この記事は Google Cloud Japan Advent Calendar 2022 (今から始める Google Cloud) の 6 日目(だったはず)の記事です。
今から始める Google Cloud ということで、これから Google Kubernetes Engine (以降 GKE) を使っていこうと考えられている方向けに GKE の基本的な特徴をご紹介しようと思います。(本記事で紹介する各機能・サービスの Product launch stages は記事執筆時点のものです)
本記事では(文量が多くなってしまうため) Kubernetes 自体のベーシックな話は割愛し、既に「Kubernetes とは?」を理解されている方向けに GKE の良さをお伝えできればと思っています。
ちなみにこの これから始める GKE はシリーズ化しようと思っていて、今後は設計に関する考慮ポイントなど細かめな話も書いていく予定です。
tl;dr
- GKE には 運用負荷を軽減するための各種自動化機能や高い拡張性が備わっています。また、幅広い GKE の周辺サービス・エコシステムを Google Cloud のマネージドサービスとして提供しています。
- これから GKE / Kubernetes を始める方には GKE Autopilot からお試しいただくのがお勧めです。Google のベストプラクティスが組み込まれたクラスタを簡単に使い始めることができます。(Autopilot では要件があわない場合は GKE Standard も検討してみましょう)
GKE とは
GKE は Google Cloud が提供するフルマネージドな Kubernetes プラットフォームです。Kubernetes をより簡単かつ安全に使っていただくための機能を多く持っています。
GKE のアーキテクチャとして、大きく Control Plane と Node というコンポーネントに分かれています。
そのうち Control Plane は Google が管理しており、利用者側で Control Plane の運用 (アップグレードやセキュリティ対策、スケール等) をしていただく必要はありません。
一方 Node は 利用者側で管理する GKE Standard もしくは Google で管理する GKE Autopilot という 2 つのモードから選ぶことができます。
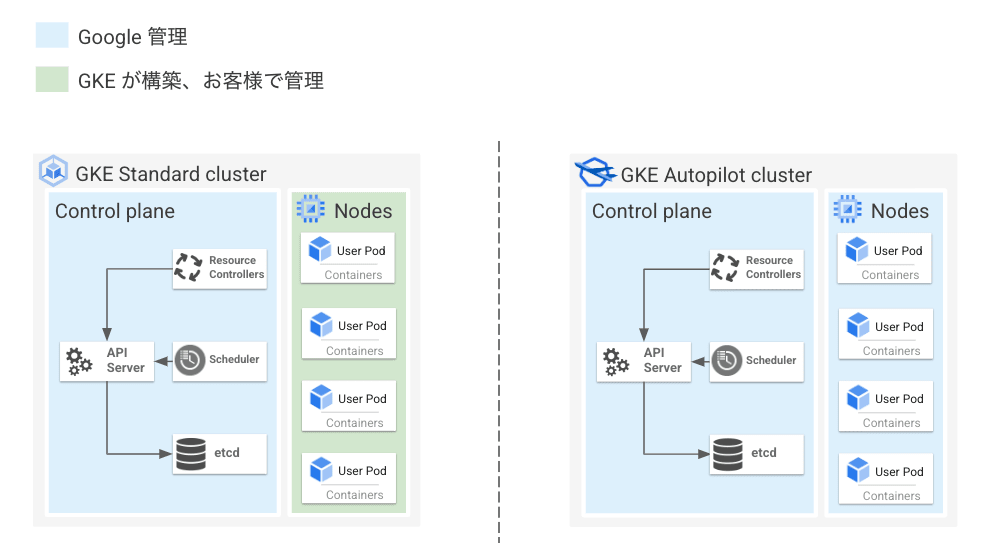
GKE Standard と GKE Autopilot (以降 Autopilot) の違いについては本記事後半で説明します。
一先ずざっくりと、従来の GKE クラスタが GKE Standard で、より簡単に運用できるようマネージド度合いが上がったものが Autopilot と考えていただければ大丈夫です。
ではここから、GKE の特徴について簡単にご紹介していきます。
特徴① 運用負荷を軽減するための各種自動化機能
まず 1 つ目の特徴として、GKE は以下のような Kuberentes クラスタをより簡単に運用するための各種自動化機能を持っているというのが挙げられます。
- 自動アップグレード
- 自動スケール
- 自動修復
サービスの成長に比例してKubernetes クラスタの運用負荷は増加しますので、より効率的に運用し作業負荷を軽減するために各種自動化機能を活用することが求められます。
本セクションでは、GKE が有する自動化機能の概要についてご紹介します。
アップグレードの負荷軽減
Kubernetes クラスタの運用の中でも特に負荷が高いのがアップグレード作業ではないでしょうか。
