Google Cloud Japan Advent Calendar 2025 の16日目の記事です。
本日のテーマは、BigQuery と Apache Iceberg (以下 Iceberg) です。
はじめに
Lakehouse を活用するアーキテクチャにおいて、様々な場面で Open Table Format として Iceberg が注目されています。Google Cloud でも、BigQuery や BigLake を中心に Iceberg に対応してから、継続的にアップデートが出ています。
本稿では、BigQuery や BigLake で扱える Iceberg テーブルについて紹介します。
Google Cloud の Iceberg に対応したテーブル
Google Cloud では、マルチクラウドな Lakehouse を構築するための BigLake というストレージエンジンがあり、BigQuery やその他 Spark 等のオープンソース分析エンジンに対し、きめ細かなガバナンスの適用やパフォーマンス向上を実現します。
Lakehouse のスタックで表すと以下のようなイメージになります。
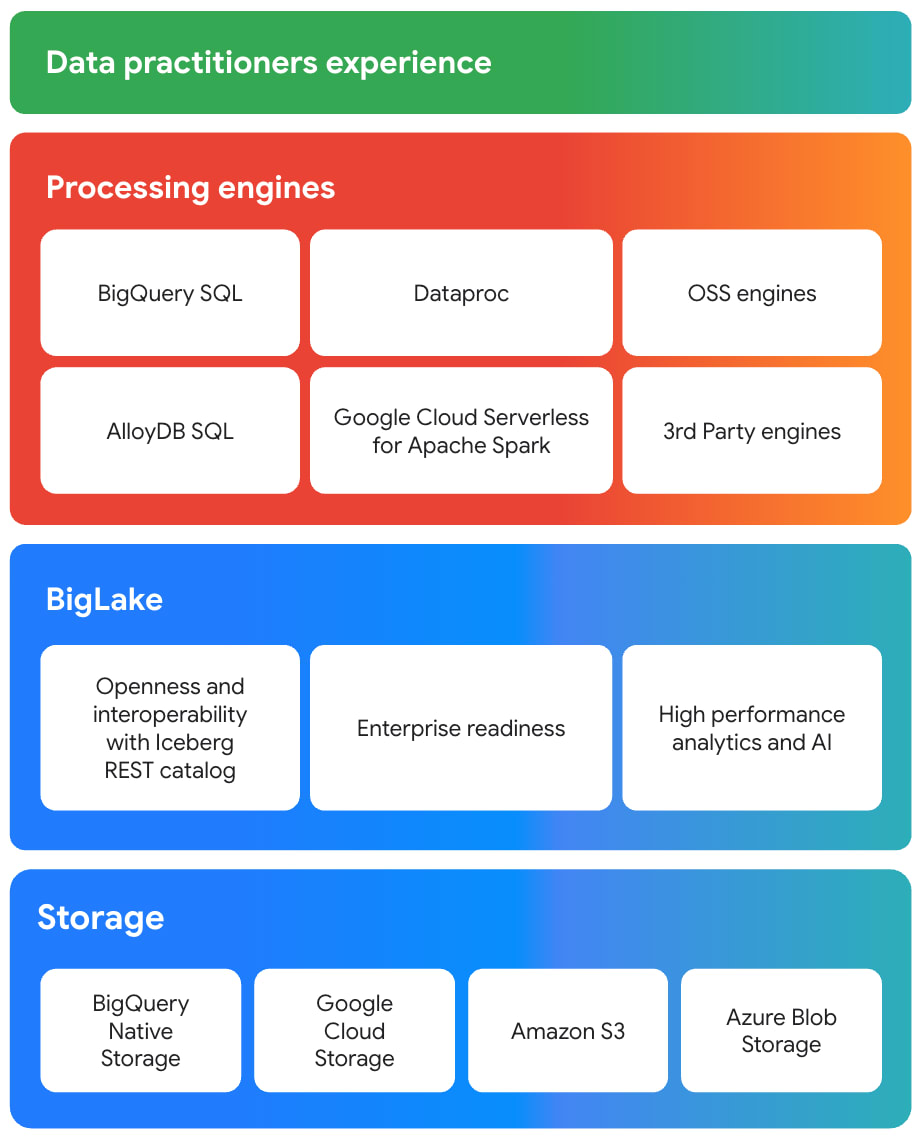
BigLake は Iceberg にも対応しており、Iceberg テーブル に対して BigQuery から読み書きができるようになります。マネージドなメタストア (BigLake Metastore)も提供していますが、BigLake Metastore の詳細はまた別の機会に投稿しようと思います。
現在 BigQuery からアクセスできる Iceberg テーブルには以下の2種類があります。
- BigLake tables for Apache Iceberg
- BigLake tables for Apache Iceberg in BigQuery
ここからは、それぞれの詳細を見ていきましょう。
BigLake tables for Apache Iceberg
BigLake tables for Apache Iceberg(以下 BigLake Iceberg tables)は、オープンソースやサードパーティエンジン主導型で、Apache Spark や Trino 等のオープンソースエンジンを中心としたデータパイプラインを構築したい場合に適した形式です。
データの書き込み(INSERT、UPDATE 等)やメンテナンスは、テーブルを作成したオープンソース等のエンジン側で行います。BigQuery はこのテーブルに対して、BigLake 外部テーブルとして ”読み取り専用” でアクセスします。
ユースケースを挙げると、既に Spark 等で ETL 処理を行っており、そのフローを変えずに BigQuery の分析能力を活用したい場合はこちらの Iceberg table が適しています。
BigLake tables for Apache Iceberg in BigQuery
BigLake tables for Apache Iceberg in BigQuery(以下 BigLake Iceberg tables in BigQuery)は、BigQuery主導型で、BigQuery の強力な管理機能や使い勝手を維持しつつ、データ形式をオープンな Iceberg にしたい場合に適した形式です。
