tl;dr
- Firestore は NoSQL のサーバーレスデータベース。
- 新規開発ならネイティブモードを選択する。
- ドキュメント指向のデータモデルを採用していて、コレクション、ドキュメントの階層構造で構成される。
- サブコレクションを使うと効率よくクエリができる。
- 直近のアップデートで、より使いやすくなった。
はじめに
みなさん、こんにちは。Google Cloud パートナーエンジニアの Sho です。
この記事は Google Cloud Japan Advent Calendar 2022(今から始める Google Cloud ) の 12/11 の記事です。本記事では、Firestore を取り上げてご紹介させていただきます。 Cloud Spanner や AlloyDB など特徴的なデータベースラインナップを持つ Google Cloud ですが、その中でも NoSQL データベースである Firestore を、本稿では取り上げていきます。
Firestore とは
Firestore は、NoSQL のサーバレスデータベース です。ドキュメント指向のデータモデルを採用しています。
Google Cloud の他のデータベースプロダクトに比べて、以下の点で差別化されています。
- フルマネージドサービスのため、ウォームアップが不要
- モバイルアプリやウェブアプリのクライアントサイドから直接接続ができる
- リアルタイム同期(同じデータベースに接続している他のデバイスとのデータの同期が可能)
- オフラインモード(オフラインでもデータベースが利用可能)
- セキュリティルールによるアクセス制御
Firestore の ネイティブ モードと Datastore モードについて
Firestore を利用開始する際、以下のどちらかの起動モードを選択する必要があります。
- ネイティブ モード
- Datastore モード
詳細な比較表はありますが、本稿ではその中で検討すべき要点について触れておきます。
まず、新規開発 であれば基本的に ネイティブ モード を選んでいただければ問題ありません。以前はパフォーマンスの観点で、非常に大規模なワークロードで利用したい場合に Datastore モード を選ぶメリットがありましたが、本年度に実施されたアップデート により、ネイティブ モードの制限( 1 秒あたりの書き込みオペレーション数の制限 10,000 回)が撤廃されました。そのため、新規開発であれば ネイティブ モードを選択いただいて良いでしょう。
選択のためのフローチャートを掲載しています。
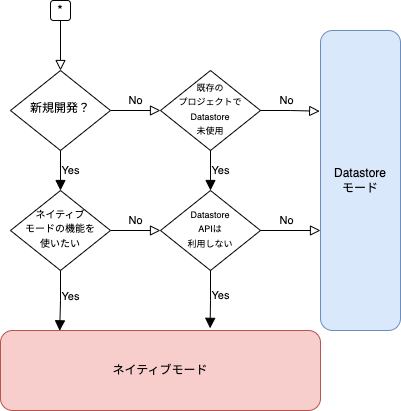
以下のいずれかのケースに当てはまる場合は Datastore モードを、当てはまらない場合はネイティブ モードを選択して良いでしょう。
- Datastore を既に利用しているプロジェクトの場合
- Firestore の Datastore モードに自動的に移行されるため、該当のプロジェクトで Firestore のネイティブ モードを利用することはできません(切り替え不可)。
- 移行したい場合、別のプロジェクトを利用する必要があります。
-
Datastore API に対応したライブラリ を使い回したい場合
- App Engine の運用実績があるチームの場合はこちらの理由で採用するケースもあります。
- ネイティブ モードは Datastore API に対応していないため、Datastore モードを選択します。
Firestore の課金モデル
Firestore では実施したオペレーションに基づく課金モデルを採用しています。
具体的には、ドキュメントの読み込み件数、書き込み件数、削除件数がカウントされ、一定件数ごとに課金が行われます。上記に加え、保持するデータ量、ネットワークの下りに課金が行われます。1 日あたりの無料枠があり、開発環境で小規模な検証を行うには十分な枠が設定されているため、スモールスタートが可能です。無料枠の対象となるのは (default) データベースになります。
ドキュメント指向データモデル
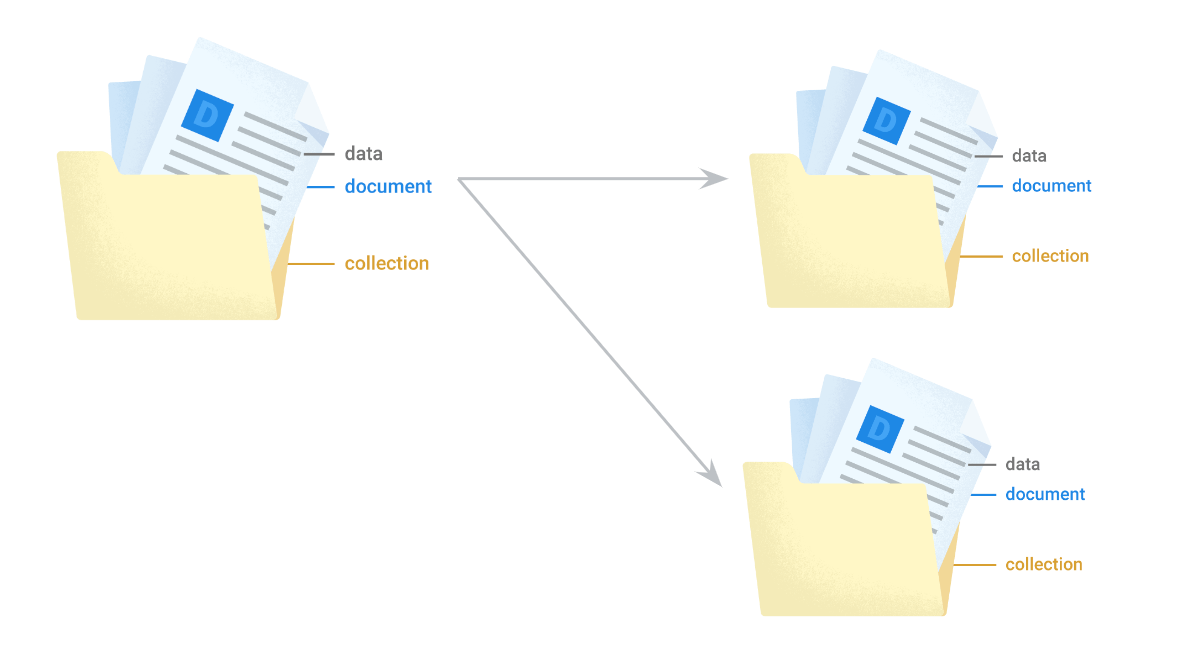
Firestore にはテーブル、行、カラムといった概念はありません。Firestore で採用しているドキュメント指向データモデルは、データをコレクション、ドキュメントという概念で扱います。ドキュメントはキーバリューの形式でデータを格納できる構造になっており、それを束ねるコンテナをコレクションと呼びます。ドキュメントは個々を区別出来るように ID を持っています。
