TransformationConfig(
chunking_config=rag.ChunkingConfig(
chunk_size=512,
chunk_overlap=100
)
)
# Import Files to the RagCorpus
rag.import_files(
rag_corpus.name,
paths,
# Alternatively, you can import from SlackChannel, Jira, or SharePoint sources by using the `source` parameter
# Note: Specify one of paths or source
transformation_config=transformation_config, # Optional
max_embedding_requests_per_min=900, # Optional
)
imported_rag_files_count: 17
RAG コーパスに対してクエリが送信できる状態になりました。
RAG Engine API の retrieval_query というメソッドを利用して、What is RAG Engine? というクエリに対しての検索結果を見てみます。
# Retrieve relevant contexts
# Optional: Configure retrieval parameters
rag_retrieval_config = rag.RagRetrievalConfig(
top_k=10,
filter=rag.Filter(
vector_distance_threshold=0.5,
# Alternatively, you can filter based on vector similarity by using the `vector_similarity_threshold` parameter
# Note: Specify one of vector_distance_threshold or vector_similarity_threshold
)
)
# Direct context retrieval
response = rag.retrieval_query(
rag_resources=[
rag.RagResource(
rag_corpus=rag_corpus.name,
)
],
text="What is RAG Engine?",
rag_retrieval_config=rag_retrieval_config # Optional
)
print(response)
検索結果は次の通りです。
contexts {
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-overview.html"
source_display_name: "rag-overview.html"
text: "hybrid, and multicloud\n* Generative AI\n* Industry solutions\n* Networking\n* Observability and monitoring\n* Security\n* Storage\n \n \n \n \n * Access and resources management\n* Costs and usage management\n* Google Cloud SDK, languages, frameworks, and tools\n* Infrastructure as code\n* Migration\n \n \n \n \n * Google Cloud Home\n* Free Trial and Free Tier\n* Architecture Center\n* Blog\n* Contact Sales\n* Google Cloud Developer Center\n* Google Developer Center\n* Google Cloud Marketplace\n* Google Cloud Marketplace Documentation\n* Google Cloud Skills Boost\n* Google Cloud Solution Center\n* Google Cloud Support\n* Google Cloud Tech Youtube Channel\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n * Home\n* \n \n \n \n \n Generative AI on Vertex AI\n* \n \n \n \n \n Documentation\n \n \n \n \n \n \n \n \n \n \n \n \n Send feedback\n \n \n \n \n\nVertex AI RAG Engine overview\n \n \n \n \n \n Stay organized with collections\n \n \n \n Save and categorize content based on your preferences.\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n The VPC-SC security control is\n supported by RAG Engine. Data residency, CMEK, and AXT security controls aren\'t supported.\nVertex AI RAG Engine, a component of the Vertex AI\nPlatform, facilitates Retrieval-Augmented Generation (RAG).\nVertex AI RAG Engine is also a data framework for developing\ncontext-augmented large language model (LLM) applications. Context augmentation\noccurs when you apply an LLM to your data. This implements retrieval-augmented\ngeneration (RAG).\nA common problem with LLMs is that they don\'t understand private knowledge, that\nis, your organization\'s data. With Vertex AI RAG Engine, you can\nenrich the LLM context with additional private information, because the model\ncan reduce hallucination and answer questions more accurately.\nBy combining additional knowledge sources with the existing knowledge that LLMs\nhave, a better context is provided. The improved context along with the query\nenhances the quality of the LLM\'s response.\nThe following image illustrates the key concepts to understanding\nVertex AI RAG Engine.\n!"
score: 0.30727602372724383
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-overview.html"
source_display_name: "rag-overview.html"
text: "Vertex AI RAG Engine overview | Generative AI on Vertex AI | Google Cloud\n \n \n \n {\n \"@context\": \"https://schema.org\",\n \"@type\": \"Article\",\n \n \"headline\": \"Vertex AI RAG Engine overview\"\n }\n {\n \"@context\": \"https://schema.org\",\n \"@type\": \"BreadcrumbList\",\n \"itemListElement\": [{\n \"@type\": \"ListItem\",\n \"position\": 1,\n \"name\": \"Generative AI on Vertex AI\",\n \"item\": \"https://cloud.google.com/vertex-ai/generative-ai/docs/overview\"\n },{\n \"@type\": \"ListItem\",\n \"position\": 2,\n \"name\": \"Documentation\",\n \"item\": \"https://cloud.google.com/vertex-ai/generative-ai/docs/learn/overview\"\n },{\n \"@type\": \"ListItem\",\n \"position\": 3,\n \"name\": \"Vertex AI RAG Engine overview\",\n \"item\": \"https://cloud.google.com/vertex-ai/generative-ai/docs/rag-overview\"\n }]\n }\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n !"
