データベース入門 ~ ブラウザ操作だけでデータベースを試してみる

TL;DR
- ブラウザ操作だけでデータベース操作入門
- Google Cloud 無料トライアルで、クラウドデータベースを無料でお試し
はじめに
こちらの記事は、初めてデータベースを学ぶ方のために、ブラウザ上の操作だけで無料でデータベースを触りながら学んでいただける学習資料として記載しました。
今回は ご自身のGoogle アカウントで無料で利用できる、Google Cloud の無料トライアルを利用して、PostgreSQL データベースを試す手順を記載していこうと思います。
PostgreSQL を最初に学ぶ理由
まずはここで、PostgreSQL について簡単に紹介したいと思いますが、「小難しい話は嫌い!」という方はこの節は読み飛ばしていただいて大丈夫です。
今回 PostgreSQL を教材として選択したのは(私の推し DB というのも一つの理由ですが)、下記のような理由からです。
- 主流なリレーショナル データベース管理システムである
- オープンソースでありライセンスの購入などの手間が不要
- Oracleなどの商用データベースと比較しても機能が豊富
- 継続してシェアを伸ばし続けている
データベースというと、まず思いつくのは今回紹介する PostgreSQL の他、 Oracle Database や SQL Server、MySQL などのメジャーなソフトウェアですね。
これらはより正確にはリレーショナル データベース管理システム (RDBMS) と呼ばれるソフトウェアです。データベースという言葉は実際にはデータの集合を指すものとなりますが、そのデータを管理するシステムという意味です。
また データべースをリレーショナルモデル という、汎用的で現在最も主流なデータモデルに基づいて構成しているので、リレーショナル データベース管理システム と呼ばれています。
その他にも キー バリュー ストアやドキュメント データベースなど、NoSQL や 非リレーショナル データベース とよばれるデータベースも最近利用を伸ばしています。有名な実装としては Bigtable や MongoDB、Redis や Apache Cassandra などが挙げられます。もちろんこれらの DB も使いこなせば、とても便利なデータベースですが、今後も引き続き主流なデータベースとしてリレーショナル データベースが使われ続ける点は変わらないかと思います。
