はじめに
Technical Solutions Engineer の Kakeru です。 今回、Kubecon + CloudNativeCon Japan 2025 にて Safeguarding Your Applications Achieving Zero Downtime During Kubernetes Upgradesというタイトルで講演いたしました。
セッションでは、我々が普段サポートする Google Kubernetes Engine (GKE) に限定されない一般的な Kubernetes において、アップグレード時にゼロダウンタイムを実現するための方法について発表しました。
本記事では、簡単な「1. 発表内容の振り返り」とともに、「2. 当日触れることのできなかったより深い内容」、「3. GKE 特有の場合での補足」について記述します。
英語のセッションではありますが、実際の講演もしくは、そのレコーディングを視聴した方向けの記事となっております。未視聴の方はよろしければこちらをまずご覧ください(発表内容は英語ですが、Youtubeの自動字幕もあります。)
発表内容の振り返り
本公演は、タイトル通り Kubernetes のアップグレード時の "ゼロダウンタイム" を目指すための様々な知見を共有することが目的でした。
大事なのが「ダウンタイムを減らす」ではなく、「ゼロダウンタイム」を目指す点です。例えば以下のような項目は今回のスコープ外としていました。
- 実際のアップグレードのコマンドや必要なオペレーション等
- アップグレード後にバージョンの差異によりアプリケーションが動かなくなってしまうこと等の継続的なダウンタイム

アップグレード時のダウンタイムを抑止する手法は、Pod Disruption Budget(PDB)の構成のベストプラクティスなどインターネット上には様々な情報が出ています。
しかし、理想的な PDB を構成したつもりでも、実際にはワークロードにダウンタイムが出てしまって原因がよくわからない。なんてことも良くあります。
この発表ではこういったPDB等のベストプラクティス集にせず、まずダウンタイムのオブザーバビリティの話から始め、ログから確認できるリソースの変化を追いながら、重要なダウンタイムが発生しうるポイントを話していくスタイルにしたのもこのためです。

アップグレード時のダウンタイムといっても数秒に満たないことも多く、詳細な分析には、主に現在の状況を取得するための kubectl や取得間隔が場合によってはダウンタイムよりも長いこともあるメトリクスデータは頼ることができないことも多々あります。
そこで、kube-apiserver の監査ログについて触れました。監査ログは kube-apiserverを介した様々なリクエストを記録するアクセスログのようなものです。Kubernetesのリソースの変更は基本的には kube-apiserverを介して行われるため、このログから様々なリソースが具体的にどのように変更されたか確認することができます。