Kubernetes / GKE では脆弱性の対応や既知問題の修正、新機能の導入のためにアップデートを頻繁にリリースしています。リリースサイクルの早さはセキュリティ対策や新機能利用の観点から有難い反面、運用を担当している方にとっては辛みにもなっている部分かと思います。
GKE はこのアップグレードの運用負荷を低減するための機能を提供しているので、ここから簡単に紹介していきます。
リリースチャンネル
前述の通り、GKE の Control Plane は自動的にアップグレードされるので、そもそも利用者側でアップグレード作業をしていただく必要はありません。
一方 Node については手動でアップグレードすることもできますが、リリースチャンネルという仕組みを使って自動的にアップグレードすることもできます (Autopilot は自動アップグレードのみ利用可能です)。
リリースチャンネルとは、バージョニングとアップグレードを行う際のベストプラクティスを提供する仕組みです。リリースチャンネルにクラスタを登録すると、 Google により Control Plane だけでなく Node のバージョンとアップグレードサイクルも自動的に管理されるようになります。
リリースチャンネルは、利用できる機能や安定性の異なる以下 3 種類のチャンネルを提供しています。利用環境や求められる安定性等に応じて使い分けることが可能です。
- Rapid ... 最新のバージョンが利用可能。検証目的での利用を推奨 (SLA 対象外)
- Regular ... 機能の可用性とリリースの安定性のバランスが取れている
- Stable ... 最も安定したバージョンを提供。新機能よりも安定性を優先するケースで採用
自動アップグレードタイミングの制御
自動アップグレード自体は便利だけどクラスタが勝手にアップグレードされると困る、という方もいらっしゃるかと思います。
そこで GKE では自動アップグレードのタイミングをコントロールする仕組みも提供しています。
メンテナンスの時間枠という設定をしていただくことで、アップグレードなど自動メンテナンスを許可する時間枠を設定することができます。またメンテナンスの除外により、自動メンテナンスを禁止する期間を設定することもできます。
- メンテナンスの時間枠 ... 自動メンテナンスを許可する時間枠を設定。営業時間・ピーク時間帯を避けてアップグレードしてほしいケースやオンコール対応のしやすさなどから日中の業務時間帯にアップグレードをしてほしいケース等で利用
- メンテナンスの除外 ... 自動メンテナンスを禁止する時間枠を設定。大型イベント期間中や人手が足りない時期などアップグレードをしてほしくない期間を設定するケース等で利用。マイナーバージョンのアップグレード (例:1.22 -> 1.23) を最大 180 日間[1]停止することも可能
これらの機能を活用することにより、自動アップグレードによる思わぬサービス影響を抑えたり、人員の不足やイベントの期間中等を避けより安全なタイミングでアップグレードができるよう制御することが可能になります。
アップグレードに影響のある構成 / API 利用の検知
また、GKE には今後のマイナー バージョンでサポートされない構成や Kubernetes API がクラスタで利用されていることを自動的に検出し通知する Deprecation Insights という機能も提供しています (Preview)。
2022.12 現在 Deprecation Insights では以下 3 種類の Deprecation を検出することが可能です。
- 1.22 で削除予定の Kubernetes API の利用
- 1.23 でサポートされなくなる SAN の無い X.509 証明書の利用