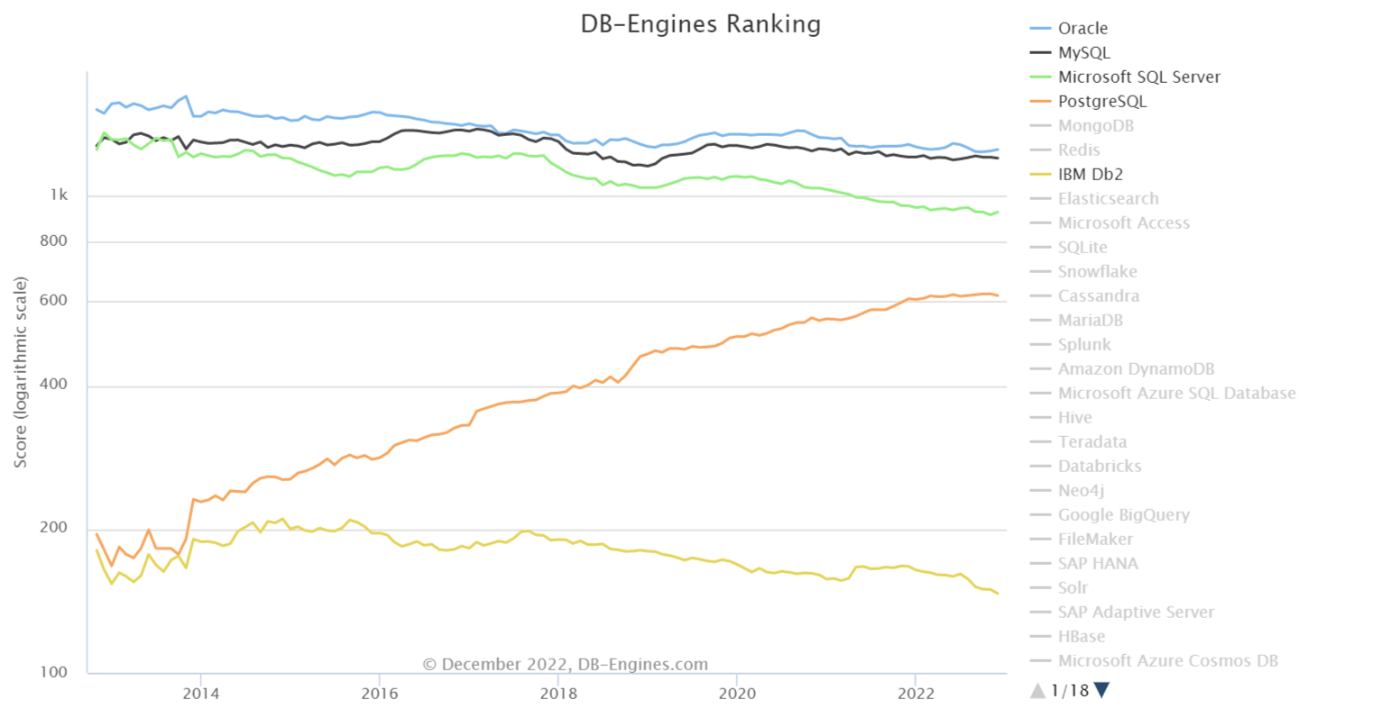
DB-ENGINES というサイトでは、独自のデータベース人気ランキングを公表していますが、主流なRDBMS のなかで PostgreSQL が唯一スコアを伸ばし続けています。
Google Cloud 無料トライアル への登録
まずは Google Cloud の無料トライアルへ登録をしましょう。Google アカウントとクレジットカードがあれば、90 日間 $300 分まで無料でGoogle Cloudの環境を利用することが出来ます。クレジットカードの登録が必要ですが、実際の利用登録(アップグレード)操作をするまでは、カードに課金されることはないので安心して $300 分ギリギリまでお試し出来るのも嬉しい点です。
Google アカウントをお持ちでない場合には、まずはこちらのサイトを参考にして作成しましょう。
Google Cloudへのアクセス
Google Cloud (https://console.cloud.google.com/) へアクセスします。
Google アカウントへログインをしていない場合には、ログインが求められます。
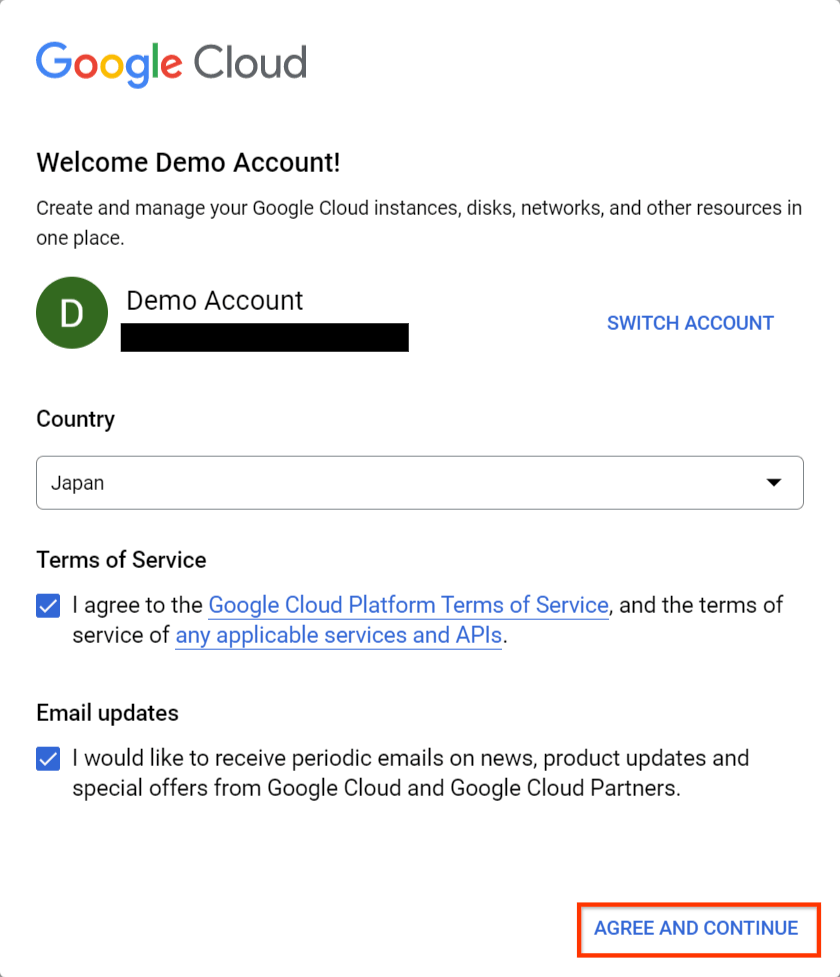
最初に下記のようなダイアログが表示されるので、Terms of Service を確認して、 [AGREE AND CONTINUE] をクリックします。
無料トライアルの有効化
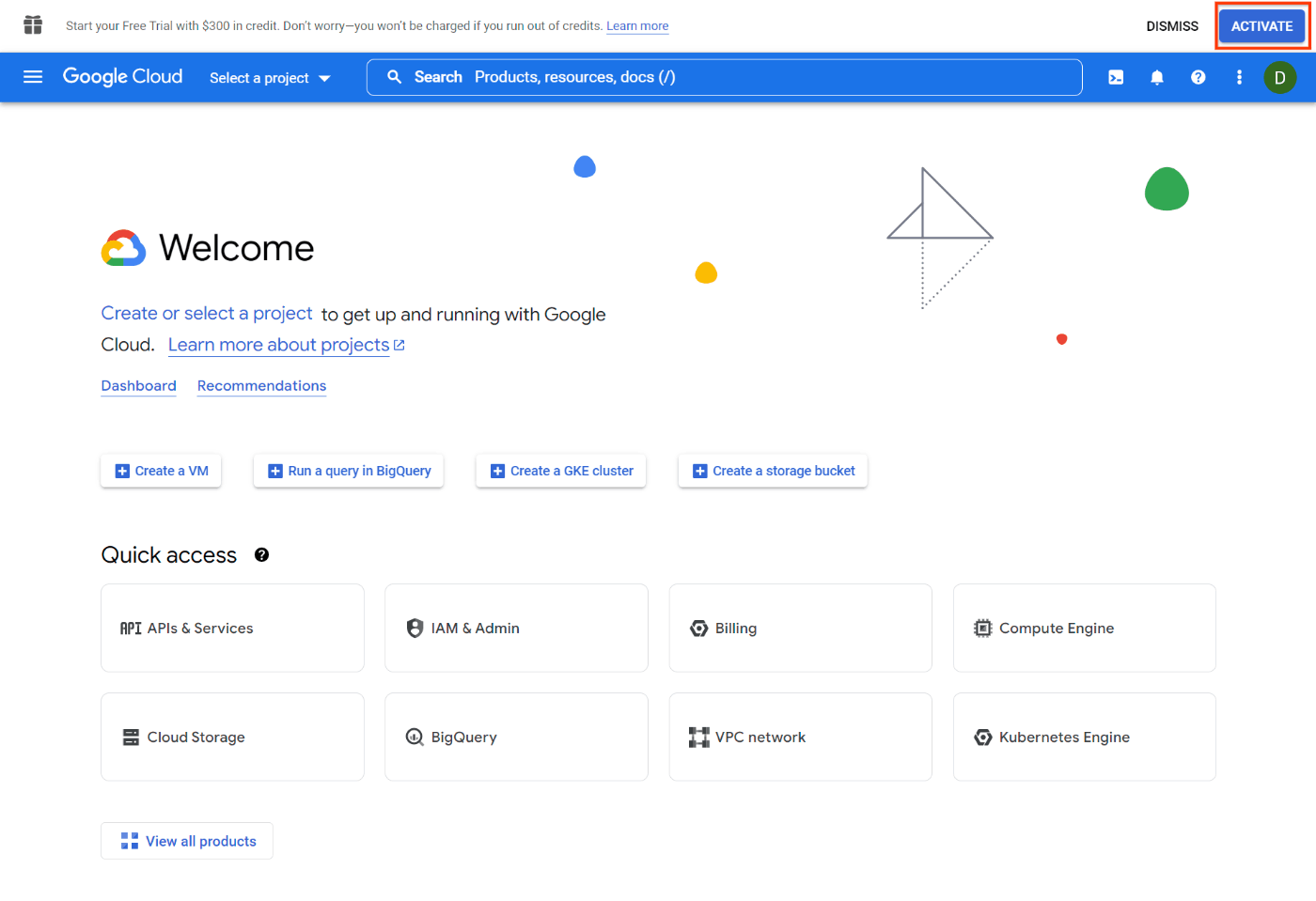
Google Cloud コンソールが表示され、上部に無料トライアルを有効化するためのボタンが表示されるので、[ACTIVATE] をクリックします。
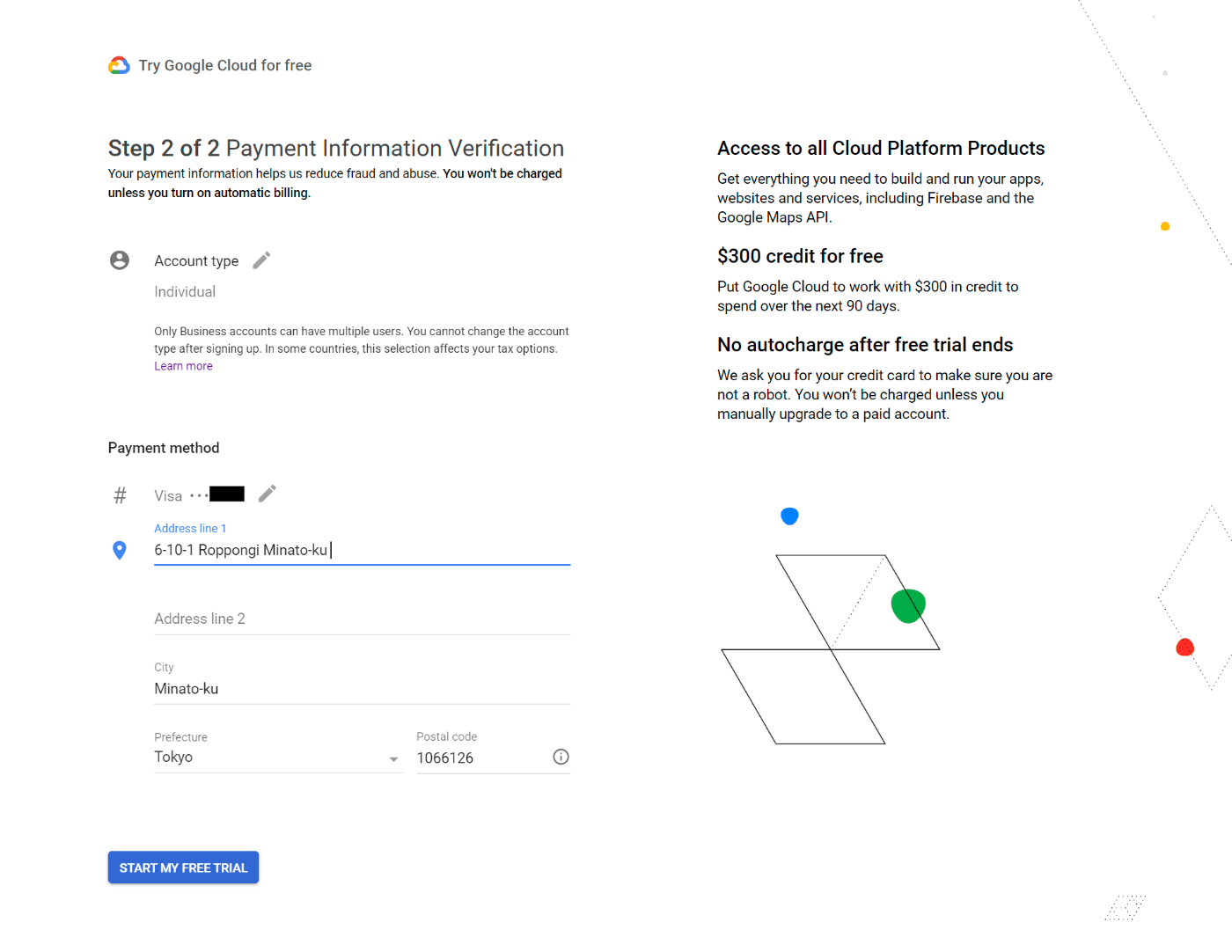
次にアカウント情報と、クレジットカード情報、住所を入力すれば、無料トライアルへの登録の完了です。