実際のセッション中では監査ログの中身、jqコマンドとdiffコマンドを使ってリソースの差分を見る手法を紹介しました。ただ、3年ぐらい前までは日々の業務でそれをやっていたのですが、とても時間がかかる調査なので、日本のサポートチーム内で開発しOSSとなり、GoogleCloudPlatformのGitHub組織で公開された、実際に Google Cloud サポート内で利用されているツールである Kubernetes History Inspector(KHI)を紹介しました。

以降の話では、リソースの差分を見ながらアップグレードの挙動を紹介しています。KHIを使わなくてもjqコマンドとdiffコマンドで見ることは可能ですがほとんど苦行なのと一覧性が低く明らかなダウンタイムの原因の被疑箇所がなければあまり有用なインサイトを得られません。
KHIを使えば、こういった可視化ができるのでよかったら活用してください。

マネージドなKubernetes環境であるGKEでは、アップグレード時にコントロールプレーンをあまり意識しませんが、実際には同じようなことが起きています。リージョナルクラスタでは3つのコントロールプレーンが存在し、コンポーネントごとに最大3回のダウンタイムがアップグレード中に存在します。
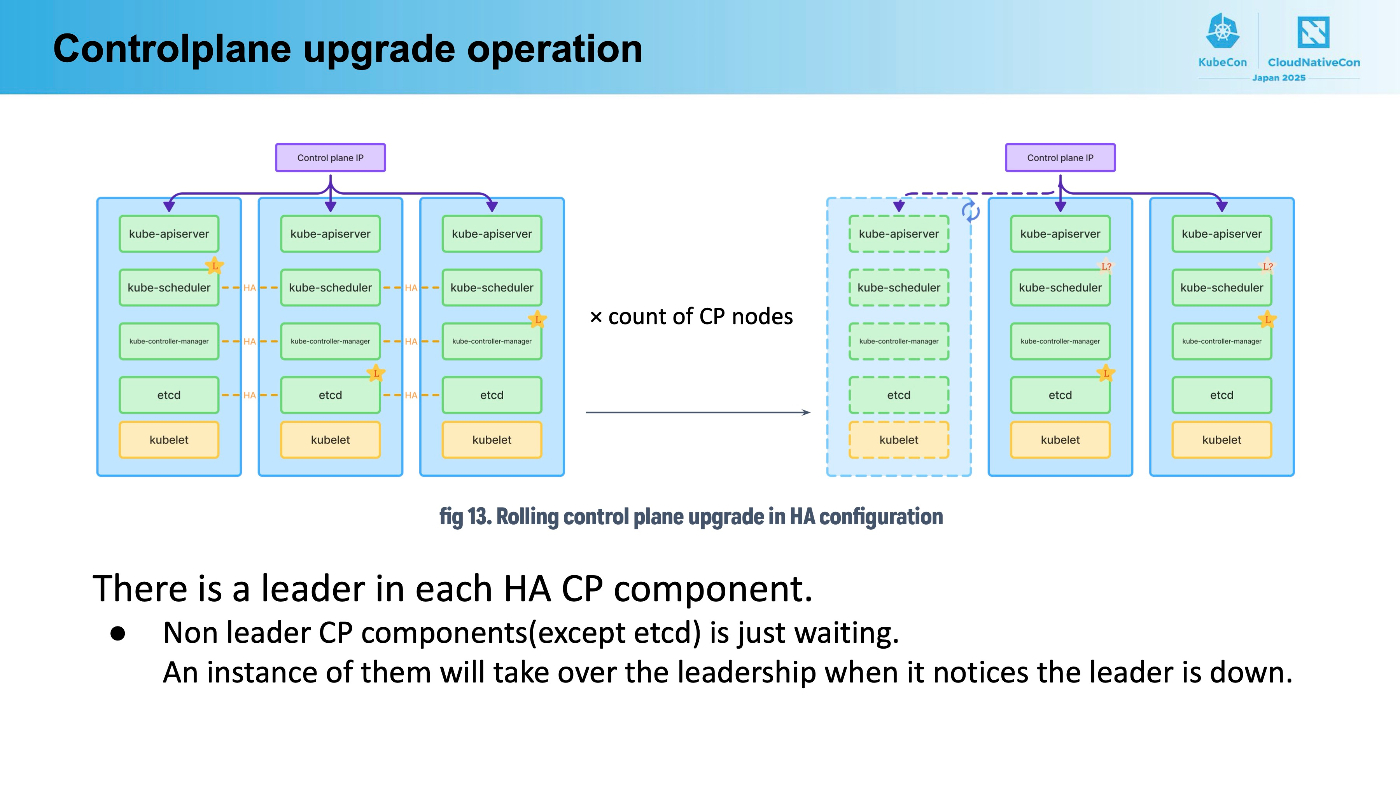
ちなみにこの辺の挙動は私の半年前の記事GKEのアップグレードのログを眺めるも合わせてご覧いただくと、実はログからマネージド部分のアップグレードに伴うフェイルオーバを確認することが可能です。
(この記事のタイミングではKHIを公開していなかったので、ログだけから頑張って分析していますが、実際にはKHIを使うとはるかに容易にわかります。よかったら試してみてくださいね。)
コントロールプレーンアップグレード時に発生するAPI関連のダウンタイムは以下のようなものです。
-
kube-apiserverから500エラーが返ってくる:etcdのリーダーがいない時にkube-apiserverにリクエストした。(リトライすれば数秒以内に回復します) -
WATCHしていた接続が閉じた: 繋げていた
kube-apiserverが落とされた。(リトライして接続し直せば別のノードに繋がり回復します)
いずれにしても、アップグレード時の影響を受けないように、KubernetesのAPIをいじるのであればリトライを前提に実装してください。
