TL;DR
DWS Flex-Start の新料金プラン (新 SKUs) により、Vertex AI で利用可能な Google Cloud のハイエンド GPU を搭載したアクセラレータ最適化 VM が、オンデマンドの最大約半額で利用可能になりました。
AI 開発者にとっては、これまで高価で手が出しにくかった、パワフルなハイエンド GPU を利用した学習や推論をより気軽に試せるようになりました。
本記事では、Vertex AI Model Garden 経由で利用可能な Gemma 3 を利用して、実際に Vertex AI の Custom Training と Online Prediction をそれぞれ実行し、オンデマンドと DWS Flex-Start の料金を比較します。
Dynamic Workload Scheduler (DWS) とは?
Dynamic Workload Scheduler (a.k.a. DWS) は、Google Cloud 上で需要の高い GPU や TPU を確保しやすくするためのリソース管理・ジョブスケジューリングの仕組みです。
これに加えて、この度リリースされた新料金体系により、ハイエンドな GPU リソース (A100, H100, H200 など) をコストを抑えながら利用できるようになりました。
DWS の詳細については、以前の記事「Dynamic Workload Scheduler on Vertex AI Training で NVIDIA H100 を確保する」もあわせてご参照ください。
Vertex AI Custom Training 料金比較
まずはじめに Vertex AI Training を動かして料金を見ていきましょう。
今回は us-central1 リージョンで、NVIDIA H100 GPU を 8 個搭載したマシンタイプ a3-highgpu-8g を利用して Custom Training ジョブを実行します。
| マシンタイプ | GPU 数 | GPU メモリ (GB) | vCPU 数 | VM メモリ (GB) | ローカル SSD (GiB) |
|---|---|---|---|---|---|
| a3-highgpu-8g | 8 | 640 | 208 | 1,872 | 6,000 |
事前に十分な Quota が割り当てられているか確認し、必要であれば Quota の引き上げ申請を行います。こちらのドキュメントに記載の通り、DWS ではオンデマンド Quota ではなく、プリエンプティブル Quota を使用します。
対象の割り当て (Quota)
- オンデマンド:
aiplatform.googleapis.com/custom_model_training_nvidia_h100_gpus - DWS Flex-Start:
aiplatform.googleapis.com/custom_model_training_preemptible_nvidia_h100_gpus
なお、こちらのブログに記載の通り、a3-highgpu-8g より小さなマシンタイプはオンデマンドではサポートされていないため、今回は上記 Quota の割り当て量がそれぞれ 8 必要となります。
Gemma 3 (1B) のファインチューニングジョブを実行
Model Garden 上の Gemma 3 モデルカードからノートブックを開くを選択し、model_garden_axolotl_gemma3_finetuning.ipynb という名前のサンプルノートブックを Colab Enterprise 上で開きます。

ノートブックの詳細は GitHub 上でもご確認いただけます。
今回は GPU を利用してジョブを実行すること自体が目的のため、チューニング内容の解説は割愛させていただき、以下のセルのみを順次実行していきます。
-
Import utility packages for fine-tuning
- デフォルト値のままで実行
※ エラー発生するが続行して問題なし
- デフォルト値のままで実行
-
Setup Google Cloud project
- 自身の GCS バケットを設定
- リージョンは
us-central1を指定
-
Set model to fine-tune
-
google/gemma-3-1bit-itを指定
-
-
Set Axolotl config
- デフォルト値のままで実行
-
Setup HF token
- 自身の Hugging Face Token を入力
-
Setup Axolotl Flags
- デフォルト値のままで実行
-
Vertex AI fine-tuning job
-
NVIDIA_H100_80GBを選択して実行
-
今回のノートブックは、デフォルトで DWS Flex-Start を利用する設定になっていますので、DWS を利用して実行する場合はデフォルトのままで特に変更は必要なく、オンデマンドで実行する際には、上記 7 のセル内のコードを is_dynamic_workload_scheduler = False に変更し、train_job.run 実行時に指定している DWS に関するパラメータ dws_kwargs をコメントアウトします。
is_dynamic_workload_scheduler = False
train_job.run(
args=train_job_args,
replica_count=replica_count,
machine_type=training_machine_type,
accelerator_type=training_accelerator_type,
accelerator_count=per_node_accelerator_count,
boot_disk_size_gb=boot_disk_size_gb,
service_account=SERVICE_ACCOUNT,
base_output_dir=TRAINING_JOB_OUTPUT_DIR,
sync=False, # Non-blocking call to run.
