Google Cloud Japan Advent Calendar 2024 1 日目です!
みなさん、生成 AI くんとは仲良くなれていますか?日々一緒に仕事していますか?
私にとっては、そしておそらく多くの同僚にとっても、いまや自社の生成 AI である Gemini は完全に仕事のパートナーです。最近ガートナーのハイプ・サイクルにおける生成 AI の位置が少し話題になっていましたが、渦中の弊社においては幻滅しているどころではなく、いまや "生産性の安定期" に入っているとさえ感じます。
そんなわけで今日は、Google 社内でも特にソフトウェア開発にフォーカスして、AI 活用に関する実験やその結果をお届けしようと思います。

2024 年 10 月の発表
まずはこちらをご覧ください。
Google の CEO、スンダー・ピチャイが先日の決算報告会でした発表からの抜粋です。

このスンダーの絵は Imagen3 が描いてくれました
- 現在、Google のすべての新しいコードの 4 分の 1 以上は AI によって生成され、エンジニアによってレビュー・承認されている
- これによりエンジニアは、より多くの作業を、より速く実行できるようになる
25% 以上という数字、多いか少ないかは意見が分かれるかもしれません。しかしそれはさておき、結果として Google 全体で一体何時間がより生産的な仕事に回ったと思いますか?
そしてこれはどのように実現できたのでしょうか?
実は、これらに関する情報は一部 Google Research から公開されています。
どんな段階を経てきたのか、過去から遡って確認してみましょう!
2022 年 7 月: 機械学習によって強化されたコード補完
2 年前、まだ ChatGPT が世に出る前、Google Research からこんな取り組みが公開されました。
従来、コード補完といえば あらかじめ定義されたルールに基づいて コードの構文や意味を解釈、補完候補を生成するものですよね。この実験は、文脈を考慮した単一行の補完候補を Transformer ベースの ML モデルを使って再ランクしたり、後続の複数行を追加で生成したり、逆に ML に生成させた単一行の補完候補を既存のルールベースのロジックで正確性を確認するといった「ハイブリッド セマンティック ML コード補完」を開発・テストしてみたよ、というものです。
結果を見てみましょう。
単一行の場合
- エンジニアの提案受け入れ率
25% - 受け入れあたり平均
21 文字 - 新規追加コード全体のうち ML 生成割合
2.6%
複数行の場合
- エンジニアの提案受け入れ率
34% - 受け入れあたり平均
73 文字 - 新規追加コード全体のうち ML 生成割合
0.6%
ここで実装上の重要な工夫の一つは、ML とルールベースのいいとこどりをしつつ、不足を補い合うように併用している、ということです。
本文にある通り、ML だとコンパイルできない候補が生成されがちですが、その一因はモデル学習後もリポジトリがどんどん変化していくことです。2020 年には RAG に関する論文もでていましたが、ここではもっと手軽で高性能、計算コストも低いであろう既存ロジックを併用することでこの課題を補っています。
新しいコードの 4 分の 1 以上は.. の件に関しては、この時点では 3% のようですね。
2023 年 5 月: ソフトウェア開発用大規模モデルの学習
そんな実験と並行し、Google はどのようにこの種の ML モデルを作るかという課題にも取り組んでいました。以下は 2023 年に公表したその手法、DIDACT です。
Google ではソフトウェア開発のためのツール群は内製していますが、結果としてコードに関連するすべての操作ログを大量に保有しています。DIDACT はそのエンジニアとツールの過去のやり取りを利用して ML モデルを強化、開発者がコンテキストに応じたアクションを実行できるよう支援します。
下図右側のように、エンジニアは不具合を修正したり、レビューに基づいてコードを変更したり、いろいろな目的でコードを追加・変更しますよね。それらを抽象化すると、いずれもまず 状態 (State) があり、それに対する 何らかの意図 (Intent) があり、その意図に沿って 行動 (Action) を起こすというセットです。この 状態 - 意図 - 行動 の形式化により、さまざまなタスクを一般的な方法で記述でき、DIDACT はこれを軸にモデルを学習します。

