何の話かと言うと
Google Cloud で提供される基盤モデルの Gemini 1.5 Pro / Flash には、Google 検索や Vertex AI Search と連携するグラウンディング機能があります。この機能の使い方を説明します。
基礎知識の確認
大規模言語モデルは、モデルの学習時に得た情報をもとに回答を生成するため、学習時に存在しない情報を必要とする質問には正しく回答できません。この課題を解決する方法として、大きく、ファインチューニングとプロンプトエンジニアリングの 2 つの手法があります。

大規模言語モデルの回答品質を向上する方法
ファインチューニングは、追加学習用のデータや学習処理を実行するインフラが必要となるので、まずは、プロンプトエンジニアリングを試す場合が多いでしょう。プロンプトエンジニアリングによる改善例としてよくあるのが、学習時に存在しない情報をプロンプトに直接埋め込む、グラウンディングの手法です。次は、カスタマーサポートの AI エージェントを実現するプロンプトの例ですが、カスタマーサポートの担当者として知っておくべき知識をすべてまとめてプロンプトに追加しています。

カスタマーサポートのAIエージェントを実現するプロンプトの例
ここで、グラウンディングと RAG の違いに注意してください。ここでは、固定的な情報をプロンプトに埋め込んでいますが、この発展系として、質問に応じて埋め込む情報を動的に選択するのが RAG の仕組みです。RAG を実現するには、質問に応じて回答に必要な情報を取得する検索システムが別途必要になります。

大規模言語モデルの回答品質を向上する方法
下記の記事でも説明したように、RAG を実現する際のハードルになるのが、この検索システムの構築です。
Gemini 1.5 Pro / Flash では、この部分のハードルを下げるために、Google 検索や Vertex AI Search などの既存の検索システムと自動連携する仕組みがあらかじめ用意されています。
Google 検索を用いたグラウンディング
ここでは、Python SDK を用いて、Google 検索によるグラウンディング機能を利用する方法を説明します。Vertex AI Workbench のノートブックからコードを実行するので、まずは、Workbench の環境をセットアップします。
新規のプロジェクトを作成したら、Cloud Shell から次のコマンドを実行します。ここでは、必要な API を有効化して、Vertex AI のサービスエージェントを作成しています。
gcloud services enable \
aiplatform.googleapis.com \
notebooks.googleapis.com \
cloudresourcemanager.googleapis.com
sleep 10
PROJECT_ID=$(gcloud config list --format 'value(core.project)')
python -c "from google.cloud import aiplatform; \
aiplatform.Endpoint.create( \
project=\"$PROJECT_ID\", location=\"us-central1\").delete()" \
2>/dev/null
続いて、次のコマンドで Workbench のインスタンスを作成します。
gcloud workbench instances create genai-development \
--project=$PROJECT_ID \
--location=us-central1-a \
--machine-type=e2-standard-2
クラウドコンソールのナビゲーションメニューから「Vertex AI」→「ワークベンチ」を選択すると、作成したインスタンス genai-development があります。インスタンスの起動が完了するのを待って、「JUPYTERLAB を開く」をクリックしたら、「Python 3(ipykernel)」の新規ノートブックを作成します。この後は、ノートブックのセルでコードを実行していきます。
はじめに、必要なモジュールをインポートして、SDK を初期化します。
import vertexai
from vertexai.generative_models import GenerationConfig, GenerativeModel, Tool
from IPython.display import display, HTML
vertexai.init()
次に、Gemini API を用いて回答を生成する関数 get_answer_google_search() を定義します。
def get_answer_google_search(prompt, grounding=True):
model = GenerativeModel(model_name='gemini-1.5-flash-001')
if grounding:
tools = [
Tool.from_google_search_retrieval(
google_search_retrieval=vertexai.generative_models.grounding.GoogleSearchRetrieval()
),
]
else:
tools = None
response = model.generate_content(
prompt,
tools=tools,
generation_config=GenerationConfig(
temperature=0.0,
),
)
print(response.candidates[0].content.parts[0].text)
entry_point_html = response.candidates[0].grounding_metadata.search_entry_point.rendered_content
display(HTML(entry_point_html))
return response
モデルを参照したオブジェクト model の generate_content() メソッドで Gemini API を呼び出す部分は、グラウンディング機能を用いない場合と同じですが、ここでは tools オプションに、Google 検索でグラウンディングするツールを与えています。これだけで、Google 検索と連動したグラウンディングが実現します!