score: 0.31352253624994963
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-quickstart.html"
source_display_name: "rag-quickstart.html"
text: "# rag_file_ids=[\"rag-file-1\", \"rag-file-2\", ...],\n )\n ],\n text=\"What is RAG and why it is helpful?\",\n similarity_top_k=10, # Optional\n vector_distance_threshold=0.5, # Optional\n)\nprint(response)\n# Enhance generation\n# Create a RAG retrieval tool\nrag_retrieval_tool = Tool.from_retrieval(\n retrieval=rag.Retrieval(\n source=rag.VertexRagStore(\n rag_resources=[\n rag.RagResource(\n rag_corpus=rag_corpus.name, # Currently only 1 corpus is allowed.\n # Optional: supply IDs from `rag.list_files()`.\n # rag_file_ids=[\"rag-file-1\", \"rag-file-2\", ...],\n )\n ],\n similarity_top_k=3, # Optional\n vector_distance_threshold=0.5, # Optional\n ),\n )\n)\n# Create a gemini-pro model instance\nrag_model = GenerativeModel(\n model_name=\"gemini-1.5-flash-001\", tools=[rag_retrieval_tool]\n)\n# Generate response\nresponse = rag_model.generate_content(\"What is RAG and why it is helpful?\")\nprint(response.text)\n# Example response:\n# RAG stands for Retrieval-Augmented Generation.\n# It\'s a technique used in AI to enhance the quality of responses\n# ...\n```\n\nWhat\'s next\n* To learn more about the RAG API, see [Vertex AI RAG Engine\nAPI](/vertex-ai/generative-ai/docs/model-reference/rag-api).\n* To learn about the Vertex AI RAG Engine, see the\nVertex AI RAG Engine overview.\n \n \n \n \n \n \n \n \n \n \n \n \n \n Send feedback\n \n \n \n \n \n \n \n \n \n \n Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.\n Last updated 2024-12-20 UTC.\n \n \n \n \n \n \n \n \n Need to tell us more?"
score: 0.322444714761425
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-quotas.html"
source_display_name: "rag-quotas.html"
text: "* To learn about the differences between RAG and grounding, see [Ground\nresponses using RAG](/vertex-ai/generative-ai/docs/ground-responses-using-rag).\n* To learn about the RAG architecture:\n\t+ Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search\n\t+ Infrastructure for a RAG-capable generative AI application using Vertex AI and AlloyDB for PostgreSQL.\n \n \n \n \n \n \n \n \n \n \n \n \n \n Send feedback\n \n \n \n \n \n \n \n \n \n \n Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.\n Last updated 2024-12-20 UTC.\n \n \n \n \n \n \n \n \n Need to tell us more?\n \n \n \n \n \n \n [[[\"Easy to understand\",\"easyToUnderstand\",\"thumb-up\"],[\"Solved my problem\",\"solvedMyProblem\",\"thumb-up\"],[\"Other\",\"otherUp\",\"thumb-up\"]],[[\"Hard to understand\",\"hardToUnderstand\",\"thumb-down\"],[\"Incorrect information or sample code\",\"incorrectInformationOrSampleCode\",\"thumb-down\"],[\"Missing the information/samples I need\",\"missingTheInformationSamplesINeed\",\"thumb-down\"],[\"Other\",\"otherDown\",\"thumb-down\"]],[\"Last updated 2024-12-20 UTC."
