はじめに
2024年4月3日に、下記の Google Cloud 公式ブログ記事が公開されました。
この記事で紹介されているチュートリアル nvidia-nemo-on-gke に従うと、Google Cloud で次の処理が体験できます。
- NVIDIA H100 Tensor Core GPU を接続したノードによる Google Kubernetes Engine(GKE)のクラスターを構築する
- NVIDIA NeMo Framework のサンプルコードを利用して、LLM(Megatron GPT)の事前学習を実行する
とはいえ・・・、「わざわざ GKE クラスターを構築するのは面倒なので、Vetrex AI のマネージドサービスだけで LLM の学習処理を体験してみたい!」という方もいるかもしれません。そこで、この記事では、Vertex AI Custom training の環境で、NeMo Framework のコードを使って LLM の分散学習処理を実行する手順を紹介します。
手軽に体験できるように、比較的安価な NVIDIA T4 GPU と小さめのモデル(Megatron GPT-5B からレイヤー数などを削減したもの)を使用して、2 GPU × 4 ノード(合計 8 GPU) での分散学習を実現します。
NeMo Framework とは?
一言で説明すると、NVIDIA の GPU を使って主要な基盤モデルのさまざまな学習処理が実施できるように、必要なツールやライブラリ、スクリプトなどをまるっと詰め込んだ環境をコンテナイメージとして用意したものです。イメージの一覧はこちらで確認できます。中に入っているツール群は、GitHub リポジトリで公開されています。
Vertex AI Custom training とは?
こちらも一言で説明すると、学習処理を実行するコードを含んだコンテナイメージを用意しておき、API リクエストを投げると、指定した構成のノードでコンテナが起動して学習処理が行われるマネージドサービスです。事前にクラスターを構築する必要がなく、さまざまなサイズの VM や、さまざまな種類の GPU を実行ごとに自由に指定できます。
各ノードには GCS バケットがファイルシステムとしてマウントされるので(Cloud Storage FUSE を利用しています)、これを共有ストレージとして使用できます。具体的には、パス /gcs/[Bucket Name] から任意のバケットにアクセスできます[1]。
事前準備
共有ストレージとして使用するストレージバケットを事前に作成しておきます。また、この後の手順では Jupyter Notebook で作業をするので、Vertex AI Workbench のノートブック環境を用意します。
新しいプロジェクトを作成した後に、Cloud Shell を開いて次のコマンドを実行していきます。これ以降に登場するスクリーンショットでは etsuji-nemo-poc という名前のプロジェクトを使用しています。
API 有効化
Vertex AI Custom Training と Vertex AI Workbench、そして、コンテナイメージのビルドに使う Cloud Build を使用するのに必要な API を有効化します。
gcloud services enable \
aiplatform.googleapis.com \
notebooks.googleapis.com \
cloudbuild.googleapis.com
ストレージバケット作成
共有ストレージとして使用するバケットを作成します。バケット名は [Project ID]-training とします[2]。
PROJECT_ID=$(gcloud config list --format 'value(core.project)')
BUCKET="gs://${PROJECT_ID}-training"
gsutil mb -b on -l us-central1 $BUCKET
Workbench インスタンス作成
Workbench インスタンスを作成します。インスタンス名は llm-training とします。
gcloud workbench instances create llm-training \
--project=$PROJECT_ID \
--location=us-central1-a \
--machine-type=e2-standard-2
コンテナイメージのリポジトリ作成
コンテナイメージを保存するリポジトリを作成します。リポジトリ名は container-image-repo とします。
gcloud artifacts repositories create container-image-repo \
--repository-format docker \
--location us-central1
マルチノード分散学習を体験
クラウドコンソールのナビゲーションメニューから「Vertex AI」→「ワークベンチ」を選択すると、先ほど作成したインスタンス llm-training があります。インスタンスの起動が完了するのを待って、「JUPYTERLAB を開く」をクリックしたら、「TensorFlow 2-11(Local)」の新規ノートブックを作成します[3]。
この後は、ノートブックのセルでコマンドを実行していきます。
環境情報の設定
次のコマンドで、プロジェクト ID とバケット名を変数に保存しておきます。
PROJECT_ID = !gcloud config list --format 'value(core.project)'
PROJECT_ID = PROJECT_ID[0]
BUCKET = f'gs://{PROJECT_ID}-training'
また、次のコマンドで、この後で使用するディレクトリを作成します。
!mkdir -p work_dir trainer
Experiment Manager の設定
NeMo Framework では、ハイパーパラメーターの設定、PyTorch Lightning を用いたチェックポイントの生成、TensorBoard 用のログの出力などをまとめて管理する Experiment Manager の機能が用意されています。Experiment Manager の設定ファイルで、学習対象のモデルのレイヤー数、学習時のバッチサイズなど、学習処理に関連したハイパーパラメーターがまとめて指定できます。
今回は、冒頭で紹介したチュートリアルが提供する設定ファイル gpt-5b.yaml をベースにして、モデルのサイズを小さくした設定ファイル gpt-small.yaml を用意します。
次のコマンドを実行して、作業用ディレクトリ work_dir に gpt-small.yaml を保存します。
%%writefile work_dir/gpt-small.yaml
run:
name: GPT-SMALL # GPT-5B
trainer:
devices: auto # 8
accelerator: gpu
precision: bf16
logger: false # logger provided by exp_manager
enable_checkpointing: false # checkpointing provided by exp_manager
# replace_sampler_ddp: false
use_distributed_sampler: false
max_epochs: null
max_steps: 50 # consumed_samples = global_step * global_batch_size
max_time: "05:00:00:00"
log_every_n_steps: 1
val_check_interval: 10 # 50
limit_val_batches: 10 # 0.0
limit_test_batches: 10
accumulate_grad_batches: 1
gradient_clip_val: 1.0
enable_progress_bar: true # false
exp_manager:
explicit_log_dir: null
name: megatron_gpt
create_wandb_logger: false
wandb_logger_kwargs:
project: null
name: null
resume_if_exists: true
resume_ignore_no_checkpoint: true
create_checkpoint_callback: true
checkpoint_callback_params:
monitor: val_loss
save_top_k: 10
mode: min
always_save_nemo: false # saves nemo file during validation, not implemented for model parallel
save_nemo_on_train_end: false # not recommended when training large models on clusters with short time limits
filename: 'megatron_gpt--{val_loss:.2f}-{step}-{consumed_samples}'
model_parallel_size: ${multiply:${model.tensor_model_parallel_size}, ${model.pipeline_model_parallel_size}}
log_step_timing: true
step_timing_kwargs:
sync_cuda: true
buffer_size: 5
model:
micro_batch_size: 4
global_batch_size: 256 # 2048
rampup_batch_size: null
tensor_model_parallel_size: 1
pipeline_model_parallel_size: 1
virtual_pipeline_model_parallel_size: null # interleaved pipeline
resume_from_checkpoint: null # manually set the checkpoint file to load from
# model architecture
encoder_seq_length: 256 # 2048
max_position_embeddings: 256 # 2048
num_layers: 1 # 24
hidden_size: 256 # 4096
ffn_hidden_size: ${multiply:4, ${.hidden_size}} # Transformer FFN hidden size. 4 * hidden_size.