API のレスポンス response から response.candidates[0].content.parts[0].text を取り出すと、Gemini の応答テキストが得られます。また、上記のコードでは、 response.candidates[0].grounding_metadata.search_entry_point.rendered_content を取り出していますが、この部分には、「Google 検索に利用したキーワードを含む検索リンク」の HTML が含まれています。この点については、実際の実行結果とあわせて説明します。
まず、次の 2 つのコマンドを実行します。
prompt = '2024年パリ・オリンピックの日本チームのメダル総数は?'
response = get_answer_google_search(prompt, grounding=False)
prompt = '2024年パリ・オリンピックの日本チームのメダル総数は?'
response = get_answer_google_search(prompt, grounding=True)
どちらも「2024年パリ・オリンピックの日本チームのメダル総数は?」という質問を投げていますが、1 つ目はグラウンディング機能を使用しない設定で、2 つ目はグラウンディング機能を使用する設定になります。それぞれの結果は、次のようになります。
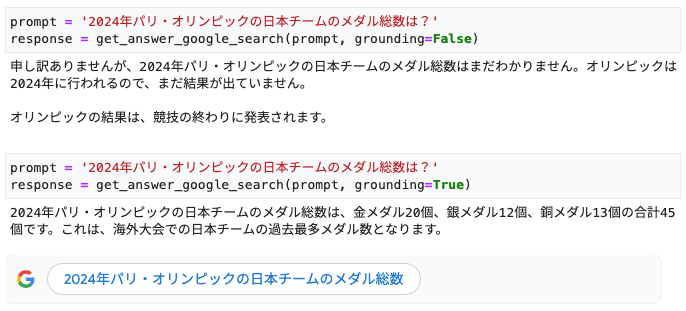
Google 検索によるグラウンディングの有無で結果が変わる様子
グラウンディングしない場合は、2024年パリ・オリンピックはまだ開催されていない前提での回答が返ります。実際には、2024年パリ・オリンピックはすでに終了しているので、誤った結果です。
一方、グラウンディングした場合は、正しい結果が得られます。回答の下に「2024年パリ・オリンピックの日本チームのメダル総数」というボタンが表示されていますが、これは、先ほど取り出した HTML をレンダリングしたものです。Gemini は、このキーワードで Google 検索を実行して、得られた情報をもとに回答を生成しています。実際には、検索結果の中から回答に役立つ部分を選択するなどの処理も必要ですが、この部分は API の裏側で自動的に行われます。
Vertex AI Search を用いたグラウンディング
続いて、Vertex AI Search によるグラウンディング機能を利用する方法を説明します。これには、大きく、次の 2 つの方法があります。
- (1) Gemini API のグラウンディング機能を使用する
- (2) Vertex AI Search の Answer API を使用する
(1) は、generate_content() メソッドで Gemini API を呼び出す際に、tools オプションに Vertex AI Search でグラウンディングするツールを与える方法です。(2) は、Vertex AI Search 自身が提供する QA 用の API を用いる方法です。ここでは、(2) の方法を詳しく解説します。
Vertex AI Search の環境準備
はじめに、Vertex AI Search によるドキュメント検索環境を用意します。
Cloud Shell で次のコマンドを実行します。ここでは、ストレージバケット [Project ID]-sample を作成して、検索対象の PDF を保存しています。例として、デジタル庁が公開している 3 つのドキュメントを使用しています。(本文中の [Project ID] の部分は、実際に使用するプロジェクト ID に置き換えて読んでください。)