簡単なアンケートの入力フォームが出てくるので、こちらへも回答します。
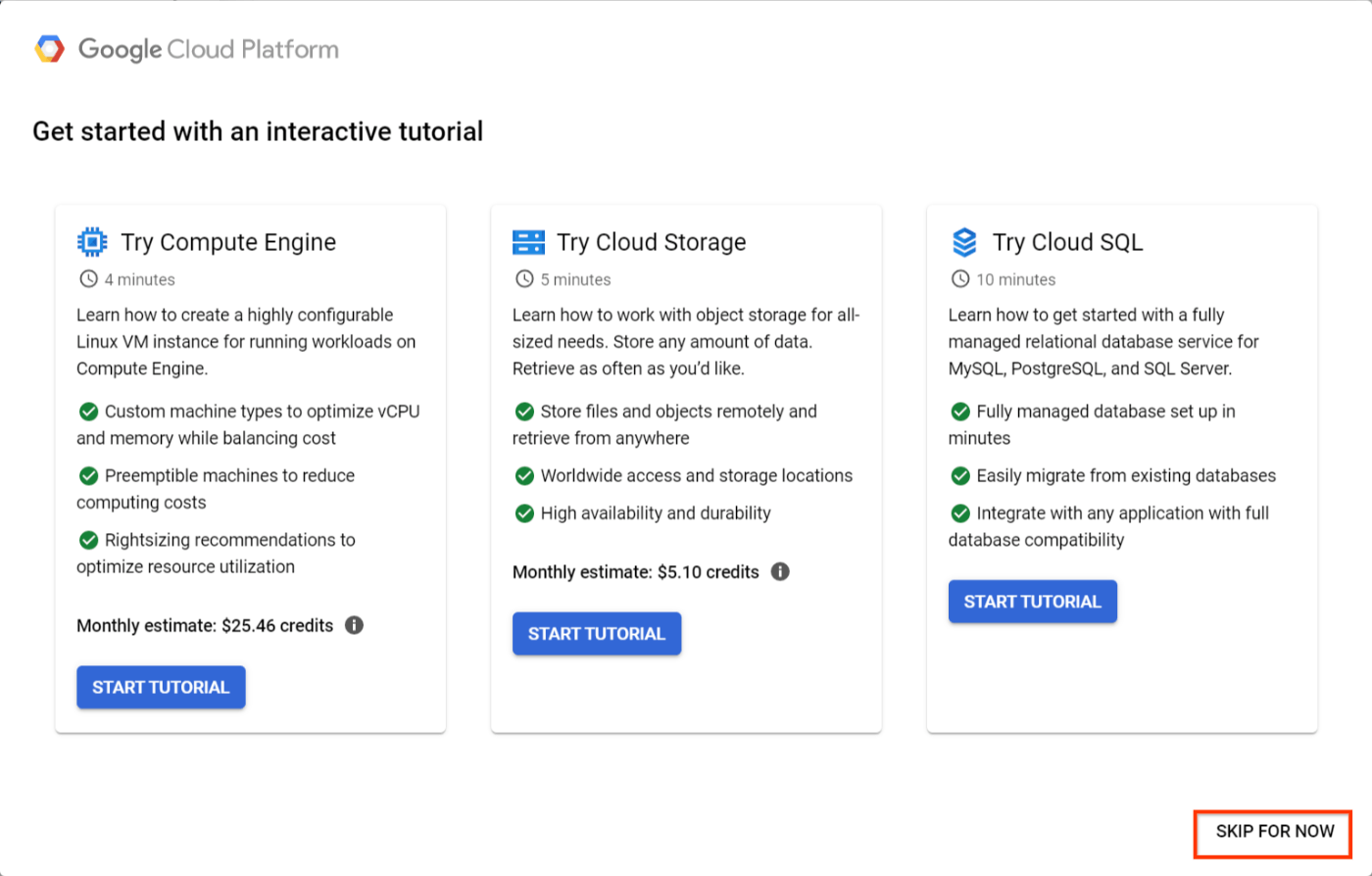
チュートリアルの案内が出てきます。[SKIP FOR NOW] を選択すると、チュートリアルをスキップできます。
コンソールの日本語化
これで無料トライアルへの登録は完了ですが、コンソールが英語表示のままになっているのは不便ですね。設定から日本語表示に変更しましょう。
右上の3つのドットが並んだボタンから [Preferences] を選択します。
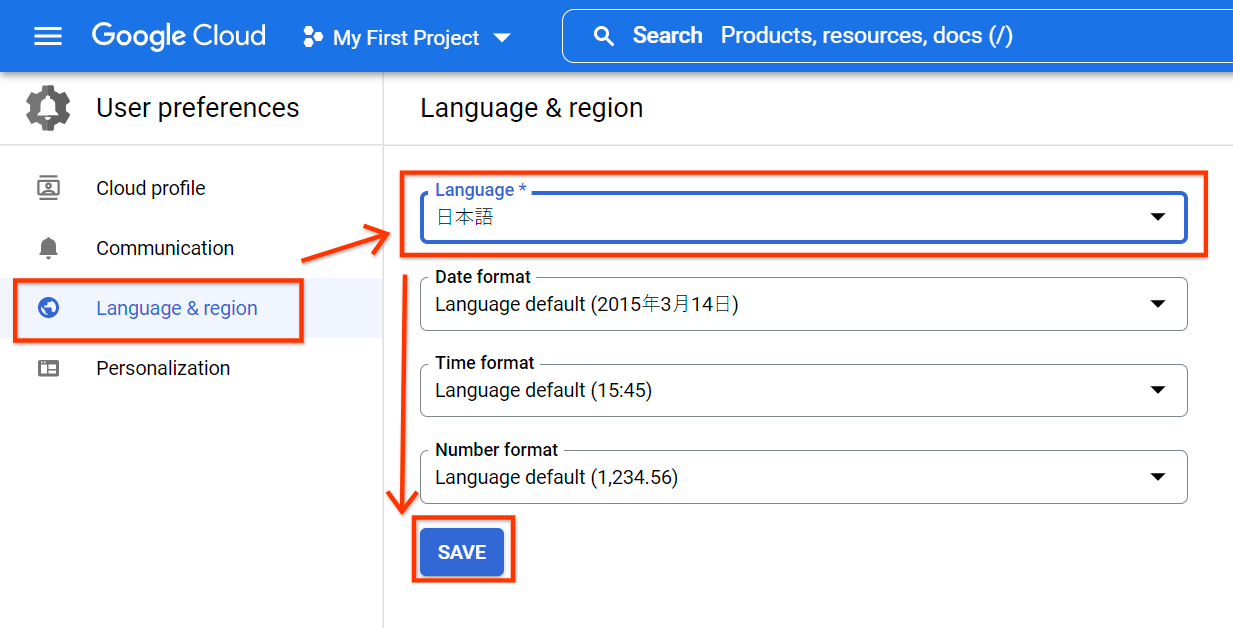
[Language & region] を選択、[Language] を “日本語” に変更、[SAVE] ボタンをクリックすると、コンソールが日本語に変更されます。
PostgreSQL (Cloud SQL for PostgreSQL) の起動
これで Google Cloud を利用する準備ができたので、早速 PostgreSQL を起動してみましょう。
左上のハンバーガーメニューをクリックすると、Google Cloud のサービスメニューが表示されるので、”SQL” というメニューをクリックしてください。
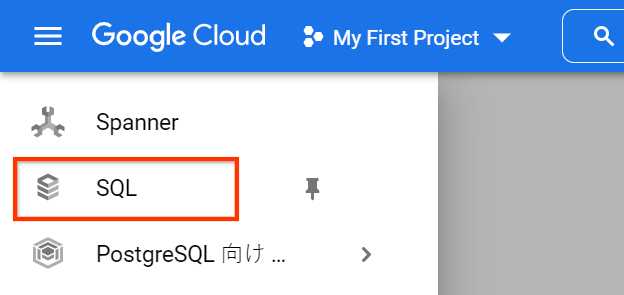
(もしかすると下記のメニューの下に隠されているかもしれません。 )