- 1.24 でサポートされなくなる Docker ベースのノードイメージの利用
この機能により、削除予定の API の利用や次バージョンでサポートされない構成が検知されるとマイナーバージョンの自動アップグレードが一時停止される挙動となるため、知らないうちにクラスタがアップグレードされて手元のマニフェストと互換性がなくなっていた。。的なトラブルの発生を防ぐことが期待できます。(但し、各マイナーバージョンの EOL を過ぎた場合は強制的にアップグレードされてしまうので注意)
Node 手動アップグレードのオプション
前述の通り Node のアップグレードタイミングを自分でコントロールしたいという場合は手動アップグレードを選択することも可能です。
手動アップグレードといっても一連の Node アップグレード作業は自動的に実施されます。アップグレードのトリガーを利用者側でコントロールできるというのがポイントになります。
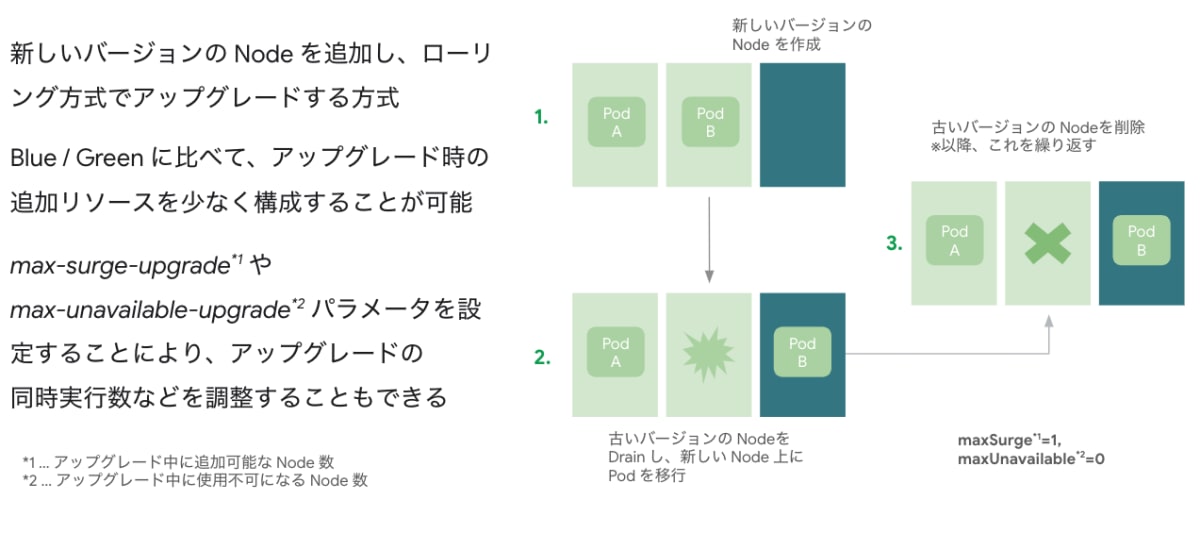
Node の手動アップグレードは Node Pool (同一マシンサイズ・構成の Node の集まり) 単位で以下 2 種類のアップグレード方式から選択可能です。(Release Channel など自動アップグレード利用の場合はサージアップグレードが選択されます)
-
サージアップグレード... デフォルトのアップグレード戦略。ノードを順次新しいバージョンにローリングアップデートする
-
Blue / Green アップグレード... 新旧2つのバージョンを保持したままアップグレードを行う。サージアップグレードに比べてロールバックが高速だが、アップグレード中に必要となるリソースが多い
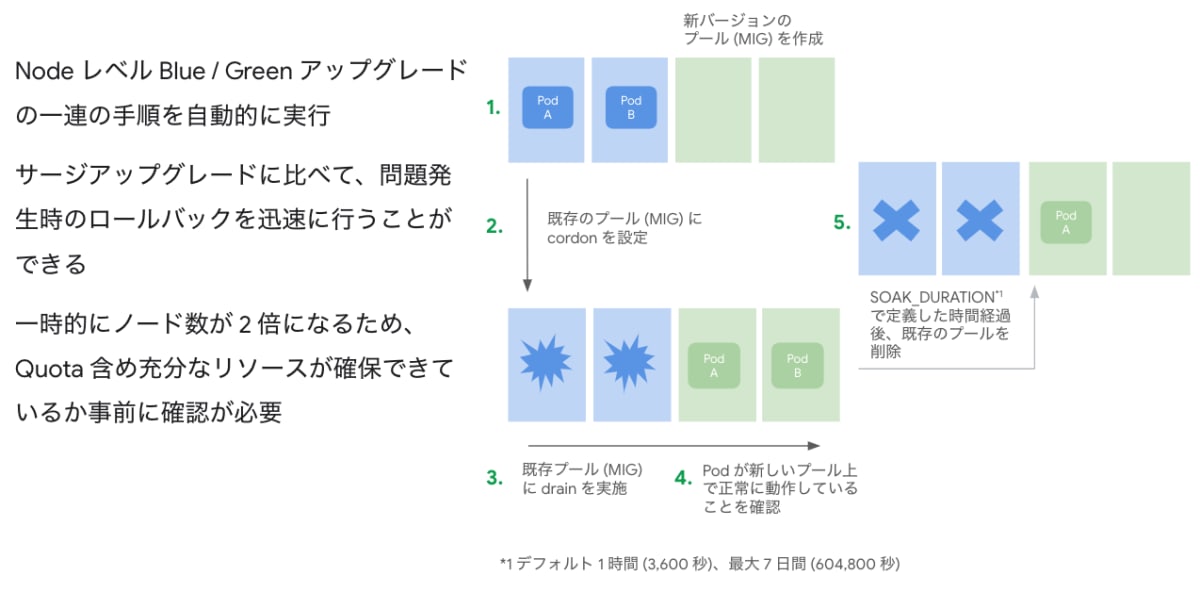
特に Blue / Green アップグレードなど、これまでは新旧複数バージョンの Node を用意して手動で切り替えることでアップグレードされていた方もいらっしゃったのではないかと思いますが、本機能をご利用いただくことで一連の作業を自動的に行うことができるようになります。
ここまででざっくりと GKE の自動アップグレードにおける特徴を説明しました。Kubernetes クラスタの運用のなかでも最も大変なのではないかと思うアップグレード作業の負荷を軽減してくれるのが GKE の大きな特徴の 1 つなのではないかと思います。
ちなみに GKE に元から入っているようなシステム系コンポーネントは GKE の Control Plane / Node のアップグレードとあわせて自動的にアップグレードされるので、コンポーネントごとに個別でアップグレードしていただく必要はありません。
自動スケール
新規ワークロードやバースト性があるワークロードなどは明確なリソース要件を事前に把握することが難しいのではないかと思います。リソースを多めに見積もるとオーバープロビジョニングでコストが想定よりもかかってしまう可能性もありますし、少なく見積もるとワークロードが正常に動作しなくなってしまう可能性もあります。
Kubernetes ではこのような課題を解決するための自動スケールの機能を元々持っていますが、GKE ではさらに独自に拡張したような自動スケール機能も存在しています。
本記事では GKE が有している以下 5 種類の Pod / Node のスケール機能のうち、特に特徴的な Multidimensional Pod Autoscaler (MPA) と Node Auto-Provisioning (NAP) という機能について紹介します。
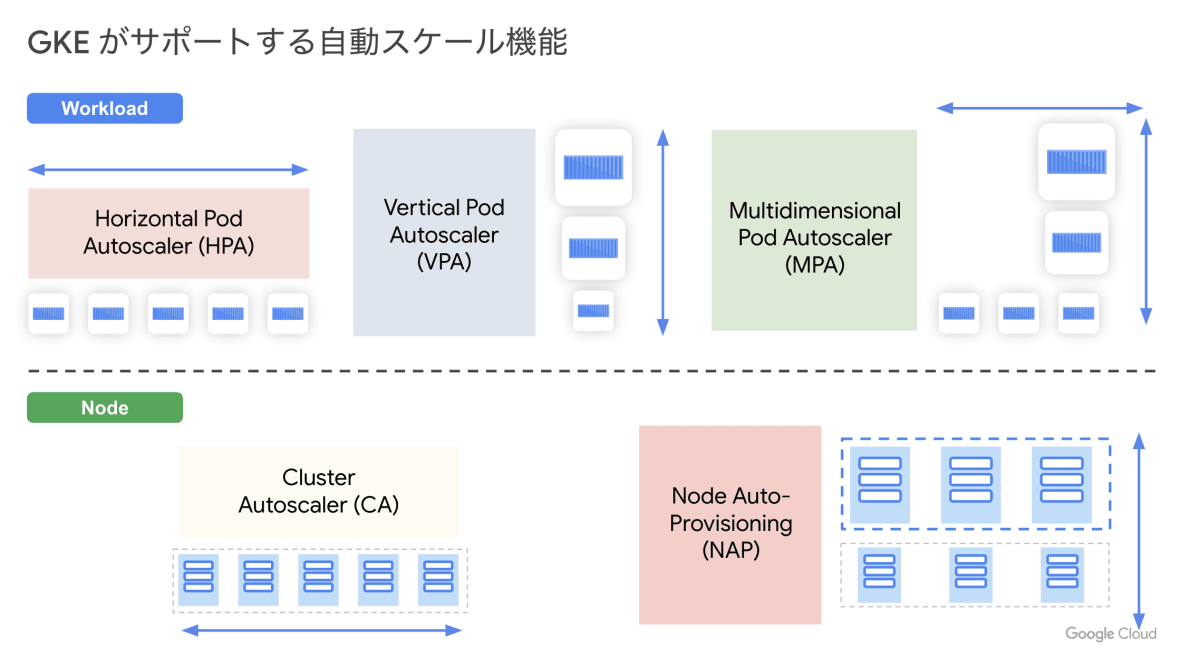
Multidimensional Pod Autoscaler (MPA)