下図は Firestore のデータモデルの概念である、コレクション、ドキュメント、データの関係を視覚的に表現したものです。フォルダ(コレクション)の中に、書類(ドキュメント)がたくさん入っています。書類には情報(データ)が記載されています。

以下のコードブロックは、コレクション、ドキュメントを JSON 形式を利用して表現したものになります。User コレクション以下に ID=alovelace, aturing を持つドキュメントが存在し、データとしてキーバリューペアを持ちます。キーバリューストアの特長上、ドキュメント内のキーは共通でなくてもよく、片方にだけ存在するキーバリューペアがあっても問題ありません。以下の例では born (生誕年) キーは ID=alovelace のみ存在しています。
{
"User": {
"alovelace": {
"first": "Ada",
"last": "Lovelace",
"born": 1815
},
"aturing": {
"first": "Alan",
"last": "turing"
}
}
}
Firestore のデータモデルの特長に、コレクションを階層構造で持つことができるというものがあります。具体的には、特定のドキュメント以下に、ドキュメントに紐づくコレクションを保持することができます。ドキュメント以下に保持できるコレクションのことをサブコレクションと呼びます。サブコレクション内のドキュメントが、更にサブコレクションを持つこともでき、最大 100 階層までデータをネストできます。
サブコレクションを利用すると、データ構造がイメージしやすくなったり、クエリが有利になったり、後述するクオータを回避できたりなどのメリットがあります。
ホットスポットに注意する
Firestore は、コレクションやドキュメントの ID によってデータを分割して保持しています。そのため、データ作成時、更新時の ID の値が辞書的に近い(1,2,3,4のような、auto incremental な連続値等)位置に集中すると、特定のクラスタにアクセスが集中するためにパフォーマンスが劣化します。この、特定の位置に書き込みが集中することをホットスポットと呼びます。
作成時の ID に自動採番(クラスタが適切に分散される)を利用したり、辞書的に近い値が連続して選ばれないようにしたりして、ホットスポット発生を回避するデータベース設計を行う必要があります。その他のパフォーマンス要件 についても一読いただくことをお勧めします。
キーバリューペア
コレクションやドキュメントのIDやフィールド名(キー)に関する制約はこちらを参照してください。バリューに格納できる値の型として、数値や文字列、配列、マップ、バイナリデータなどをサポート しています。
注意すべき3つのFirestoreのクオータ
Firestoreを利用するにあたって、注意すべきクオータがあります。ここでは、代表的なものを3つご紹介します。
1. ドキュメントサイズの上限 1 MB
ドキュメントを肥大化させすぎないようにします。Firestore とやり取りするデータ量はパフォーマンスにも関わってくるためです。クエリの制限があるため、なるだけ多くの情報をドキュメントに含めようとしたくなりますが、こちらの制限に注意します。なお、サブコレクション内のデータは、該当のドキュメントサイズには含まれません。
解決策: ドキュメントを分割したりサブコレクションを使ったり、ドキュメントが肥大化しすぎないように設計を行います。
2. コレクションへの書き込み速度 500 QPS(Query per second)
本制限はハードリミット(厳密な制約)ではありませんが、コレクションに対する書き込み速度が 1 秒間に 500 回を超えるとエラーが発生する可能性が増加し、性能が最大限発揮できなくなります。
解決策: 書き込みをキューイングして制御する。特定のコレクションに書き込みが集中しないようにコレクションを分割したり、シャーディングしたり、サブコレクションを利用したりする。
3. ドキュメントあたりの更新速度 1 QPS
Firestoreはデータを冗長化して保持するための設計上、同一ドキュメントの更新頻度を制限しています。こちらもハードリミットではなく、一時的に 1 QPS以上の書き込みを行うことは可能ですが、負荷をかけ続けるとデータベース全体の性能が悪化するリスクがあります。
解決策: 書き込みをキューイングして制御する。データ設計を工夫したり、ドキュメントをシャーディングしたりして、特定のドキュメントに書き込みが集中しないようにする。サブコレクションを利用する。頻繁に更新が必要な箇所はキャッシュサービス等を有効活用する。