# **dws_kwargs,
)
オンデマンド
ノートブック上のセルを実行したら、Cloud Console の Vertex AI > トレーニング > カスタムジョブの画面に遷移してジョブが作成されていることを確認します。
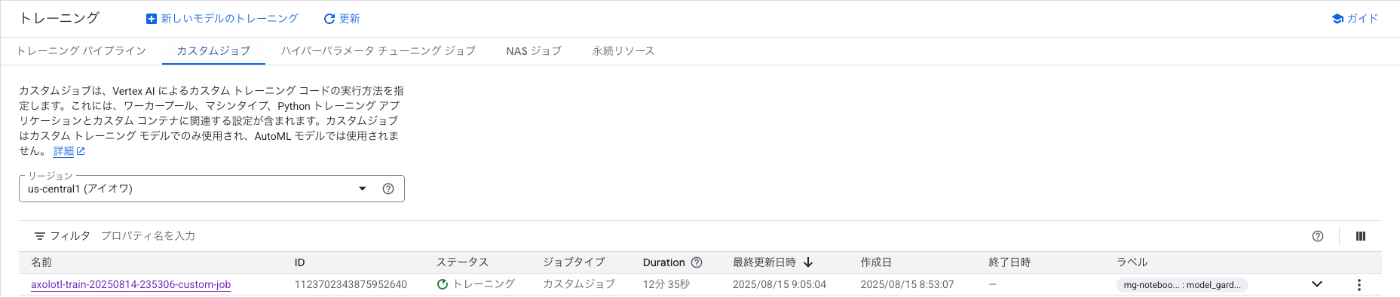
しばらく待つと無事にジョブが完了していました。

ジョブの詳細は次のようになっており、GPU もきちんと使えていそうでした。

続いて、Cloud Billing のレポート上で料金を確認してみましょう。
※ 最新の請求情報が反映されるまでに通常 1 日程度かかります。[1]

上記のレポートには今回実際に掛かった費用が含まれていますが、これらの費用はジョブの実行時間によって変動するため、今回は実際に発生した費用を直接見比べるのではなく、対象となる課金項目 (SKU) を特定し、それらを元に 1 時間あたりの費用を再計算したもので料金比較をしていきたいと思います。
具体的には、オンデマンドの料金を SKU 単位で 1 時間あたりに換算して再計算します。[2]
| SKU | サービス | SKU ID | 単価 | 単位 | 数量 | 小計 |
|---|---|---|---|---|---|---|
| Vertex AI: Training/Pipelines on NVIDIA H100 80GB in Iowa | Vertex AI | 3F95-001E-B747 | $11.2660332 | per 1 hour | 8 | $90.1282656 |
| Vertex AI: Training/Pipelines on A3 Instance Core in Iowa | Vertex AI | 2E83-99F1-391A | $0.0293227 | per 1 hour | 208 | $6.0991216 |
| Vertex AI: Training/Pipelines on A3 Instance RAM in Iowa | Vertex AI | B045-9255-8314 | $0.0025534 | per 1 gigabyte hour | 1,872 | $4.7799648 |
| Vertex AI: Training/Pipelines on SSD backed PD Capacity | Vertex AI | A005-98FE-36CC | $0.0002678 [3] | per 1 gigabyte hour | 2,000 [4] | $0.53561644 |
