はじめに
いよいよ年の瀬ですが、2025年は皆さんにとってどのような年でしたでしょうか。LLM、生成 AI という近年の技術革新の中、今年はビジネスへの実装を意識した議論が多かったように個人的には思います。
そこで今一度、評価 について概要をまとめ、皆様の来年の取り組みの一助となればと思っています。
これまで、【生成 AI 時代の LLMOps】のシリーズでプロンプト管理編、モデルマイグレーション編を扱ってきました。今回は LLMOps でも重要な要素、評価 について取り扱います。
評価とは
まずみなさんは評価という言葉をどのような文脈で目にしますか。映像作品の評価、商品の評価、人事評価など、日常生活やビジネスの場面でも目にするかと思います。いわゆる 評価 という言葉には価値を決めるという意味合いがありますが、機械学習における価値とは何でしょうか。
機械学習において学習されたモデルの主な役割は 推論 と捉えることができるでしょう。過去のデータ、パターンから未来の事象を予測することです。気象情報から天候を予測するモデル、交通量から到着時間を予測するモデル、長い文章から要約文を生成するモデルなど、様々なタスクにおいてモデルは推論(予測や生成)を行っています。この役割に対する価値とは、推論結果が期待通りだったか、とも言い換えられるはずです。
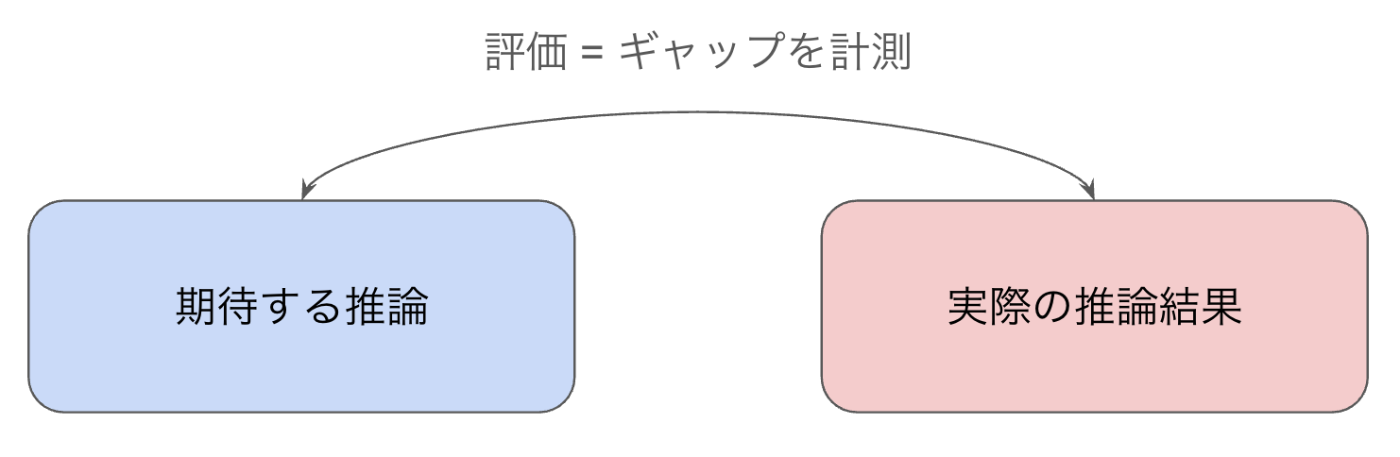
図1: 推論の評価
評価の種類
より厳密な定義や具体例を出す前に、生成 AI や LLMOps の文脈で考慮すべき評価の全体像を整理したいと思います。そもそも機械学習に限らず、ソフトウェアの世界ではシステムやアプリケーションについても評価という考え方があります。そして、最近よく目にするのが エージェントの評価 です。エージェントの評価がどのような観点からその価値を決めているかは後述しますが、エージェントの評価と、従来からある機械学習のモデルの評価とは大きく性質が異なります。まずはそれぞれの特徴を説明します。
モデルの評価
機械学習のモデルにおいて、期待する推論(正解データ、教師データ、参照データを指しています)と実際の推論結果の差を定量化することが評価です。
実は機械学習の中でも、予測 AI (Predictive AI) と生成 AI (Generative AI) とで評価のアプローチが少し異なります。予測 AI とは、スパムメールの検知などがその例ですが、比較的歴史の長いカテゴリです。回帰モデル(連続値の予測)や分類モデル(ラベル、離散値の予測)などに大別され、正解の数値やラベルがあるため、数値として扱い安いカテゴリです。生成 AI や LLMOps の文脈からは少し離れてしまうので今回は割愛しますが、興味がある方は決定係数R2、MSE、正解率、適合率、再現率、AUC などの言葉を検索されると有用な情報が見つかると思います。
LLMOps という文脈においては、主に生成 AI の評価方法が重要になります。生成 AI の評価の難しさは、出力の正解が一意に決めることが難しいという点にあるかと思います。まず、生成 AI の評価において、ルーブリック ベース(モデルベース)の指標と、計算ベースの指標で区別されることがあります。