[インスタンスを作成]を選択します。
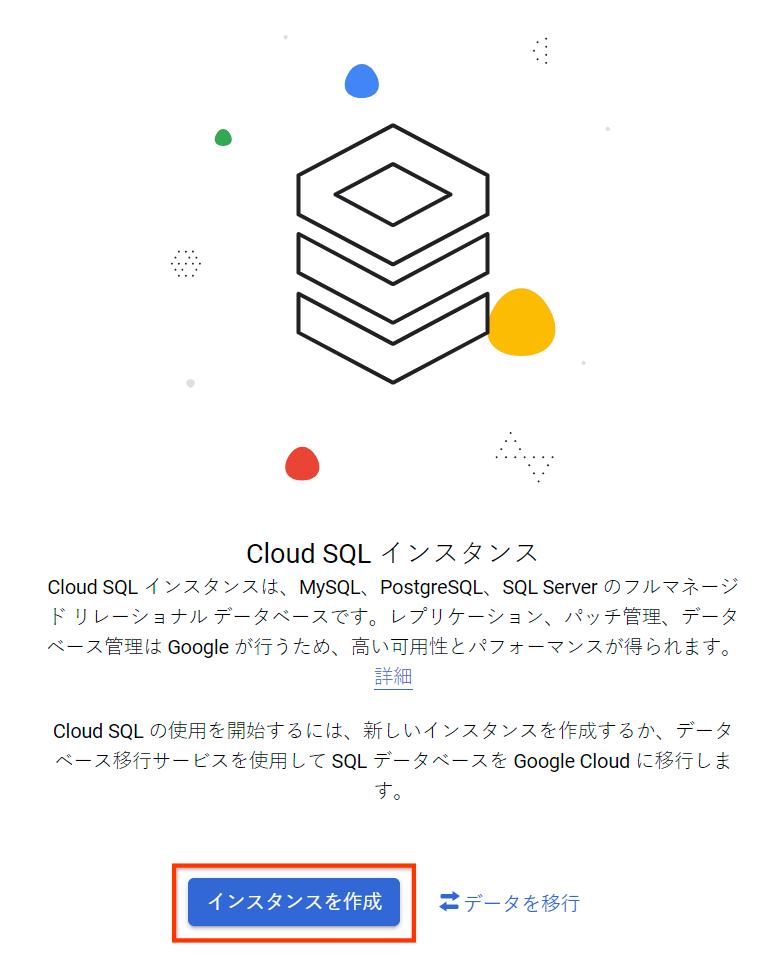
データベースの選択画面では、PostgreSQL を選択しましょう。

