BigQuery で音声文字変換モデルのプレビュー版をご利用いただけるようになりました🥳
BigQuery 上で 音声ファイルを簡単に文字変換して他の構造化データと組み合わせ、分析を行うことが可能です。(公式ブログもご確認ください!)
これまで、音声データをスケーラブルかつ管理された方法で AI モデルに接続して、音声データから大規模なインサイトを得ることは困難でした。なぜなら、音声データの分析を行うためには、音声データの書き起こしのために個別の AI パイプラインを構築する必要があったからです。これらのパイプラインは BigQuery からサイロ化されており、文字変換されたデータを BigQuery に取り込むためにはカスタム インフラストラクチャを作成する必要がありました。
しかし、BigQuery 上で音声文字変換モデルをご利用いただくことで、SQL のシンプルさとパワーを活用して組み込みのセキュリティとガバナンスを提供しながら、音声ファイルを簡単に文字変換して他の構造化データと組み合わせ、分析を行っていただけます!
この記事ではコールセンターの会話を録音した音声データを BigQuery 上で、1.書き起こし、2.要約、3.分類するための手順をご紹介します。
それでは早速、具体的な手順を見ていきましょう💨
まず、Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
API 有効化
以下の API を有効化します。
- BigQuery API
- BigQuery Connection API
- Vertex AI API
- Cloud Speech-to-Text API
Cloud Shell を使って有効化する際は Cloud Shell で以下のコードを実行してください。
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable speech.googleapis.com
BigQuery の新しいデータセットを作成する
テーブルを保存するためのデータセットを作成します。
-
[エクスプローラ ペイン] で、プロジェクト ID の近くにある [アクションを表示] をクリックし、次に [データセットを作成] をクリックします。