合計: $101.5429684 per hour
DWS Flex-Start
DWS Flex-Start についても、ノートブックを実行し、カスタムジョブの画面からジョブが作成されていることを確認します。
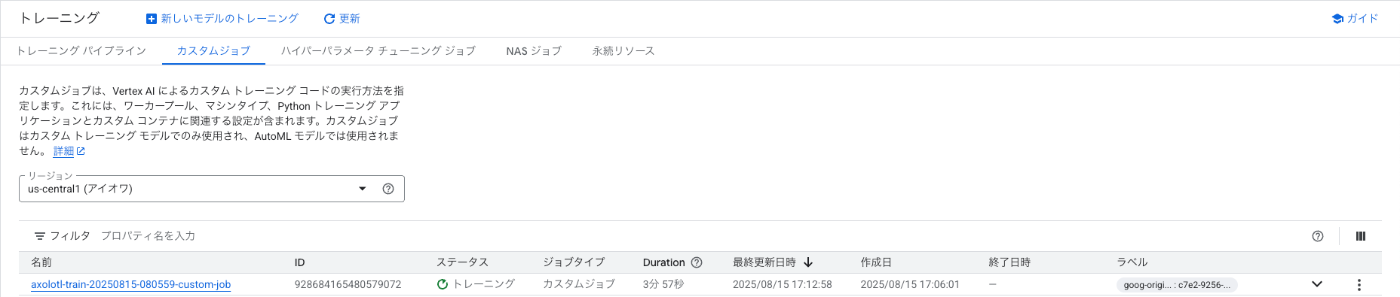
こちらもしばらく待つとジョブが完了していました。
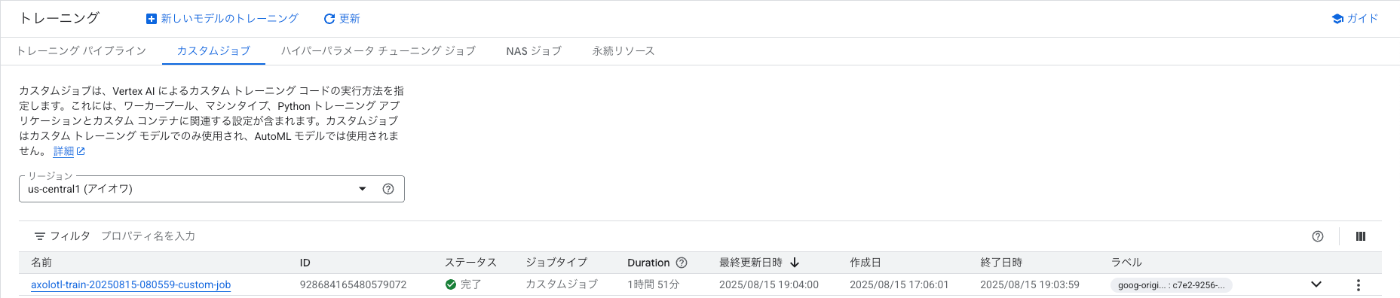
ジョブの詳細を確認すると、今回は VM プロビジョニング モデルが Flex Start になっておりました。
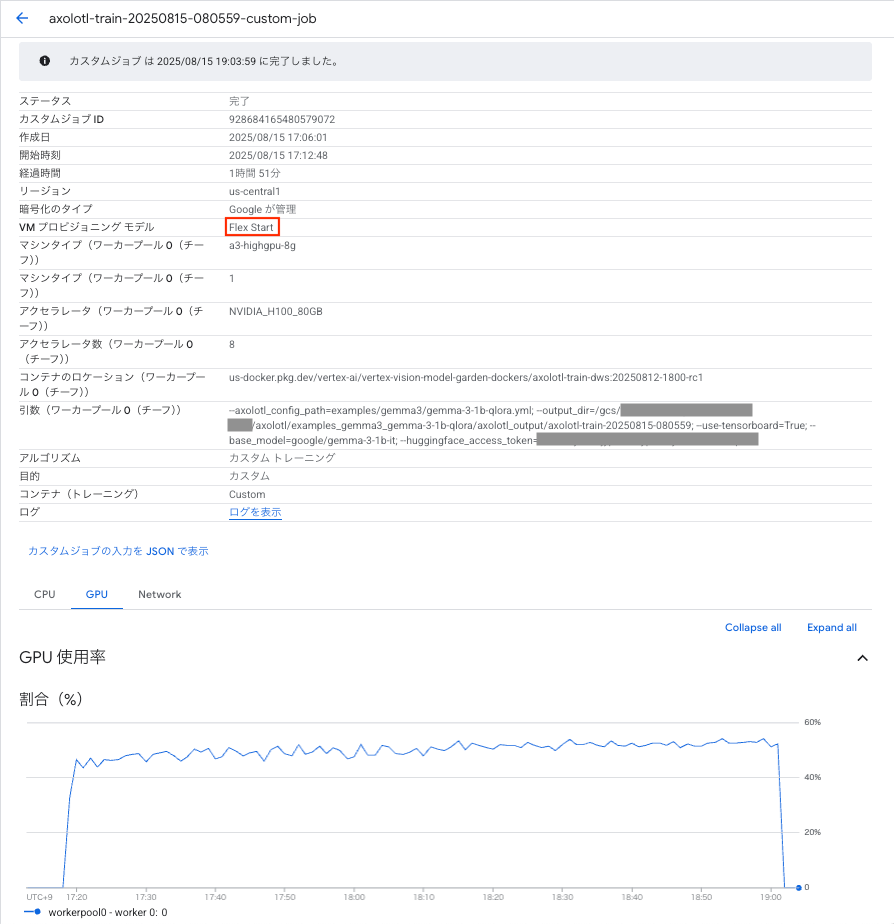
続いて請求レポートを見ていきましょう。

オンデマンドと異なり、DWS 利用時には Compute Engine と Vertex AI に分かれて費用が計上されていました。
少々複雑で分かりづらいのですが、DWS 利用時には GPU を含む VM に係る費用は Compute Engine 側の SKU [5] が適用され、Vertex AI 側は Management Fee (管理手数料) の SKU が適用される、ハイブリッドな課金体系となっております。[6]
DWS Flex-Start の料金も SKU 単位で 1 時間あたりに換算して再計算します。
| SKU | サービス | SKU ID | 単価 | 単位 | 数量 | 小計 |
|---|---|---|---|---|---|---|
| Nvidia H100 80GB GPU attached to DWS Defined Duration VMs running in Americas | Compute Engine | 341A-49A5-0C07 | $4.200761 | per 1 hour | 8 | $33.606088 |
| DWS Defined Duration A3 Core running in Americas | Compute Engine | 9A32-36B2-7FBC | $0.010934 | per 1 hour | 208 | $2.274272 |
| DWS Defined Duration A3 Ram running in Americas | Compute Engine | ED19-A584-4A84 | $0.000952 | per 1 gigabyte hour | 1,872 | $1.782144 |