Firestore を利用するための権限
Firestore をサーバサイドから利用するには、適切な権限を付与したサービスアカウントが必要です。
- 読み書きを行う: 「Cloud Datastore ユーザ(roles/datastore.user)」
- 読み込みだけ行う: 「Cloud Datastore 閲覧者(roles/datastore.viewer)」
- インデックスの管理を行う: 「Cloud Datastore インデックス 管理者(roles/datastore.indexAdmin)」
上記は事前定義された権限になりますが、より詳細に権限を管理したい場合は、サーバー クライアント ライブラリのセキュリティを参照して下さい。App Engine の場合はデフォルトで必要な権限が付与されているため、対応は不要です。
セキュリティルール
Firestore セキュリティ ルールを使用すると、データベース内のドキュメントおよびコレクションへのアクセスを制御できます。セキュリティ ルールの構文の柔軟性により、データベース全体へのすべての書き込みから特定のドキュメントに対する特定のオペレーションまで制御を行うことが可能です。セキュリティ ルールの編集は、Firebase コンソール上で行う他、Firebase Rules API も利用できます。
Firebase セキュリティ ルールは、データベース内のドキュメントを識別する match ステートメントと、ドキュメントへのアクセスを制御する allow 式で構成されます。
以下に例を示します。<some_path> にはドキュメントのパスを、 <some_condition> にはブール式( true / false を返す式)を指定します。
service cloud.firestore {
match /databases/{database}/documents {
match /<some_path>/ {
allow read, write: if <some_condition>;
}
}
}
以下に具体的な例を示します。users コレクション以下にドキュメントを作成する処理は、ログインしていれば(request.auth != null)許可されるが、作成されたドキュメントを読み込んだり、更新したり、削除したりは作成したユーザのみ行える(request.auth.uid == userId)、といった制御ができます。
service cloud.firestore {
match /databases/{database}/documents {
// Make sure the uid of the requesting user matches name of the user
// document. The wildcard expression {userId} makes the userId variable
// available in rules.
match /users/{userId} {
allow read, update, delete: if request.auth != null && request.auth.uid == userId;
allow create: if request.auth != null;
}
}
}
開発環境では、認証を必須[1]とした基本的なセキュリティルールから始めることをおすすめします。認証なしでの読み込み / 書き込みを許可[2]すると、ネットワーク上全体からのアクセスを許可することになってしまうため、本番環境では絶対に利用しないで下さい。
// Allow read/write access on all documents to any user signed in to the application
// [1] 認証必須
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
allow read, write: if request.auth != null;
}
}
}
// Allow read/write access to all users under any conditions
// Warning: **NEVER** use this rule set in production; it allows
// anyone to overwrite your entire database.