MPA は Horizontal Pod Autoscaler (HPA) というワークロードの CPU やメモリの消費量等に応じて自動的に Pod 数を水平方向にスケールさせる機能と Vertical Pod Autoscaler (VPA) という実行中のワークロードを分析し、CPU やメモリの requests / limits 値の推奨値算出やリソース値を自動更新し垂直スケールさせる機能を併用したオートスケール機能です (Preview)。
本来、CPU やメモリの値をターゲットにした HPA と VPA を合わせて使うことは非推奨となっていますが、MPA を利用することでこの 2 つを安全に併用することができます。
MPA 自体は CPU ベースの HPA とメモリベースの VPA を組み合わせたオートスケールを 1 つのオブジェクト (MultidimPodAutoscaler) で制御しています。
ユースケースとしては CPU の利用率ベースで Pod 数を調整しつつ OOM が発生しないよう VPA によるメモリの垂直スケールも併せて行いたいようなケースでの利用が想定されます。
Node Auto-Provisioning (NAP)
NAP は Cluster Autoscaler (CA) の仕組みの 1 つで、ワークロードにフィットする Node Pool を自動的に作成・削除してくれる機能です。CA はワークロードの需要に基づいて特定 Node Pool 内の (同一マシンサイズの) Node 数を増減させてくれますが、NAP を使うとスケジューリングされた Pod のサイズに応じて適切なマシンサイズの Node Pool を動的にプロビジョニングしてくれるようになります。
これにより、ノードのサイジングを含めたリソース管理を GKE に任せることができ、またワークロードに合ったサイズのマシンがプロビジョニングされるためインフラリソースを効率的に活用することが可能になります。ちなみに GKE Autopilot では NAP を利用し Pod に必要な Node を自動的にプロビジョニングしています。
自動修復
GKE では Node が Unhealthy な状態になっていることを検知し、自動的に修復プロセスを開始する Node Auto Repair という機能も提供しています。
例えば以下のような状態の場合に Node が Unhealthy と判断され、対象 Node が Drain & 再作成されます。
- 約 10 分間、Node が NotReady ステータスを報告
- 約 10 分間、Node がステータスを何も報告しない
- 長期間(約 30 分間)、DiskPressure ステータスを報告
この機能はデフォルト有効です(Autopilot やリリースチャンネルに登録されているクラスタでは無効化できません)。
利用者側で Node 自体の健全性の確認やその復旧作業を実施する負荷が軽減できるため、特に理由がなければそのまま有効にしておくべき機能だと思います。
特徴② 高い拡張性
2 つ目の GKE の特徴として、高い拡張性を持っているというのが挙げられます。
例えば GKE Standard のクラスタあたりの最大ノード数は 15,000 です。(とはいえここまで大きなクラスタを実際に作るのはあまりお勧めしないので、数百数千 Node 以上の規模になる場合は一度 Google Cloud のカスタマーエンジニアにアーキテクチャやキャパシティのご相談いただくのが良いかと思います)
GKE は単純な Node 数上限の高さだけではなく、より大規模なワークロードの実行に適した構成オプションやリソース拡張のしやすい仕組みを提供しています。