また、cronjob-controllerやdeployment-controllerなど、様々なリソースのコントローラが高可用性(HA)構成であってもリーダー選出時に一時停止します。CronJobがあるのに、本来Jobが作成されるべきタイミングから数十秒遅れて作成されるなど、一時的にリソースが処理されるタイミングが遅延するかもしれません。この時間は高可用性(HA)構成であっても発生するので、それぞれのコントローラごとに1分処理が仮に遅延しても問題ないようにしてください。
また、数十秒の遅延が許容できないJobなどは、そもそも Kubernetes のJobとして実行すべきかどうか再考の余地があります。
ワーカーノードのアップデート、つまりGKEではノードプールのアップデートでは主に意識しなければいけないのは以下の2つです。
- 今その
Podの削除処理を開始しても良いか? (PDBで担保すること) -
Podの削除時に適切な終了処理をしているか? (preStopやアプリケーションで担保すること)

PDBを正しく理解するには、PDBはあくまでブロッカーであることを気に留めておく必要があります。PDBが許しているときだけkube-apiserverがeviction APIを受付け、実際の削除を行うのです。

したがって、PDBを設定しても削除を防止しますが、Podを増やしたりはしません。PDBによって守られているものの削除することができるPodがノードのドレインによって消えると、ReplicaSet等によって再作成され、これが再度別のノードにスケジュールされるだけなのです。
これを理解していないと、replica:1 かつ minAvailable: 1のようなワークロードを作成してしまいがちですが、このPDB設定は満たされることがありません。GKEの場合にはノードプールのアップグレード時に1時間の猶予時間があります。逆に言えば、PDBが1時間の間満たせなければ強制的に削除され、新たなノードにスケジュールされるまでの間ダウンタイムとなります。ちなみに、これはサポートが担当するダウンタイム関連の調査でとてもよく見る問題です。
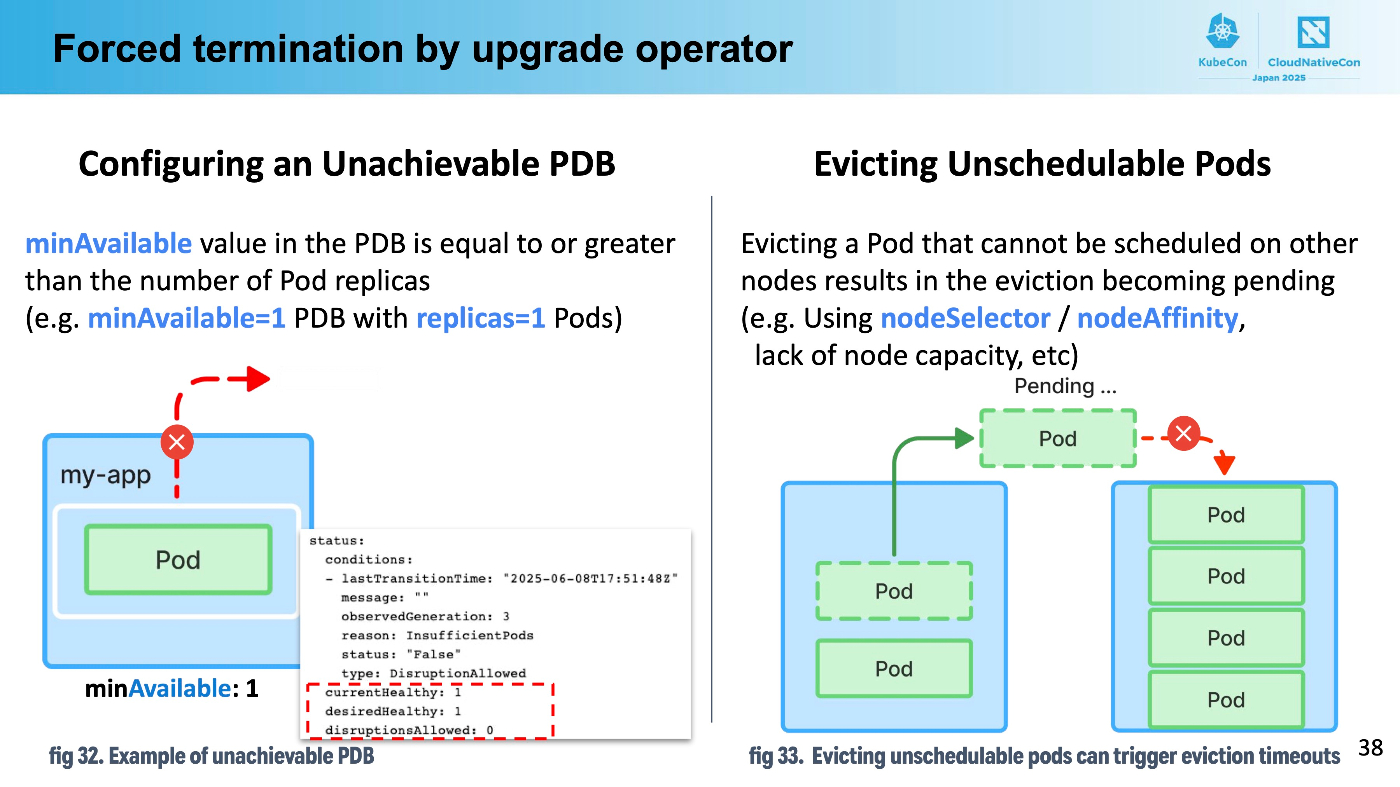
よりダウンタイムにセンシティブなワークロードでは適切にアプリケーションを停止しなければ接続がタイムアウトしたり、コネクションが強制的に切断されるクライアントが発生してしまいます。
この理解はとても難しいですが、削除開始時に「これから確立される接続」、「既に確立されている接続」に分けて考えることが重要です。紙芝居形式で実際のセッションでは説明しているので、実際のセッションの録画の方がわかりやすいですが、以下の二点を分けて押さえることが重要だと思います。
-
これから確立される接続:
Podの削除と同時にルーティングが止まるわけではなく、各ノードのkube-proxy等にPod削除に伴うエンドポイント情報の更新情報が伝搬してから、kube-proxyがiptablesのルールを変更してから新規のルーティングが止まるため少しのタイムラグが生じます。これはpreStop等でsleepしてkube-proxyのルール伝搬を待つ必要があるとされる主な理由です。 -