// [2] 認証なし
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
allow read, write: if true;
}
}
}
作成したセキュリティ ルールは、Firebase コンソール上で検証を行うことができます。認証の有無、パスを指定することでアクセスが許可されるか、拒否されるかを確認できます。
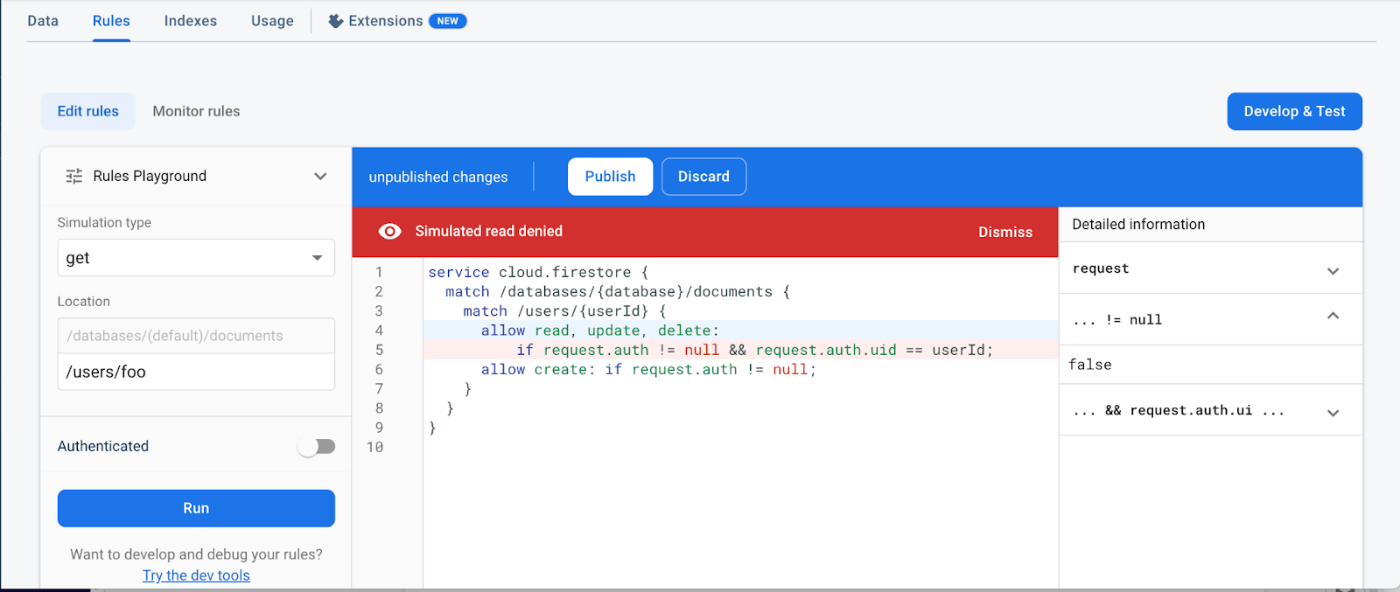
上記は、 /users/foo に認証なしでアクセスした例です。アクセスが拒否され、 Read denied と表示されています。Detailed information を見ると、 request.auth != null となっており、アクセスが拒否されていることがわかります。
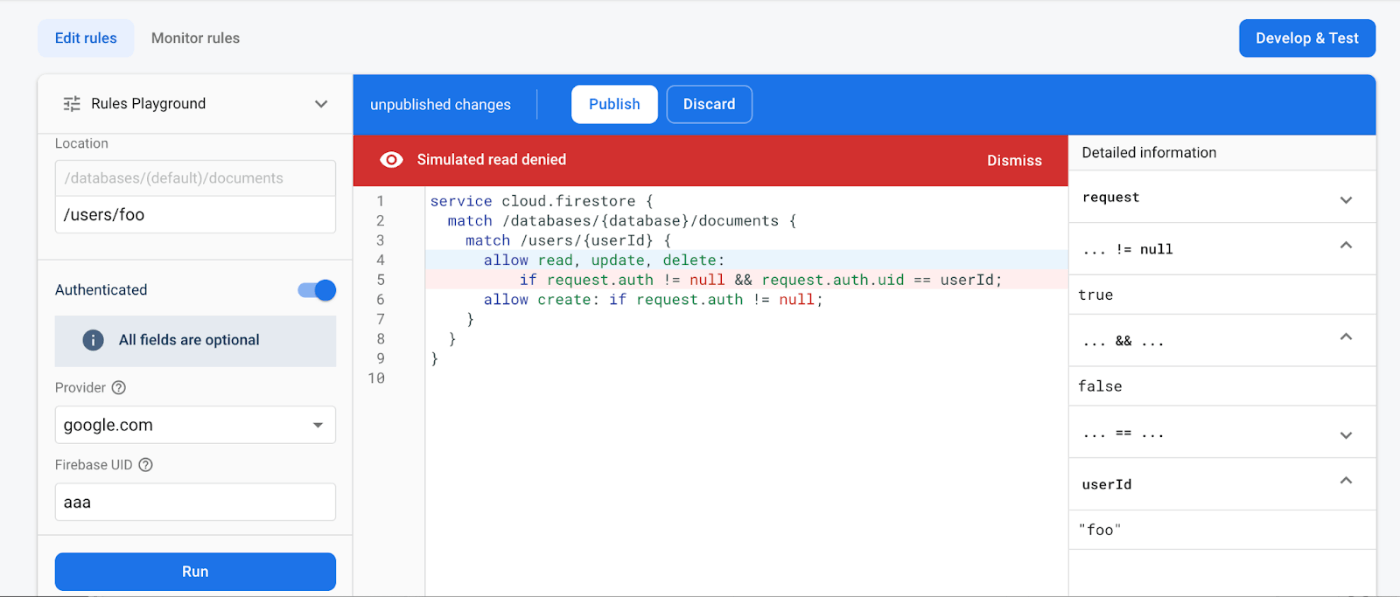
続いて、認証を有効にしてアクセスしたケースを示しています。/users/foo にアクセスする際に ID として Firebase UID = aaa を指定しています。このケースでは、request.auth != null は true となっていますが、 request.auth.uid == userId が aaa != foo となり、アクセスが拒否されています。
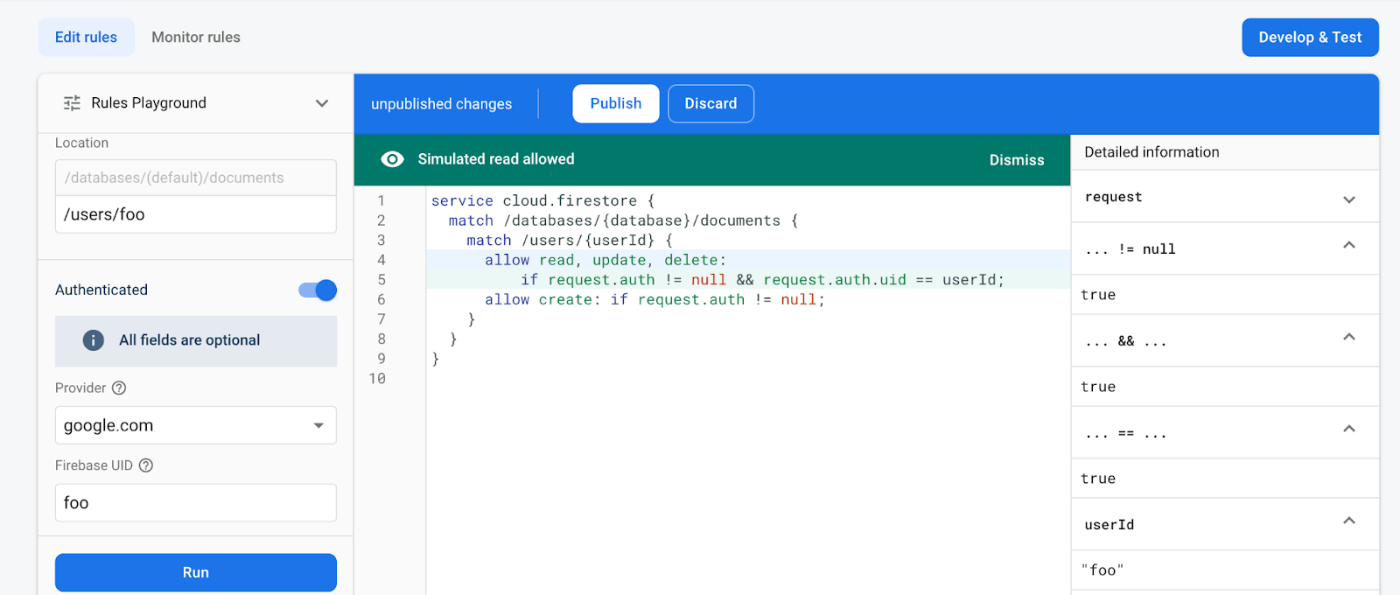
最後に、認証を有効にしたうえで、Firebase UID = foo を指定したケースです。こちらは Read allowed となり、アクセスが許可されています。このように、セキュリティルールをコンソール上で試すことができ、かつ各々のルールがどのように判定されたかがわかるため、直感的に利用できます。
データの作成・取得
それでは、実際にFirestore にデータを格納してみましょう。以降、サーバサイドでの利用を想定して、Python の擬似コードを示します。
