この記事は Google Cloud Japan Advent Calendar 2024 (Gemini編) の4日目の記事です。
Google Cloud Next Tokyo '24 で実施した Gemini in BigQuery のハンズオンセッションの内容を公開します。記事に沿って進めていけば Gemini in BigQuery を簡単にお試しいただくことができます!
概要
このハンズオンは、架空の小売チェーン Next Drug での顧客分析を題材にしています。
Next Drug における来店客のアンケートや売上などのデータを BigQuery と Gemini を使って分析します。
ハンズオンのポイント
- Gemini in BigQuery を使用し、日本語の指示を与えて SQL クエリを生成できます。
- BigQueryML を使用し、BigQueryから SQL で直接 Gemini モデルを呼び出すことができます。
ハンズオン手順
まずはハンズオン用のファイル、環境の準備から実施します。
ハンズオンの準備
- Cloud Shell を開きます。
- 次のコマンドを実行してハンズオン資材をダウンロードし、チュートリアルを開きます。
cd ~/
git clone https://github.com/google-cloud-japan/next-tokyo-assets.git
cd ~/next-tokyo-assets/2024/bq/
teachme tutorial.md
Cloud Shell で teachme コマンドを実行することで、画面右側にチュートリアルが開きます。

以降はチュートリアルに沿って 1 ステップずつ実行すれば 2 時間ほどでハンズオンを実施できますが、この記事では時間がない方向けにサクッとポイントだけ体験するためのハンズオン手順をご紹介します。
- ターミナルの環境変数にプロジェクトIDを設定します。
export PROJECT_ID=$(gcloud config list --format 'value(core.project)')
- このハンズオンで利用する API を有効化します。
gcloud services enable cloudaicompanion.googleapis.com aiplatform.googleapis.com bigqueryconnection.googleapis.com --project=${PROJECT_ID}
- bq コマンドを用いて CSV ファイルを BigQuery にインポートします。
bq mk --location=us-central1 --dataset ${PROJECT_ID}:next_drug
bq load --location=us-central1 --autodetect --replace --source_format=CSV ${PROJECT_ID}:next_drug.store ./store.csv
bq load --location=us-central1 --autodetect --replace --source_format=CSV ${PROJECT_ID}:next_drug.order ./order.csv
bq load --location=us-central1 --autodetect --replace --source_format=CSV ${PROJECT_ID}:next_drug.order_items ./order_items.csv
bq load --location=us-central1 --autodetect --replace --source_format=CSV ${PROJECT_ID}:next_drug.customer_voice ./customer_voice.csv
- ナビゲーションメニューから [BigQuery] に移動します。エクスプローラペインの 自身の プロジェクト ID の下に、データセット
next_drugが作成され、next_drugデータセットの下に 4 つのテーブルが作成されていることを確認します。
-
storeテーブル : 各店舗の名前、所在地などのデータ -
orderテーブル : 各店舗での販売データ (親) -
order_itemsテーブル : 各店舗での販売データ (子) -
customer_voiceテーブル : 各店舗に来店した顧客のアンケートデータ
ポイント1. Gemini in BigQuery を用いて SQL を生成する
-
[SQL クエリを作成] アイコンをクリックして新しいタブを開きます。
-
[SQL 生成ツール]アイコンをクリックするか、Ctrl + Shift + P を入力して、SQL 生成ツールを開きます。