すでに確立した接続: 既に
TCP等として接続は確立しているものの、Pod内のコンテナがキルされてしまうと接続が切れてしまいます。コンテナの終了時に接続中のソケットが閉じるまで待ってあげるような変更がアプリケーションに必要でしょう。ただし、新規接続から一定時間以内に必ずレスポンスができるという仮定であれば、preStopでsleepして待てばこの問題も対処できます。

当日触れることのできなかったより深い内容
ここからは、当日触れることができなかったものの、本来は触れたかった話を少し紹介します。
preStopのsleepは万能ではない
preStopにsleepを追加するアイデアは様々なネット上の記事で触れられています。
これは、前提として「すべての接続は一定時間以内に閉じる」が仮定できる範囲内で有効です。例えば、長い接続を維持するWebSocketだったり、NAT超えができないクライアントがWebRTCを行うために仲介するために使われるTURNなどが用いられている場合には、クライアントが具体的にどの程度そのセッションを必要としているのかの長さにより接続のライフタイムが変化してしまうため、多くの場合で一定時間の限度の線を引くことができずsleepは有効ではありません。
また、他にも長いコネクションが意図せず使われていることを忘れがちなケースもあります。
HTTP 1.1 Keep-Alive
Keep-AliveなHTTPヘッダが付与されている時、クライアントはしばらくの間接続を保持してしまいます。HTTP1.1の場合にはサーバ側から接続をグレースフルに切ることはできないので、
-
Keep-Aliveのタイムアウト時間以上の間、Podの削除後からコンテナの終了を待つ -
Podの削除開始後リクエストがクライアントから来た場合には、Connection: closeのレスポンスヘッダで応答し、クライアントが次回接続時に別のソケットを貼るようにさせる
の二点を押さえる必要があります。これはpreStopのsleepでは対応できません。SIGTERM後、Connection: closeの応答をサーバ側ではじめ、Keep-Aliveのタイムアウト時間だけ待ってアプリケーションプロセスを終了させる必要があります。
HTTP2(特にgRPC)
HTTP2ではデフォルトでソケットを維持します。しかし、サーバ側からフレームを送ることができるので、HTTP 1.1のKeep-Aliveよりも若干フローはシンプルで、SIGTERM受信後接続中のクライアントにGOAWAYフレームを送ることによりクライアント側の接続を閉じさせることで実現できます。これはgRPCを活用されている方が、意図せずHTTP2で動いているのを忘れていて問題に遭遇することもよく見ます。
でも現実的には...