[APIを有効にする] を選択します。

次に作成するCloud SQL インスタンスの情報を入力します。
[インスタンスID] はインスタンスの名前となるので、管理しやすい名前を選択しましょう。迷ったら例と同じ ”instance1” で大丈夫です。
[パスワード] はインスタンスへログインするときのパスワードです。忘れてしまうとログインができなくなるので、忘れずにメモをしておきましょう。[生成] を押すと自動的に強固なパスワードを生成してくれるますが、[パスワードを表示する](目のボタン) を押して生成されたパスワードをメモしておくことを忘れないようにしてください。

[データベースのバージョン] は PostgreSQL 14 のままとしましょう。
[最初に使用する構成の選択] では Development を選択します。

[リージョン] では、インスタンスを配置するロケーションを選択できます。[us-central1(アイオワ)] のままで問題ありません。配置するリージョンで料金が変わるため、料金の安いアイオワを選択することで、$300 の無料枠を有効に利用します。
[ゾーンの可用性] も料金を抑えるため、[シングルゾーン]のままとします。

今回のお試しでは、マシンタイプも最も安価な構成で問題ないので、[共有コア] > [1 vCPU、0.614 GB]を選択します。

[ストレージ容量] も標準の 100GB は大きすぎるため、10 GB へ調整します。

[削除からの保護の有効化] のチェックを外します。

最終的に下記のような構成概要となりました。

最後に [インスタンスを作成] を選択します。

インスタンスの作成が開始されると、右下に下記のようなダイアログが表示されます。

ここまででデータベースの環境の準備は完了です!
インスタンスの作成まで暫く掛かるので、一度休憩しましょう。
インスタンスの作成が完了すると、下記のようなダイアログが表示されます。

データベースを学ぶ
接続
それではデータベースに接続してみましょう。
データベースへの接続のためにはクライアントを準備する必要がありますが、ここでは簡単に利用できる Google Cloud の Cloud Shell をクライアントとして利用します。
右上の Cloud Shell 有効化ボタンを押してください。