num_attention_heads: 4 # 32
init_method_std: 0.01 # Standard deviation of the zero mean normal distribution used for weight initialization.')
hidden_dropout: 0.0 # Dropout probability for hidden state transformer.
attention_dropout: 0.0
kv_channels: null # Projection weights dimension in multi-head attention. Set to hidden_size // num_attention_heads if null
apply_query_key_layer_scaling: true # scale Q * K^T by 1 / layer-number.
layernorm_epsilon: 1e-5
make_vocab_size_divisible_by: 128 # Pad the vocab size to be divisible by this value for computation efficiency.
pre_process: true # add embedding
post_process: true # add pooler
persist_layer_norm: true # Use of persistent fused layer norm kernel.
gradient_as_bucket_view: true # Allocate gradients in a contiguous bucket to save memory (less fragmentation and buffer memory)
# Fusion
grad_div_ar_fusion: true # Fuse grad division into torch.distributed.all_reduce
gradient_accumulation_fusion: true # Fuse weight gradient accumulation to GEMMs
bias_activation_fusion: true # Use a kernel that fuses the bias addition from weight matrices with the subsequent activation function.
bias_dropout_add_fusion: true # Use a kernel that fuses the bias addition, dropout and residual connection addition.
masked_softmax_fusion: true # Use a kernel that fuses the attention softmax with it's mask.
## Activation Checkpointing
activations_checkpoint_granularity: null # 'selective' or 'full'
activations_checkpoint_method: null # 'uniform', 'block'
activations_checkpoint_num_layers: null
num_micro_batches_with_partial_activation_checkpoints: null
activations_checkpoint_layers_per_pipeline: null
## Sequence Parallelism
sequence_parallel: false
overlap_p2p_comm: false # Overlap p2p communication with computes. This argument is valid only when `virtual_pipeline_model_parallel_size` is larger than 1
batch_p2p_comm: true # Batch consecutive inter-peer send/recv operations. This argument is valid only when `virtual_pipeline_model_parallel_size` is larger than 1
num_query_groups: null # Number of query groups for group query attention. If None, normal attention is used.
tokenizer:
library: 'megatron'
type: 'GPT2BPETokenizer'
model: null
delimiter: null # only used for tabular tokenizer
vocab_file: gpt2-vocab.json
merge_file: gpt2-merges.txt
# precision
native_amp_init_scale: 4294967296 # 2 ** 32
native_amp_growth_interval: 1000
hysteresis: 2 # Gradient scale hysteresis
fp32_residual_connection: false # Move residual connections to fp32
fp16_lm_cross_entropy: false # Move the cross entropy unreduced loss calculation for lm head to fp16
# Megatron O2-style half-precision
megatron_amp_O2: true # Enable O2-level automatic mixed precision using master parameters
grad_allreduce_chunk_size_mb: 125
mcore_gpt: true
## Transformer Engine
# To use fp8, please set `transformer_engine=true` and `fp8=true`.
# The rest of fp8 knobs are set for the fp8 training mode, which are ignored in non-fp8 training
transformer_engine: true
fp8: false # enables fp8 in TransformerLayer forward
fp8_e4m3: false # sets fp8_format = recipe.Format.E4M3
fp8_hybrid: true # sets fp8_format = recipe.Format.HYBRID
fp8_margin: 0 # scaling margin
fp8_interval: 1 # scaling update interval
fp8_amax_history_len: 1024 # Number of steps for which amax history is recorded per tensor
fp8_amax_compute_algo: max # 'most_recent' or 'max'. Algorithm for computing amax from history
fp8_wgrad: true
# use_emha: false
ub_tp_comm_overlap: false
# miscellaneous
seed: 1234
sync_batch_comm: false
use_cpu_initialization: false # Init weights on the CPU (slow for large models)
onnx_safe: false # Use work-arounds for known problems with Torch ONNX exporter.