HTTP 1.1のKeep-Aliveのケースや、HTTP2のケースを適切にアプリケーションレベルでハンドルして、1リクエストも落ちないようにするのはとても大変です。Webサーバ実装時に用いるライブラリ等によっても SIGTERM受信後の挙動が異なっていることもあり、アプリケーションレベルでの対応はとても骨が折れる作業です。
Istioなどのサービスメッシュを利用している場合には、こういったことを考慮したコネクションドレインといった機能が利用可能である場合が多いです。
Statefulなワークロードはどうしたら良い
ステートフルなワークロードである以上、それ単体でゼロダウンタイムは実現することができません。基本的には「Statefulワークロードそのもののダウンタイムを短くする」、「ステートレスなワークロードでリトライし、ユーザにダウンタイムを表出させない」という二つのアプローチの組み合わせになります。
Statefulなワークロードそのもののダウンタイムを短くする
そのアプリケーション自身がHA構成をサポートしているなら、その設定を用いてダウンタイムを短くすべきです。DBなどのステートフルなワークロードでは、多くの場合、フェイルオーバー関連の何らかの設定でハートビートの間隔を構成するなどして発生しうるダウンタイムの長さを短くすることができるかもしれません。
アプリケーション自身がHA構成ではないなら、Kubernetes上ではセッション中で解説したコントロールプレーンのコンポーネントにおけるLeaseリソースを用いたHAと同様に自身でLeaseリソースを用いてリーダー選出をアプリケーション側に実装してHA構成にすることが可能です。
GoでKubernetes APIをいじる時に用いられるclient-goでは、リーダー選出用のユーティリティが定義されています。
また、GKEであれば、ステートフルなワークロードだけノードプールを切って、Blue/Greenアップグレードをノードプールで有効にし、ある程度マニュアルでワークロードを削除するのも良いでしょう。Blue/Greenアップグレードではノードのドレイン時の一時間のタイムアウトの制約は生じません。
そこで、例えばデータベース等であれば、先にreadレプリカだけ削除し、アップデート後の新しいノードにスケジュールさせ、readレプリカをリーダーに昇格させてから古いノードプールにいるデータベースを終了させるといったマニュアル操作が時間的余裕を持って可能になります。よくあるオペレーションであるならば、カスタムコントローラを作って自動化するのもありかと思います。
ステートレスなワークロードでリトライし、ユーザにダウンタイムを表出させない
ステートフルなワークロードがクライアントから直接見えるWebサーバなどとして振る舞うなどするべきではありません。ステートレスなWebサーバから、こういったステートフルなアプリケーションに接続することにより、リトライをユーザ側ではなくステートレスなWebサーバ側で行うことができます。
ユーザ視点でのレイテンシは、あくまでステートフルなワークロードのダウンタイムの長さによりますが、まずダウンタイムがレイテンシとして出る状態にまでしておき、この後でダウンタイムを短くするようなチューニングをしていくことになるでしょう。
externalTrafficPolicy: Local と type:Loadbalancer なService
externalTrafficPolicyをLocalにすることで接続元のIPを保持したいというケースはよくありますが、これとtype: Loadbalancerが重なるとゼロダウンタイムを実現するのが難しくなります。
最後に難易度の高いケースとして、externalTrafficPolicy: Localかつ、type: Loadbalancerな場合の事例を考えてみましょう。
きっとこれでゼロダウンタイム...???
type: LoadbalancerなLBをGKE上で作成すると、ロードバランサ(LB)のバックエンドがノードそのものになることはご存知でしょうか? GKEのIngressやGatewayなどでは、Container native load balancingにより、LBのバックエンドがPodのIPそのものになります。
一方、type:Loadbalancerな ServiceによりプロビジョニングされるLBでは、バックエンドはNodeです。つまり、LBのIP宛のリクエストは、LBでいずれかのReadyなノードのIPとNodePortに向けられ、ノード内のkube-proxyにより構成されるiptablesにより、対象のPodIPに変換されます。
では、externalTrafficPolicy: Localである場合、LBはどのような基準であるノードがReadyであると知るのでしょうか?