まずは Admin SDK を導入します。他言語の Firebase Admin SDK の一覧はこちらを参照してください。
pip install firebase-admin
実際にコードを記述してみます。まず、コード内でクライアントの生成を行います。
import firebase_admin
from firebase_admin import firestore
firebase_admin.initialize_app()
db = firebase_admin.client()
users コレクションにユーザ情報を作成してみます。
users_ref = db.collection('users')
users_ref.document('aturing').set(
{
'first': 'Alan',
'last': 'Turing'
}
)
Firebase コンソールを確認すると、以下のようにドキュメントが生成されていることがわかります。
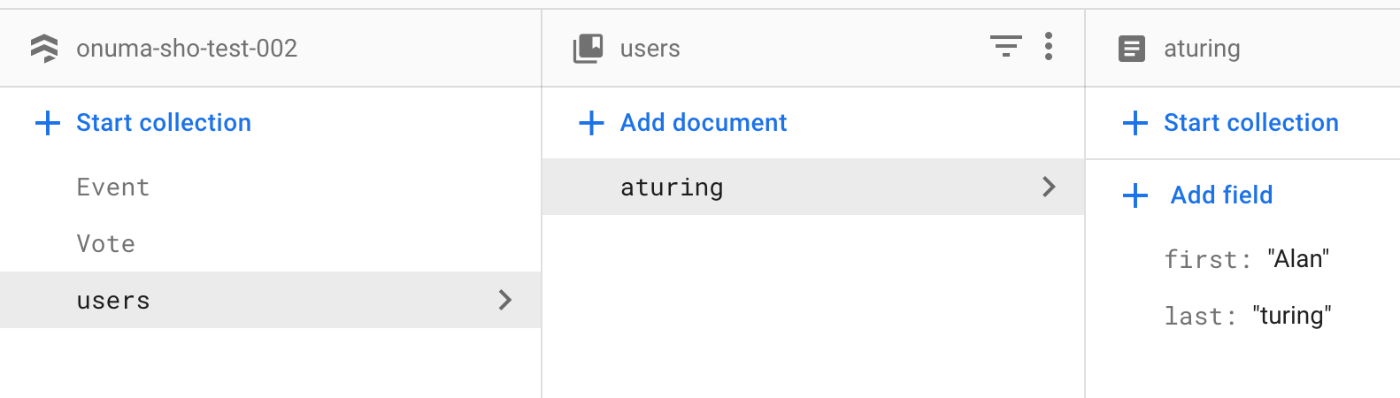
作成したデータを取得してみます。
doc_ref = db.collection('users').document('aturing')
doc = doc_ref.get()
#ID
print(doc.id)
#data
print(doc.to_dict())
IDを指定せず(自動生成)にドキュメントを作成する場合は、 set() ではなく add() を使います。add() と doc().set() は等価(同じ結果)です。
users_ref = db.collection('users')
users_ref.add(
{
'first': 'Ada',
'last': 'Lovelace',
'born': 1815
}
)
# equivalent to .add()
users_ref.doc().set(
{
'first': 'Ada',