Pod / Service IP レンジ
GKE ではPod の IP アドレスレンジを後から追加することができます。
これにより、サービスの成長に伴い設計当初の想定より多くの Pod をデプロイする必要がある場合などに、追加の Pod CIDR を設定した Node Pool をプロビジョニングすることで、クラスタで利用する IP アドレスレンジの枯渇を防ぐことが可能です。クラスタ構築時や初期の設計段階で余分な IP アドレスを割り振る必要がなくなり、アドレスレンジの有効活用もしやすくなるのではないかと思います。
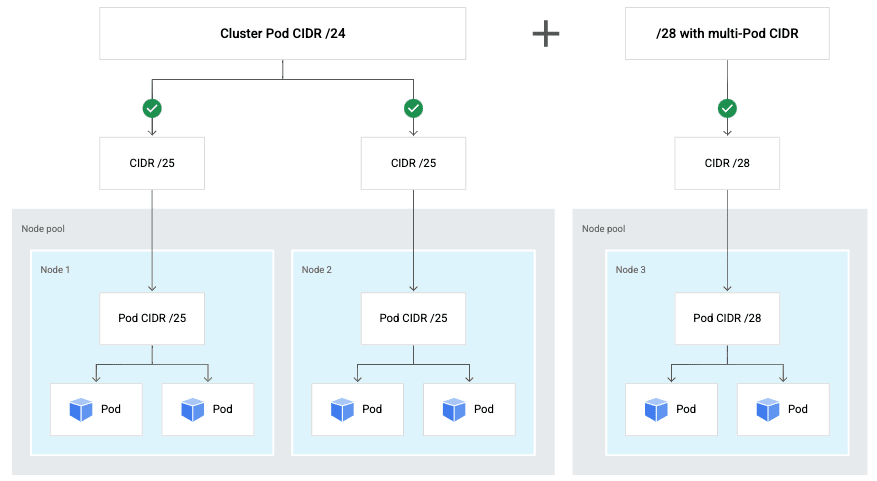
また Pod のアドレスレンジの追加だけでなく、Service リソース用のセカンダリ IP アドレスレンジをクラスタ間で共有することも可能です。Service の IP アドレスレンジをクラスタ間で共有することにより、複数クラスタを利用されている環境などで VPC 内の IP アドレスの節約に貢献できます。
これらの機能を活用することにより、より大規模な Kubernetes クラスタの運用がしやすくなるのではないかと思います。
クラスタ内 DNS
続いて、クラスタ内 DNS のスケーラビリティという観点だと Cloud DNS for GKE という構成オプションを利用することにより、従来の kube-dns の代わりに Cloud DNS を使った名前解決が可能になります。DNS としてクラスタ内のコンポーネントではなくマネージドサービスを利用することで、より高いスケーラビリティが期待できます。DNS の負荷がネックになるレベルの大規模なクラスタを使われる場合はぜひ利用を検討していただきたいオプションです。

また、NodeLocal DNSCache というアドオンを有効化することで各 Node 上で DNS キャッシュを提供することができます。ちなみに NodeLocal DNSCache は先ほど紹介した Cloud DNS for GKE と併用することも可能です。
この機能により Pod から送られる名前解決のリクエストを、まずその Pod が動いている Node 上のキャッシュで解決しようとするため、クラスタ内の kube-dns や Cloud DNS に対するクエリ発行が抑えられ DNS 側(特に kube-dns)の負荷の低減やレイテンシーを小さくすることが期待できます。

マルチクラスタ間での負荷分散
1 クラスタあたりのリソース上限の観点やリージョンレベルでの可用性の観点から、結果としてマルチクラスタ構成となるケースもあるかと思います。
GKE には複数クラスタを効率的に管理するための機能・サービスが多く提供されていますが、本記事では特にマルチクラスタにおける負荷分散の観点で機能紹介をしていきます。
GKE では、複数クラスタ間での North-South トラフィック (クライアント等からのトラフィック) の分散を実現する方法として、以下 2 種類の機能を提供しています。
- Multi-cluster Ingress (MCI) (GA)
- Multi-cluster Gateway (MCG) (Preview)
特に Mutli-cluster Gateway (以降 MCG) では複数クラスタ間での重み付けルーティングやヘッダベースのルーティング等の高度なトラフィックコントロールやキャパシティベースのルーティング機能をサポートしています。
例えば MCG のキャパシティベースのルーティングを使うと RPS ベースの負荷分散が実現でき、とあるクラスタのキャパシティ(許容可能な RPS)を超えたリクエストがきた場合にもう片方のクラスタに自動的にトラフィックを流しオフロードするという構成をとることもできます。