score: 0.32987539339563876
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-overview.html"
source_display_name: "rag-overview.html"
text: "With Vertex AI RAG Engine, you can\nenrich the LLM context with additional private information, because the model\ncan reduce hallucination and answer questions more accurately.\nBy combining additional knowledge sources with the existing knowledge that LLMs\nhave, a better context is provided. The improved context along with the query\nenhances the quality of the LLM\'s response.\nThe following image illustrates the key concepts to understanding\nVertex AI RAG Engine.\n\nThese concepts are listed in the order of the retrieval-augmented generation\n(RAG) process.\n1. **Data ingestion**: Intake data from different data sources. For example,\nlocal files, Cloud Storage, and Google Drive.\n2. **Data transformation**:\nConversion of the data in preparation for indexing. For example, data is\nsplit into chunks.\n3. **Embedding**: Numerical\nrepresentations of words or pieces of text. These numbers capture the\nsemantic meaning and context of the text. Similar or related words or text\ntend to have similar embeddings, which means they are closer together in the\nhigh-dimensional vector space.\n4. **Data indexing**: Vertex AI RAG Engine creates an index called a corpus.\nThe index structures the knowledge base so it\'s optimized for searching. For\nexample, the index is like a detailed table of contents for a massive\nreference book.\n5. **Retrieval**: When a user asks a question or provides a prompt, the retrieval\ncomponent in Vertex AI RAG Engine searches through its knowledge\nbase to find information that is relevant to the query.\n6. **Generation**: The retrieved information becomes the context added to the\noriginal user query as a guide for the generative AI model to generate\nfactually grounded and relevant responses.\n\nSupported regions\nVertex AI RAG Engine is supported in the following regions:\n| Region | Location | Description | Launch stage |\n| `europe-west3` | Frankfurt, Germany | Only `v1beta1` version is supported. | Preview |\n| `us-central1` | Iowa | `v1` and `v1beta1` versions are supported."
score: 0.3299165834413782
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-quickstart.html"
source_display_name: "rag-quickstart.html"
text: "Prepare your Google Cloud console\nTo use Vertex AI RAG Engine, do the following:\n1. Install the Vertex AI SDK for Python.\n2. Run this command in the Google Cloud console to set up your project.\n`gcloud config set {project}`\n3. Run this command to authorize your login.\n`gcloud auth application-default login`\n\nRun Vertex AI RAG Engine\nCopy and paste this sample code into the Google Cloud console to run Vertex AI RAG Engine.\n\nPython\n```\nfrom vertexai import rag\nfrom vertexai.generative_models import GenerativeModel, Tool\nimport vertexai\n# Create a RAG Corpus, Import Files, and Generate a response\n# TODO(developer): Update and un-comment below lines\n# PROJECT_ID = \"your-project-id\"\n# display_name = \"test_corpus\"\n# paths = [\"https://drive.google.com/file/d/123\", \"gs://my_bucket/my_files_dir\"] # Supports Google Cloud Storage and Google Drive Links\n# Initialize Vertex AI API once per session\nvertexai.init(project=PROJECT_ID, location=\"us-central1\")\n# Create RagCorpus\n# Configure embedding model, for example \"text-embedding-004\".\nembedding_model_config = rag.EmbeddingModelConfig(\n publisher_model=\"publishers/google/models/text-embedding-004\"\n)\nrag_corpus = rag.create_corpus(\n display_name=display_name,\n embedding_model_config=embedding_model_config,\n)\n# Import Files to the RagCorpus\nrag.import_files(\n rag_corpus.name,\n paths,\n chunk_size=512, # Optional\n chunk_overlap=100, # Optional\n max_embedding_requests_per_min=900, # Optional\n)\n# Direct context retrieval\nresponse = rag.retrieval_query(\n rag_resources=[\n rag.RagResource(\n rag_corpus=rag_corpus.name,\n # Optional: supply IDs from `rag.list_files()`.\n # rag_file_ids=[\"rag-file-1\", \"rag-file-2\", ...],\n )\n ],\n text=\"What is RAG and why it is helpful?"