PROJECT_ID=$(gcloud config list --format 'value(core.project)')
BUCKET="gs://${PROJECT_ID}-sample"
gsutil mb -b on -l us-central1 $BUCKET
sleep 10
base_url="https://raw.githubusercontent.com/google-cloud-japan/sa-ml-workshop/main"
for file in agile-guidebook.pdf handbook-prologue.pdf standard-guideline.pdf; do
curl -OL $base_url/genAI_book/PDF/$file
gsutil cp $file $BUCKET/
rm -f $file
done
続いて、Vertex AI Search のデータストアを作成します。クラウドコンソールのナビゲーションメニューから「Agent Builder」を選択して、[CONTINUE AND ACTIVATE THE API] をクリックします。左のメニューで「データストア」を選択したら、「データストアを作成」をクリックして、データソースに「Cloud Storage」を選択します。

データストアの作成手順 1
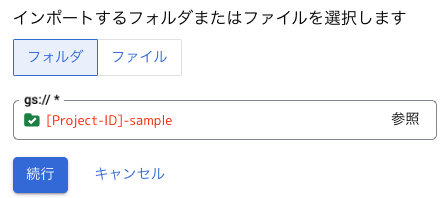
「Cloud Storage のデータをインポート」の画面が表示されるので、インポートするフォルダに先ほど作成したバケット [Project-ID]-sample を指定して、[続行] をクリックします。
データストアの作成手順 2
「データストアの構成」の画面が表示されるので、データストア名に「grounding-datastore」を指定して、[作成] をクリックします。

データストアの作成手順 3
次に、このデータストアを使用する検索アプリケーションを構成します。左のメニューで「アプリ」を選択して、「アプリを作成する」をクリックしたら、アプリの種類に「検索」を選択します。
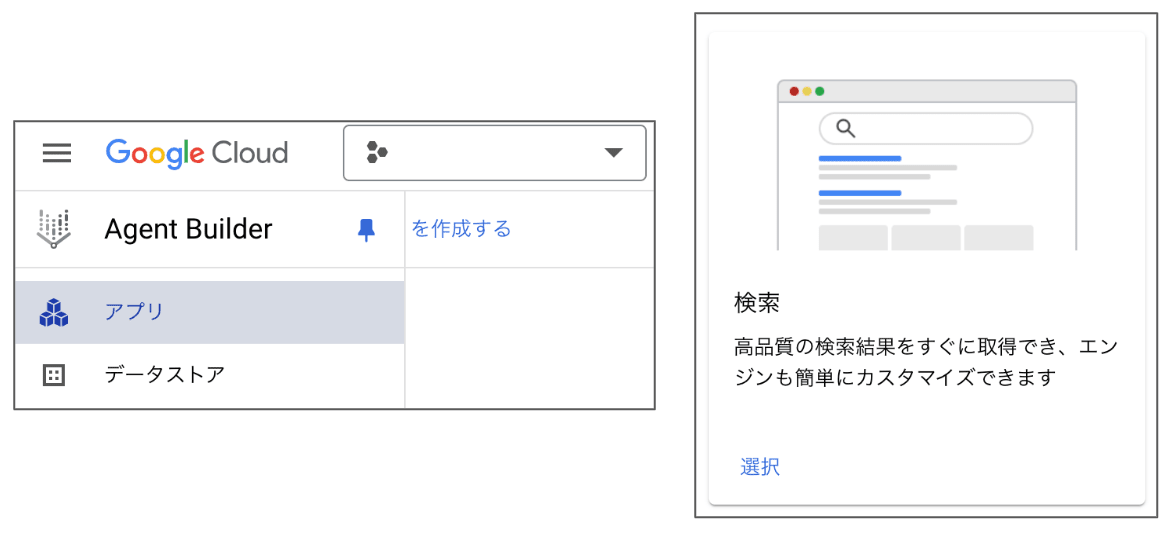
検索アプリケーションの作成手順 1
「アプリの構成の検索」の画面が表示されるので、アプリ名に「grounding-app」、会社名に「example」を入力して [続行] をクリックします。

検索アプリケーションの作成手順 2
「データストア」の画面が表示されるので、先ほど作成した「groundig-datastore」を選択して、[作成] をクリックします。

検索アプリケーションの作成手順 3
データストアの管理画面が表示されるので、「アクティビティ」のタブを選択して、データのインポートが完了するのを待ちます。また、画面上部に表示された「データストアの ID」の値をコピーして保存しておきます。

検索アプリケーションの作成手順 4
これで、Vertex AI Search の環境が用意できました。
Answer API の利用
Workbench の環境に戻って、「Python 3(ipykernel)」の新規ノートブックを作成します。ここからは、ノートブックのセルでコードを実行していきます。
はじめに、次のコマンドで、Vertex AI のクライアント SDK のパッケージをインストールします。