| DWS Defined Duration SSD backed Local Storage running in Americas | Compute Engine | 2303-1D6A-9C08 | $0.0001096 [3:1] | per 1 gibibyte hour | 6,000 | $0.65753425 |
| Vertex AI: Training/Pipelines management fee on NVIDIA H100 80GB in Iowa | Vertex AI | 5853-505F-A5C4 | $1.4694826 | per 1 hour | 8 | $11.7558608 |
| Vertex AI: Training/Pipelines management fee on A3 Instance Core in Iowa | Vertex AI | 9AC1-7D9B-C47E | $0.0038247 | per 1 hour | 208 | $0.7955376 |
| Vertex AI: Training/Pipelines management fee on A3 Instance RAM in Iowa | Vertex AI | D30D-69C9-F057 | $0.0003331 | per 1 gigabyte hour | 1,872 | $0.6235632 |
| Vertex AI: Training/Pipelines on SSD backed PD Capacity | Vertex AI | A005-98FE-36CC | $0.0002678 [3:2] | per 1 gigabyte hour | 2,000 [4:1] | $0.53561644 |
合計: $52.0306163 per hour
オンデマンドと比べると、DWS Flex-Start 利用時には 48.76% も安く利用できていました。
Vertex AI Online Prediction 料金比較
続いて Vertex AI Online Prediction を動かして料金を比較していきます。
2025 年 7 月のリリースにて Online Prediction でも DWS Flex-Start が利用できるようになりましたが、こちらは A3 High VM のより小さなマシンタイプもサポートされていますので、今回は us-central1 リージョンで、NVIDIA H100 GPU を 1 個搭載したマシンタイプ a3-highgpu-1g を利用してエンドポイントにモデルをデプロイします。