ルーブリック ベースとは、評価をするための評価モデルを使用することで、評価用データの準備コストを減らすことが可能です。ルーブリックという言葉が評価基準という意味合いですが、複数の観点から生成結果に評点を付けるようなものです。流暢な言葉使いをしているか、要約タスクで指定の文字数が守られているか、などがその一例です。言語モデルを開発している企業・団体から提供されている評価モデルもありますので、LLMOps の開発や実装をより円滑に進めることができます。例えば Google Cloud の Vertex AI からは、ルーブリック ベースの指標として評価機能が提供されています。評価の指標をある程度自動的に定義することもできますし、基準を与えることである程度コントロールすることも可能です。評価に特化したモデルを使うと言っても、プラットフォームやソフトウェア毎に特色があり、Vertex AI では評価の方針をユーザ自身が記述できる余地を残しているため、より広範なタスクに柔軟に対応できるよう設計されています。(また別の観点でポイントワイズ、ペアワイズなどの分類もできますが、今回は割愛します。)
もう一つの計算ベースの指標とは、生成データと参照データを比較する際に、スコアの計算方法が決定論的に定義されています。例えばテキスト生成において、"This is a pen." という英文を日本語に訳す機械翻訳モデルを例に取ると、「これはペンだ」や「こちらはペンになります」などの出力のばらつきが想像できます。しかし、「これは筆です」や「ここはペンシルベニア州です」などの文と比べると、前述の出力の方が期待した推論のはずです。そこで、「これはペンだ」を正解(参照データ)とした時に、「こちらはペンになります」「これはペンです」がどれだけ正解と離れているかを数値化する必要があります。これは、今日の生成 AI や深層学習などの技術より歴史が長く、言語処理の分野などで提案されてきたアプローチです。もちろん、Vertex AI にも標準的に実装されていますので、計算ベースの指標 の候補から選択するだけで指標が計算できます。
- Recall-Oriented Understudy for Gisting Evaluation (
rouge_l、rouge_1) - Bilingual Evaluation Understudy (
bleu) - 完全一致 (
exact_match)
完全一致についてはその名の通り、生成データと参照データが完全に一致することを正とする指標ですが、rouge や bleu はテキスト全体の中で共通する表現がどの程度含まれているかを評価する指標です。'This is a pen.' の日本語訳として、「ペン」が含まれていると望ましいですし、「筆」は加点にならない、というイメージです。LLM や生成 AI に関する様々な論文で、これらを指標は度々使われてきました。1つの入力(プロンプト)に対して1つの参照データを用意するというのは若干恣意的な行為にも感じられますが、データセットの多様性を高めることで緩和できるはずです。
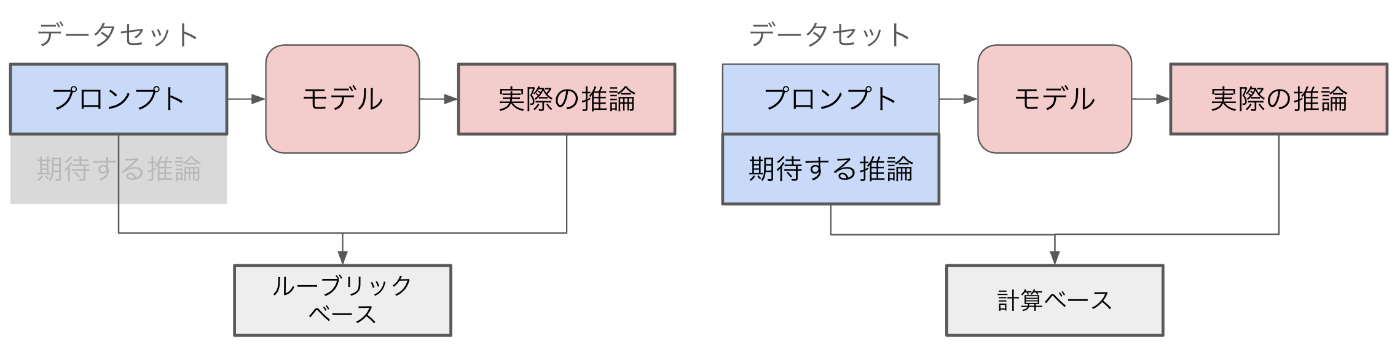
図2: ルーブリック ベースと計算 ベースのモデル評価
ルーブリックベースと計算ベースの評価指標を簡単に比較すると図2のようになります。(もちろん全ての手法をこの図で網羅しているわけではありませんので、簡単のために代表的な手法について特徴的な側面を比較しています。)
エージェントの評価