実は、externalTrafficPolicy: Localの場合、Serviceはspec.healthCheckNodePortにあいているポートを割り当てます。kube-proxyが使われている場合には、このkube-proxyがヘルスチェックに応答するようになります。externalTrafficPolicy: Localの場合には、そのノードに宛先のPodが存在しない場合にはリクエストは到達しないため、kube-proxyはPodがそのノードに存在しない場合にはこのhealthCheckNodePort宛のリクエストに対して失敗応答を返します。

もう少し深掘りしてみましょう。このヘルスチェックの挙動とルーティングの挙動は KEP-1669 Proxy Terminating Endpointsに記載されています。
kube-proxyはヘルスチェック時に、同一ノードで稼働中のPodがすべてterminatingである場合に、失敗応答をします。このため、十分な時間経過後、Podが削除されるノードではリクエストがLB側からは来なくなります。一方、LBとKubernetesは独立して動作していますので、現在のヘルスチェックの応答が変わったからといってLB側が実際にそのヘルスチェックポートにアクセスしてノードがReadyではないと知るのに時間がかかります。
このため、(LBのヘルスチェックのサイクルあたりの時間)x(LBの失敗回数閾値)時間だけはSIGTERMの送信後待つ(もしくはpreStopでsleepで待つ必要があります)
この構成であればPodを削除した際、コンテナが応答できなくなる前にノードのヘルスチェックが落ちる方が先に来るはずなので、ゼロダウンタイムが実現できる...?と思うかもしれません。
同一ノード上の2つ以上のPodがほとんど同時刻にterminatingになる場合
externalTrafficPolicy: Localの構成で重要なのは実際にはLBのヘルスチェックへの応答とkube-proxyのルーティングの動作の両方になります。LBのヘルスチェックの間隔とkube-proxyがエンドポイントの状態変化に気がつくタイミングは一致しないので、実際にはノード上の対象ServiceのPodがすべてterminating状態となってもしばらくの間LBはノードまでリクエストを送り続けてしまいます。これに対処するためにterminatingなPodであるから、kube-proxyはリクエストをそのノード上でルーティングしないというわけではありません。
KEP-1669 によれば
-
externalTrafficPolicy: Localかつ、ノード上で稼働する一部のPodがterminatingである場合:kube-proxyはterminatingではない、ReadyなPodにリクエストをルーティングします。 -
externalTrafficPolicy: Localかつ、ノード上で稼働するすべてのPodがterminatingである場合:kube-proxyはterminatingでReadyなPodにランダムにリクエストをルーティングします。
一見、preStopでLBのヘルスチェック間隔よりも長く待つことができれば、この仕様によってすべてのPodがterminatingである状態のノードにリクエストが来てしまっても、kube-proxyがひとまずpreStop中のPodにリクエストを流せるように思えるかもしれません。
しかし、同一のノード上の同一のServiceを提供するPodがほとんど同時期に削除される場合、LBのヘルスチェック間隔を十分に待つsleepをpreStopに入れてもダウンタイムを防げません。
例えば、以下のようなケースを考えます。(LBのヘルスチェックは図の都合上、等間隔ではありませんが、実際には同一間隔でヘルスチェックが行われていると考えてください)

Pod Aの方が少し早く削除開始され、Pod Bがそれに続いて削除されます。お互いにpreStopでsleepをしている時、Pod Aの削除後、Pod Bが削除開始されるまではkube-proxyはヘルスチェックにReady応答をします。すると、Pod AはすでにpreStopのsleep期間が終わり、SIGTERMを送信されていて、Pod BはpreStopのsleepの時間というタイミングが生じます。
このタイミングでkube-proxyにリクエストが到達すると、kube-proxyはPod AもPod BもterminatingかつReadyなので、Pod Aに50%の確率でリクエストを振り分けることになります。
しかし、Pod AはすでにSIGTERMが送信されており、いつサーバが停止してもおかしくありません。
この状況下ではリクエストがドロップしてしまう可能性が存在します。
どうすれば良いのか?