特徴③ 幅広い周辺サービス・エコシステム
GKE の特筆すべき特徴の最後として、多くの周辺サービス、エコシステムが提供されているというのが挙げられます。
例えば、Google Cloud では Kubernetes エコシステムのマネージドサービスとして下記を提供しています。
- Prometheus のマネージドサービスである Google Cloud Managed Service for Prometheus (GMP)
- Istio のマネージドサービスである Anthos Service Mesh (ASM)
- OPA Gatekeeper のマネージドサービスである Policy Controller
- Knative のマネージドサービスである Cloud Run for Anthos
Kubernetes 運用の大変なところの 1 つとして、エコシステムの運用があると思うのですが、上記のようなマネージドサービスを活用することによって、Kubernetes エコシステムのアップグレードやセキュリティ対応、可用性の担保、リソース管理などいわゆる Day2 Operation の負荷を軽減することが期待できます。
その他セキュリティの観点でも Binary Authorization という信頼できるコンテナイメージのみデプロイを許可するサービスや Security Command Center の Container Threat Detection という実行中のコンテナに対する振る舞い検知機能を提供するサービスなど、多くのサービスが存在します。
以下、セキュリティ関連サービスの例です:
- Container Analysis... コンテナイメージの脆弱性をスキャンしてくれるサービス。Artifact Registry や Container Registry といった Google Cloud マネージドのコンテナレジストリ上に Push されたイメージを自動的にスキャンしたり、オンデマンドでコンテナレジストリやローカルにあるイメージをスキャンすることができる
- Binary Authorization... 信頼できるコンテナイメージのみが GKE クラスタにデプロイされることを保証してくれるサービス。「信頼できないリポジトリが提供しているベースイメージやコンテナイメージにマルウェアや脆弱性が含まれている」リスクや「CI / CD をバイパスした有害なコンテナイメージがデプロイされる」リスクを低減することができる
- Container Threat Detection... 実行中のコンテナに対する振る舞い検知機能を提供するサービス。元のコンテナ イメージに存在しなかったバイナリ (マルウェアやクリプトマイナー等) の実行やリバースシェル実行 (ボットネット) のような異常な挙動・攻撃を検出することができる
-
GKE Security Posture... GKE 上で動くワークロードの Kubernetes マニフェストやコンテナイメージの脆弱性を継続的にチェックしてくれるサービス。例えばワークロードの構成スキャンを有効化すると、特権コンテナの利用や
runAsNonRootが設定されていないワークロード等 Kubernetes の Pod Security Standards に沿っていないワークロードを検出し知らせてくれる
GKE のセキュリティ機能やセキュリティ関連サービスについては以下の記事でまとめていますので、ご興味あれば見てみてください。
その他、Backup for GKE という GKE 上のワークロードのバックアップ・リストアを行ってくれるマネージドサービスもあります。クラスタ全体やステートフルなワークロードの保護、またクラスタを移行する際などに役立つサービスです。