'last': 'Lovelace',
'born': 1815
}
)
Firebase コンソールを確認すると、自動生成された ID が割り当てられていることがわかります。
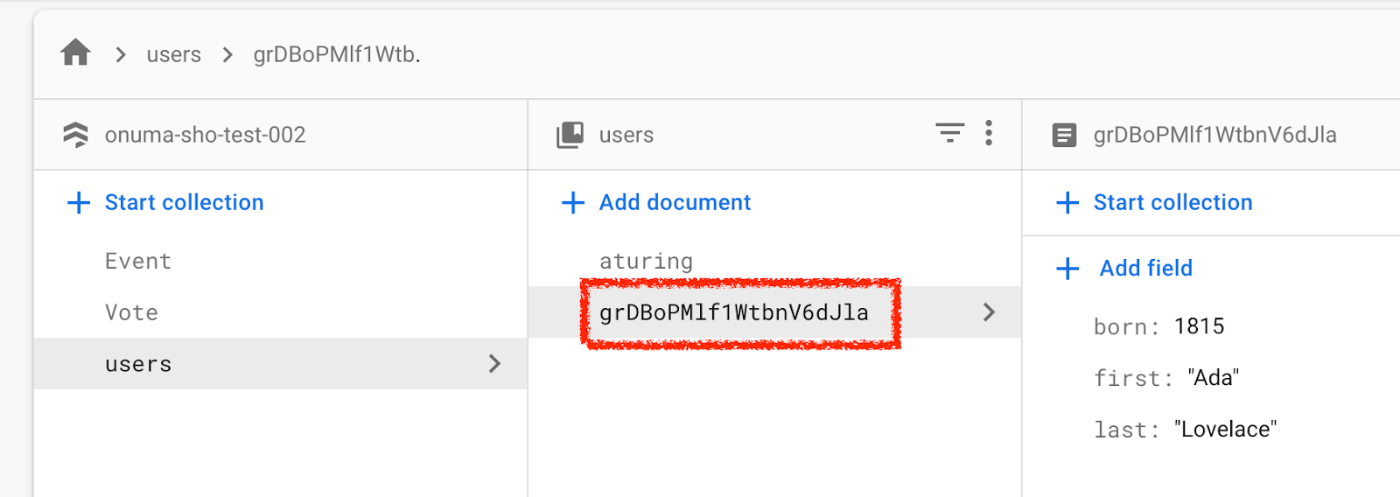
自動生成された ID は Firestore のバックエンド側で 適切に負荷分散される値であるため、連続してドキュメントを作成してもホットスポットになることはありません。
データのクエリ
Firestore は キーバリューストア でありつつも、クエリを実施することができます。クエリには制約条件がありますが、強力な武器になります。例えば、users ドキュメントから born == 1815 のエントリを取得するには、以下のようにします。
users_ref = db.collection('users')
query_ref = users_ref.where('born', '==', 1815)
#execute query
docs = query_ref.stream()
for doc in docs:
#id
print(doc.id)
#value
print(doc.to_dict())
クエリには、不等号条件や並べ替え条件を1つのフィールドまで指定できます。例えば、born >= 1800 を満たす結果を取得するクエリは[1]のように記述できます。また、 1800 <= born <= 1900 といったクエリ[2]も実行可能です。
# [1] OK
query_ref = users_ref.where('born', '>=', 1800)
# [2] OK
query_ref = users_ref.where(
'born', '>=', 1800).where('born', '<=', 1900)
ここで、クエリには制限があることをおさえておきましょう。例えば等価の条件と範囲指定を組み合わせて指定[3]することはできません。範囲指定の複数フィールドの組み合わせ[4]も同様です。