DIDACT によって学習したモデルに開発者が最近行った操作を渡すことで、モデルは開発者が次に行うべき操作をより正確に推測できることもわかっています。次のアニメーションは、関数のパラメタ追加に伴って、モデルが適切なドキュメント文字列の位置にカーソルを移動、補完を行っている様子です。
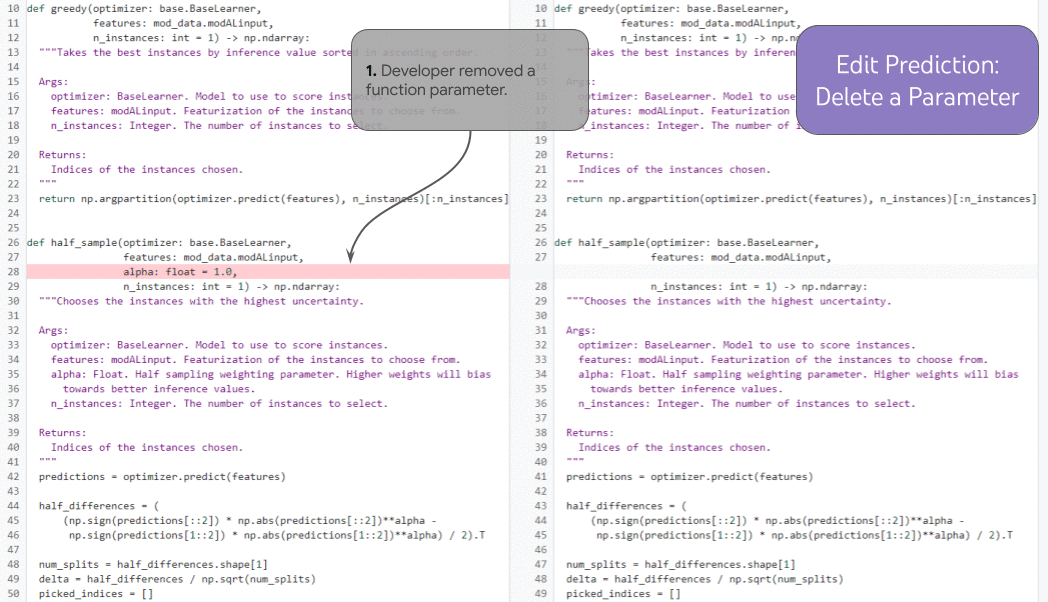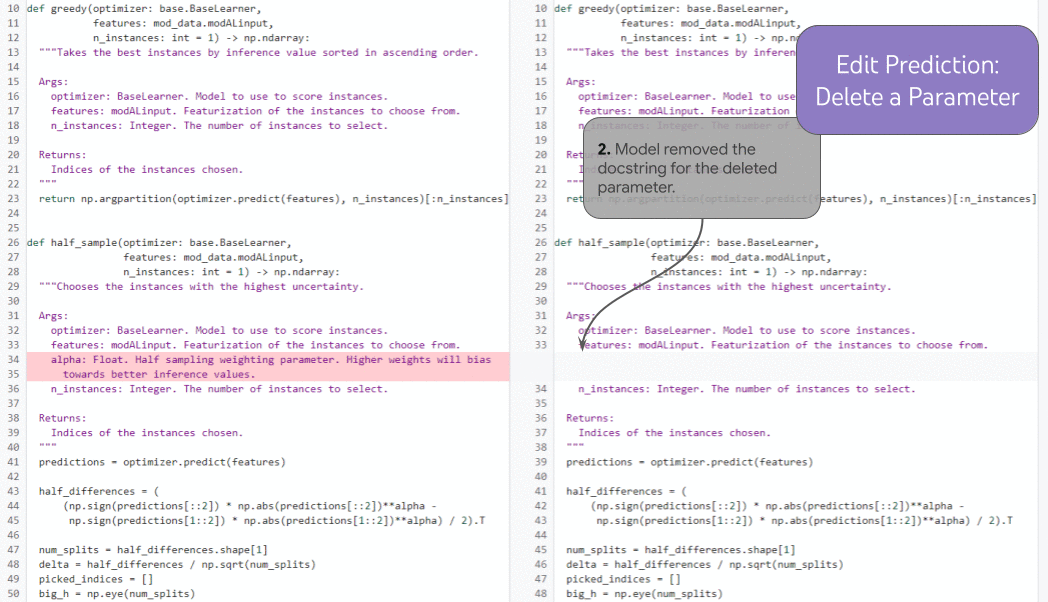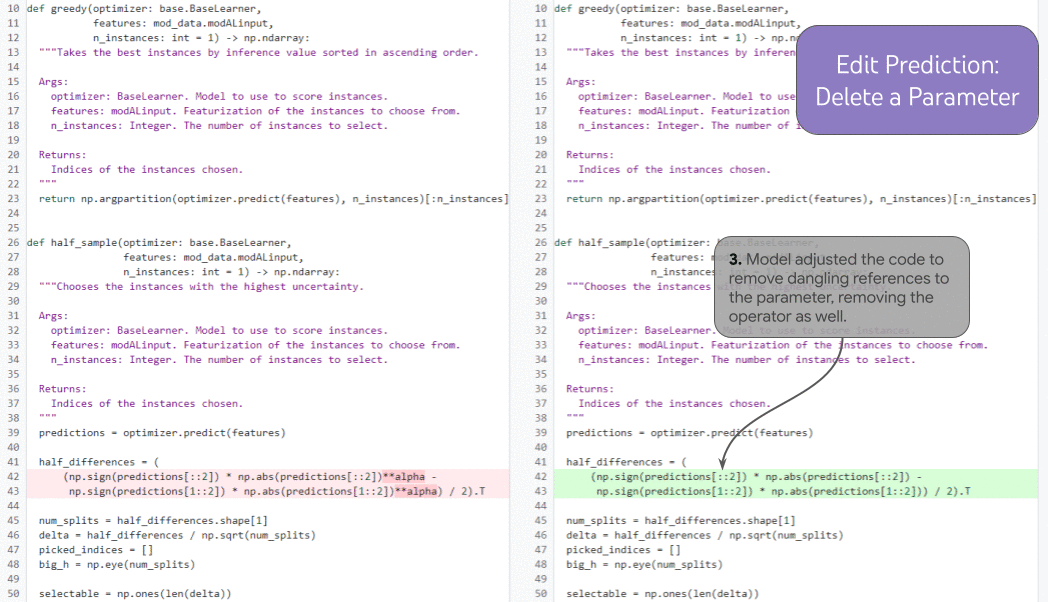
記事の結論には These innovations are already powering tools enjoyed by Google developers every day. とあります。私は冒頭、社内では生成 AI が "生産性の安定期" のように感じると書きましたが、こういった支援機能がいつの間にかルールベースのそれから生成 AI による実装に拡張されているのはその好例と言えそうです。
2023 年 5 月時点の成果
実際この手法による結果はとても良好です。
Google においてとても時間がかかっている工程のひとつはコードレビューです。Google の開発ツール群を横断して開発者の行動を調査・分析する社内システム、InSession を使った考察 によると、アクティブなシェパーディング(レビューに対処し始めてから、議論しつつ、対応が完了するまで)には平均 60 分かかっています。
年間数百万のレビューに対処している Google においては、DIDACT による ML が提案する編集を利用することで、年間数十万時間削減されると期待されています。
2024 年 6 月: AI ベースの開発者支援の進捗とこれから
今年 6 月には最新の成果も公表されました。そして継続的に環境を改善する過程で、担当チームがどういった基準でアイディアをシステムに導入し、何を計測・モニタリングしているかといったこともまとめられています。
受け入れ率は 37% に改善し、(スンダーのいう "すべての新しいコード" ではなく)"コード補完によって" 実際にリポジトリに入った文字列の 50% は AI 由来となっています。