-
[データセット ID] は 「callcenter」とします。
その他のオプションはデフォルト値のままにします。

-
[データセットを作成] をクリックします。
これでデータセットが作成されました。
外部接続を作成する
BigQuery の外部に保存されているデータをクエリするために外部接続を作成します。今回は Cloud Storage の非構造化データをクエリするための Cloud リソース接続を作成します。接続の概要はこちらのドキュメントをご確認ください。
- BigQuery エクスプローラ ペインの [+ 追加] ボタンをクリックし、リストされている一般的なソースの [外部データ ソースへの接続] をクリックします。
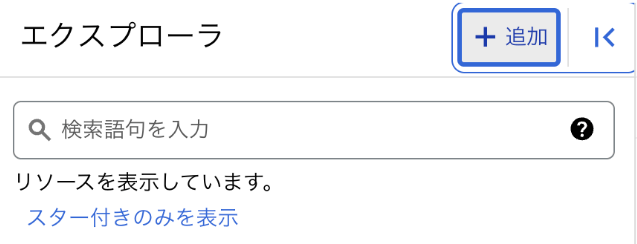
-
接続タイプとして [Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)] を選択します。
接続 ID を cc_connector とします。
他の値はデフォルトのままで [接続の作成] をクリックします。 - プロジェクトのデータセットの [外部接続] セクションから us.cc_connector を選択します。外部接続構成の詳細から生成されたサービス アカウント ID をクリップボードにコピーします。次の手順で使用します。
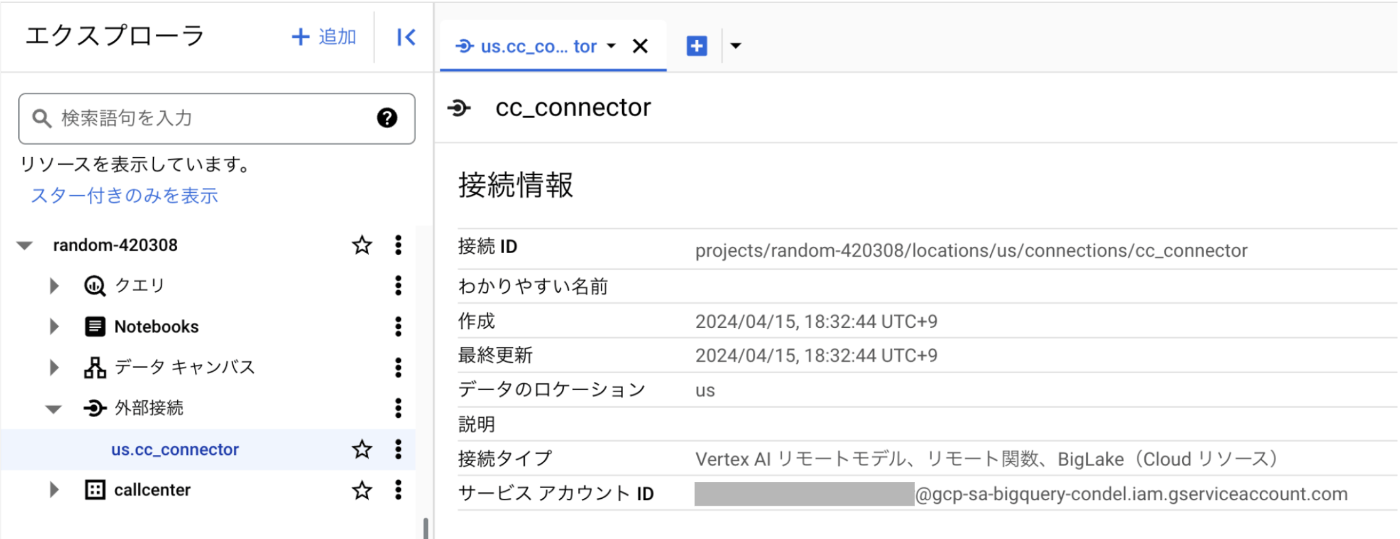
サービスアカウントに権限を付与する
外部接続によって生成されたサービス アカウントに各種サービスへのアクセスを許可する必要があります。そのためには、次の手順を実行します。
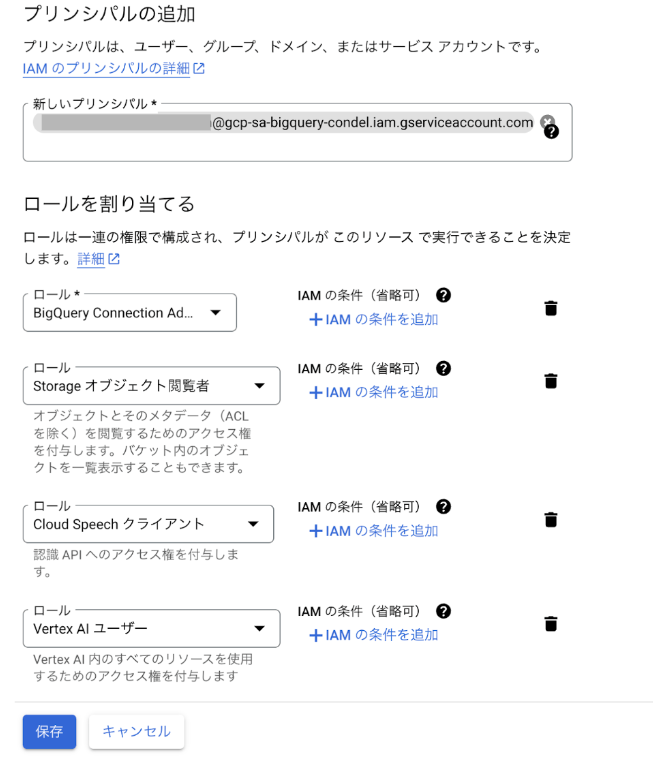
- ナビゲーション メニューから [IAM & 管理] を選択します。
- IAM ページで + アクセス権を付与 をクリックします。
- 外部接続によって生成されたサービス アカウント ID を [新しいプリンシパル] フォーム入力に貼り付けます。
- ロール
- BigQuery Connection Admin
- Storage オブジェクト閲覧者
- Cloud Speech クライアント