score: 0.33937644934144162
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/use-weaviate-db.html"
source_display_name: "use-weaviate-db.html"
text: "For more information, see the launch stage descriptions.\n Further, by using the Gemini API on Vertex AI, you agree to the Generative AI Preview terms and conditions (Preview\n Terms).\n \n The VPC-SC security control is\n supported by RAG Engine. Data residency, CMEK, and AXT security controls aren\'t supported.\nTo see an example of using RAG Engine with Weaviate,\n run the \"RAG Engine with Weaviate\" Jupyter notebook in one of the following\n environments:\n \n[Open\nin Colab](https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/gemini/rag-engine/rag_engine_weaviate.ipynb)\n \n \n | \n \n[Open\nin Colab Enterprise](https://console.cloud.google.com/vertex-ai/colab/import/https%3A%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Frag-engine%2Frag_engine_weaviate.ipynb)\n \n \n | \n \n[Open\nin Vertex AI Workbench user-managed notebooks](https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https%3A%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Frag-engine%2Frag_engine_weaviate.ipynb)\n \n \n | \n \nView on GitHub\nThis page shows you how to connect your RAG Engine corpus to your Weaviate\ndatabase.\nYou can also follow along using this notebook RAG Engine with Weaviate.\nYou can use your Weaviate database instance, which is an open source database,\nwith RAG Engine to index and conduct a vector-based similarity search. A\nsimilarity search is a way to find pieces of text that are similar to the text\nthat you\'re looking for, which requires the use of an [embedding\nmodel](/vertex-ai/generative-ai/docs/use-embedding-models). The embedding model produces vector\ndata for each piece of text being compared. The similarity search is used to\nretrieve semantic contexts for grounding to\nreturn the most accurate content from your LLM."
score: 0.34956474382103808
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/use-vertexai-search.html"
source_display_name: "use-vertexai-search.html"
text: "For more information, see the launch stage descriptions.\n Further, by using the Gemini API on Vertex AI, you agree to the Generative AI Preview terms and conditions (Preview\n Terms).\n \n The VPC-SC security control is\n supported by RAG Engine. Data residency, CMEK, and AXT security controls aren\'t supported.\nTo see an example of using RAG Engine with Vertex AI Search,\n run the \"RAG Engine with Vertex AI Search\" Jupyter notebook in one of the following\n environments:\n \n[Open\nin Colab](https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/gemini/rag-engine/rag_engine_vertex_ai_search.ipynb)\n \n \n | \n \n[Open\nin Colab Enterprise](https://console.cloud.google.com/vertex-ai/colab/import/https%3A%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Frag-engine%2Frag_engine_vertex_ai_search.ipynb)\n \n \n | \n \n[Open\nin Vertex AI Workbench user-managed notebooks](https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https%3A%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Frag-engine%2Frag_engine_vertex_ai_search.ipynb)\n \n \n | \n \nView on GitHub\nThis page introduces Vertex AI Search integration with the\nVertex AI RAG Engine.\nVertex AI Search provides a solution for retrieving and managing\ndata within your Vertex AI RAG applications. By using\nVertex AI Search as your retrieval backend, you can improve\nperformance, scalability, and ease of integration.\n* **Enhanced performance and scalability**: Vertex AI Search is\ndesigned to handle large volumes of data with exceptionally low latency. This\ntranslates to faster response times and improved performance for your RAG\napplications, especially when dealing with complex or extensive knowledge\nbases.\n* **Simplified data management**: Import your data from various sources, such as\nwebsites, BigQuery datasets, and Cloud Storage buckets, that\ncan streamline your data ingestion process."
score: 0.3496084278770234
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-overview.html"
source_display_name: "rag-overview.html"
text: "Supported regions\nVertex AI RAG Engine is supported in the following regions:\n| Region | Location | Description | Launch stage |\n| `europe-west3` | Frankfurt, Germany | Only `v1beta1` version is supported. | Preview |\n| `us-central1` | Iowa | `v1` and `v1beta1` versions are supported. | GA |\n\nWhat\'s next\n* To learn how to use the Vertex AI SDK to run\nVertex AI RAG Engine tasks, see [RAG quickstart for\nPython](/vertex-ai/generative-ai/docs/rag-quickstart).\n* To learn about grounding, see [Grounding\noverview](/vertex-ai/generative-ai/docs/grounding/overview).\n* To learn about the differences between RAG and grounding, see [Ground\nresponses using RAG](/vertex-ai/generative-ai/docs/ground-responses-using-rag).\n* To learn about the RAG architecture:\n\t+ Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search\n\t+ Infrastructure for a RAG-capable generative AI application using Vertex AI and AlloyDB for PostgreSQL.\n \n \n \n \n \n \n \n \n \n \n \n \n \n Send feedback\n \n \n \n \n \n \n \n \n \n \n Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.\n Last updated 2024-12-20 UTC.\n \n \n \n \n \n \n \n \n Need to tell us more?\n \n \n \n \n \n \n [[[\"Easy to understand\",\"easyToUnderstand\",\"thumb-up\"],[\"Solved my problem\",\"solvedMyProblem\",\"thumb-up\"],[\"Other\",\"otherUp\",\"thumb-up\"]],[[\"Hard to understand\",\"hardToUnderstand\",\"thumb-down\"],[\"Incorrect information or sample code\",\"incorrectInformationOrSampleCode\",\"thumb-down\"],[\"Missing the information/samples I need\",\"missingTheInformationSamplesINeed\",\"thumb-down\"],[\"Other\",\"otherDown\",\"thumb-down\"]],[\"Last updated 2024-12-20 UTC."