今日の生成 AI 分野におけるエージェントは、語源通り代理人として様々なシステムやサブエージェントと連携し、自然言語のインターフェースでユーザと繋がることイメージを持たれていると思います。機械学習のモデルとは異なり、他のシステムに依存する応答がしばしば含まれるため、依存している他のシステムの評価と、エージェントそれ自体の評価は区別する必要があります。
例えば「明日の天気は?」という質問をエージェントに問い合わせて、「明日は晴れです」と応答があったとします。
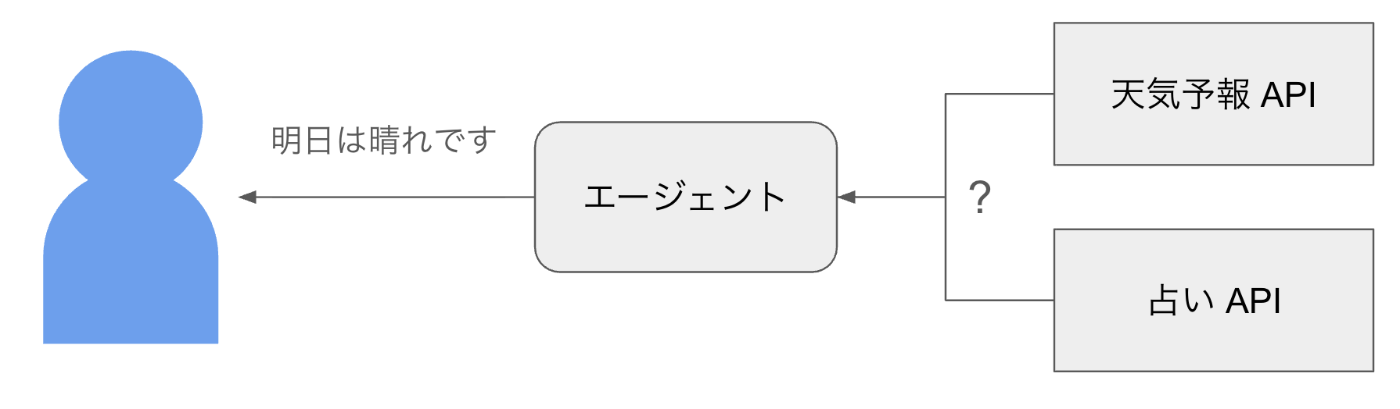
図3: エージェントの振る舞い
この際、ユーザはエージェントが裏でどのように処理したのかは認識しておらず、実は天気予報 API ではなく、占い API に問い合わせて「明日は晴れです」と出力した可能性もあります。この場合、エージェント開発者が期待する応答(参照データ)が「明日は晴れです」だったとしても、エージェントが適切に振る舞ったとは言えないと思います。出力されたテキストが一致していても、エージェントの設計シナリオに、天気に関する問い合わせは天気予報 API をコールするという想定が含まれていれば、今回の挙動は精度が低いとしたいはずです。
つまりエージェントの評価とは、期待した通りのプロセスでツールを使用したかという観点で計測することができます。もちろんエージェントの最終的な出力自体も評価可能ですが、まずはエージェントの評価に着目して説明します。前述の通り、エージェントの振る舞いは、他のツールをどのような順序で、どのようなパラメータで使用したのか、という形に抽象化できます。例えば Vertex AI が提供する Agent Evaluation では、この一連のプロセスを 軌跡 として、いくつかの評価指標が用意されています。データセットの例 から、example 2 のデータを抜粋しました。
reference_trajectory = [
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
このデータでは、predicted_trajectory が実際に観測された振る舞い(ログのようなもの)で、reference_trajectory が期待する振る舞い(参照データ)として評価データを与えています。厳密性やセキュリティの観点は一度考えずに絵にすると、以下のようなスマートホームを想像してください。
ユーザから「エアコンをつけて」という命令を受け取ったエージェントが、ユーザの好みの取得し、その室温に設定するという一連の流れです。

図4: エージェントのツールの軌跡
この一連の流れを考えると、get_user_preferences と set_temperature の順序は入れ替えない方が良さそうです。また、update_user_preferences という好みの室温を書き換えるコマンドも呼ぶべきではないでしょう。
このように、ツールの軌跡を考えたときに、完全一致を正とするか、順序だけあっていることを正とするか、順不同だが全て実行して欲しいか、などの基準がシナリオによって変化するはずです。Vertex AI の Agent Evaluation においてはいくつかの軌跡評価が用意されています。
- 完全一致
- 順序一致
- 順序を問わない一致
- 適合率
- 再現率
- 単一ツールの使用