# [3] NG
query_ref = users_ref.where(
'born', '>=', 1800).where('country', '==', 'GB')
# [4] NG
query_ref = users_ref.where(
'born', '>=', 1800).where('follower', '>=', 100000)
Firestore はクエリを効率的に実行するためにインデックスを利用します。複数フィールドに渡るクエリの場合はデフォルトのインデックスだけでは高速に結果を出すことができないためです。上記のクエリは、複合インデックスを定義することで、実行可能とすることができます。複合インデックスは便利ですが、作成することでストレージ容量が増加します。また、作成インデックス数には上限があります。これらの制限を考慮して、効率的に複合インデックスを活用しましょう。
サブコレクションを使う
サブコレクションとは、前述した通りドキュメント以下に保持できるコレクションになります。このサブコレクションを使うことで、クエリを便利に利用することができます。具体例として、チャットルームにユーザが参加しており、ルームのコメントを管理することを考えてみましょう。
以下の例では、ルームを rooms コレクション、ルームに対して投稿された内容を posts コレクションで管理しています。rooms コレクション内のドキュメントで posts を管理したくなりますが、ドキュメントの更新頻度を1 QPS 以内に収めるため、別のコレクションで管理しています。posts コレクションは、どのルームの投稿内容であるかを保持するために roomId を保持しています。
// rooms コレクション
{
"rooms": {
"R0001": {
"capacity": 10,
"title": "Game Lovers",
"description": "Let's talk!"