!pip install --user --upgrade google-cloud-discoveryengine
インストールしたパッケージが利用できるように、ノートブックのカーネルを再起動します。
import IPython
app = IPython.Application.instance()
_ = app.kernel.do_shutdown(True)
必要なモジュールをインポートして、検索クライアントのオブジェクトを取得します。DATA_STORE_ID には、先ほど確認したデータストア ID を指定します。
from google.cloud import discoveryengine_v1alpha as discoveryengine
from google.api_core.client_options import ClientOptions
[PROJECT_ID] = !gcloud config list --format 'value(core.project)'
[PROJECT_NO] = !gcloud projects describe {PROJECT_ID} --format='value(projectNumber)'
VERTEX_AI_LOCATION = 'global'
DATA_STORE_ID = 'grounding-datastore_xxxxxxxx' # 実際に使用するデータストア ID を指定
search_client = discoveryengine.ConversationalSearchServiceClient(
client_options=(
ClientOptions(api_endpoint=f'{VERTEX_AI_LOCATION}-discoveryengine.googleapis.com')
if VERTEX_AI_LOCATION != 'global'
else None
)
)
検索クライアントを利用して、質問に回答する関数 get_answer_vais() を定義します。
def get_answer_vais(query_text):
query = discoveryengine.Query()
query.text = query_text
request = discoveryengine.AnswerQueryRequest(
serving_config=('projects/{}/locations/global/collections/default_collection'
'/dataStores/{}/servingConfigs/default_serving_config'
).format(PROJECT_NO, DATA_STORE_ID),
query=query,
answer_generation_spec=discoveryengine.AnswerQueryRequest.AnswerGenerationSpec(
model_spec=discoveryengine.AnswerQueryRequest.AnswerGenerationSpec.ModelSpec(
model_version='gemini-1.5-flash-001/answer_gen/v1'
),
prompt_spec=discoveryengine.AnswerQueryRequest.AnswerGenerationSpec.PromptSpec(
preamble='Answer in Japanese. In plaintext, no markdowns.'