- Vertex AI ユーザー
を追加して、保存をクリックします。
データの準備:オブジェクトテーブルの作成
オブジェクト テーブルは、Cloud Storage 内にある非構造化データ オブジェクトの読み取り専用テーブルです。
Cloud Storage 内の非構造化データをオブジェクト テーブルとして BigQuery に取り込むことで、リモート関数で分析を行ったり、BigQuery ML を使用して推論を実行したりできるようになります。これらのオペレーションの結果は BigQuery の残りの構造化データと結合して分析を行うことができます。オブジェクトテーブルについて詳しくは公式ドキュメントをご確認ください。
- Cloud Storage に移動し、+作成 をクリックしてバケットを作成します。任意のバケット名を入力し、他の設定はデフォルトのまま 作成 をクリックしてください。
公開アクセスの防止、というポップアップは「このバケットに対する公開アクセス禁止を適用する」にチェックを入れて確認をクリックしてください。

- 作成したバケットに音声ファイルをアップロードしてください。
Cloud Storage バケットにオブジェクトをアップロードする方法についてはこちらのドキュメントをご確認ください。
音声ファイルのアップロードが完了したら、再び BigQuery に戻ります。以下のクエリを実行して、音声データを置いた GCS 上のパスを指定してオブジェクトテーブルを作成します。
テーブル名を conversation_object_table とします。
CREATE EXTERNAL TABLE `PROJECT_ID.callcenter.conversation_object_table`
WITH CONNECTION `PROJECT_ID.us.cc_connector`
OPTIONS(
object_metadata = 'SIMPLE',
uris = ['BUCKET_PATH/*']
);
作成したオブジェクトテーブル conversation_object_table 上の情報を確認します。
SELECT *
FROM `PROJECT_ID.callcenter.conversation_object_table`