- 次のプロンプトを入力します。
next_drug データセットから、販売金額トップ 10 の商品とそのカテゴリを調べるクエリを書いて
- [生成] をクリックします。Gemini は、次のような SQL クエリを生成します。
-- next_drug データセットから、販売金額トップ 10 の商品とそのカテゴリを調べるクエリを書いて
SELECT
oi.item,
oi.category,
SUM(oi.total_price) AS total_sales
FROM
`next_drug.order_items` AS oi
GROUP BY 1, 2
ORDER BY
total_sales DESC
LIMIT 10;
- 以下のようなプロンプトも試してみましょう。
最も販売数が多い商品カテゴリは?
各店舗の時間帯ごとの来店数を計算し、店舗ごとに最も来店数が多い 1 時間帯を表示して
ポイント2. BigQueryML を用いて SQL で Gemini モデルを呼び出す
- Cloud Shell で以下のコマンドを実行し、BigQuery から Vertex AI への接続を作成します。
bq mk --connection --location=us-central1 --project_id=${PROJECT_ID} --connection_type=CLOUD_RESOURCE gemini-connect
export SA_ID=$(bq show --format=json --connection ${PROJECT_ID}.us-central1.gemini-connect | jq '.cloudResource.serviceAccountId' | sed 's/"//g')
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member=serviceAccount:${SA_ID} --role='roles/aiplatform.user'
- [SQL クエリを作成] アイコンをクリックして新しいタブを開き、以下の SQL を実行します。ここでは、生成 AI モデルの Gemini 1.5 Flash を指定しています。
CREATE OR REPLACE MODEL next_drug.gemini_model
REMOTE WITH CONNECTION `us-central1.gemini-connect`
OPTIONS(ENDPOINT = 'gemini-1.5-flash')
- 同じタブで以下の SQL を実行し、Gemini からのレスポンスを確認します。
SELECT JSON_VALUE(ml_generate_text_result.candidates[0].content.parts[0].text) as response
FROM ML.GENERATE_TEXT(
MODEL next_drug.gemini_model,
(SELECT 'Google Cloud Next について教えてください' AS prompt),
STRUCT(1000 as max_output_tokens, 0.2 as temperature)
)
- それでは、
customer_voiceテーブルのデータを Gemini に渡して、顧客の声の感情分析を行います。
SELECT
customer_voice,
JSON_VALUE(ml_generate_text_result.candidates[0].content.parts[0].text) AS sentiment
FROM
ML.GENERATE_TEXT( MODEL next_drug.gemini_model,
(
SELECT
CONCAT(
'次の[顧客の声]の感情分析を行い、[出力形式]に従って出力してください。¥n¥n',
'[出力形式]¥nNegative, Neutral, Positive のいずれか1つをプレーンテキストで出力。',
'余計な情報は付加しないこと。¥n¥n',
'[顧客の声]¥n',
customer_voice ) AS prompt, -- 感情分析のプロンプト
customer_voice,
FROM
`next_drug.customer_voice`),
STRUCT(1000 AS max_output_tokens,
0.0 AS temperature) )
;
次のような結果が表示されます。
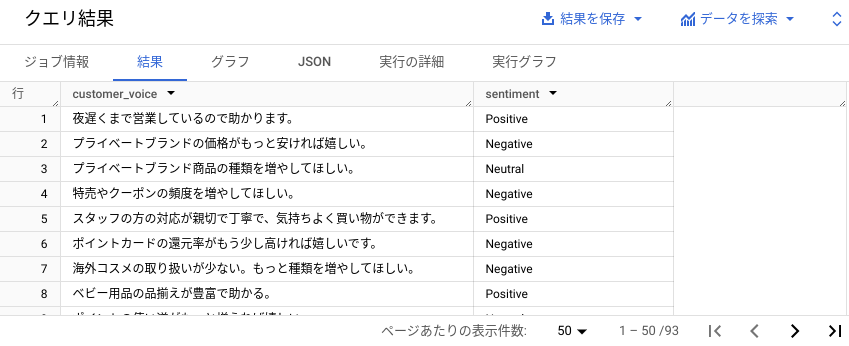
- 続いて、顧客の声のトピック分析も行います。
SELECT
customer_voice,
JSON_VALUE(ml_generate_text_result.candidates[0].content.parts[0].text) AS topic
FROM
ML.GENERATE_TEXT( MODEL next_drug.gemini_model,
(
SELECT
CONCAT(
'次の[顧客の声]を分類して、[出力形式]に従って出力してください。¥n¥n',
'[出力形式]¥n 商品・品揃え、価格、スタッフ、店舗環境、その他、のいずれか1つだけをプレーンテキストで出力。',
'余計な情報は付加しないこと。¥n¥n',
'[顧客の声]¥n',
customer_voice ) AS prompt, -- トピック分析のプロンプト
customer_voice,
FROM
`next_drug.customer_voice`),
STRUCT(1000 AS max_output_tokens,
0.0 AS temperature) )
次のような結果が表示されます。
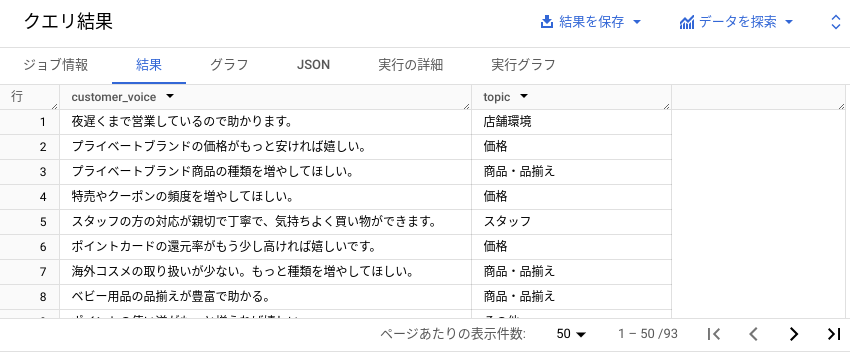
まとめ
この記事では Gemini in BigQuery による SQL クエリ生成と、BigQueryML による Gemini モデルの呼び出しを簡単に試していただくステップをご紹介しました。
BigQuery と Gemini を組み合わせることで SQL クエリを書くハードルがぐっと下がり、かつテキストや画像のような非構造化データも分析できるようになることをご理解いただけたかと思います。
「データ分析は社内の一部の人だけに属人化している」「手作業で分析しているので負担が大きい」そんな課題を抱えている方に活用いただければ幸いです。
それでは明日以降の Advent Calendar もお楽しみに!

Discussion