例えば SNS で使うアイコンを作るというタスクであれば、好みの背景色を取得する、好みのメガネの形を取得する、好みの髪型を取得する、というツールは入れ替わりを許容できそうですし、逆に銀行システムの取引を代行する場合には、順序も正しく、余計なツールの使用も避けたいはずです。
用途に応じて適切な評価基準を選ぶことができれば、エージェントの実装、評価がより円滑に、より正確に進めることができるようになります。
なぜ評価が重要なのか
ここまで、評価とは何か、どのようなアプローチがあるのか概説してきました。評価が重要ということは直感的には受け入れられるかと思いますが、生成 AI アプリケーションの手軽さから、評価に思い至らないケースも多々あると思います。本節では、改めてなぜ評価が重要なのか考えてみようと思います。
IT 部門で社内の DX 推進を担当することを想像してみてください。社内に生成 AI を組み込んだチャットボット アプリケーションを導入し、様々な質疑応答、メール下書き、情報検索などの自動化を実現しました。運用が始まり数週間後、アプリケーションのユーザ体験に関するアンケートを実施したところ、経理部からは「メールの下書きが捗る」と非常に高い評価が得られましたが、営業部は反対に「メールの下書きには使えない」というネガティブな回答でした。
ヒアリングをすると、以下のような期待値のズレが見えてきました。
表: プロンプト「佐藤さんに納品書が届いていない件でメールを書いてください。」への期待値
| 経理部の期待する出力 | 営業部の期待する出力 |
|---|---|
| 〇〇部 佐藤さん お疲れ様です。〇〇です。 先日お話ししていた納品書がまだ届いていないようです。 至急、経理部までお送りください。 |
株式会社〇〇 佐藤様 お世話になっております。〇〇の〇〇でございます。 先日はカクカクシカジカありがとうございました。 お問い合わせいただいておりました納品書の件ですが、弊社の手違いでお送りできておりませんでした。PDF を添付しておりますので、ご確認いただけますでしょうか。 |
社内のユーザが生成 AI に慣れていなければ、このようにプロンプトが簡素化し、意図した結果を出力させられないパターンもあるでしょう。納品書が届いていない件の当事者が誰なのか、宛先が同僚なのか取引先なのか、など、使い方のズレがあります。本来はプロンプトの中にこのようなコンテキストを埋め込むことで、より期待する推論結果に近い出力が得られるはずですが、ここで議論したいのはツールの使い方ではありません。アプリケーションの開発・提供者が、誰に対してどのようなユースケースを想定し、どのように評価するか、ということを事前に決めておくことで回避できたかもしれないということです。
この例では、経理部と営業部ではそもそも違う用途でアプリケーションを使っており、期待する生成結果も微妙に異なります。例えば所属する部署毎にプロンプトのシステム インストラクションを切り替えて、期待する振る舞いに強制することもできるでしょう。しかし、もし長期的にアプリケーションを運用し、LLMOps の実装に取り組むのであれば、まずは評価データを用意することが重要です。