apex_transformer_log_level: 30 # Python logging level displays logs with severity greater than or equal to this
# Nsys profiling options
nsys_profile:
enabled: false
trace: [nvtx, cuda]
start_step: 10 # Global batch to start profiling
end_step: 12 # Global batch to end profiling
ranks: [0] # Global rank IDs to profile
gen_shape: false # Generate model and kernel details including input shapes
optim:
name: distributed_fused_adam
bucket_cap_mb: 400
overlap_grad_sync: true
overlap_param_sync: true
contiguous_grad_buffer: true
# grad_sync_dtype: bf16
lr: 1.6e-4
weight_decay: 0.1
betas:
- 0.9
- 0.95
sched:
name: CosineAnnealing
warmup_steps: 115
constant_steps: 12500
min_lr: 1.6e-5
data:
exchange_indices_distributed: true
data_impl: mmap
splits_string: "99990,8,2"
seq_length: 256 # 2048
skip_warmup: true
num_workers: 2
dataloader_type: single # cyclic
reset_position_ids: false # Reset position ids after end-of-document token
reset_attention_mask: false # Reset attention mask after end-of-document token
eod_mask_loss: false # Mask loss for the end of document tokens
# index_mapping_dir: null # path to save index mapping .npy files, by default will save in the same location as data_prefix
index_mapping_dir: /gcs/__BUCKET__/index_mapping # /nfs
最後の index_mapping_dir は共有ストレージを使用するので、__BUCKET__ の部分を先ほど作成したバケットに書き換えます。また、このファイルを共有ストレージとして使うバケットにコピーしておき、コンテナ内のコードから参照できるようにします。
__BUCKET__ 部分の書き換えと、バケットへのコピーは次のコマンドで行います。
BUCKET_NAME = BUCKET.replace('gs://', '')
!sed -i 's#__BUCKET__#{BUCKET_NAME}#g' work_dir/gpt-small.yaml
!gsutil cp work_dir/gpt-small.yaml {BUCKET}/config/
なお、オリジナルのgpt-5b.yamlからの変更部分は以下になります。
run:
name: GPT-SMALL # GPT-5B
trainer:
devices: auto # 8
val_check_interval: 10 # 50
limit_val_batches: 10 # 0.0
enable_progress_bar: true # false
model:
global_batch_size: 256 # 2048
encoder_seq_length: 256 # 2048
max_position_embeddings: 256 # 2048
num_layers: 1 # 24
hidden_size: 256 # 4096
num_attention_heads: 4 # 32
data:
seq_length: 256 # 2048
index_mapping_dir: /gcs/__BUCKET__/index_mapping # /nfs
今回は enable_progress_bar: true の指定があるので、ログファイルに学習の進捗を示すプログレスバーが出力されます。これが不要な場合は、false に変更してください。
学習用コードの実装
コンテナで実行する学習用コード(コンテナ起動時に最初に実行されるコード)を用意します。基本的には、必要な環境変数を設定した上で、TORCH_DISTRIBUTED_TARGET で指定された NeMo Framework が提供するスクリプトをバックグラウンドで実行するだけです。詳細は後で説明します。
次のコマンドで、ディレクトリ trainer の中に学習用コード task.py を保存します。
%%writefile trainer/task.py
import os, json, socket, subprocess, sys, shutil
import datetime, time
from distutils.util import strtobool
debug = strtobool(os.environ.get('DEBUG', 'False'))
## Modify here to change the training script and training data
BASE_DIR = '/opt/NeMo/examples/nlp/language_modeling'
TORCH_DISTRIBUTED_TARGET = f'{BASE_DIR}/megatron_gpt_pretraining.py'
GCS_DATA_SOURCE = 'gs://nemo-megatron-demo/training-data/tokenized/bpe2gpt/wikipedia/'
DATA_FILE_PREFIX = 'wikipedia-tokenized-for-gpt2'
####
## Cache the training data
DATA_PREFIX = '[1.0,{}/{}]'.format(GCS_DATA_SOURCE.replace('gs://', '/gcs/'), DATA_FILE_PREFIX)