}
}
}
// posts コレクション
{
"posts": {
"P0001": {
"roomId": "R0001",
"userId": "M0001",
"comment": "Hello",
"postedAt": 1234567890
},
"P0002": {
"roomId": "R0001",
"userId": "M0002",
"comment": "Hi",
"postedAt": 1234567898
}
}
}
上記の構成で「特定のルームの投稿内容を取得する」場合のクエリを考えてみます。それは、以下のようになります。
# OK
db.collection('posts').where('roomId', '==', 'R0001')
では、「最新のコメントを10件取得したい」場合を考えています。order_by は並び順を制御する構文で、direction に 降順を指定しています。このクエリは動作するでしょうか。残念ながら、これは動作しません。
# NG
db.collection('posts').where(
'roomId', '==', 'R0001').order_by(
'postedAt', direction=firestore.Query.DESCENDING).limit(10)
なぜなら、order_by 句は範囲指定と同様に扱われるため、等価の条件(where 句)と一緒に扱う場合は複合インデックスが必要となるためです。
では、サブコレクションを使った場合はどうでしょう。上記のユースケースは、 posts コレクションが「特定のルーム内のコメント」と階層構造になっていることに着目し、これをサブコレクションで管理することを考えてみます。以下は、階層構造をJSON形式で表現したものです。
{
"rooms": {
"R0001": {
"capacity": 10,
"title": "Game Lovers",
"description": "Let's talk!"
"posts": <posts>
}
}
}
// <posts>
{
"posts": {
"P0001": {
"userId": "M0001",
"comment": "Hello",
"postedAt": 1234567890
},
"P0002": {
"userId": "M0002",
"comment": "Hi",
"postedAt": 1234567890
}
}
}
先ほどの posts コレクションが最上位のコレクションで定義されている時とは異なり、posts コレクションのドキュメントに roomId が不要になりました。これは、上位のドキュメント情報に roomId が含まれているためです。
上記の構造の場合、「特定のルームの投稿内容を取得する」クエリは以下のように表現できます。
db.collection('rooms').doc('R0001').collection('posts')
同様に「最新のコメントを 10 件取得したい」ケースは、以下のように記述できます。これは動作します。なぜなら、クエリ条件に where 句が存在しないため、複合インデックスがなくても良いためです。そのため、サブコレクションを使うことで、無償の where 句が提供されているものと考えることができます。
# OK
db.collection('rooms').doc('R0001').collection(
'posts').order_by(
'postedAt', direction=firestore.Query.DESCENDING).limit(10)
一方で、サブコレクションを利用することによりルーム横断で投稿内容を取得するのが難しくなるように見えます。このようなユースケース、例えば「全投稿内容から最新の 10 件を取りたい」といった場合はコレクショングループ という概念が利用できます。
(参考)エミュレータを使う
ローカル環境で開発を行う場合など、リモートのデータベースに接続するのが難しい場合、ローカルで動作する Firebase エミュレータを利用することができます。詳細は公式ドキュメントを参考にして下さい。
- https://firebase.google.com/docs/emulator-suite/install_and_configure
- https://firebase.google.com/docs/emulator-suite/connect_firestore
# エミュレータの導入
firebase init emulators
# 環境変数にエミュレータのホストを指定
export FIRESTORE_EMULATOR_HOST="localhost:8080"
エミュレータはローカルで動作するほか、単体テストで利用できるメリットもあります。
なお、更新やトランザクションなど、一部の制限が実際の Firestore と異なることに注意して下さい。本番環境への投入前の負荷試験では実際にリモートの Firestore を使って検証を行うことをお勧めします。
直近の更新のご紹介
直近行われた Firestore に関する更新について、3点ご紹介します。
1. count() のサポート
特定のスコア以上を獲得したユーザを取得するというケースを考えた場合、従来は該当するドキュメントをクエリで取得した上で、取得された件数をカウントする必要がありました。count() の導入により、ドキュメントの内容を取得する必要がなく件数をカウントできるようになりました。
2. ネイティブ モードでのパフォーマンス向上
これまではデータベースごとに 1 秒あたりの書き込みオペレーションの回数が 10,000 回という上限がありましたが、この上限が撤廃されました。Firestore は、書き込みトラフィックの増加に応じて、自動的にスケールアップします。
3. TTL(Time To Live、有効期限)の導入
ストレージコストを最適化するため、事前にコレクションに設定を行うことで、不要なデータを時間経過で削除することができるようになりました。
上記の3点について、詳細は公式ブログでも紹介されています。
まとめ
本日は わかる! Firestore ということで、Firestore の概要をご紹介させていただきました。
NoSQL のデータベースということで、今まで RDBMS に触れられていた方からすると勝手が違う部分もあり、最初は戸惑う部分も多いと思いますが、利用してみると柔軟なスキーマに対応できたりと、便利な部分も多いデータベースになります。サーバが不要で開発が行える部分も大きな特徴で、要件次第ではサーバ運用なしでサービスを運営できるポテンシャルも秘めています。
本稿を読んでちょっとでも興味を持たれた方は、是非これを期に Firestore に触れてみてください。
次回は Dataplex についての記事となります。お楽しみに!

Discussion