BigQuery インターフェースから作成される Iceberg テーブルで、通常の BigQuery テーブルと同様に扱えますが、データの実体はユーザーが管理する Cloud Storage (GCS) バケットに、Iceberg テーブルとして保存されます。
データの書き込みや管理は BigQuery が行い、BigQuery のフルマネージドな機能(自動ストレージ最適化、クラスタリング、ガベージコレクション等)が適用されます。Spark 等の他のエンジンからも読み取りが可能です。
ユースケースを挙げると、ETL 処理を BigQuery で完結させたいが、他のエンジンとの相互運用性も確保したい場合はこちらが適しています。
比較表
それぞれの特徴を表にまとめると以下のとおりです。
| BigLake Iceberg tables | BigLake Iceberg tables in BigQuery | |
|---|---|---|
| メタストア | BigLake metastore AWS Glue Data Catalog Iceberg JSON metadata files |
BigLake metastore |
| データの実体 | GCS Amazon S3 Azure Blob Storage |
GCS |
| 読み書き(R/W) | BigQuery (R) 3Pエンジン (R/W) |
BigQuery (R/W) 3Pエンジン (R) |
| メンテナンス | 3Pエンジン | BigQuery / BigLake |
| ユースケース | Spark 等の OSS Engine で ETL 処理を行っており、そのフローを変えずに BigQuery の分析能力を活用したい場合 | ETL 処理を BigQuery で完結させつつ、他のエンジンとの相互運用性も確保したい場合 |
今後の BigLake Iceberg tables
本稿で紹介した2つの BigLake Iceberg tables が統合されるというロードマップがあります。統合されると、書き込みを行う処理エンジンが、BigQuery か Iceberg 互換エンジンかによって、BigLake Iceberg Tables を使い分ける必要がなくなる見込みです。
統合された BigLake Iceberg tables については、以下の Webinar の ”Open Lakehouse” のパートでも紹介されていますので、参考にしていただけると幸いです。
Data Analytics Innovation Roadmap
作成してみよう
ここからは実際にテーブルを作成し、BigQuery から参照していきます。
BigLake Iceberg tables
まずは、BigQuery Iceberg tables を作成します。今回は BigQuery Studio の Notebook から Serverless Spark を使って作成します。
※ BigQuery Studio の Notebook から実行するためには、事前に Serverless Spark や Colab Enterprise の権限設定等が必要です。