if strtobool(os.environ.get('CACHING', 'False')):
GCS_DATA_TARGET = '/ssd/.cache/'
DATA_PREFIX = f'[1.0,/ssd/.cache/{DATA_FILE_PREFIX}]'
print(f'Caching training data from {GCS_DATA_SOURCE} to {GCS_DATA_TARGET}')
os.makedirs(GCS_DATA_TARGET, exist_ok=True)
subprocess.run(f'gcloud storage rsync --recursive {GCS_DATA_SOURCE} {GCS_DATA_TARGET}',
shell=True, stdout=sys.stdout, stderr=sys.stderr)
## Retrieve the cluster and config information
tf_config = json.loads(os.environ['TF_CONFIG'])
if debug:
print('#### TF_CONFIG ####')
print(json.dumps(tf_config, sort_keys=True, indent=2))
JOB_IDENTIFIER = os.environ['JOB_IDENTIFIER']
GPUS_PER_NODE = int(os.environ['GPUS_PER_NODE'])
NNODES = len(tf_config['cluster']['worker']) + 1
WORLD_SIZE = NNODES * GPUS_PER_NODE
BUCKET_ROOT = '/gcs/{}'.format(os.environ['BUCKET_NAME'])
CONFIG_PATH = f'{BUCKET_ROOT}/config'
CONFIG_NAME = os.environ['NEMO_CONFIG']
## Construct options and environment variables
OPTIONS = [
f'--config-path={CONFIG_PATH}',
f'--config-name={CONFIG_NAME}',
f'+trainer.num_nodes={NNODES}',
f'+exp_manager.version={JOB_IDENTIFIER}',
f'+exp_manager.exp_dir={BUCKET_ROOT}/nemo-experiments/',
f'+model.data.data_prefix={DATA_PREFIX}'
]
MASTER_ADDR, MASTER_PORT = tf_config['cluster']['chief'][0].split(':')
if tf_config['task']['type'] == 'chief':
NODE_RANK = 0
else:
NODE_RANK = int(tf_config['task']['index']) + 1
env_all = {x: os.getenv(x) for x in os.environ}
env_all = env_all | {
'JOB_IDENTIFIER': JOB_IDENTIFIER,
'TORCH_DISTRIBUTED_TARGET': TORCH_DISTRIBUTED_TARGET,
'MASTER_ADDR': MASTER_ADDR,
'MASTER_PORT': MASTER_PORT,
'WORLD_SIZE': f'{WORLD_SIZE}',
'NNODES': f'{NNODES}',
'NODE_RANK': f'{NODE_RANK}',
'GPUS_PER_NODE': f'{GPUS_PER_NODE}',
'GLOO_SOCKET_IFNAME': 'eth0',
'NCCL_SOCKET_IFNAME': 'eth0',
'NCCL_CHECK_POINTERS': '0',
'NCCL_DYNAMIC_CHUNK_SIZE': '524288',
'NCCL_P2P_NET_CHUNKSIZE': '524288',
'NCCL_P2P_PCI_CHUNKSIZE': '524288',
'NCCL_P2P_NVL_CHUNKSIZE': '1048576',
'NCCL_CROSS_NIC': '0',
'NCCL_ALGO': 'Ring',
'NCCL_PROTO': 'Simple',
'NCCL_NET_GDR_LEVEL': 'PIX',
'NCCL_P2P_PXN_LEVEL': '0',
'NCCL_DEBUG': 'VERSION',
'NCCL_MIN_NCHANNELS': '1', # '8'
'NCCL_MAX_NCHANNELS': '8',
'NCCL_SOCKET_NTHREADS': '1',
'NCCL_NSOCKS_PERTHREAD': '4',
'OMP_NUM_THREADS': '12',
}
if debug:
print('#### Environment variables ####')
print(json.dumps(env_all, sort_keys=True, indent=2))
## Execute the real training script
running_procs = []
for LOCAL_RANK in range(0, GPUS_PER_NODE):
RANK = GPUS_PER_NODE * NODE_RANK + LOCAL_RANK
env = env_all | {
'RANK': f'{RANK}',
'LOCAL_RANK': f'{LOCAL_RANK}',
}
print(f'Starting a task with NODE_RANK: {NODE_RANK}, LOCAL_RANK: {LOCAL_RANK}')
if debug:
print(['/usr/bin/python3', TORCH_DISTRIBUTED_TARGET] + OPTIONS)
running_procs.append(
subprocess.Popen(['/usr/bin/python3', TORCH_DISTRIBUTED_TARGET] + OPTIONS,
env=env, shell=False,
stdout=sys.stdout, stderr=sys.stderr))
# Wait for subprocesses to finish
while running_procs:
if debug:
print('Waiting for {} processes to finish.'.format(len(running_procs)))
time.sleep(60)