すると画面下に Cloud Shell が起動します。最初にダイアログが表示されるので [続行] を選択します。

Cloud Shell のターミナル画面が下記のように起動します。

データベースへの接続には、gcloud sql connect コマンドを使います。
$ gcloud sql connect instance1
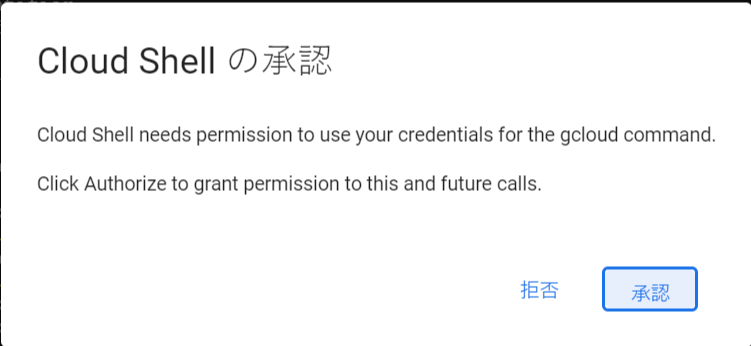
Cloud Shell で gloud コマンドを実行すると最初に下記のようなダイアログが表示されるため、[承認] を選択します。
次に API [sqladmin.googleapis.com] の有効化 の確認を求められるので、 “y” を入力します。
API [sqladmin.googleapis.com] not enabled on project [2xxxxxxx879]. Would you like to enable and retry (this will take a few minutes)? (y/N)? y
インスタンス作成時に指定したパスワードを入力します。
(パスワードを忘れてしまった場合には、こちらの手順 で新しいパスワードを設定できます。)
Enabling service [sqladmin.googleapis.com] on project [2xxxxxxx879]...
Operation "operations/acat.p2-2xxxxxxx879-15b9af7b-2bc7-4cfe-870b-94094ee4c02f" finished successfully.
Allowlisting your IP for incoming connection for 5 minutes...done.
Connecting to database with SQL user [postgres].Password: [パスワード]
PostgreSQL へ無事にログインできると、下記のようなプロンプトが表示されます。
psql (15.1 (Debian 15.1-1.pgdg110+1), server 14.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
postgres=>
この後の操作はデータベースへ接続した状態で行いますが、データベースへの接続を終了したいときには、\q コマンドを入力します。操作を再開したいときには改めてデータベースへ接続しましょう。
postgres=> \q
$
データベースの作成
PostgreSQL インスタンスの中には、複数のデータベース (データの集合) を作成することが出来ます。
試しに接続したインスタンスの中のデータベースを \l コマンドでリストしてみましょう。
postgres=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges
---------------+-------------------+----------+------------+------------+------------+-----------------+-----------------------------------------
cloudsqladmin | cloudsqladmin | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
postgres | cloudsqlsuperuser | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
template0 | cloudsqladmin | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc | =c/cloudsqladmin +
| | | | | | | cloudsqladmin=CTc/cloudsqladmin
template1 | cloudsqlsuperuser | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc | =c/cloudsqlsuperuser +
| | | | | | | cloudsqlsuperuser=CTc/cloudsqlsuperuser
(4 rows)
既に複数の管理用のデータベースが作成されている状況が確認できます。
今回は CREATE DATABASE 文でお試し用データベース mydb を作成してみます。
postgres=> CREATE DATABASE mydb;
CREATE DATABASE
postgres=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges
---------------+-------------------+----------+------------+------------+------------+-----------------+-----------------------------------------
cloudsqladmin | cloudsqladmin | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
mydb | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
postgres | cloudsqlsuperuser | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc |
template0 | cloudsqladmin | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc | =c/cloudsqladmin +
| | | | | | | cloudsqladmin=CTc/cloudsqladmin
template1 | cloudsqlsuperuser | UTF8 | en_US.UTF8 | en_US.UTF8 | | libc | =c/cloudsqlsuperuser +
| | | | | | | cloudsqlsuperuser=CTc/cloudsqlsuperuser
(5 rows)
作成したデータベースを利用するために、 \c コマンドで接続します。
postgres=> \c mydb
Password: [パスワード]
psql (15.1 (Debian 15.1-1.pgdg110+1), server 14.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
You are now connected to database "mydb" as user "postgres".
mydb=>
接続先データベースが変わると、プロンプトも接続したデータベースの名前に変わります。
もしデータベース接続が切断し、再度接続しなければならないときには、下記のコマンドで mydb へ直接接続できます。
$ gcloud sql connect instance1 --database mydb
テーブルの作成
リレーショナル データベースでは、データを下記のサンプルデータのような行と列で構成されるテーブルの形式で格納します。
| Employee ID | First Name | Last Name | Birthday | Department | |
|---|---|---|---|---|---|
| 1001 | Taro | Yamada | tyamada | 2001/12/10 | Sales |
| 1002 | Toshio | Tanaka | ttanaka | 2012/2/1 | Engineer |
| 1003 | Reina | Ishii | rishii | 1998/6/9 | HR |
データを格納するためには、まずは箱であるテーブルを先に作成する必要があります。
リレーショナル データベースでは操作のために、SQL と呼ばれる言語が一般的に用いられます。SQL は利用される RDBMS 間で多少の方言がありますが、PostgreSQL で用いられる SQL 言語の詳細は マニュアル で確認できます。
サンプルデータを格納するためのテーブルとして、テーブル employees をCREATE TABLE 文で作成してみましょう。
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(10),
last_name VARCHAR(10),
email VARCHAR(50),
birthday DATE,
department VARCHAR(50)
);
mydb=> CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(10),
last_name VARCHAR(10),
email VARCHAR(50),
birthday DATE,
department VARCHAR(50)
);
CREATE TABLE
mydb=>
CREATE TABLE では、テーブル名と列名の他に、各列のデータ形式を指定する必要があります。
例えば INT は整数型、VARCHAR(50) は 50 文字を上限とする文字列型、DATE は日付型と言った具合です。
作成されたテーブルは \dt コマンドで確認ができます。
mydb=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------+-------+----------
public | employees | table | postgres
(1 row)
データの挿入
作成したテーブルへのデータの挿入は、INSERT 文を利用します。
ここで VARCHAR 型 と DATE 型 の列の値は、文字列で指定するため、シングルクォートで囲む必要があることに気をつけてください。