ORDER BY uri DESC;
クエリ結果は次のようになります。

音声認識用のモデルの作成
Speech-to-Text で 認識ツールを作成 します。
左上のナビゲーション メニューから Speech を選択し、認識ツールを開きます。
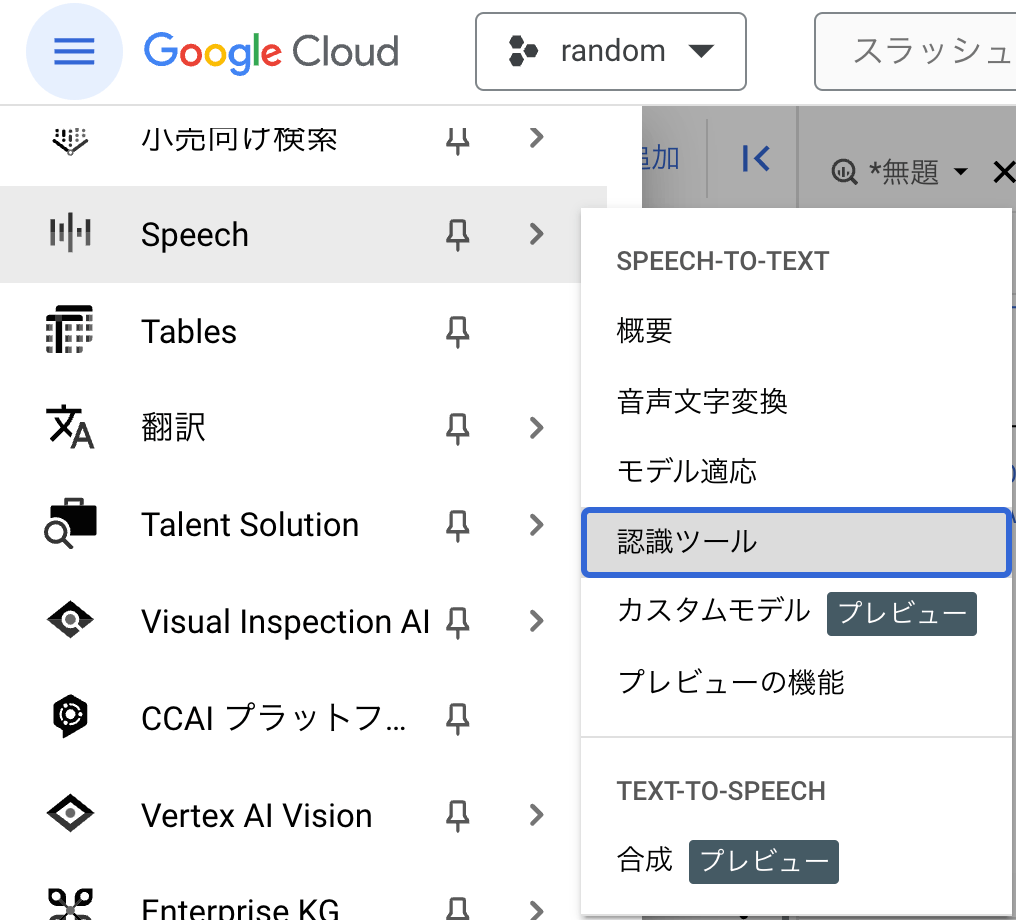
+作成 をクリックします。
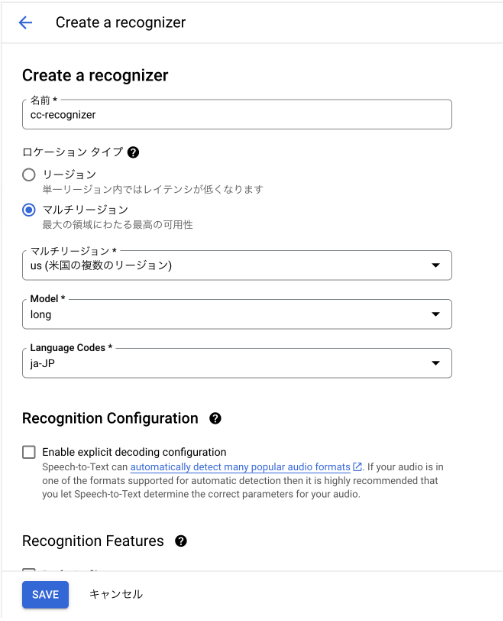
名前を cc-recognizer、マルチリージョンのドロップダウンから us を選択します。
お持ちの音声データのユースケースに合わせて Model をこちらのドキュメントを参照してお選びください。本記事ではデフォルトの long のままで作成します。
Language Codes を ja-JP とし、その他はデフォルトのままで Save します。
下のクエリを実行して音声認識リモートモデルを作成します。モデル名を transcribe_model とします。
CREATE OR REPLACE MODEL
`PROJECT_ID.callcenter.transcribe_model`
REMOTE WITH CONNECTION `PROJECT_ID.us.cc_connector`
OPTIONS (
REMOTE_SERVICE_TYPE = 'CLOUD_AI_SPEECH_TO_TEXT_V2',
SPEECH_RECOGNIZER = 'projects/PROJECT_ID/locations/us/recognizers/cc-recognizer'
);
データセット内に transcribe_model というリモートモデルが作成されました。

音声ファイルの文字変換
オブジェクトテーブル内のリンクから音声データにアクセスして書き起こします。
実行完了には数分かかります。
SELECT
*
FROM
ML.TRANSCRIBE(
MODEL `PROJECT_ID.callcenter.transcribe_model`,
TABLE `PROJECT_ID.callcenter.conversation_object_table`,
RECOGNITION_CONFIG => (