AI が提案し受け入れられた文字数を、手入力した文字数と AI 由来の文字数の合計で割ったもの
この成果を支えた機能は以下の通りですが
- 上述のコードレビュー時のコメント対応(その 8% 以上が AI による支援)
- コピペ時、周囲のコンテキストに自動的に適用させるためのコード変更提案
- IDE に自然言語でコード編集を実行するよう指示する機能
- ビルドの失敗に対する修正予測
- コードの読みやすさに関するヒントを提示する
このような機能があっても、現場に気付いてもらい、採用されなければ意味がありません。

- モデルの提案に十分な信頼性があるか
- モデルは十分に速く提案できるか
- ユーザーはその提案に気付くか
大規模に使ってもらうための不断の努力が垣間見えます。
壊れたビルドを ML の提案に沿って修正しても安全か
Google 社内の実績においては 安全性に悪影響はなく、開発者の生産性が向上しました。
上述の「ビルドの失敗に対する修正予測」についての研究にその様子がまとめられています。
しかし業界一般には、コード生成 ML モデルによってバグが生まれ、それが開発者の目をすり抜ける可能性が指摘されています。そこで Google ではコードベースの品質と安全性を維持するため、ML が生成する修正に独自の後処理を適用し、コードの脆弱性といった一般的な品質と安全性の落とし穴を回避する努力がなされています。
生産性については以下の改善が見られています。
- 変更リスト(レビューに提出する単位)あたりのコーディング時間が
約 2%短縮 - 変更リストごとのシェパーディング時間も
約 2%短縮 - 1 週間あたりに送信される変更リストの平均数が
約 2%増加
実際の研究成果や取り組みは本文中にリンクがたくさんあります。
興味がある方は覗いてみてください!
さいごに
スンダーの何気ない一言、"新しいコードの 4 分の 1 以上は AI によって生成" の裏側はいかがでしたか?実は今年の Google Cloud Next では "Transforming software engineering with Google AI" という登壇があり、動画が公開されています。ご興味ある方はこちらもぜひご覧ください!
今日の話の多くは明日からみなさんが使えるものではありませんが、この手の改善に取り組まれている / 取り組もうとされている方のヒントになれば幸いです。
そして最後に宣伝です。Google Cloud にはこういった Google の知見が詰まった(もしくはこれから詰め込まれることが期待いただける)Gemini Code Assist という製品があります。Google のソフトウェア開発のための AI 投資に興味を持ってくださった方はぜひ、こちらもお試しください :)
それではみなさま、よい 2024 年末をお迎えください!
明日は MFA 有効化について です。お楽しみに〜

Discussion