| マシンタイプ | GPU 数 | GPU メモリ (GB) | vCPU 数 | VM メモリ (GB) | ローカル SSD (GiB) |
|---|---|---|---|---|---|
| a3-highgpu-1g | 1 | 80 | 26 | 234 | 750 |
こちらも十分な Quota が割り当てられているか事前に確認します。
対象の割り当て (Quota)
- オンデマンド:
aiplatform.googleapis.com/custom_model_serving_nvidia_h100_gpus - DWS Flex-Start:
aiplatform.googleapis.com/custom_model_serving_preemptible_nvidia_h100_gpus
今回は上記 Quota の割り当て量がそれぞれ 1 必要となります。
Gemma 3 (1B) モデルをエンドポイントにデプロイ
Online Precition の方はシンプルな GUI 操作だけでデプロイが可能で、今回は Gemma 3 モデルカードの Deploy options から Vertex AI を選択します。
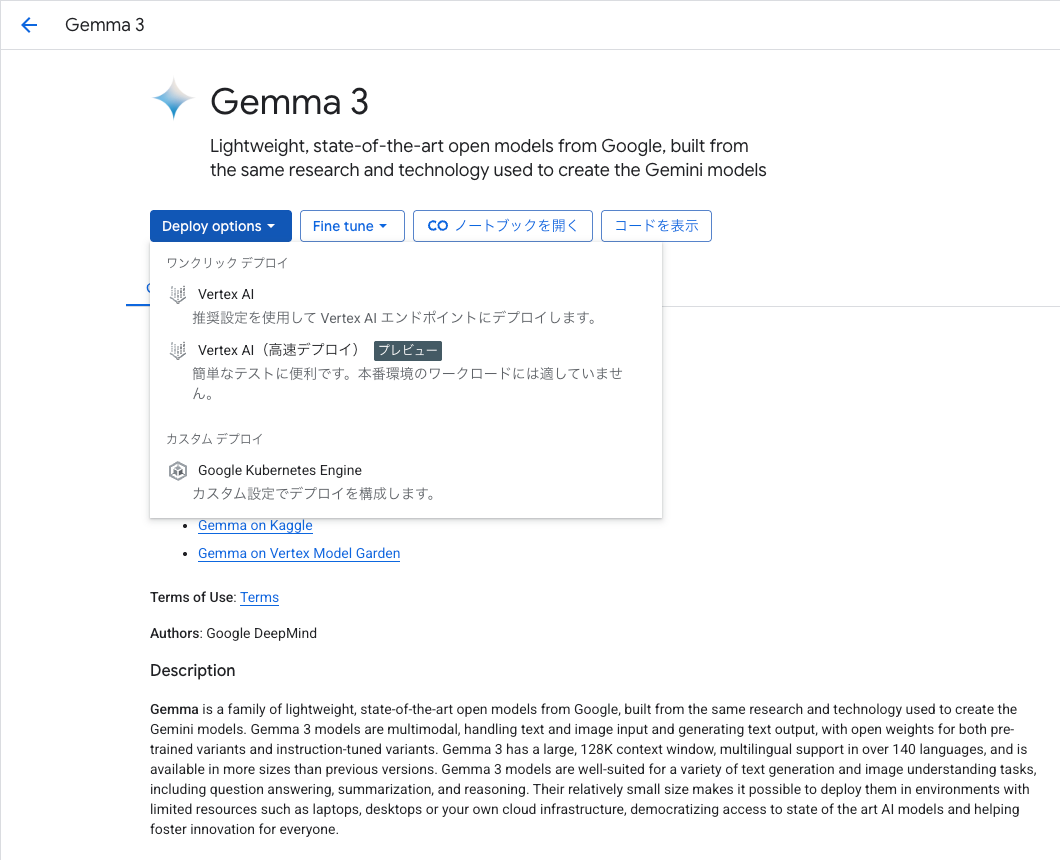
画面右側にデプロイの設定を入力する枠が表示されますので、リソース ID とリージョンを以下の通り設定します。
- リソース ID:
gemma-3-1b-it - リージョン:
us-central1
オンデマンド
オンデマンドの場合、リソース ID とリージョンを指定したら、あとはデフォルト値のままでデプロイを実行します。
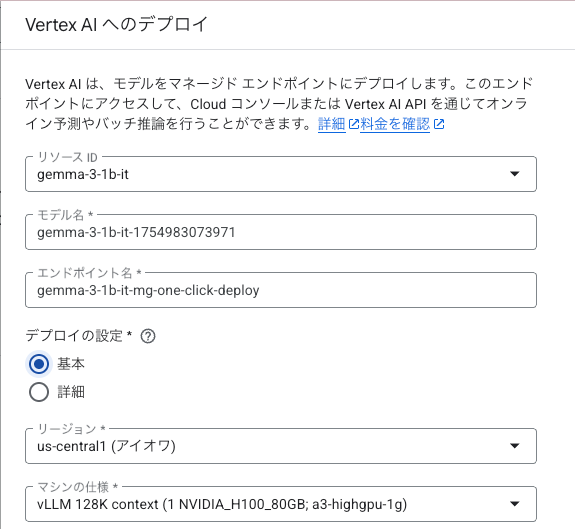
無事にデプロイが完了しました。
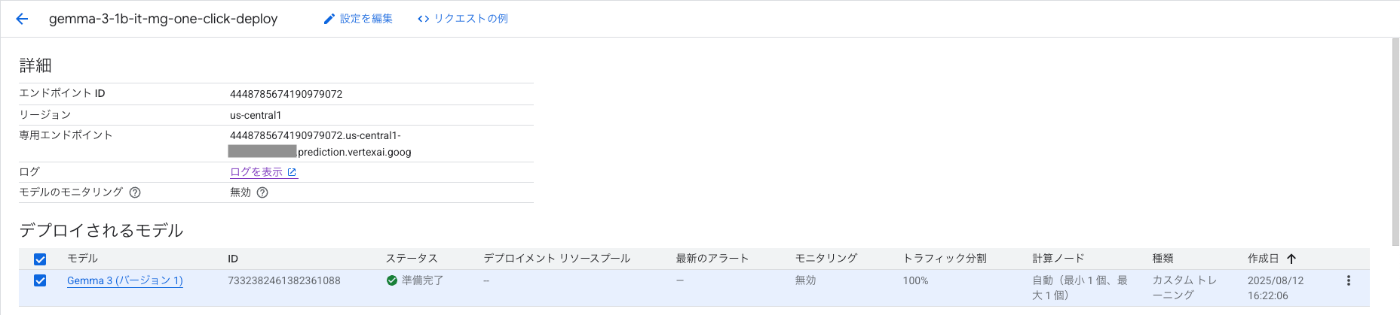
Training と同様に Cloud Billing のレポート上で料金を確認します。

上記の SKU を元に 1 時間あたりの料金に換算して再計算します。
| SKU | サービス | SKU ID | 単価 | 単位 | 数量 | 小計 |
|---|---|---|---|---|---|---|
| Vertex AI: Online/Batch Prediction Nvidia H100 80gb GPU running in Iowa | Vertex AI | AE9C-DB60-DF46 | $11.2660332 | per 1 hour | 1 | $11.2660332 |