JSON '{"model": "long"}'
)
);
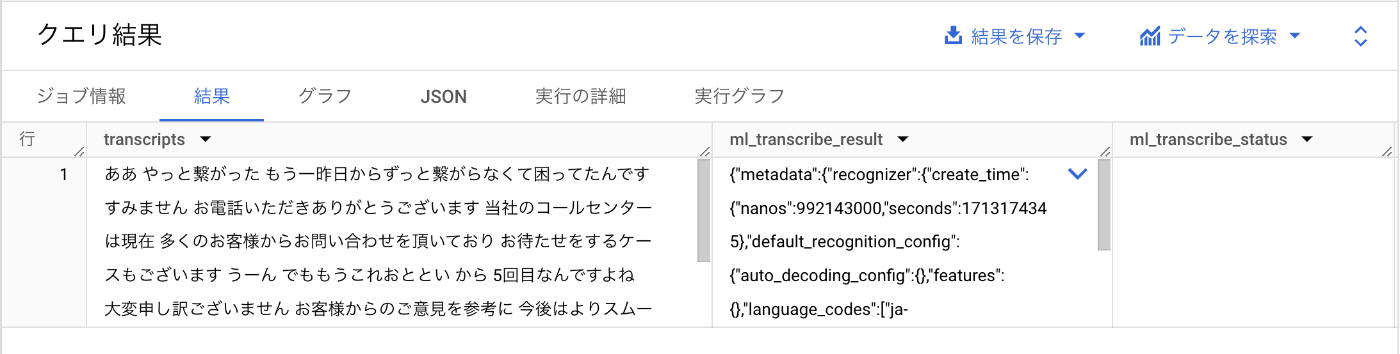
クエリ実行結果はこちらです。
transcripts の列に書き起こされたテキストが入っています。電話をかけてきたお客様は電話が繋がらなかったことに怒っていることが分かります👀
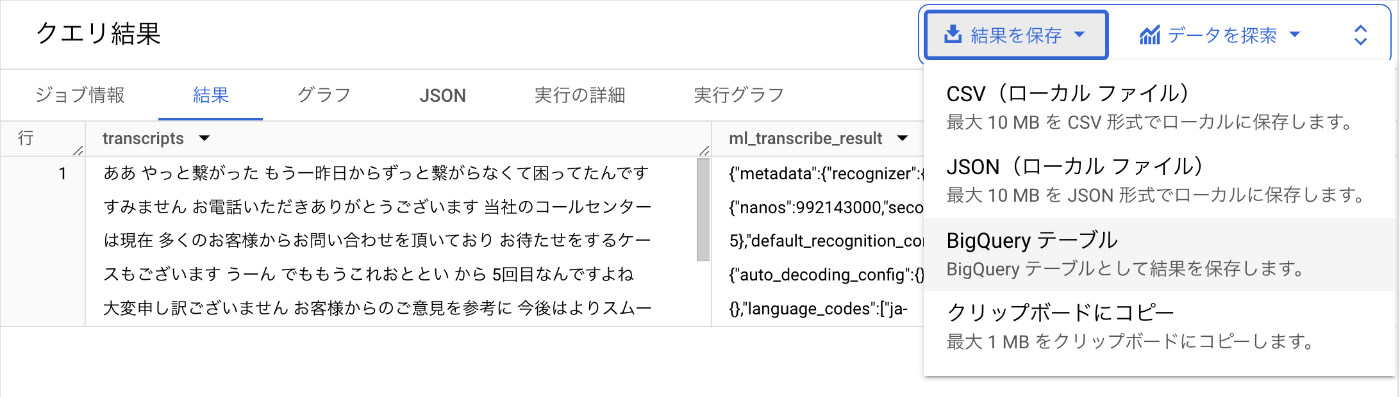
この結果を “transcribed” という名前のテーブルとして保存します。
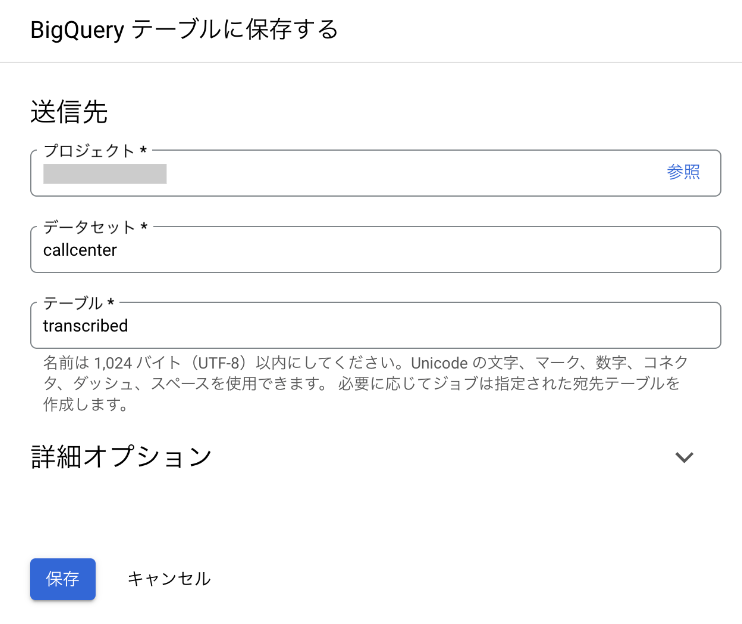
LLM リモートモデルの作成
以下のクエリを実行して LLM リモートモデルを作成します。モデル名を llm_model_gemini としています。
CREATE OR REPLACE MODEL
`PROJECT_ID.callcenter.llm_model_gemini`
REMOTE WITH CONNECTION
`PROJECT_ID.us.cc_connector`
OPTIONS (
ENDPOINT = 'gemini-pro'
);
この時点でのエクスプローラはこのようになっています。
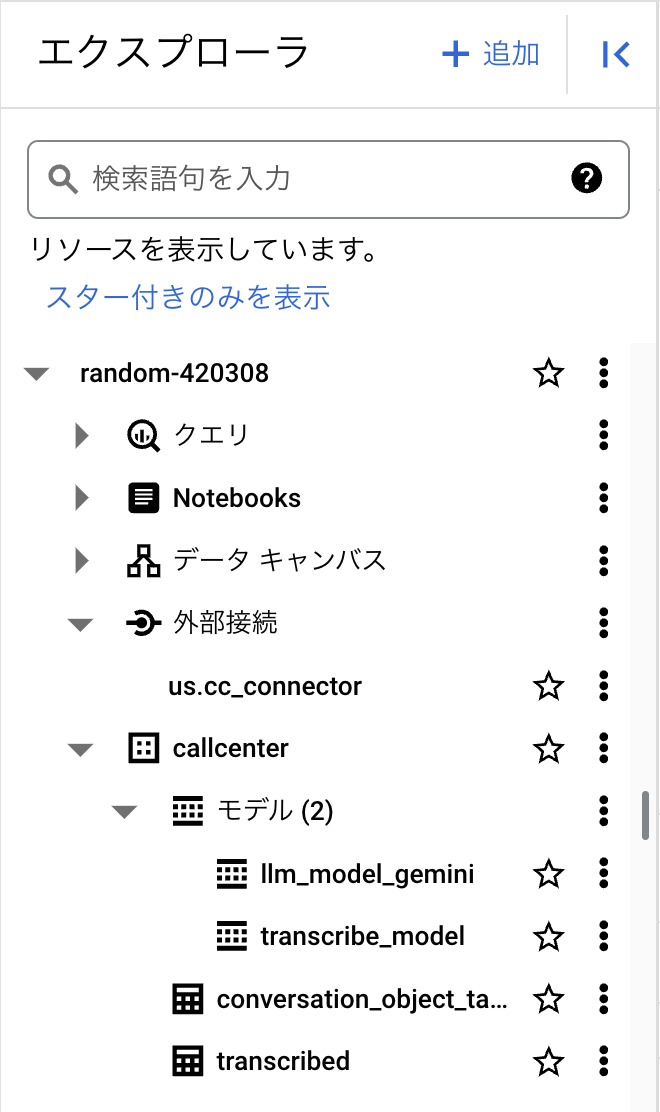
テキストの要約・分類
以下のクエリを実行して LLM リモートモデルを用いて、文字起こしされた会話の (i) 要約、(ii) 内容の分類、を実行します。
WITH generated_summary AS (
SELECT transcripts, ml_generate_text_llm_result AS summary, uri
FROM ml.generate_text(
MODEL `PROJECT_ID.callcenter.llm_model_gemini`,
(
SELECT CONCAT(
'"コールセンターでの会話内容を書き起こしたtextについて、顧客がどう感じているかを自然な文章で30文字程度でまとめてください。',
'text: "', transcripts, '"'
) AS prompt, transcripts, uri
FROM PROJECT_ID.callcenter.transcribed