部署毎にアンケートの結果が異なるのであれば、部署毎に評価用データを用意することが理想です。その評価用データセットに対して、プロンプトを改善すべきか、ベースモデルを改善すべきか、あるいは RAG のように外部データソースと連携すべきか、など評価スコアが改善する方策を実験によって明らかにします。様々な試行錯誤による設定の変更が、良い影響を与えたのか、悪い影響を与えたのか、それを定量的に示してくれる評価がなければ、再現性のない実験になってしまいます。最悪のケースでは膨大な時間や計算リソースを費やして、何も得られなかった、という事態にもなりかねません。
評価のデータと評価方法を事前に決めておくことで、方位磁針をもって航海ができるのです。北極点を目指すためには北に進む必要がありますが、方位を知る手段がなければ前途多難です。生成 AI において絶対的かつ普遍的な正解はなく、状況によって目指すものが異なります。自分がどこを目指すのかを知っておくことが重要であり、それを実現するために評価というプロセスが欠かせないのです。
技術的な評価からビジネス的な評価へ
ここまで技術的な側面から解説してきましたが、最後にビジネス的な観点から評価について説明したいと思います。「精度のスコア(rougeなど)はどこまで高めるべきか?」と経営者に問われると、皆さんはどのような思考プロセスを辿るでしょう。
新しい手法が論文で発表される際、ベンチマークとして様々な精度指標がまとめられているため、ビジネスの開発現場でもしばしば参考にされると思います。しかし、他社の達成したベンチマークをそのまま目標にするのは、ビジネス上は効率的な戦略とは言えません。精度指標がどこまであれば要件を満たすのか、ということを事前に実験することが非常に重要です。
例えば長い商品説明を入力に、広告や記事のヘッドラインを生成させるタスクを考えてみます。ライターの熟練度にばらつきがあり、新人のかく文章のサポートを目的としています。このタスクにおいて、ゴールは生成 AI が熟練のライターと遜色ない品質の文章を生成することです。実際にプロの書いた文章を参照データとして rouge を計算してみると、0.7 や 0.8 といった 0 から 1 の範囲の数値が出力されます。
ここまでは技術的な評価を実行しただけですが、この数値をビジネスの評価とどのように紐づけるかが本節の肝になります。一例をご紹介すると、スコアが 0.4~0.6, 0.6~0.8, 0.8~1.0 の生成データを集め、プロのライター数名に「新人の文章をレビューするとして、手直しが不要なものを選んでください」とそれぞれのデータを評価してもらいます。このプロセスによって、技術的な評価指標と、ビジネスの現場での評価に関連性があるのかを測る事ができます。0.8-1.0のデータセットは95%レビュー不要だった、という結果が得られれば、0.8 を目指すことが妥当と言えます。三段論法のようにも見えますが、評価のプロセスも機械的に計算できるものと、人間が介在しないと評価できないものをどう関連づけられるかが鍵となってきます。ここまで論理的に実験を実施していれば、最初の経営者の質問にも躊躇う事なく答えられるはずです。このプロセスには唯一の正解があるわけではないので、皆さんの現場での評価のアイディアとなればと思います。
終わりに
今回はコードの使用を控え、まずは 評価 自体の技術体系やそれぞれの役割について解説しました。特にモデルの評価とエージェントの評価は混同されがちですので、Vertex AI の機能を例に、それぞれの性質について触れました。これから生成 AI によって価値を生み出す皆様のヒントになれば幸いです。

Discussion