| Vertex AI: Online/Batch Prediction A3 Predefined Instance Core running in Iowa | Vertex AI | A002-4323-D900 | $0.0293227 | per 1 hour | 26 | $0.7623902 |
| Vertex AI: Online/Batch Prediction A3 Predefined Instance Ram running in Iowa | Vertex AI | 2424-9F04-82A8 | $0.0025534 | per 1 gigabyte hour | 234 | $0.5974956 |
合計: $12.625919 per hour
DWS Flex-Start
DWS Flex-Start の場合は、デプロイ設定画面のデプロイの設定で詳細を選択します。次に可用性ポリシーにある VM プロビジョニング モデルを Flex Start に変更してデプロイを実行します。
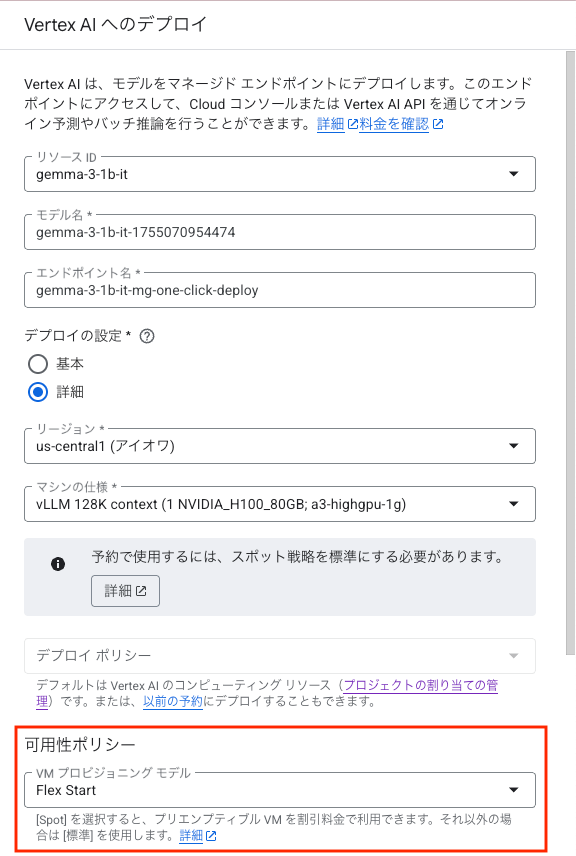
こちらも無事にデプロイが完了しました。
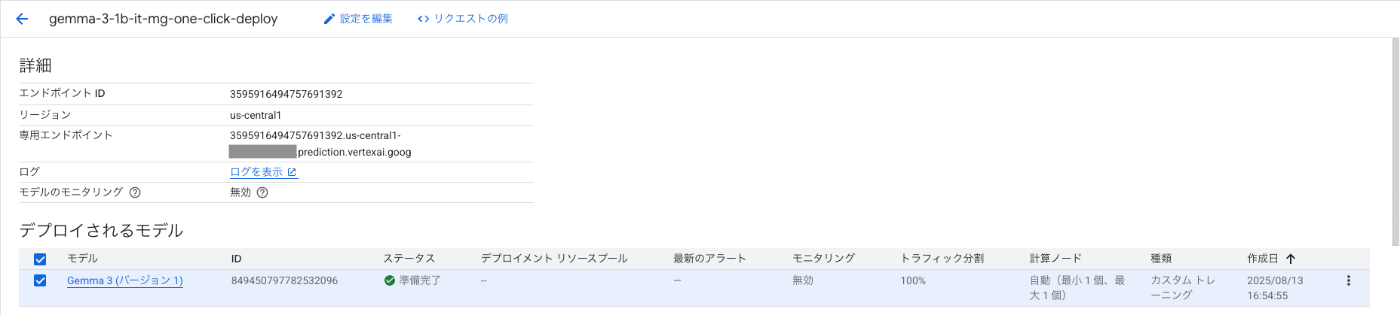
Cloud Billing の請求レポートを見ていきましょう。

Training 同様に、Prediction でも DWS Flex-Start 利用時には Compute Engine と Vertex AI に分かれて費用が計上されていました。
こちらも 1 時間あたりの料金に換算して再計算します。
| SKU | サービス | SKU ID | 単価 | 単位 | 数量 | 小計 |
|---|---|---|---|---|---|---|
| Nvidia H100 80GB GPU attached to DWS Defined Duration VMs running in Americas | Compute Engine | 341A-49A5-0C07 | $4.200761 | per 1 hour | 1 | $4.200761 |
| DWS Defined Duration A3 Core running in Americas | Compute Engine | 9A32-36B2-7FBC | $0.010934 | per 1 hour | 26 | $0.284284 |