),
STRUCT(TRUE AS flatten_json_output)
)
),
generated_reason_label AS (
SELECT uri, ml_generate_text_llm_result AS reason
FROM ml.generate_text(
MODEL `PROJECT_ID.callcenter.llm_model_gemini`,
(
SELECT CONCAT(
'"コールセンターでの会話内容のtextから顧客の不満が次のintentのうちどれに当たるか答えなさい。次のintentの値のみで回答してください。',
'intent: ["製品","オペレーター","購入プロセス","待ち時間","アフターサービス"]',
'intent : "', transcripts, '"'
) AS prompt, uri
FROM PROJECT_ID.callcenter.transcribed
),
STRUCT(TRUE AS flatten_json_output)
)
)
SELECT s.transcripts, s.summary, r.reason
FROM generated_summary s
INNER JOIN generated_reason_label r ON s.uri = r.uri;
クエリ実行結果はこちらのようになります。
Summary の列には要約が、reason の列にはそのカテゴリーが生成されています。
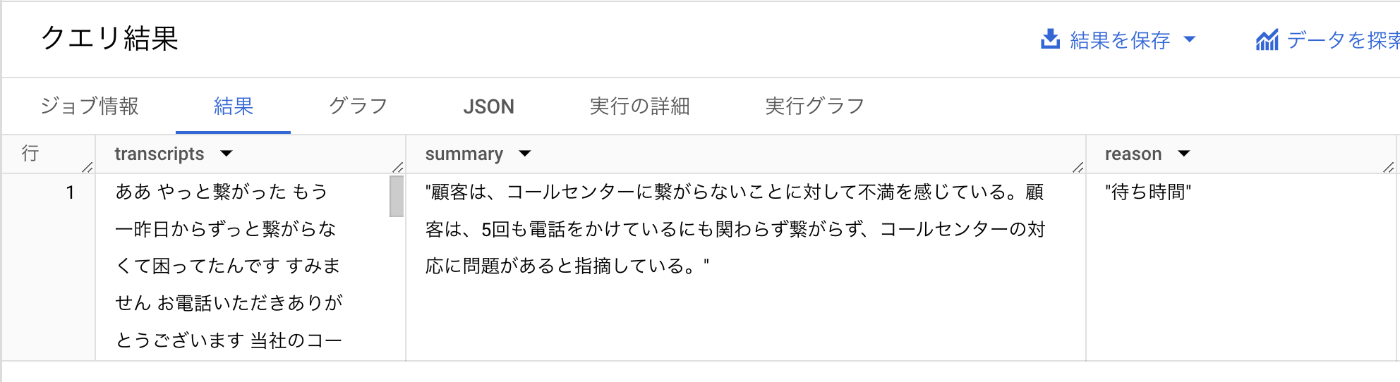
コールセンターに電話をかけてきた顧客が、何に不満を持っているのか分類することができました🎉
音声を書き起こした後のデータ活用例
音声入力を文字変換した後で、そのテキストデータを分析する方法を 3 つご紹介します💥
- BigQuery から PaLM API を直接呼び出し、文字変換されたデータの要約、分類、Q&A プロンプトを行う: PaLM は、さまざまな自然言語タスクに使用できる強力な AI 言語モデルです。たとえば、PaLM を使用してサポートコールの要約を生成したり、顧客からのフィードバックをさまざまなカテゴリに分類したりできます。