),
include_citations=True,
),
)
response = search_client.answer_query(request=request)
print(response.answer.answer_text)
return response
ここでは、必要最小限のオプションのみを指定しています。詳細については、次の公式ドキュメントを参照してください。
先ほどの手順で用意したデータストアには、「アジャイル開発実践ガイドブック」が含まれているので、アジャイル開発に関する質問をしてみます。
prompt = 'アジャイル開発のメリットを説明して'
response = get_answer_vais(prompt)
[出力結果]
アジャイル開発は、従来のウォーターフォール型開発と比べて、柔軟性と迅速性を持ち、変化に
適応しやすい開発手法です。開発の初期段階からユーザーのフィードバックを取り入れ、段階的
にシステムを構築していくため、ユーザーのニーズに合致したシステムを開発できます。また、
開発期間を短縮し、市場への投入を早めることが可能になります。さらに、開発チームのコミュニ
ケーションを促進し、チームワークを向上させる効果も期待できます。ただし、アジャイル開発は、
関係者全員が協力し、共通の目標に向かって取り組むことが重要です。
それらしい答えが返ってきましたが、これだけでは、実際にグラウンディングされているかがわかりません。API のレスポンス response にグラウンディングに関する情報が含まれており、ここからどのようにグラウンディングされたかが確認できます。ここでは、説明のために Protobuf 形式のデータを Python の辞書形式に変換します。
import proto
response_dict = proto.Message.to_dict(response.answer)
citations, references = response_dict['citations'], response_dict['references']
まず、citations には、「回答テキストのどの部分がどの情報(テキストチャンク)に基づいているのか」という情報が入っており、具体的には次のような内容になります。
[
{
'start_index': '0',
'end_index': '168',
'sources': [{'reference_id': '1'}, {'reference_id': '2'}, {'reference_id': '4'}],
},
{
'start_index': '170',
'end_index': '380',
'sources': [{'reference_id': '1'}, {'reference_id': '2'}]
},
...(以下省略)...
]
リスト形式で複数の情報が与えられており、たとえば、最初の要素は「回答テキストの 0 バイト目から 168 バイト目までは、reference_id が 1, 2, 4 の 3 つのテキストチャンクに基づいている」ことを意味します。
それぞれの reference_id で示されるテキストチャンクの内容は、references から確認できます。こちらは、reference_id の順に情報が格納されたリストになっており、たとえば、最初の要素 references[0] は次のようになります。
{
'chunk_info': {
'content': '15 1 つです。XP は、ペアプログラミングや …(中略)… の複雑度も増加します。 ',
'relevance_score': 0.4,
'document_metadata': {
'document': 'projects/675744119732/locations/global/collections/default_collection/dataStores/grounding-datastore_1726633598820/branches/0/documents/f988782be652186bdea5bdb0e1236109',
'uri': 'gs://etsuji-15pro-poc-sample2/agile-guidebook.pdf',
'title': 'アジャイル開発実践ガイドブック ',
'page_identifier': '19'
},
'chunk': ''
}
}
少し複雑な構成ですが、たとえば、次のような情報が参照できることがわかります。
-
reference_id[0]['chunk_info']['content']:テキストチャンクの中身 -
reference_id[0]['chunk_info']['document_metadata']['document']:テキストチャンクを含むドキュメントの(Vertex AI Search 内部で定義された)ドキュメント ID -
reference_id[0]['chunk_info']['document_metadata']['title']:テキストチャンクを含むドキュメントのタイトル -
reference_id[0]['chunk_info']['document_metadata']['uri']:テキストチャンクを含むドキュメントの URI
これらの情報を元の回答文にマッピングして表示する関数 render_response() を例示すると、次のようになります。
def render_response(response):
answer = response.answer.answer_text
answer = answer.encode()
answer_with_citations = ''
all_ids = []
end_index_pre = 0
for item in response.answer.citations:
start_index = item.start_index
end_index = item.end_index + 1
sources = item.sources
ids = []
for source in item.sources:
ids.append(int(source.reference_id)+1)
all_ids.append(int(source.reference_id)+1)
answer_with_citations += ''.join([
answer[end_index_pre:start_index].decode(),
'{', answer[start_index:end_index].decode(),str(ids), '}'
])
end_index_pre = end_index
answer_with_citations += answer[end_index_pre:].decode()
print('<回答>')
print(answer_with_citations)
print()
print('<ソース>')
for c, item in enumerate(response.answer.references):
if c+1 in all_ids:
chunk = item.chunk_info.content
chunk = chunk.replace('\n', '')
title = item.chunk_info.document_metadata.title
print(f'[{c+1}] {title}')
print(f' # {chunk[:50]}...')