score: 0.35083362040458044
}
contexts {
source_uri: "gs://MY-BUCKET-NAME/rag-quotas.html"
source_display_name: "rag-quotas.html"
text: "The VPC-SC security control is\n supported by RAG Engine. Data residency, CMEK, and AXT security controls aren\'t supported.\nFor each service to perform retrieval-augmented generation (RAG) using RAG Engine, the\nfollowing quotas apply, with the quota measured as requests per minute (RPM).\nService,Quota,Metric\nRAG Engine data management APIs,60 RPM,`VertexRagDataService requests per minute per region`\n`RetrievalContexts` API,1,500 RPM,`VertexRagService retrieve requests per minute per region`\n`base_model: textembedding-gecko`,1,500 RPM,`Online prediction requests per base model per minute per region per base_model`An additional filter for you to specify is `base_model: textembedding-gecko`\nThe following limits apply:\nService,Limit,Metric\nConcurrent `ImportRagFiles` requests,3 RPM,`VertexRagService concurrent import requests per region`\nMaximum number of files per `ImportRagFiles` request,10,000,`VertexRagService import rag files requests per region`\nFor more rate limits and quotas, see [Generative AI on Vertex AI\nrate limits](/vertex-ai/generative-ai/docs/quotas).\n\nWhat\'s next\n* To learn how to use the Vertex AI SDK to run\nVertex AI RAG Engine tasks, see [RAG quickstart for\nPython](/vertex-ai/generative-ai/docs/rag-quickstart).\n* To learn about grounding, see [Grounding\noverview](/vertex-ai/generative-ai/docs/grounding/overview).\n* To learn about the differences between RAG and grounding, see [Ground\nresponses using RAG](/vertex-ai/generative-ai/docs/ground-responses-using-rag).\n* To learn about the RAG architecture:\n\t+ Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search\n\t+ Infrastructure for a RAG-capable generative AI application using Vertex AI and AlloyDB for PostgreSQL."
score: 0.35789881162537995
}
}
質問と関連性の高い上位 10 件 (top_k で指定した件数) のコンテキストが抽出されていました。尚、HTML もきちんとパースされているように見えます。
いよいよ今回の主題である RAG Engine + Gemini API を組み合わせた RAG を実行していきます。
先ほどは retrieval_query メソッドで RAG コーパスに対して直接クエリを送信しましたが、実際にアプリケーションに組み込む際には、RAG 検索ツールを作成 (定義) した上で、Gemini へのリクエスト送信時に同ツールを指定することで RAG を実行することができます。
# IMPORTANT: Migrated to google.genai due to deprecation of vertexai.generative_models
# NOTE: Migrated from vertexai.generative_models.Tool to google.genai.types.Tool.
# # Create a RAG retrieval tool
# rag_retrieval_tool = Tool.from_retrieval(
# retrieval=rag.Retrieval(
# source=rag.VertexRagStore(
# rag_resources=[
# rag.RagResource(
# rag_corpus=rag_corpus.name,
# )
# ],
# rag_retrieval_config=rag_retrieval_config # Optional
# ),
# )
# )
# Create a RAG retrieval tool for the RAG Corpus
rag_retrieval_tool = Tool(
retrieval=Retrieval(
vertex_rag_store=VertexRagStore(
rag_corpora=[rag_corpus.name],
similarity_top_k=10,
vector_distance_threshold=0.5,
)
)
)
# NOTE: Migrated from vertexai.generative_models.GenerativeModel to google.genai.Client.
# # Create a gemini-flash model instance
# rag_model = GenerativeModel(
# model_name="gemini-1.5-flash-002", tools=[rag_retrieval_tool]
# )
# # Generate response
# response = rag_model.generate_content("What are the default values for chunk_size and chunk_overlap?")
# Configure the Gen AI client and tools
client = genai.Client()
config = GenerateContentConfig(tools=[rag_retrieval_tool],)
# Generate response
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="What are the default values for chunk_size and chunk_overlap?",
config=config,
)
print(response.text)
今回クエリには What are the default values for chunk_size and chunk_overlap? というより具体的な質問を送信してみます。
The default chunk size is 1,024 tokens, and the default chunk overlap is 200 tokens.