- BigQueryML を使用して、よく使用される自然言語のユースケースを実行する: BigQueryML は、テキストモデルのトレーニングやデプロイを実行するための幅広いサポートを提供します。たとえば、BigQuery ML を使用して、サポートへの問い合わせ時の顧客の感情を識別したり、製品へのフィードバックをさまざまなカテゴリに分類したりできます。Python をご利用の場合は、BigQuery Studio を使用して、テキスト分析を行う Pandas 関数を実行することもできます。
- 音声文字変換のメタデータを BigQuery テーブルに保存されている他の構造化データと結合する: これにより、構造化データと非構造化データを組み合わせて、より強力なユースケースを実現できます。たとえば、否定的な感情のサポートコールを活用して顧客のライフタイム バリュー(CLTV)の高い顧客を特定したり、顧客のフィードバックから特に要望の多い製品機能の一覧を作成したりできます。
まとめ
BigQuery 上で SQL だけで音声認識モデルと大規模言語モデルを使用して音声データを分析することができました!
これを顧客の属性などの構造化データと組み合わせることで、音声をひとつひとつ確認せずとも全体的な傾向を分析してビジネス上の意思決定に繋げることができます。
ぜひ皆様もお手元の音声データを使用して、 BigQuery で分析と活用を行ってみてください!
本記事に関連する公式ドキュメントとブログ記事
- Vertex AI transcription models are available in BigQuery _ Google Cloud 公式ブログ
- BigQuery の概要 | Google Cloud
- Cloud リソース接続を作成して設定する | BigQuery
- オブジェクト テーブルを作成する | BigQuery | Google Cloud
- ML.TRANSCRIBE 関数を使用して音声ファイルを音声文字変換する | BigQuery | Google Cloud
- ML.GENERATE_TEXT 関数を使用してテキストを生成する | BigQuery | Google Cloud

Discussion