一番簡単な解決法は、externalTrafficPolicy: LocalなServiceのバックエンドのPodを同一ノードにスケジュールさせないです。podAntiAffinityやtopologySpreadConstraintsを用いてPodを分散させれば、そもそも同一ノードに複数の同一Serviceに応答するPodが存在しないため、このような複雑な状態は生じません。また、この場合においてもLBのヘルスチェックの時間を十分待つため、preStopにおけるsleepは必要です。
次に考えられる方法はkubelet側のReadinessProbeを落とす方法です。
-
Podの削除開始 - 1から
LBのHCが落ちるために必要な時間は停止処理をしない。また、この間ReadinessProbeにはReadyな応答を続ける。 - 2から
kubeletのReadinessProbeがPodをNot Readyと判定するまでの時間、ReadinessProbeを落とす。この間も終了処理をしない。 - サーバの終了処理
こうすることにより、前の例でPod AはpreStopのsleepの区間が終わった後はNot Readyとなり、kube-proxyがルーティングの対象にはならないため、Pod BがterminatingであってもPod Bのみが応答することになります。
一見、2,3を同時にやっても良いように感じますがこれもできません。Podが1つしかノードにない場合には、2,3を同時にやると、LB側のHCの結果が反映される前にノードに到達したリクエストが、Readyなエンドポイントがないことになりドロップします。
GKE特有の話
クラスタのアップグレードはシステムワークロードを含む
GKEにおけるクラスタのアップグレードを実行すると、マネージドなコントロールプレーン側のバージョンが更新されると思われますが、実際にはこれに加えてクラスタ上のシステムワークロードのDaemonSetなども更新されます。
例えば、Workload Identityを用いる時に使うgke-metadata-server DaemonSetが更新されるタイミングと、そのノード上で起動しているアプリケーションがアクセストークンを取得しようとするタイミングが重なればトークンが取得できずエラーになる可能性があります。
現実的にこれらマネージドワークロードのアップグレードがどのような影響を与えうるか知っておくのは難しいですが、何らかのエラーが起きた際にクラスタ内のシステムワークロードの更新が走っていたかどうか調査することができれば、次にそのシステムワークロードの瞬断が発生した時にユーザワークロード側でリトライなどの対策を施し問題を減らすことが可能です。このような具体的にどのようにワークロードが編集されたか知るためにはKHIを用いて監査ログを辿るのがおすすめです。
ロールアウトシーケンシング
今回のセッションの主なトピックでは一瞬生じるダウンタイムをいかにゼロにしていくかという話でした。しかし、実際のアップグレードでは、一瞬のダウンタイム以外にも、アップデートした結果古いAPIを使っていたコントローラが動かなくなってしまったなどアップグレード後のある程度継続的な問題が生じる可能性があります。事前にこのようなリスクを本番環境がアップグレードする前に知りたいですよね。また、アップグレードでどの程度のダウンタイムが生じるか、ステージング環境のアップグレード等を先に起こしたいというケースがあります。
このような場合、GKEのロールアウトの順序付けが便利です。
ロールアウトの順序付けを使用したクラスタ アップグレードについて
最後に
セッションの話に加え、より深いダウンタイムの話をしてきました。最初からこのような問題をすべて把握し、アップグレード時にゼロダウンタイムなシステムを構成するのはとても難しい作業です。
実際には、ダウンタイムを計測、原因を分析して一つ一つ削減していく必要があります。アップグレード時のゼロダウンタイムが実現できることは、迅速で安全かつタイミングを自動化可能なアップグレードにつながり、アップグレード時のオペレーションの軽減にもつながるはずです。ぜひ、日々のクラスタの運用にご活用ください。
私とGoogle Cloud Japanのサポートチームが主として開発しているKHIはこのようなさまざまなダウンタイムの調査から生まれました。「このタイミングで何かが起きた...」というような時、「アップデートで落ちないはずなのに落ちてしまった」のように、広範なリソースを特定のタイミングに絞って網羅的に調査するのに便利です。GKEにおいては監査ログは無料ですし400日も残るとても強力なログですので活用しない手はないはず!
KHIは日本語ドキュメントもあります!
ぜひ気に入ったらリポジトリにスターを残していただければ幸いです。
あと、この子の名前が決まってないので提案お待ちしています(モグラです)

Discussion