| DWS Defined Duration A3 Ram running in Americas | Compute Engine | ED19-A584-4A84 | $0.000952 | per 1 gigabyte hour | 234 | $0.222768 |
| DWS Defined Duration SSD backed Local Storage running in Americas | Compute Engine | 2303-1D6A-9C08 | $0.0001096 [3:3] | per 1 gibibyte hour | 750 | $0.0821918 |
| Vertex AI: Online/Batch Prediction management fee on NVIDIA H100 80GB in Iowa | Vertex AI | 1797-967A-274D | $1.4694826 | per 1 hour | 1 | $1.4694826 |
| Vertex AI: Online/Batch Prediction management fee on A3 Instance Core in Iowa | Vertex AI | 9AC1-7D9B-C47E | $0.0038247 | per 1 hour | 26 | $0.0994422 |
| Vertex AI: Online/Batch Prediction management fee on A3 Instance RAM in Iowa | Vertex AI | 5692-009D-2057 | $0.0003331 | per 1 gigabyte hour | 234 | $0.0779454 |
合計: $6.436875 per hour
Prediction においても DWS Flex-Start 利用時には、オンデマンド比で 49.02% の割引率で利用できていました。
まとめ
- DWS Flex-Start の新しい料金プランにより、NVIDIA H100 GPU を搭載した A3 High VM を利用した場合、Vertex AI Training / Online Prediction いずれの場合も、オンデマンド比で最大約半額の割引価格で利用できることが確認できました。
- Vertex AI では、オンデマンド利用時と DWS 利用時で使用される SKU 体系が異なり、DWS では Compute Engine の VM 利用料と Vertex AI の管理手数料を組み合わせたハイブリッドな課金体系となっておりました。