for proc in running_procs:
if proc.poll() is not None: # Process finished
running_procs.remove(proc)
コンテナイメージ作成
次のコマンドで、コンテナイメージ作成に使用する Dockerfile を用意します。ベースイメージとして、NeMo Framework のコンテナイメージ nvcr.io/nvidia/nemo:24.03.01.framework を使用しています。
%%writefile Dockerfile
FROM nvcr.io/nvidia/nemo:24.03.01.framework
ENV PYTHONUNBUFFERED=1
WORKDIR /
# install google cloud SDK
RUN echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | \
tee -a /etc/apt/sources.list.d/google-cloud-sdk.list && \
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | \
gpg --dearmor -o /usr/share/keyrings/cloud.google.gpg && \
apt-get update -y && \
apt-get install -y google-cloud-sdk
COPY trainer /trainer
ENTRYPOINT ["python", "-m", "trainer.task"]
次のコマンドで、Cloud Build を使ってコンテナイメージをビルドします。
REPO_NAME = 'container-image-repo'
IMAGE_URI = f'us-central1-docker.pkg.dev/{PROJECT_ID}/{REPO_NAME}/gpt-small-pretraining:latest'
!gcloud builds submit . --tag {IMAGE_URI}
ベースイメージのサイズが大きいので、イメージの Pull / Push に少し時間がかかります[4]。変数 IMAGE_URI に保存した値は、この後、ビルドしたイメージを指定する際の URI として使用します。
トレーニングジョブの実行
次のコマンドで、Custom training にジョブをリクエストするための設定ファイル work_dir/custom_training.yaml を用意します。
%%writefile work_dir/custom_training.yaml
workerPoolSpecs:
- machineSpec:
machineType: n1-highmem-4
acceleratorType: NVIDIA_TESLA_T4
acceleratorCount: 2
diskSpec:
bootDiskSizeGb: 100
replicaCount: 1
containerSpec:
imageUri: "__IMAGE_URI__"
env:
- name: JOB_IDENTIFIER
value: "__JOB_IDENTIFIER__"
- name: GPUS_PER_NODE
value: "2"
- name: CACHING
value: "True"
- name: BUCKET_NAME
value: "__BUCKET__"
- name: NEMO_CONFIG
value: "gpt-small.yaml"
- name: DEBUG
value: "True"
- machineSpec:
machineType: n1-highmem-4
acceleratorType: NVIDIA_TESLA_T4
acceleratorCount: 2
diskSpec:
bootDiskSizeGb: 100
replicaCount: 3
containerSpec:
imageUri: "__IMAGE_URI__"
env:
- name: JOB_IDENTIFIER
value: "__JOB_IDENTIFIER__"
- name: GPUS_PER_NODE
value: "2"
- name: CACHING
value: "True"
- name: BUCKET_NAME
value: "__BUCKET__"
- name: NEMO_CONFIG
value: "gpt-small.yaml"
- name: DEBUG
value: "True"
設定ファイル内の項目は、次になります。
| 要素 | 説明 |
|---|---|
| machineSpec.machineType | ノードのマシンタイプ |
| machineSpec.acceleratorType | ノードに接続する GPU の種類 |
| machineSpec.acceleratorCount | 1 ノードに接続する GPU の個数 |
| diskSpec.bootDiskSizeGb | ローカルディスク(デフォルトでは SSD)の容量 [GB] |
| replicaCount | 起動するノード数 |
| containerSpec.imageUri | ノードにデプロイするコンテナイメージ |
| containerSpec.env | コンテナに受け渡す環境変数 |
実際の設定ファイルを見ると machineSpec のセクションが2つありますが、1つ目はマスターノード、2つ目はワーカーノードの設定になります。replicaCount は、それぞれのノードの個数で、マスターノードは必ず 1 を指定します。ワーカーノードは任意の数が指定できます。
この例では、マスターノード 1、ワーカーノード 3 の 4 ノード構成になります。マスターノードも学習処理に参加するので、4 ノードで並列学習処理が行われます。GPU については、各ノードに NVIDIA Tesla T4 を 2 枚ずつアサインしています。マシンタイプによって、接続可能な GPU の種類や枚数が異なるので注意してください。
containerSpec.imageUri には、先ほど変数 IMAGE_URI に保存した URI を指定します。この後の手順で、設定ファイル内の __IMAGE_URI__ の部分を書き換えます。
containerSpec.env は、コンテナに受け渡す環境変数の設定です。今回は、先ほど作成した学習用コード trainer/task.py が必要とする、次の情報を受け渡します。
| 環境変数 | 説明 |
|---|---|
| JOB_IDENTIFIER | ジョブごとのユニークな ID |
| GPUS_PER_NODE | ノードあたりの GPU の数 |