先ほど得られたレスポンスを適用すると、次の結果が得られます。
render_response(response)
[実行結果]
<回答>
{アジャイル開発は、従来のウォーターフォール型開発と比べて、柔軟性と迅速性を持ち、変化に
適応しやすい開発手法です。 [2, 3, 5]} {開発の初期段階からユーザーのフィードバックを
取り入れ、段階的にシステムを構築していくため、ユーザーのニーズに合致したシステムを開発
できます。 [2, 3]} {また、開発期間を短縮し、市場への投入を早めることが可能になります。
[2, 3]} {さらに、開発チームのコミュニケーションを促進し、チームワークを向上させる効果も
期待できます。 [4, 10]} {ただし、アジャイル開発は、関係者全員が協力し、共通の目標に
向かって取り組むことが重要です。 [10]}
<ソース>
[2] アジャイル開発実践ガイドブック
# 1 1 はじめに 1.1 背景と目的本ガイドブックは、政府情報システム開発におけるアジャイル開発の適...
[3] アジャイル開発実践ガイドブック
# 特に、政府情報システムの利用は府省職員だけではなく、自治体や国民をもその範囲とするため、昨今の社会環...
[4] アジャイル開発実践ガイドブック
# 16 3 アジャイル開発の運営 3.1 運営の概要アジャイル開発の実際の運営に際して、以下の内容を把...
[5] デジタル社会推進標準ガイドライン DS-100
# オ 開発形態、開発手法、開発環境、開発ツール等設計・開発において採用する開発方式(スクラッチ開発、ソ...
[10] アジャイル開発実践ガイドブック
# なお、アジャイル開発の適用にあたっては、本ガイドブックの記述どおり進めれば上手くいくというわけではな...
回答文の {...} で括られた部分のそれぞれに、対応するテキストチャンクの番号が付与されており、たとえば、冒頭の「アジャイル開発は、・・・開発手法です。」の部分は、2, 3, 5 のテキストチャンクを根拠に生成されたとわかります。下の<ソース> 部分には、各テキストチャンクを含むドキュメントのタイトルと、実際のテキストチャンクの内容(先頭の 50 文字)を表示しています。大部分が「アジャイル開発実践ガイドブック」の内容でグラウンディングされており、一部、「デジタル社会推進標準ガイドライン」の開発方式に言及したテキストも用いられていることがわかります。
まとめ
冒頭で触れたように、RAG システムの構築では、グラウンディングに必要な情報を取得する検索システムの構築が技術的なハードルになることがよくあります。Gemini 1.5 Pro / Flash のグラウンディング機能を利用すると、Google 検索や Vertex AI Search といった既存の検索システムと簡単に連携できて、検索処理を API の裏側で自動実行することができます。
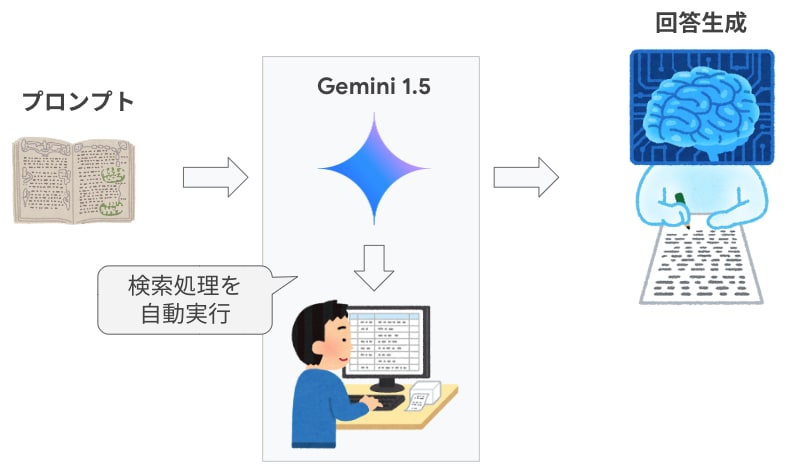
Gemini 1.5 のグラウンディング機能
この記事で紹介したコードを参考にして、Gemini 1.5 Pro / Flash を活用した生成 AI アプリにグラウンディング処理を組み入れてみてください。

Discussion