ということで、GKE の特徴を 3 つのカテゴリに沿って簡単に紹介してみました。(シンプルにまとめるつもりが長々と書いてしまいました)
GKE Standard と Autopilot の違い
最後に、これまでちょくちょく出てきていた GKE Standard と Autopilot の違いについてざっくり説明をします。(NAP やリリースチャンネル等の説明を先にしたかったので後半に持ってきました)
Autopilot の仕様の詳細については公式ドキュメントや同僚の Kazuu さんの記事にわかりやすくまとまっていますのでこちらも読んでみてください。
本セクションではもう少しアバウトな各モードでの違いに言及していきます。
まず GKE Standard は従来通りの GKE クラスタであり、Control Plane は Google 管理ですが Node はユーザー管理となっています。
一方 GKE Autopilot は Control Plane だけでなく Node も Google 管理になっています。Google 管理が具体的に何を指しているかというと
- Node のサイズや台数調整などリソースの管理が不要 (CA および NAP による Node の自動スケールで実現)
- Node のアップグレード作業が不要 (リリースチャンネルによる自動的なバージョン管理)
- Unhealthy な Node を自動的に修復 (Node Auto Repair による自動修復)
- Node は利用者から見えない (
kubectl get nodes等で確認することはできる)
上記の通り、GKE Autopilot は Node が隠蔽されてはいるものの、実態としてはこれまでご紹介してきた GKE の各種自動化機能を使って構成されており、何かしら特殊なことをしているわけではありません。
なので、例えば DaemonSet もデプロイができますし、Istio (のマネージドサービスである ASM) を使ったり GPU の利用(Preview)もサポートされています。
ただ、Node が Google 管理であるということで Node のシステム構成をカスタマイズするなど、細かなチューニングをすることはできません。sysctl や kubelet のパラメーターチューニングが必要なワークロードの場合は GKE Standard をご利用いただくのが良いかと思います。
次にセキュリティの観点ですが、 GKE Autopilot は各種セキュリティのベストプラクティスが組み込みで実装されており、Production Ready なクラスタをすぐに利用することができます。
- Workload Identity 有効化 (無効化不可)
- Shielded GKE Node / セキュアブート有効化 (無効化不可)
- Container-Optimized OS (COS) containerd イメージのみ利用可能
- Node への SSH 不可
- 特権コンテナのデプロイ不可
- 利用可能な Linux capabilities が制限されている、等
これらはセキュリティ面での利点でもありつつ、制約とも言える内容になっているかと思います。ワークロードがこれら制約を許容できるか、というのは Autopilot を選択する上での重要なポイントです。
その他セキュリティ面での特徴については公式ドキュメントもご参照ください。