参考: BigQuery Studio ノートブックで PySpark コードを実行する
各種設定
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
from pyspark.sql import SparkSession
import pyspark.sql.functions as f
# Create the Dataproc Serverless session.
session = Session()
project_id = "your-project-id"
region = "US"
subnet_name = "subnet-name"
location = "US"
idle_ttl = "1800s"
session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}"
session.environment_config.execution_config.idle_ttl = f"{idle_ttl}"
warehouse_dir = "gs://your-bucket-name/biglake_iceberg"
catalog = "blms1"
namespace = "blms_sample_1" # NAMESPACE は BQのDatasetに相当
session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}"
Spark セッション作成
# Create the Spark Connect session.
spark = (
DataprocSparkSession.builder
.appName("BigLake Metastore Iceberg")
.dataprocSessionConfig(session)
.getOrCreate()
)
テーブル作成
spark.sql("USE blms1;")
spark.sql("CREATE NAMESPACE IF NOT EXISTS blms_sample_1;")
spark.sql("USE blms_sample_1;")
spark.sql("CREATE TABLE oct_iceberg_1 (id int, data string) USING ICEBERG LOCATION 'gs://your-bucket-name/iceberg_1'")
spark.sql("DESCRIBE oct_iceberg_1;")
+--------+---------+-------+
|col_name|data_type|comment|
+--------+---------+-------+
| id| int| NULL|
| data| string| NULL|
+--------+---------+-------+
作成したテーブルにデータを Insert
spark.sql("INSERT INTO oct_iceberg_1 VALUES (1, \"first row\");")
作成したテーブルを Select
spark.sql("SELECT * from oct_iceberg_1;").show()
最新の JSON metadata file を調べる
spark.sql("SELECT file FROM blms1.blms_sample_1.oct_iceberg_1.metadata_log_entries order by latest_sequence_number desc limit 1").show(truncate=False)
+-------------------------------------------------------------------------------------------------+
|file |
+-------------------------------------------------------------------------------------------------+
|gs://your-bucket-name/iceberg_1/metadata/00009-4859d59c-d085-44c8-b88d-67514a9d4a16.metadata.json|