きちんとドキュメントの内容を踏まえた回答が返ってきていました。
Vertex AI Studio 経由で利用
これまで RAG Engine API を利用して RAG コーパスの作成および RAG を実行する方法を解説しましたが、この度の GA に伴い、Vertex AI Studio (GUI) 経由でも RAG Engine を利用することが可能となりました。
具体的には AI Studio の右側のメニューからグラウンディングを有効にし、カスタマイズを選択すると RAG Engine ならびに先ほど作成した RAG コーパスが選択できるようになっています。
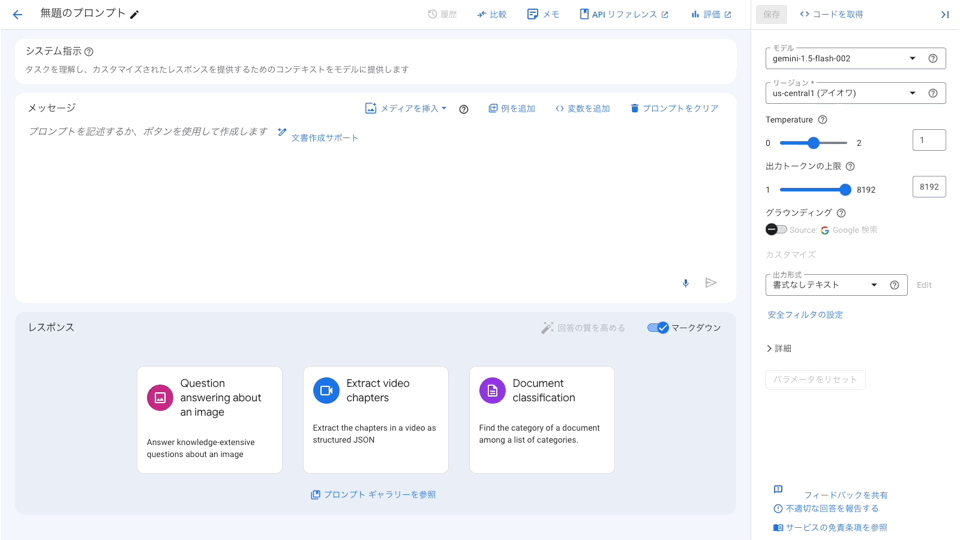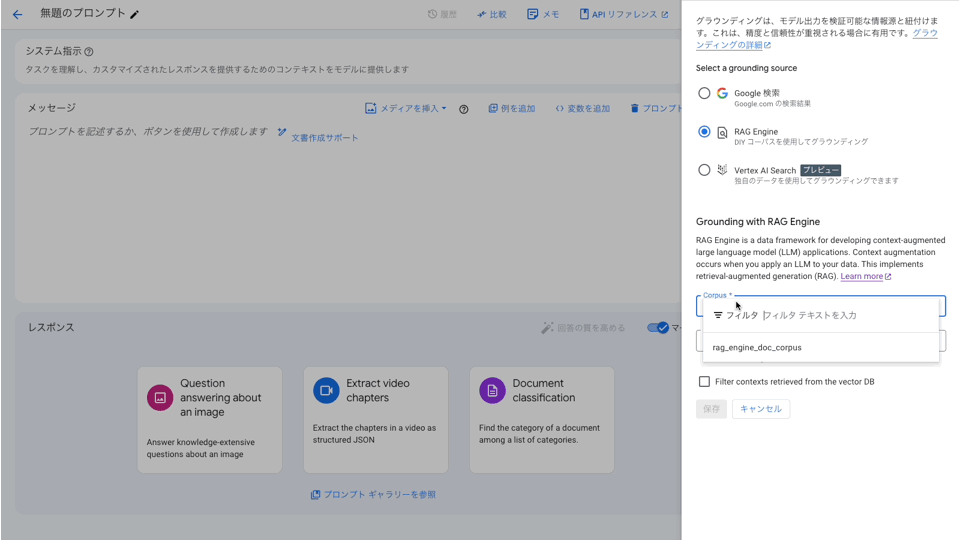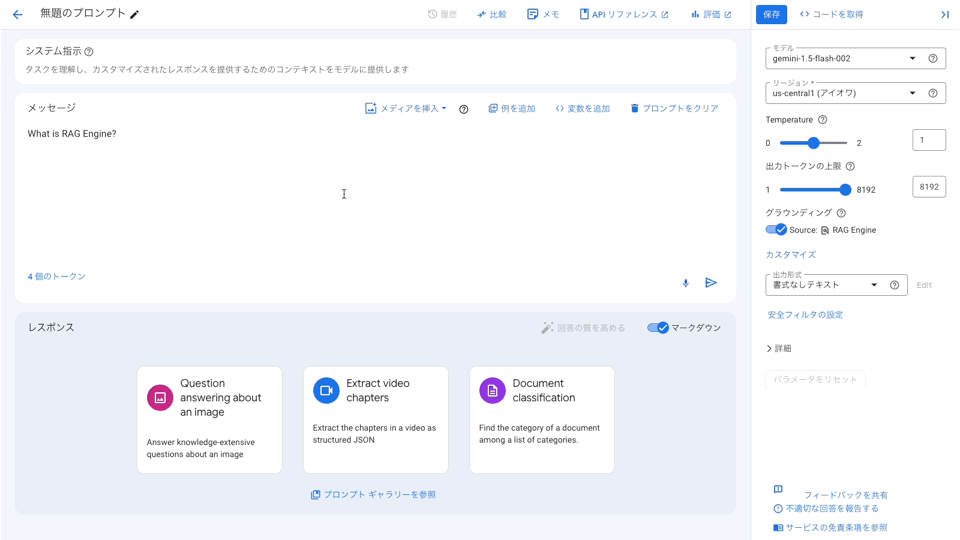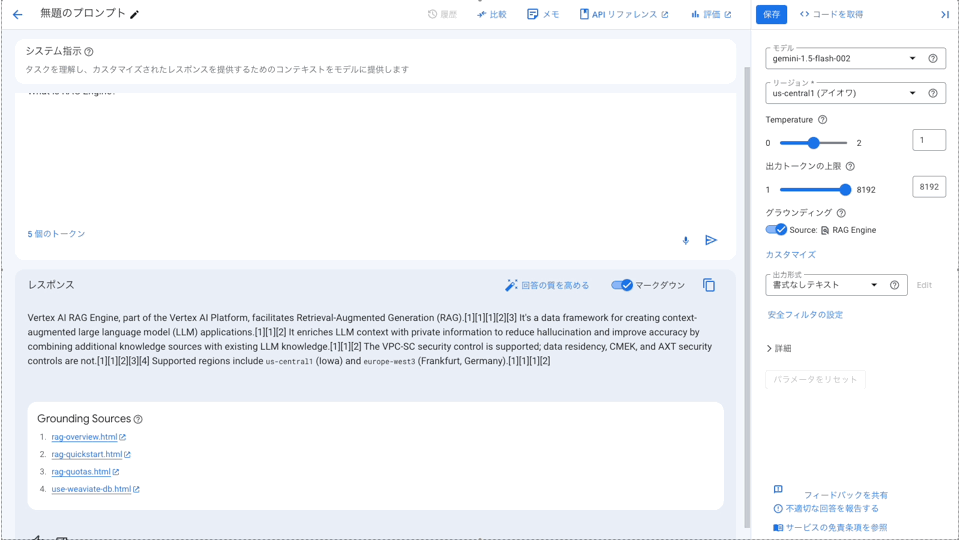
また Top-k Similarity の件数や Vector Distance Threshold or Vector Similarity Threshold のフィルタ条件・閾値もこちらの画面上で設定が可能となっています。
まとめ
- 本記事では、GA となった RAG Engine の概要、利用方法、そして RAG Engine API と Vertex AI Studio を利用した RAG の実行方法について解説しました
- RAG Engine を利用することで、カスタム RAG アプリケーションを簡単に実装し、Gemini をはじめとする LLM の能力を最大限に引き出すことができます
- 最後にクリーンアップもお忘れなく!
メリークリスマスっ🎄✨

Discussion