| CACHING | 学習データをローカルディスクに事前コピーするか [True/False] |
| BUCKET_NAME | 共有ストレージのバケット名 |
| NEMO_CONFIG | Experiment Mangaer の設定ファイル名 |
| DEBUG | デバッグフラグ [True/False] |
特に GPUS_PER_NODE には、machineSpec.acceleratorCount と同じ値を指定します。また、学習結果を保存するチェックポイントは、JOB_IDENTIFIER で識別されます。一度終了した学習処理を再開したい場合は、同じ JOB_IDENTIFIER を指定します。今回は、実行ごとに新しく学習を開始するために、JOB_IDENTIFIER にタイムスタンプを付け加えます。
次のコマンドで、JOB_IDENTIFIER を生成して、設定ファイル内の __JOB_IDENTIFIER__ の部分を書き換えます。あわせて、__IMAGE_URI__ と __BUCKET__ の部分も書き換えておきます。
import datetime, time
ts = datetime.datetime.fromtimestamp(time.time()).strftime("%Y%m%d%H%M%S")
JOB_IDENTIFIER = 'gpt-small-' + ts
BUCKET_NAME = BUCKET.replace('gs://', '')
!sed -i 's#__BUCKET__#{BUCKET_NAME}#g' work_dir/custom_training.yaml
!sed -i 's#__IMAGE_URI__#{IMAGE_URI}#g' work_dir/custom_training.yaml
!sed -i 's#__JOB_IDENTIFIER__#{JOB_IDENTIFIER}#g' work_dir/custom_training.yaml
print(f"JOB_IDENTIFIER = '{JOB_IDENTIFIER}'")
生成された JOB_IDENTIFIER の値が表示されるので、必要に応じてメモしておいてください。
これですべての準備ができました。次のコマンドで、Custom training のジョブを投入します。--region オプションで、ジョブを実行するリージョンを指定します。
!gcloud ai custom-jobs create \
--region=us-central1 \
--display-name={JOB_IDENTIFIER} \
--config=work_dir/custom_training.yaml
クラウドコンソールのナビゲーションメニューから「Vertex AI」→「トレーニング」を選択して、「カスタムジョブ」のタブをクリックすると、投入したジョブが確認できます。ジョブの名前が先ほど確認した JOB_IDENTIFIER に一致しています。ステータスが「保留」になっていますが、数分待つとリソースが割り当てられてジョブの実行が開始します。
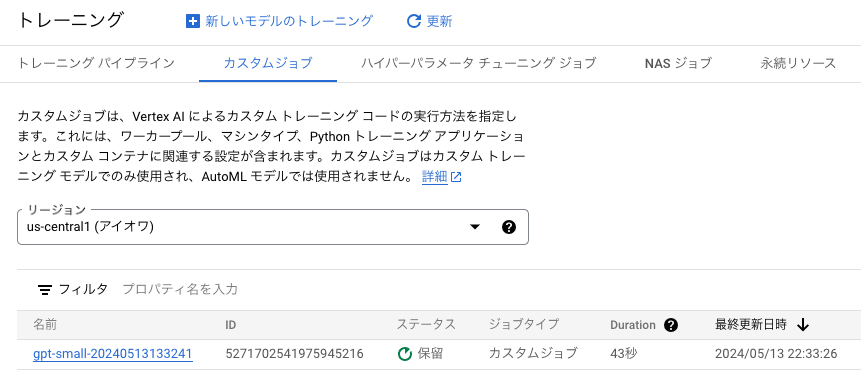
Custom training のジョブ一覧画面
ジョブの名前のリンクをクリックすると、次のようにジョブの詳細が確認できます。この画面にある「ログを表示」のリンクから、コンテナが出力するログメッセージが確認できます[5]。

Custom training ジョブの詳細情報
また、画面を下にスクロールすると、CPU、GPU、ネットワークなどのリソース使用状況のグラフも確認できます。
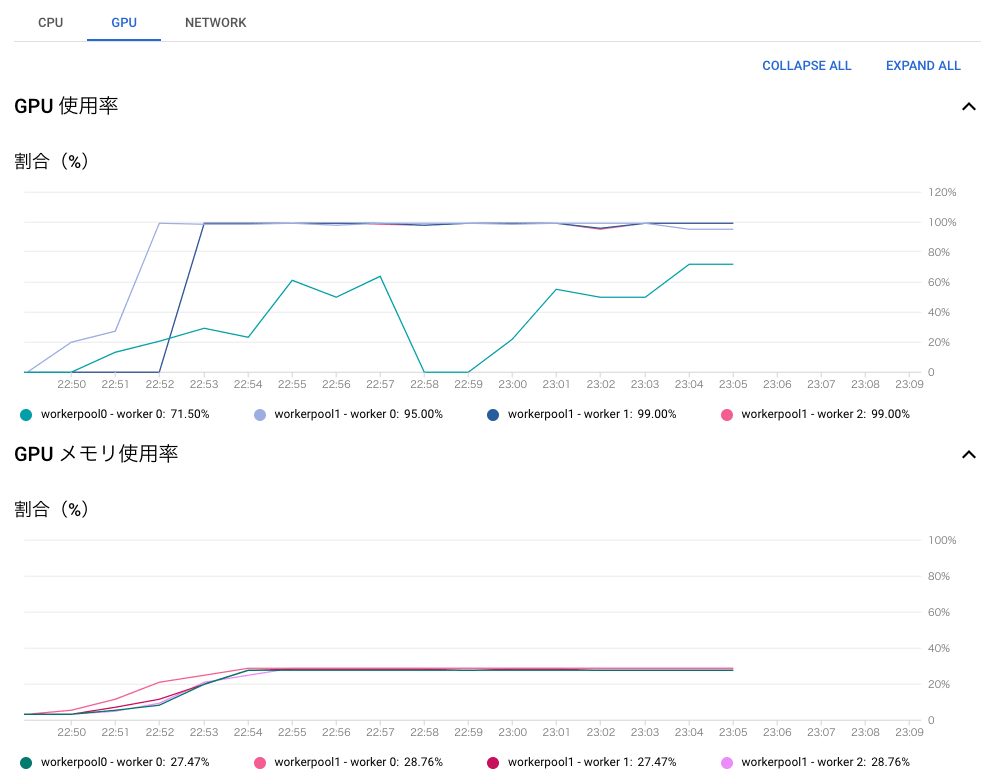
リソース使用状況のグラフ
なお、指定のリージョンで利用可能な GPU リソースが不足していると、ジョブの実行が開始するまで長く待たされる場合があります。永続リソースを利用すると、Custom training で使用する GPU リソースを事前に確保することができます。
保留中、もしくは、実行中のジョブを途中でキャンセルする際は、ジョブ一覧画面で、該当ジョブの右にあるプルダウンメニューから「カスタムジョブをキャンセル」を選択します。
ジョブの実行が開始すると、20 分程度で学習処理が完了して、ジョブのステータスが「完了」になります[6]。GCS バケット gs://[Project ID]-training/ 内のフォルダー nemo-experiments/megatron_gpt/[JOB_IDENTIFIER] 以下に各種のログファイルとチェックポイントが保存されており、この中には、TensorBoard で学習状況を確認するためのログファイルも含まれています。
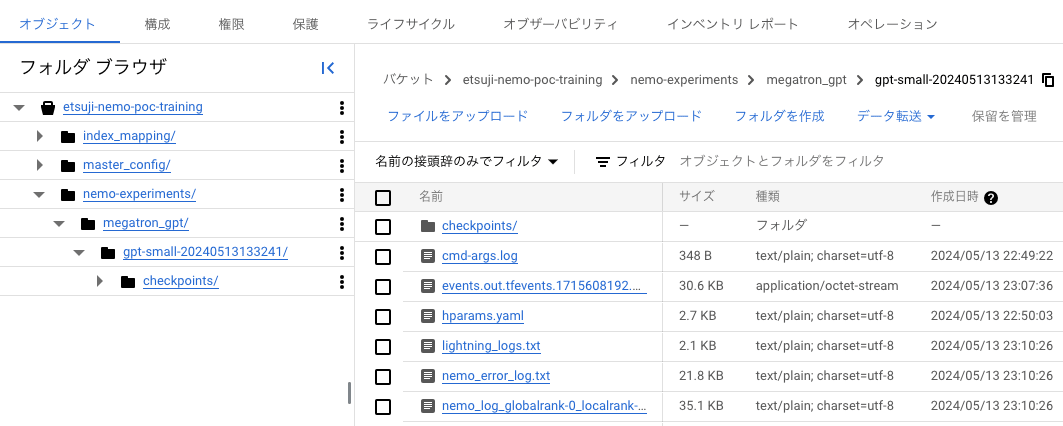
GCS バケットに出力されたログファイル
TensorBoard による学習状況の確認
Vertex AI TensorBoard を利用して、先ほどのジョブの実行結果を TensorBoard で確認します。
次のコマンドで、新しい TensorBoard インスタンスを起動します。
from google.cloud import aiplatform
tensorboard = aiplatform.Tensorboard.create(
display_name=JOB_IDENTIFIER,
project=PROJECT_ID,
location='us-central1'
)
TB_RESOURCE_NAME = str(tensorboard).split('resource name: ')[1]
print(f"TB_RESOURCE_NAME = '{TB_RESOURCE_NAME}'")
TB_RESOURCE_NAME の値が表示されるので、必要に応じてメモしておきます。この値は、TensorBoard インスタンスを削除する際に必要になります。
次のコマンドで、ログファイルを TensorBoard インスタンスにアップロードします。
!tb-gcp-uploader --tensorboard_resource_name {TB_RESOURCE_NAME} \
--logdir={BUCKET}/nemo-experiments/megatron_gpt/{JOB_IDENTIFIER} \
--experiment_name={JOB_IDENTIFIER} \
--one_shot=True
次のようなメッセージが表示されるので、指定された URL をブラウザーで開くと、TensorBoard の画面が表示されます。
View your Tensorboard at https://us-central1.tensorboard.googleusercontent.com...