また Autopilot は Node リソースを CA / NAP により自動的に管理しているため Node 上に余剰リソースがあまりなく、新しい Pod をデプロイすると新しく Node のプロビジョニングが走ることが多いです。Node 上で余剰を確保しづらいため、突発的に Pod がスケールするようなワークロードにはあまり向いていないとも言えます。
そのようなワークロードの場合は GKE Standard を利用し、あらかじめスケールに耐えうる分の Node をプロビジョニングしておくなどの方法を取るのも良いではないかと思います。(もしくはワークアラウンドとして GKE Autopilot でも予め Priority の低い Pod をデプロイしておき余剰リソースを確保するという方法を取ることもできます)
最後に、課金についてですが GKE Standard は Node リソースに対して課金が発生しますが、Autopilot は Node リソースに対する課金はされず Pod 単位の課金となります。Pod 単位といってもシステム系 Pod のリソースは課金の対象外で、利用者でデプロイしたアプリケーションの Pod に対して課金されます。
料金体系も含め、Autopilot はアプリケーション開発に集中できる Kubernetes クラスタであることがお分かりいただけるのではないかと思います。
ということでまとめると、各種自動化機能が有効化されていてより簡単に運用できる Kubernetes クラスタが欲しい場合やセキュアな構成のクラスタを簡単に利用したい場合は Autopilot を選択いただくのが良いかと思います。
一方、要件的に Node レベルのチューニングが必要なワークロードや、Autopilot 特有の制限が許容できないワークロードをデプロイしたい場合などは GKE Standard を選んでいただく必要があります。
急激に Pod の増減が発生するようなバースト性のあるワークロードも(ワークアラウンドはあるものの) Autopilot には向いていないことが多いので、負荷試験などをした上で GKE Standard or Autopilot を選択いただくのが良いと思います。
個人的にはまずは Autopilot 前提で検討してみて、要件的に合わなければ GKE Standard という選択の仕方もアリだと思います。(ちなみに現在、Cloud Console 上から GKE クラスタを作成する際のデフォルトは Autopilot になっています)
まとめ
GKE の良さは色々とあるものの、今回は 3 つのポイントに絞ってご紹介させていただきました。
- 特徴① 運用負荷を軽減するための各種自動化機能... 自動アップグレード機能や、自動スケール機能など Kubernetes クラスタの運用をより簡単にするための機能が備わっている
- 特徴② 高い拡張性... クラスタ内 DNS の代わりにマネージドサービスを活用するオプションの提供や、リソース追加に伴う IP アドレス枯渇に対処可能なオプションの提供等、拡張性の高さ
- 特徴③ 幅広い周辺サービス・エコシステム... Prometheus や Istio 等 Kubernetes エコシステムのマネージドサービスを提供、またコンテナセキュリティ関連のサービスを多数提供
また、これから GKE / Kubernetes を始める方には GKE Autopilot から試していただくのがお勧めです。Google のベストプラクティスが組み込まれたクラスタを簡単に使い始めることができます。(要件があわなければ GKE Standard も検討してみましょう)
この記事が何かの参考になれば幸いです。気になった方は GKE をぜひ触ってみてください!
-
リリースチャンネルに登録されているクラスタが対象。また、マイナーバージョンの EOL を超過することはできません。 ↩︎

Discussion