INSERT INTO employees VALUES
( 1001, 'Taro', 'Yamada', 'tyamada', '2001-12-10', 'Sales');
mydb=> INSERT INTO employees VALUES
( 1001, 'Taro', 'Yamada', 'tyamada', '2001-12-10', 'Sales');
INSERT 0 1
挿入したデータは、SELECT 文で見ることが出来ます。
mydb=> SELECT * FROM employees;
employee_id | first_name | last_name | email | birthday | department
-------------+------------+-----------+---------+------------+------------
1001 | Taro | Yamada | tyamada | 2001-12-10 | Sales
(1 row)
残り2つのデータも挿入してしまいましょう。
mydb=> INSERT INTO employees VALUES
( 1002, 'Toshio', 'Tanaka', 'ttanaka', '2012-02-01', 'Engineer'),
( 1003, 'Reina', 'Ishii', 'rishii', '1998-06-09', 'HR');
INSERT 0 2
mydb=> SELECT * FROM employees;
employee_id | first_name | last_name | email | birthday | department
-------------+------------+-----------+---------+------------+------------
1001 | Taro | Yamada | tyamada | 2001-12-10 | Sales
1002 | Toshio | Tanaka | ttanaka | 2012-02-01 | Engineer
1003 | Reina | Ishii | rishii | 1998-06-09 | HR
(3 rows)
検索
データベースでは、単にテーブルの中身を見るだけではなく、より詳細な条件を指定した検索をすることが出来るのも一つの特徴です。
例えば、Tanaka さんの First Name を検索したい場合には、下記のように WHERE 句の後に条件を指定することで、特定の情報だけを抜き出すことが出来ます。
SELECT first_name -- First name だけ表示
FROM employees -- employees テーブルを検索
WHERE last_name = 'Tanaka' -- Last name が Tanaka さんのデータを探す
; -- ここで SQL 終了
mydb=> SELECT first_name -- First name だけ表示
FROM employees -- employees テーブルを検索
WHERE last_name = 'Tanaka' -- Last name が Tanaka さんのデータを探す
; -- ここで SQL 終了
first_name
------------
Toshio
(1 row)
次の例は、誕生日が 2002-01-01 より前の従業員のメールアドレスを検索する SQL 文です。
SELECT email -- EMail だけ表示
FROM employees -- employees テーブルを検索
WHERE birthday < '2002-01-01' -- 誕生日が 2002-01-01 より前のデータを探す
; -- ここでSQL終了
mydb=> SELECT email -- EMail だけ表示
FROM employees -- employees テーブルを検索
WHERE birthday < '2002-01-01' -- 誕生日が 2002-01-01 より前のデータを探す
; -- ここで SQL 終了
email
---------
tyamada
rishii
(2 rows)
更新 削除
テーブル上のデータは、更新や削除を行うこともできます。
例えば Employee ID 1003 の Reina さんの First name が、実は Reika さんだったことに、テーブルへの挿入後に気づいたとしましょう。そのような場合には、UPDATE 文を用います。
UPDATE employees -- employees テーブルを更新
SET first_name='Reika' -- First name を Reika へ変更
WHERE employee_id=1003 -- Employee ID 1003 のレコードを更新
; -- ここで SQL 終了
mydb=> UPDATE employees -- employees テーブルを更新
SET first_name='Reika' -- First name を Reika へ変更
WHERE employee_id=1003 -- Employee ID 1003 のレコードを更新
; -- ここで SQL 終了
UPDATE 1
mydb=> SELECT employee_id, first_name FROM employees;
employee_id | first_name
-------------+------------
1001 | Taro
1002 | Toshio
1003 | Reika
(3 rows)
また Employee ID 1002 の Tanaka さんが退職をしたために、テーブルから Tanaka さんのデータを削除しなければならないとしましょう。そのような場合には、DELETE 文を用います。
DELETE FROM employees -- employees テーブルからデータを削除
WHERE employee_id=1002 -- Employee ID 1002 のレコードを削除
; -- ここで SQL 終了
mydb=> DELETE FROM employees -- employees テーブルからデータを削除
WHERE employee_id=1002 -- Employee ID 1002 のレコードを削除
; -- ここで SQL 終了
DELETE 1
mydb=> SELECT * FROM employees;
employee_id | first_name | last_name | email | birthday | department
-------------+------------+-----------+---------+------------+------------
1001 | Taro | Yamada | tyamada | 2001-12-10 | Sales
1003 | Reika | Ishii | rishii | 1998-06-09 | HR
(2 rows)
トランザクション
例えば4月に下記のような複数の人事があったとしましょう。
- 従業員2人入社
- Taro Yamada さんがMarketing部門に異動
- Reika IshiiさんがSales部門に異動
これらの操作を行うには、下記のように複数のSQL 文を実行しなければなりません。
INSERT INTO employees VALUES
( 1004, 'Kana', 'Nakada', 'knakada', '2008-10-09', 'HR'),
( 1005, 'Dai', 'Ishiki', 'dishiki', '1980-03-20', 'Engineer');
UPDATE employees SET departmnt='Marketing' WHERE employee_id=1001;
UPDATE employees SET department='Sales' WHERE employee_id=1003;
ところで上記の SQL には一つ誤りがあるのですが、お気づきになりましたか?そうです。2番目の処理の UPDATE 文の中で、部署列の名前が department であるところ、departmnt と記載されてしまっています。
もしこの SQL 文を実行した場合、途中でエラーが発生して、1番目の処理だけ終えて止まってしまいます。
エラーが発生した事に気づいたあなたは、SQL を修正して改めて処理を実行しますが、正常に実行された INSERT 文を改めて実行するとデータが重複してしまいますので、2番目以降の処理から開始しなければなりません。
今回は3行だけなのでそこまで複雑な処理ではないですが、大規模な組織ではより多くのSQLの実行が必要となり、スクリプトファイルなどで一辺に実行したいと思うかもしれません。エラーが発生するたびにスクリプトファイルを修正して再実行するのは手間です。
また中途半端に更新された従業員データが社内で参照されることで、問題が発生する可能性もあります。
このような状況を防ぐために、リレーショナルデータベースではトランザクションという機能が提供されています。
下記がトランザクション機能を用いた SQL の例となりますが、先程の SQL を BEGIN と COMMIT で囲っています。
BEGIN;
INSERT INTO employees VALUES
( 1004, 'Kana', 'Nakada', 'knakada', '2008-10-09', 'HR'),
( 1005, 'Dai', 'Ishiki', 'dishiki', '1980-03-20', 'Engineer');
UPDATE employees SET departmnt='Marketing' WHERE employee_id=1001;
UPDATE employees SET department='Sales' WHERE employee_id=1003;
COMMIT;
こちらを実際に実行してみましょう。