+-------------------------------------------------------------------------------------------------+
BigLake Metastore を指定している場合、この時点で外部テーブルとして BigQuery から参照することができます。

上記で作成したIceberg table を BigLake Iceberg tables として読み込めるように BigLake table を定義します。
”接続”のサービスアカウントに次のロールを付与して、Cloud Storage のデータの読み取りと書き込みを行えるようにします。
- Storage Object User
roles/storage.objectUser - Storage Legacy Bucket Reader
roles/storage.legacyBucketReader
ここからは BigQuery の SQL を実行します。
テーブル作成
-- Create BigLake Iceberg table
CREATE OR REPLACE EXTERNAL TABLE `your-project-id`.blms_sample_1.bl_iceberg_1
WITH CONNECTION `your-project-id.us.iceberg-01`
OPTIONS (
format = 'ICEBERG',
uris =
['gs://your-bucket-name/iceberg_1/metadata/00009-4859d59c-d085-44c8-b88d-67514a9d4a16.metadata.json'],
require_partition_filter = FALSE)
作成したテーブルの詳細は以下のようになります。
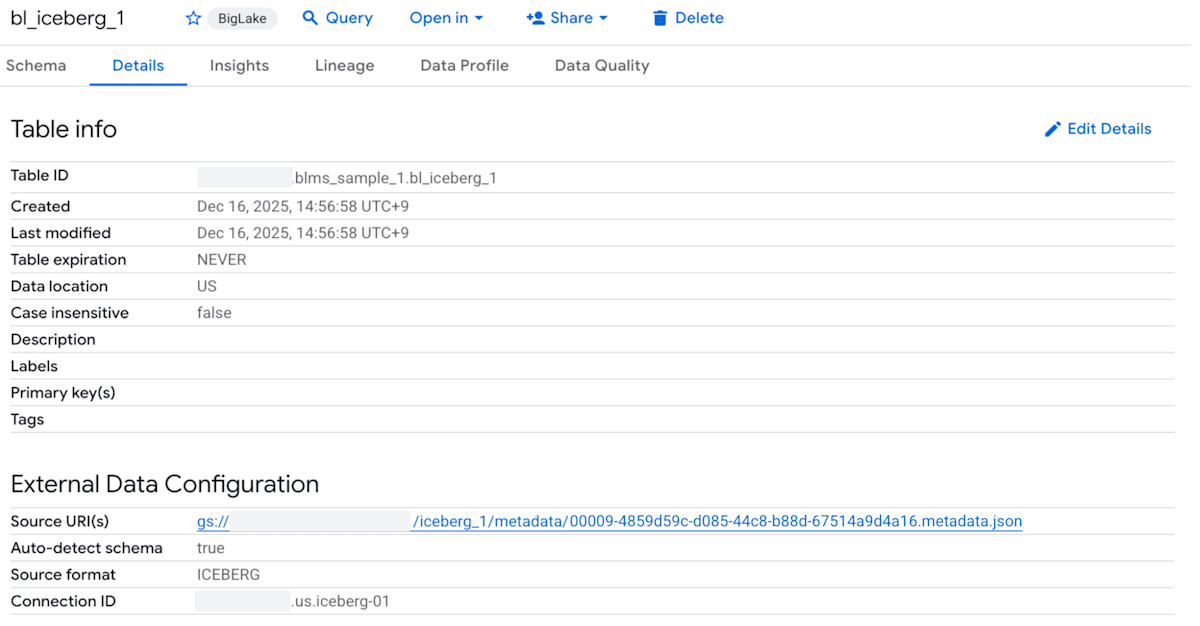
作成したテーブルを Select
select * from blms_sample_1.bl_iceberg_1;
+---+---------+
| id| data|
+---+---------+
| 1|first row|
+---+---------+
このように、Spark で作成し、書き込んだ Iceberg テーブルを BigQuery から参照することができるようになりました。
BigLake Iceberg tables in BigQuery
続いて、BigQuery から読み書きができる BigLake Iceberg tables in BigQuery を作成します。
テーブル作成
CREATE TABLE `your-project-id`.blms_sample_1.bq_iceberg_1(
name STRING,id INT64
)
WITH CONNECTION `your-project-id.us.iceberg-01`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://your-bucket-name/bq_iceberg');
作成したテーブルの詳細は以下のようになります。

いくつかのレコードを Insert
INSERT INTO `your-project-id`.blms_sample_1.bq_iceberg_1 VALUES ('test_name1', 123),('test_name2', 456),('test_name3', 789);
作成したテーブルを Select
SELECT * FROM `your-project-id`.blms_sample_1.bq_iceberg_1;
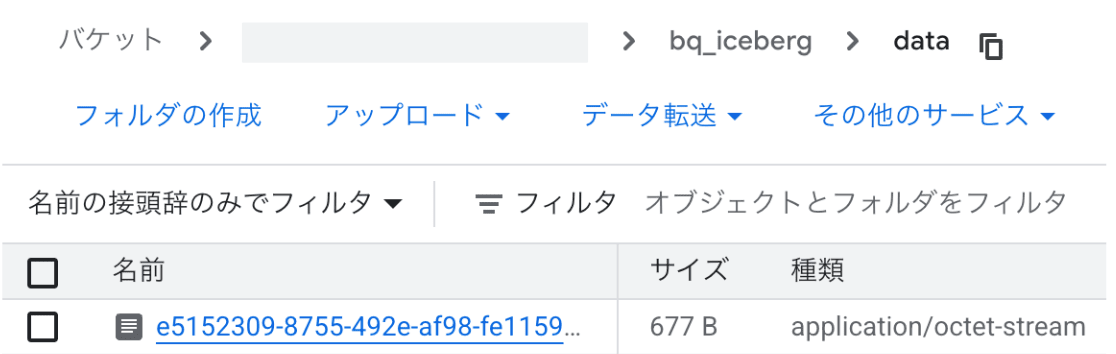
指定した GCS バケットを見ると、 data 配下にオブジェクトが追加されているのがわかります。
まとめ
Google Cloud の Open Lakehouse は、BigQuery の強力な分析機能と Apache Iceberg のオープン性を両立させるアーキテクチャです。
本稿では、BigQuery で扱える 2 種類の Iceberg テーブルについて解説しました。今後はこれらが統合され、エンジンの境界を意識することなく、さらにシームレスな体験が提供される見込みです。
進化し続ける Google Cloud の Open Lakehouse に、引き続きご注目ください!

Discussion