最後に
- DWS Flex-Start を実際に試される際には、制約や要件 (Training / Prediction) についても事前にご確認いただいた上でご利用ください。
- 今回は Vertex AI を利用した解説をしましたが、GCE や GKE を活用して Vertex AI 以外から DWS Flex-Start を利用する際も DWS の新料金の恩恵を受けることができます。その場合 Vertex AI における管理手数料が発生しないため、より深い割引率で利用することが可能です。
- マシンタイプやリージョンによっては割引率が異なることもありますので、実際に利用する際には、以下の SKU グループ等を参照して事前に費用を試算いただくことをお勧めします。
Compute Engine SKU Groups
- Flex-start Mode A2 VMs
- Flex-start Mode A3 VMs
- Flex-start Mode A3 Mega VMs
- Flex-start mode A3 Ultra VMs
- Flex-start Mode A4 VMs
- Flex-start Mode Local SSD
Vertex AI SKU Groups
-
SKU 上の単価はあくまでも Unit Price となりますので、費用合計を算出するためには、単価に対して GPU 数、vCPU 数、RAM 容量などの数量を掛けて算出する必要があります。 ↩︎
-
SKU 上の単位は
per 1 gibibyte monthですが、単位をper 1 gibibyte hourにあわせるために、1 ヶ月 ≒ 730 時間で割った金額を単価としています。 ↩︎ ↩︎ ↩︎ ↩︎ -
Training ジョブ実行時のブートディスクのサイズによります。今回はノートブック内で
2,000 GiBと指定しています。 ↩︎ ↩︎ -
Compute Engine 側で DWS Flex-Start を直接利用する場合も同じ SKU が適用されます。 ↩︎
-
Vertex AI の料金によると、Vertex AI で Spot VM や Reservations (予約) を利用する場合も、DWS 利用時と同様に Compute Engine の SKU と Vertex AI の Management Fee (管理手数料) SKU の組み合わせの課金体系となることが明記されています。 ↩︎

Discussion