mydb=> BEGIN;
INSERT INTO employees VALUES
( 1004, 'Kana', 'Nakada', 'knakada', '2008-10-09', 'HR'),
( 1005, 'Dai', 'Ishiki', 'dishiki', '1980-03-20', 'Engineer');
UPDATE employees SET departmnt='Marketing' WHERE employee_id=1001;
UPDATE employees SET department='Sales' WHERE employee_id=1003;
COMMIT;
BEGIN
INSERT 0 2
ERROR: column "departmnt" of relation "employees" does not exist
LINE 1: UPDATE employees SET departmnt='Marketing' WHERE employee_id...
^
ERROR: current transaction is aborted, commands ignored until end of transaction block
ROLLBACK
上記のように2番目の処理でエラーが発生して、処理が止まってしまいました。”INSERT 0 2” と表示されているので、1番目の処理は無事に実行されたようですね。
しかし最後に ROLLBACK と表示されています。これは何を意味するのでしょうか?
mydb=> SELECT * FROM employees;
employee_id | first_name | last_name | email | birthday | department
-------------+------------+-----------+---------+------------+------------
1001 | Taro | Yamada | tyamada | 2001-12-10 | Sales
1003 | Reika | Ishii | rishii | 1998-06-09 | HR
(2 rows)
テーブルを見てみると、SQL 実行前の状況のままです。2番目以降の処理 だけではなく、1番目の処理 の結果も反映されていないのが確認できますね。これはトランザクション内でエラーが発生したことで、トランザクション内のそれまでの処理がすべて ROLLBACK されたことを示しています。
そのためエラー原因となった SQL を修正した後は、処理の重複を心配することなく同じ処理を改めて流すことができます。
mydb=> BEGIN;
INSERT INTO employees VALUES
( 1004, 'Kana', 'Nakada', 'knakada', '2008-10-09', 'HR'),
( 1005, 'Dai', 'Ishiki', 'dishiki', '1980-03-20', 'Engineer');
UPDATE employees SET department='Marketing' WHERE employee_id=1001;
UPDATE employees SET department='Sales' WHERE employee_id=1003;
COMMIT;
BEGIN
INSERT 0 2
UPDATE 1
UPDATE 1
COMMIT
mydb=> SELECT * FROM employees;
employee_id | first_name | last_name | email | birthday | department
-------------+------------+-----------+---------+------------+------------
1004 | Kana | Nakada | knakada | 2008-10-09 | HR
1005 | Dai | Ishiki | dishiki | 1980-03-20 | Engineer
1001 | Taro | Yamada | tyamada | 2001-12-10 | Marketing
1003 | Reika | Ishii | rishii | 1998-06-09 | Sales
(4 rows)
制約
例えば従業員番号 (Employee ID) は従業員を識別するものですので、通常他の従業員と重複したり、番号が割り振られていないといった状況は許されません。このようなルールについても、データベースに対し、テーブル上のデータを挿入 更新する際のルール (制約) として設定することが出来ます。
employees テーブルの Employee ID 列に対し、ALTER TABLE 文を利用して、一意 (UNIQUE) 制約を設定してデータの重複を拒否し、NOT NULL 制約を設定して空 (NULL) のデータを拒否するように設定します。
ALTER TABLE employees
ALTER COLUMN employee_id SET NOT NULL; – NOT NULL 制約の設定
ALTER TABLE employees
ADD CONSTRAINT uq_employee_id UNIQUE(employee_id); – UNIQUE 制約の設定
mydb=> ALTER TABLE employees
ALTER COLUMN employee_id SET NOT NULL; – NOT NULL 制約の設定
ALTER TABLE
mydb=> ALTER TABLE employees
ADD CONSTRAINT uq_employee_id UNIQUE(employee_id); – UNIQUE 制約の設定
ALTER TABLE
\d コマンドを実行すると、各制約の設定状況が確認できます。
mydb=> \d employees
Table "public.employees"
Column | Type | Collation | Nullable | Default
-------------+-----------------------+-----------+----------+---------
employee_id | integer | | not null |
first_name | character varying(10) | | |
last_name | character varying(10) | | |
email | character varying(50) | | |
birthday | date | | |
department | character varying(50) | | |
Indexes:
"uq_employee_id" UNIQUE CONSTRAINT, btree (employee_id)
ここで実際に既存の Employee ID (1004) と重複した従業員情報と、空の Employee ID (NULL) の従業員情報の挿入を試してみると、ともにエラーにより失敗することが確認出来ます。
mydb=> INSERT INTO employees VALUES
( 1004, 'Dummy', 'Employee', 'dummy', '2001-01-01', 'Dummy');
ERROR: duplicate key value violates unique constraint "uq_employee_id"
DETAIL: Key (employee_id)=(1004) already exists.
mydb=> INSERT INTO employees VALUES
( NULL, 'Dummy', 'Employee', 'dummy', '2001-01-01', 'Dummy');
ERROR: null value in column "employee_id" of relation "employees" violates not-null constraint
DETAIL: Failing row contains (null, Dummy, Employee, dummy, 2001-01-01, Dummy).
データベース管理について
今回の記事では、データベース内部のデータの操作方法について学んできました。
データベースはその他に 構成変更 や バックアップ、リストア、ユーザ管理 などのデータベース管理 (DBA) の側面もあります。
今回利用した Cloud SQL のようなクラウド上で提供されているデータベースサービスでは、多くの DBA 操作が自動化されており、コンソール上からの GUI 操作で簡単に行えるようになっています。
製品マニュアルの他、下記のような動画を参考にして、クラウド データベースの管理についてもぜひ学んでみましょう。
Cloud SQL を使ってみよう! 〜管理ツールやアプリケーションからの接続 編〜
最後に
この記事を読んでいただいた皆さまがこれをきっかけに、少しでもデータベースへの理解を深めていただけたようであれば幸いです。
最後にインスタンスの削除方法についてご紹介します。Cloud SQLなど、Google Cloud上のリソースは使用時間に応じて課金されます。お試しが終わったら削除して $300 分の無料トライアルのクレジットを有効に使いましょう。
改めてコンソール左上のハンバーガーメニューから、”SQL” をクリックして Cloud SQL コンソールを開きます。
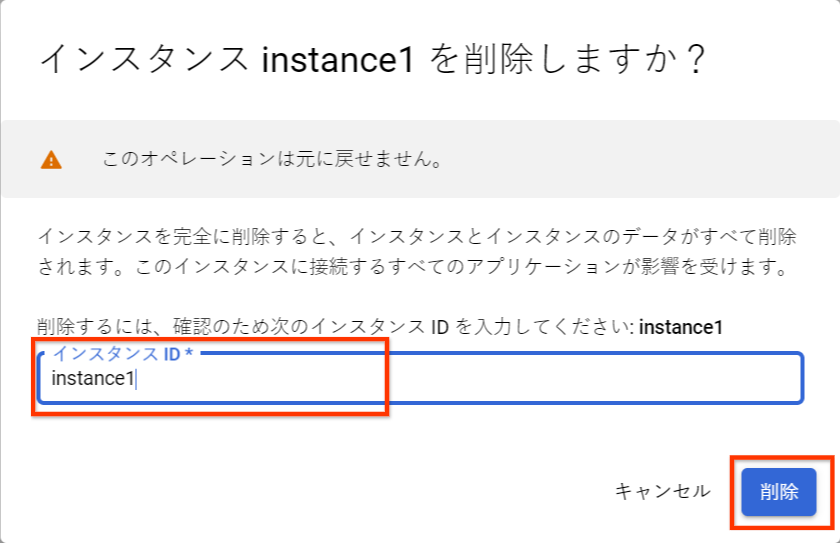
今回作成したインスタンス instance1 右側の、ドットが並んだアイコンを選択し、[削除] を選択します。

確認のためインスタンス名を入力して、[削除] を選択すると、削除処理が開始されます。
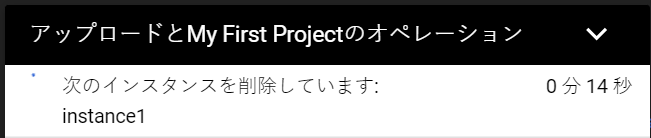
削除処理の進捗は右下のダイアログで確認が出来ますが、削除処理自体は自動で行われるので、追加での操作は不要です。

Discussion