次のように、train_loss、val_loss が減少していることがわかります。
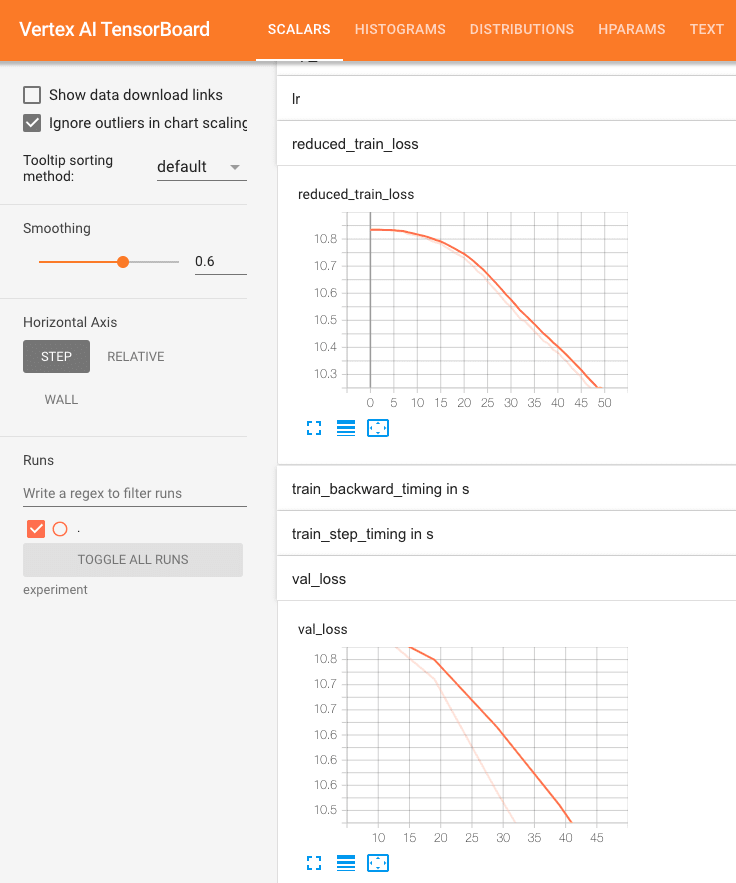
TensorBoard による学習状況の確認
確認が終わったら、次のコマンドで TensorBoard インスタンスを削除しておきます。
tensorboard = aiplatform.Tensorboard(
tensorboard_name=TB_RESOURCE_NAME,
project=PROJECT_ID,
location='us-central1'
)
tensorboard.delete()
起動中の TensorBoard インスタンスは、ナビゲーションメニューから「Vertex AI」→「テスト」を選択して、「TENSORBOARD インスタンス」のタブからも確認できます。この画面から TensorBoard インスタンスを削除することもできます。
学習用スクリプトの内容
Custom training のジョブからコンテナが起動すると、学習用スクリプト trainer/task.py が実行されます。これは、NeMo Framework が提供するスクリプトをバックグラウンドで起動します。
ここでは、具体的な処理内容を順番に説明します。
学習処理を行うスクリプトと学習データの指定
次の部分で、起動するスクリプトと学習に使うデータを指定します。
## Modify here to change the training script and training data
BASE_DIR = '/opt/NeMo/examples/nlp/language_modeling'
TORCH_DISTRIBUTED_TARGET = f'{BASE_DIR}/megatron_gpt_pretraining.py'
GCS_DATA_SOURCE = 'gs://nemo-megatron-demo/training-data/tokenized/bpe2gpt/wikipedia/'
DATA_FILE_PREFIX = 'wikipedia-tokenized-for-gpt2'
####
学習データは GCS の公開バケットにあるので、コンテナ内からは /gcs/[Bucket Name] でアクセスできますが、環境変数 CACHING のオプション指定により、事前にローカルディスクにコピーするように実装しています。
## Cache the training data
DATA_PREFIX = '[1.0,{}/{}]'.format(GCS_DATA_SOURCE.replace('gs://', '/gcs/'), DATA_FILE_PREFIX)
if strtobool(os.environ.get('CACHING', 'False')):
GCS_DATA_TARGET = '/ssd/.cache/'
DATA_PREFIX = f'[1.0,/ssd/.cache/{DATA_FILE_PREFIX}]'
print(f'Caching training data from {GCS_DATA_SOURCE} to {GCS_DATA_TARGET}')
os.makedirs(GCS_DATA_TARGET, exist_ok=True)
subprocess.run(f'gcloud storage rsync --recursive {GCS_DATA_SOURCE} {GCS_DATA_TARGET}',
shell=True, stdout=sys.stdout, stderr=sys.stderr)
クラスター構成の取得
NeMo Framework のスクリプトは、分散学習に PyTorch Lightning を使用しており、次の環境変数でクラスターの構成を指定します。
| 環境変数 | 説明 |
|---|---|
| MASTER_ADDR | マスターノードと通信可能なホスト名、もしくは、IP アドレス |
| MASTER_PORT | マスターノードとの通信に使用するポート番号 |
| WORLD_SIZE | クラスター全体での GPU の総数 |
| NODE_RANK | 各ノードの ID 番号(マスターは 0) |
Custom training で起動したコンテナでは、環境変数 TF_CONFIG から、クラスター全体の構成と、その中で自分がどのノードにあたるかがわかります。これを利用して、上記の環境変数の内容を用意します。
今回の構成では、TF_CONFIG は次のような JSON 文字列になります。
{
'cluster': {
'chief': ['cmle-training-workerpool0-c4441ce95b-0:2222']
'worker': ['cmle-training-workerpool1-c4441ce95b-0:2222',
'cmle-training-workerpool1-c4441ce95b-1:2222',
'cmle-training-workerpool1-c4441ce95b-2:2222'],
},
'environment': 'cloud',
'task': {'type': 'worker', 'index': 0},
'job': '{"python_module":"","package_uris":[],"job_args":[]}'}"
}
cluster 要素を見ると、マスター(chief)が 1 ノード、ワーカー(worker)が 3 ノードあることがわかります。task 要素を見ると、この例では、自分は 0 番目のワーカーだとわかります。これをパースしたものを変数 tf_config に保存して利用します。
次は、TF_CONFIG、および、その他の環境変数から、クラスターの構成情報と設定ファイルに関する情報を取得しています。
## Retrieve the cluster and config information
tf_config = json.loads(os.environ['TF_CONFIG'])
if debug:
print('#### TF_CONFIG ####')
print(json.dumps(tf_config, sort_keys=True, indent=2))
JOB_IDENTIFIER = os.environ['JOB_IDENTIFIER']
GPUS_PER_NODE = int(os.environ['GPUS_PER_NODE'])
NNODES = len(tf_config['cluster']['worker']) + 1
WORLD_SIZE = NNODES * GPUS_PER_NODE
BUCKET_ROOT = '/gcs/{}'.format(os.environ['BUCKET_NAME'])
CONFIG_PATH = f'{BUCKET_ROOT}/config'
CONFIG_NAME = os.environ['NEMO_CONFIG']
たとえば、マスターは必ず 1 ノードという前提があるので、次で、全体のノード数 NNODES がわかります。
NNODES = len(tf_config['cluster']['worker']) + 1
これに、環境変数 GPUS_PER_NODE から取得した 1 ノードあたりの GPU 数を掛ければ、GPU の総数を表す WORLD_SIZE が決まります。
WORLD_SIZE = NNODES * GPUS_PER_NODE
スクリプトに渡すオプションと環境変数の構成
次の部分は、NeMo Framework のスクリプト実行時に指定するオプションを構成しています。
## Construct options and environment variables
OPTIONS = [
f'--config-path={CONFIG_PATH}',
f'--config-name={CONFIG_NAME}',
f'+trainer.num_nodes={NNODES}',
f'+exp_manager.version={JOB_IDENTIFIER}',
f'+exp_manager.exp_dir={BUCKET_ROOT}/nemo-experiments/',
f'+model.data.data_prefix={DATA_PREFIX}'
]
また、PyTorch Lightning が必要とする前述の情報や NCCL の設定など、いくつかのオプションを環境変数で指定する必要があります。次の部分は、既存の環境変数の内容に加えて、追加で必要な環境変数の内容をすべてまとめてディクショナリ env_all に保存しています[7]。
MASTER_ADDR, MASTER_PORT = tf_config['cluster']['chief'][0].split(':')
if tf_config['task']['type'] == 'chief':
NODE_RANK = 0
else:
NODE_RANK = int(tf_config['task']['index']) + 1
env_all = {x: os.getenv(x) for x in os.environ}
env_all = env_all | {
'JOB_IDENTIFIER': JOB_IDENTIFIER,
'TORCH_DISTRIBUTED_TARGET': TORCH_DISTRIBUTED_TARGET,
'MASTER_ADDR': MASTER_ADDR,
'MASTER_PORT': MASTER_PORT,
'WORLD_SIZE': f'{WORLD_SIZE}',
'NNODES': f'{NNODES}',
'NODE_RANK': f'{NODE_RANK}',
'GPUS_PER_NODE': f'{GPUS_PER_NODE}',
'GLOO_SOCKET_IFNAME': 'eth0',
'NCCL_SOCKET_IFNAME': 'eth0',
'NCCL_CHECK_POINTERS': '0',
'NCCL_DYNAMIC_CHUNK_SIZE': '524288',
'NCCL_P2P_NET_CHUNKSIZE': '524288',
'NCCL_P2P_PCI_CHUNKSIZE': '524288',
'NCCL_P2P_NVL_CHUNKSIZE': '1048576',
'NCCL_CROSS_NIC': '0',
'NCCL_ALGO': 'Ring',
'NCCL_PROTO': 'Simple',
'NCCL_NET_GDR_LEVEL': 'PIX',
'NCCL_P2P_PXN_LEVEL': '0',
'NCCL_DEBUG': 'VERSION',
'NCCL_MIN_NCHANNELS': '1', # '8'
'NCCL_MAX_NCHANNELS': '8',
'NCCL_SOCKET_NTHREADS': '1',
'NCCL_NSOCKS_PERTHREAD': '4',
'OMP_NUM_THREADS': '12',
}
if debug:
print('#### Environment variables ####')
print(json.dumps(env_all, sort_keys=True, indent=2))
前述の tf_config の中に、各ノードのホスト名と利用可能なポート番号が含まれているので、マスターノードのホスト名(IP アドレス)とポート番号を表す MASTER_ADDR と MASTER_PORT は、ここから取得しています。各ノードの ID 番号を表す NODE_RANK も同様に、tf_config の情報を利用して設定しています。
NeMo Framework のスクリプトを実行
いよいよ、NeMo Framework のスクリプトを実行します。各ノードで、ノード上の GPU の個数分のスクリプトを並列実行します。この際、個々のスクリプトを判別するために、次の環境変数を設定します。
| 環境変数 | 説明 |
|---|---|
| LOCAL_RANK | ノード内での通し番号 |
| RANK | クラスター全体での通し番号 |
具体的なコードは次になります。TORCH_DISTRIBUTED_TARGET で指定されたスクリプトを subprocess.Popen() でバックグラウンド実行しており、ディクショナリ env に用意した内容をオプション env=env で環境変数に設定しています。
## Execute the real training script
running_procs = []
for LOCAL_RANK in range(0, GPUS_PER_NODE):
RANK = GPUS_PER_NODE * NODE_RANK + LOCAL_RANK
env = env_all | {
'RANK': f'{RANK}',
'LOCAL_RANK': f'{LOCAL_RANK}',
}
print(f'Starting a task with NODE_RANK: {NODE_RANK}, LOCAL_RANK: {LOCAL_RANK}')
if debug:
print(['/usr/bin/python3', TORCH_DISTRIBUTED_TARGET] + OPTIONS)
running_procs.append(
subprocess.Popen(['/usr/bin/python3', TORCH_DISTRIBUTED_TARGET] + OPTIONS,
env=env, shell=False,
stdout=sys.stdout, stderr=sys.stderr))
あとは、バックグラウンドで起動したスクリプトがすべて終了するのを待ちます。
# Wait for subprocesses to finish
while running_procs:
if debug:
print('Waiting for {} processes to finish.'.format(len(running_procs)))
time.sleep(60)
for proc in running_procs:
if proc.poll() is not None: # Process finished
running_procs.remove(proc)
まとめ
この記事では、Vertex AI Custom training の環境で、NeMo Framework のコードを使って LLM の分散学習処理を実行する手順を紹介しました。一例として、Megatron GPT の事前学習 megatron_gpt_pretraining.py を実行しましたが、NeMo Framework ではさまざまな基盤モデルの学習スクリプトが提供されています。この手順を参考にして、その他の基盤モデルの分散学習も体験してください。
-
[Bucket Name]はストレージパスgs://...から先頭のgs://部分を除いたものになります。 ↩︎ -
本文内の
[Project ID]の部分は、実際に使用するプロジェクトのプロジェクト ID に読み替えてください。 ↩︎ -
Vertex AI TensorBoard のインスタンスを操作するために TensorFlow のモジュールが必要になります。 ↩︎
-
初回のイメージ作成時は、ベースイメージのレイヤーをすべてリポジトリに Push するので、特に時間がかかります。少し気長にお待ちください。 ↩︎
-
モデルの構造などに関して警告が出力されますが、今回は「お試し」なので気にしないことにします。 ↩︎
-
設定ファイル
gpt-small.yamlでmax_steps: 50を指定しているので、50 回分のバッチを処理したところで終了します。 ↩︎ -
環境変数に指定する内容は、冒頭で紹介したチュートリアルでの設定 nemo-example.yaml を参考にしています。今回の環境では不要な設定もあるかもしれません。 ↩︎

Discussion